Recognition: unknown
PoTAcc: A Pipeline for End-to-End Acceleration of Power-of-Two Quantized DNNs
Pith reviewed 2026-05-08 04:03 UTC · model grok-4.3
The pith
PoTAcc pipeline deploys power-of-two quantized DNNs on edge FPGAs with custom shift accelerators for measured speed and energy gains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
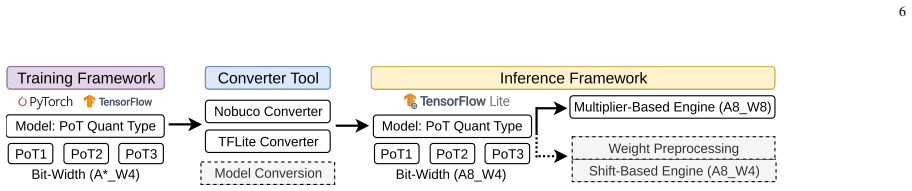
PoTAcc enables seamless preparation and deployment of PoT-quantized models via TensorFlow Lite across CPU-only systems and hybrid CPU-FPGA systems with custom accelerators. Shift-based processing element accelerators are designed for three PoT quantization methods and implemented on PYNQ-Z2 and Kria boards. Across CNNs and Transformer models, the CPU-accelerator design delivers up to 3.6x speedup and 78% energy reduction compared to CPU-only execution.
What carries the argument
The PoTAcc end-to-end pipeline that integrates TensorFlow Lite model preparation with custom shift-PE accelerators to replace multiplications by bit shifts in power-of-two quantized DNNs.
If this is right
- Power-of-two quantized models become practical to run at higher throughput on power-limited edge hardware when paired with shift-specific accelerators.
- Developers can compare multiple power-of-two quantization variants on actual FPGA hardware without rewriting inference engines.
- Hybrid CPU-FPGA edge platforms can host quantized DNN inference while keeping accuracy close to the original floating-point versions.
- Full end-to-end pipelines that include both software preparation and hardware mapping lower the barrier to testing quantization choices on real devices.
Where Pith is reading between the lines
- If the pipeline generalizes to new models without re-engineering the accelerators, it could shorten development cycles for always-on edge AI applications.
- The same shift-PE approach might combine with other low-precision formats that also favor simple arithmetic, widening the set of deployable models on FPGAs.
- Releasing the code publicly lets others test whether the reported speedups persist when the pipeline is applied to larger transformer variants or different FPGA families.
- Lower energy per inference on edge boards could translate into longer battery life for portable devices running quantized vision or language models.
Load-bearing premise
That existing TensorFlow Lite support plus the added custom shift accelerators integrate without large hidden overheads or accuracy losses when moving from CPU-only to hybrid execution on the tested boards and models.
What would settle it
Measure wall-clock time and energy for the same set of power-of-two quantized models on the PYNQ-Z2 board first with the accelerator enabled and then with it disabled; if the gap shrinks below 2x or energy savings fall under 50 percent, the integration benefit claim would not hold.
Figures




read the original abstract
Power-of-two (PoT) quantization significantly reduces the size of deep neural networks (DNNs) and replaces multiplications with bit-shift operations for inference. Prior work has shown that PoT-quantized DNNs can preserve accuracy for tasks such as image classification; however, their performance on resource-constrained edge devices remains insufficiently understood. While general-purpose edge CPUs and GPUs do not provide optimized backends for bit-shift operations, custom hardware accelerators can better exploit PoT quantization by implementing dedicated shift-based processing elements. However, deploying PoT-quantized models on such accelerators is challenging due to limited support in existing inference frameworks. In addition, the impact of different PoT quantization strategies on hardware design, performance, and energy efficiency during full inference has not been systematically explored. To address these challenges, we propose PoTAcc, an open-source end-to-end pipeline for accelerating and evaluating PoT-quantized DNNs on resource-constrained edge devices. PoTAcc enables seamless preparation and deployment of PoT-quantized models via TensorFlow Lite (TFLite) across heterogeneous platforms, including CPU-only systems and hybrid CPU-FPGA systems with custom accelerators. We design shift-based processing element (shift-PE) accelerators for three PoT quantization methods and implement them on two FPGA platforms. We evaluate accuracy, performance, energy efficiency, and resource utilization across a range of models, including CNNs and Transformer-based architectures. Results show that our CPU-accelerator design achieves up to 3.6x speedup and 78% energy reduction compared to CPU-only execution for PoT-quantized DNNs on PYNQ-Z2 and Kria boards. The code will be publicly released at https://github.com/gicLAB/PoTAcc
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PoTAcc, an open-source end-to-end pipeline that prepares and deploys Power-of-Two (PoT) quantized DNNs via TensorFlow Lite on CPU-only and hybrid CPU-FPGA edge platforms. It designs custom shift-PE accelerators for three PoT quantization schemes, implements them on PYNQ-Z2 and Kria boards, and evaluates accuracy, performance, energy efficiency, and resource utilization on CNNs and Transformer models. The central empirical claim is that the hybrid CPU-accelerator design delivers up to 3.6× speedup and 78% energy reduction versus pure CPU execution of the same PoT-quantized networks.
Significance. If the reported speedups and energy savings prove robust after isolating interconnect and offload costs, the work would supply a practical, reproducible pipeline for exploiting bit-shift arithmetic in quantized inference on heterogeneous edge hardware where standard frameworks provide limited support. The open-source release, coverage of both CNN and Transformer architectures, and systematic comparison across multiple PoT strategies are concrete strengths that would aid follow-on research in edge acceleration.
major comments (2)
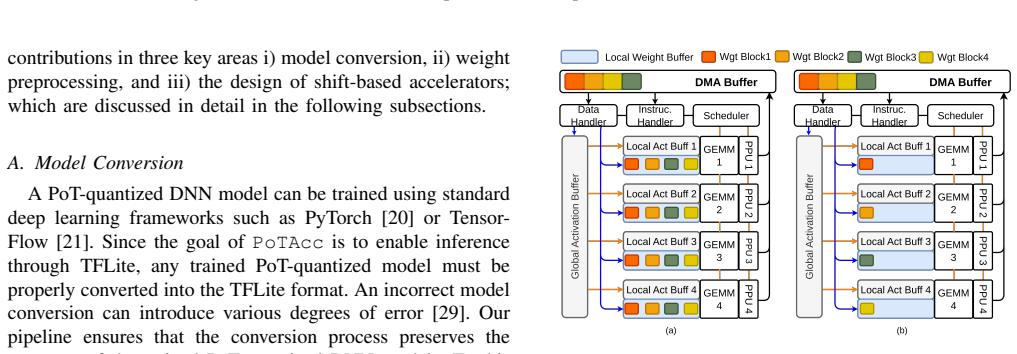
- [Evaluation / Results] Evaluation / Results section: The headline claims of up to 3.6× speedup and 78% energy reduction are presented as end-to-end hybrid measurements, yet no breakdown isolates compute time/energy inside the shift-PEs from data-movement and synchronization overheads (DMA/AXI transfers between PS and PL, delegate invocation latency). Because the paper's own motivation highlights limited framework support for bit-shift ops, this omission directly affects whether the net gains are attributable to the accelerators or are eroded by integration costs, especially for smaller models or attention layers that may not map fully to the shift-PEs.
- [Evaluation / Results] Evaluation / Results section: Performance and energy figures are given without error bars, standard deviations, or the number of repeated runs; likewise, the exact set of evaluated models, per-layer offloading decisions, and precise CPU-only TFLite baseline configuration (thread count, optimization flags) are not enumerated. These details are load-bearing for reproducibility and for assessing whether the reported gains generalize beyond the specific boards and workloads tested.
minor comments (2)
- [Abstract] Abstract: The summary of results would be clearer if it listed the concrete models (e.g., ResNet-50, ViT-B/16) and the three PoT quantization methods evaluated.
- [Implementation / Evaluation] The manuscript would benefit from an explicit statement of which layers remain on the CPU versus those offloaded to the shift-PE accelerator in the hybrid configuration.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the evaluation and results. We address each major comment below and have revised the manuscript to improve clarity, reproducibility, and attribution of the reported gains.
read point-by-point responses
-
Referee: The headline claims of up to 3.6× speedup and 78% energy reduction are presented as end-to-end hybrid measurements, yet no breakdown isolates compute time/energy inside the shift-PEs from data-movement and synchronization overheads (DMA/AXI transfers between PS and PL, delegate invocation latency). Because the paper's own motivation highlights limited framework support for bit-shift ops, this omission directly affects whether the net gains are attributable to the accelerators or are eroded by integration costs, especially for smaller models or attention layers that may not map fully to the shift-PEs.
Authors: We agree that isolating the accelerator compute contribution from integration overheads would strengthen attribution of the gains, particularly given the paper's emphasis on framework limitations for bit-shift operations. The end-to-end figures represent the practical user-visible benefit of the full pipeline, but we acknowledge the value of the requested breakdown. In the revised manuscript we have added a new profiling subsection (Section 5.4) that reports separate measurements for shift-PE compute time, DMA/AXI transfer latency, delegate invocation overhead, and synchronization costs on both platforms. These data were obtained by instrumenting the TFLite delegate and FPGA drivers; the results confirm that accelerator compute dominates for the offloaded layers in the evaluated CNNs and Transformers, while overheads remain below 15% of total time for models larger than MobileNetV2. revision: yes
-
Referee: Performance and energy figures are given without error bars, standard deviations, or the number of repeated runs; likewise, the exact set of evaluated models, per-layer offloading decisions, and precise CPU-only TFLite baseline configuration (thread count, optimization flags) are not enumerated. These details are load-bearing for reproducibility and for assessing whether the reported gains generalize beyond the specific boards and workloads tested.
Authors: We accept that the original manuscript lacked sufficient experimental detail for full reproducibility. The revised version now includes: (i) all timing and energy results averaged over 10 independent runs with standard deviations shown as error bars in Figures 6–9 and Table 3; (ii) an explicit enumeration of the evaluated models (ResNet-18/50, MobileNetV2, EfficientNet-B0, ViT-Base, and BERT-Base) together with per-layer offloading decisions (convolutions and linear layers mapped to shift-PEs where PoT weights are present; attention softmax and layer-norm remain on CPU); and (iii) the precise CPU-only TFLite baseline settings (4 threads, XNNPACK delegate enabled, -O3 compilation, and the same quantized model files used for the hybrid runs). These additions appear in Sections 4.3 and 5.1–5.2. revision: yes
Circularity Check
No circularity: empirical hardware measurements only
full rationale
The paper presents an engineering pipeline (PoTAcc) for deploying PoT-quantized models via TFLite on CPU-FPGA platforms, with custom shift-PE accelerators implemented on PYNQ-Z2 and Kria boards. All central claims (up to 3.6x speedup, 78% energy reduction) are direct empirical measurements of end-to-end inference across CNNs and Transformers; no mathematical derivations, fitted parameters renamed as predictions, uniqueness theorems, or self-citation chains appear in the text. The work is self-contained against external benchmarks because results are obtained from physical hardware runs rather than reduced to prior inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
DLAS: A Conceptual Model for Across-Stack Deep Learning Acceleration,
P. Gibson, J. Cano, E. Crowley, A. Storkey, and M. O’Boyle, “DLAS: A Conceptual Model for Across-Stack Deep Learning Acceleration,” ACM Trans. Archit. Code Optim., 2025
2025
-
[2]
Additive Powers-of-Two Quantization: An Efficient Non-Uniform Discretization for Neural Networks,
Y . Li, X. Dong, and W. Wang, “Additive Powers-of-Two Quantization: An Efficient Non-Uniform Discretization for Neural Networks,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2020
2020
-
[3]
Mix and Match: A Novel FPGA-Centric Deep Neural Network Quantization Framework,
S. Chang, Y . Li, M. Sun, R. Shi, H. H. So et al., “Mix and Match: A Novel FPGA-Centric Deep Neural Network Quantization Framework,” in Proc. IEEE Int. Symp. High-Performance Comput. Archit. (HPCA), 2021
2021
-
[4]
Power-of-two quantization for low bitwidth and hardware compliant neural networks,
D. Przewlocka-Rus, S. S. Sarwar, H. E. Sumbul, Y . Li, and B. D. Salvo, “Power-of-Two Quantization for Low Bitwidth and Hardware Compliant Neural Networks,” arXiv preprint arXiv:2203.05025, 2022
-
[5]
An Energy-and-Area- Efficient CNN Accelerator for Universal Powers-of-Two Quantization,
T. Xia, B. Zhao, J. Ma, G. Fu, W. Zhao et al., “An Energy-and-Area- Efficient CNN Accelerator for Universal Powers-of-Two Quantization,” IEEE Trans. Circuits Syst. I, Reg. Papers(TCAS-I), 2023
2023
-
[6]
LiteRT overview - google ai edge,
Google, “LiteRT overview - google ai edge,” [Online]. Available: https: //ai.google.dev/edge/litert, 2017, accessed: Apr. 22, 2026
2017
-
[7]
TensorRT - Get Started,
NVIDIA, “TensorRT - Get Started,” [Online]. Available: https:// developer.nvidia.com/tensorrt-getting-started, 2019, accessed: Apr. 22, 2026
2019
-
[8]
TVM: An Automated End-to-End Optimizing Compiler for Deep Learning,
T. Chen, T. Moreau, Z. Jiang, L. Zheng, E. Yan et al., “TVM: An Automated End-to-End Optimizing Compiler for Deep Learning,” in Proc. USENIX Symp. Operating Systems Design and Implementation (OSDI), 2018
2018
-
[9]
Convolutional Neu- ral Networks Using Logarithmic Data Representation,
D. Miyashita, E. H. Lee, and B. Murmann, “Convolutional Neu- ral Networks Using Logarithmic Data Representation,” arXiv preprint arXiv:1603.01025, 2016
-
[10]
Incremental Network Quantization: Towards Lossless CNNs with Low-Precision Weights,
A. Zhou, A. Yao, Y . Guo, L. Xu, and Y . Chen, “Incremental Network Quantization: Towards Lossless CNNs with Low-Precision Weights,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2017
2017
-
[11]
ShiftCNN: Generalized Low- Precision Architecture for Inference of Convolutional Neural Networks,
D. A. Gudovskiy and L. Rigazio, “ShiftCNN: Generalized Low- Precision Architecture for Inference of Convolutional Neural Networks,” arXiv preprint arXiv:1706.02393, 2017
-
[12]
DeepShift: Towards Multiplication-Less Neural Networks,
M. Elhoushi, Z. Chen, F. Shafiq, Y . H. Tian, and J. Y . Li, “DeepShift: Towards Multiplication-Less Neural Networks,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2021. 13
2021
-
[13]
Jumping Shift: A Logarithmic Quantization Method for Low-Power CNN Acceleration,
L. Jiang, D. Aledo, and R. van Leuken, “Jumping Shift: A Logarithmic Quantization Method for Low-Power CNN Acceleration,” in Proc. Design, Autom. Test Europe Conf. Exhib. (DATE), 2023
2023
-
[14]
DenseShift: Towards Accurate and Efficient Low-Bit Power-of-Two Quantization,
X. Li, B. Liu, R. H. Yang, V . Courville, C. Xing et al., “DenseShift: Towards Accurate and Efficient Low-Bit Power-of-Two Quantization,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2023
2023
-
[15]
Bit-Shift-Based Accelerator for CNNs with Selectable Accuracy and Throughput,
S. V ogel, R. B. Raghunath, A. Guntoro, K. V . Laerhoven, and G. As- cheid, “Bit-Shift-Based Accelerator for CNNs with Selectable Accuracy and Throughput,” in Proc. Euromicro Conf. Digit. Syst. Design (DSD), 2019
2019
-
[16]
Optimize FPGA-Based Neural Network Accelerator with Bit-Shift Quantization,
Y . Liu, X. Liu, and L. Liang, “Optimize FPGA-Based Neural Network Accelerator with Bit-Shift Quantization,” in Proc. IEEE Int. Symp. Circuits Syst. (ISCAS), 2020
2020
-
[17]
QKeras: A Quantization Deep Learning Library for Ten- sorFlow Keras,
Google, “QKeras: A Quantization Deep Learning Library for Ten- sorFlow Keras,” [Online]. Available: https://github.com/google/qkeras, 2020, accessed: Apr. 22, 2026
2020
-
[18]
Energy Efficient Hardware Accel- eration of Neural Networks with Power-of-Two Quantisation,
D. Przewlocka-Rus and T. Kryjak, “Energy Efficient Hardware Accel- eration of Neural Networks with Power-of-Two Quantisation,” in Proc. Int. Conf. Comput. Vis. Graph. (ICCVG), 2023
2023
-
[19]
Accelerating PoT Quantization on Edge Devices,
R. Saha, J. Haris, and J. Cano, “Accelerating PoT Quantization on Edge Devices,” arXiv preprint arXiv:2409.20403, 2024
-
[20]
PyTorch: an imperative style, high-performance deep learning library,
A. Paszke, S. Gross, F. Massa, A. Lerer, J. Bradbury et al., “PyTorch: an imperative style, high-performance deep learning library,” in Proc. of the Conf. on Neural Inf. Process. Syst. (NIPS), 2019
2019
-
[21]
TensorFlow: A System for Large-Scale Machine Learning,
M. Abadi, P. Barham, J. Chen, Z. Chen, A. Davis et al., “TensorFlow: A System for Large-Scale Machine Learning,” in Proc. USENIX Symp. Operating Systems Design and Implementation (OSDI), 2016
2016
-
[22]
An Improved Logarith- mic Multiplier for Energy-Efficient Neural Computing,
M. S. Ansari, B. F. Cockburn, and J. Han, “An Improved Logarith- mic Multiplier for Energy-Efficient Neural Computing,” IEEE Trans. Comput., 2021
2021
-
[23]
Elastic Significant Bit Quantization and Acceleration for Deep Neural Networks,
C. Gong, Y . Lu, K. Xie, Z. Jin, T. Li et al., “Elastic Significant Bit Quantization and Acceleration for Deep Neural Networks,” IEEE Trans. Parallel Distrib. Syst., 2021
2021
-
[24]
Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference,
B. Jacob, S. Kligys, B. Chen, M. Zhu, M. Tang et al., “Quantization and Training of Neural Networks for Efficient Integer-Arithmetic-Only Inference,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018
2018
-
[25]
SECDA: Efficient Hardware/Software Co-Design of FPGA-Based DNN Acceler- ators for Edge Inference,
J. Haris, P. Gibson, J. Cano, N. B. Agostini, and D. Kaeli, “SECDA: Efficient Hardware/Software Co-Design of FPGA-Based DNN Acceler- ators for Edge Inference,” inProc. Symp. Comput. Archit. High Perform. Comput. (SBAC-PAD), 2021
2021
-
[26]
SECDA- TFLite: A Toolkit for Efficient Development of FPGA-Based DNN Accelerators for Edge Inference,
J. Haris, P. Gibson, J. Cano, N. B. Agostini, and D. Kaeli, “SECDA- TFLite: A Toolkit for Efficient Development of FPGA-Based DNN Accelerators for Edge Inference,” J. Parallel Distrib. Comput.(JPDC), 2023
2023
-
[27]
High Performance Convolutional Neural Networks for Document Processing,
K. Chellapilla, S. Puri, and P. Simard, “High Performance Convolutional Neural Networks for Document Processing,” in Proc. Int. Workshop Frontiers in Handwriting Recognition (IWFHR), 2006
2006
-
[28]
Learning Semantic Image Representations at a Large Scale,
Y . Jia, “Learning Semantic Image Representations at a Large Scale,” Ph.D. dissertation, University of California, Berkeley, 2014
2014
-
[29]
FetaFix: Automatic Fault Localization and Repair of Deep Learning Model Conversions,
N. Louloudakis, P. Gibson, J. Cano, and A. Rajan, “FetaFix: Automatic Fault Localization and Repair of Deep Learning Model Conversions,” in Proc. Evaluation and Assessment in Software Engineering (EASE), 2025
2025
-
[30]
Lutsenko, “Nobuco,” [Online]
A. Lutsenko, “Nobuco,” [Online]. Available: https://github.com/ AlexanderLutsenko/nobuco, 2023, accessed: Apr. 22, 2026
2023
-
[31]
Deep Residual Learning for Image Recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep Residual Learning for Image Recognition,” inProc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2016
2016
-
[32]
MobileNetV2: Inverted Residuals and Linear Bottlenecks,
M. Sandler, A. Howard, M. Zhu, A. Zhmoginov, and L.-C. Chen, “MobileNetV2: Inverted Residuals and Linear Bottlenecks,” in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit. (CVPR), 2018
2018
-
[33]
PYNQ-Z2,
AMD, “PYNQ-Z2,” [Online]. Available: https://www.pynq.io/boards. html, 2018, accessed: Apr. 22, 2026
2018
-
[34]
Kria KV260 Vision AI Starter Kit,
AMD INC, “Kria KV260 Vision AI Starter Kit,” [Online]. Avail- able: https://www.amd.com/en/products/system-on-modules/KRIA/k26/ kv260-vision-starter-kit.html, 2021, accessed: Apr. 22, 2026
2021
-
[35]
Going Deeper with Convolutions,
C. Szegedy, W. Liu, Y . Jia, P. Sermanet, S. Reed et al., “Going Deeper with Convolutions,” in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), 2015
2015
-
[36]
EfficientNet: Rethinking Model Scaling for Con- volutional Neural Networks,
M. Tan and Q. Le, “EfficientNet: Rethinking Model Scaling for Con- volutional Neural Networks,” in Proc. Int. Conf. Mach. Learn. (ICML), 2019
2019
-
[37]
An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale,
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai et al., “An Image Is Worth 16x16 Words: Transformers for Image Recognition at Scale,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2020
2020
-
[38]
Training Data-Efficient Image Transformers and Distillation Through Attention,
H. Touvron, M. Cord, M. Douze, F. Massa, A. Sablayrolles et al., “Training Data-Efficient Image Transformers and Distillation Through Attention,” in Proc. Int. Conf. Mach. Learn. (ICML), 2021
2021
-
[39]
ImageNet Large Scale Visual Recognition Challenge,
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh et al., “ImageNet Large Scale Visual Recognition Challenge,” Int. J. Comput. Vis.(IJCV), 2015
2015
-
[40]
Learning Multiple Layers of Features from Tiny Im- ages,
A. Krizhevsky, “Learning Multiple Layers of Features from Tiny Im- ages,” University of Toronto, Tech. Rep., 2009
2009
-
[41]
A VHzY CT-3 USB Digital Power Meter,
“A VHzY CT-3 USB Digital Power Meter,” [Online]. Available: https:// www.avhzy.com/html/product-detail/ct3, 2025, accessed: Apr. 22, 2026
2025
-
[42]
AMD Inc., Vivado Design Suite User Guide: Designing IP Subsystems Using IP Integrator, 2019, uG994 (v2019.1)
2019
-
[43]
RMSMP: A Novel Deep Neural Network Quantization Framework with Row-Wise Mixed Schemes and Multiple Precisions,
S.-E. Chang, Y . Li, M. Sun, R. Shi, H. H. So et al., “RMSMP: A Novel Deep Neural Network Quantization Framework with Row-Wise Mixed Schemes and Multiple Precisions,” in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), 2021
2021
-
[44]
Compact Powers- of-Two: An Efficient Non-Uniform Quantization for Deep Neural Net- works,
X. Geng, S. Liu, J. Jiang, K. Jiang, and H. Jiang, “Compact Powers- of-Two: An Efficient Non-Uniform Quantization for Deep Neural Net- works,” in Proc. Design, Autom. Test Europe Conf. Exhib. (DATE), 2024
2024
-
[45]
S 3: Sign-Sparse-Shift Reparametrization for Effective Training of Low-Bit Shift Networks,
X. Li, B. Liu, Y . Yu, W. Liu, C. Xu et al., “S 3: Sign-Sparse-Shift Reparametrization for Effective Training of Low-Bit Shift Networks,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2021
2021
-
[46]
ImageNet Classification with Deep Convolutional Neural Networks,
A. Krizhevsky, I. Sutskever, and G. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks,” in Proc. Adv. Neural Inf. Process. Syst. (NeurIPS), 2012
2012
-
[47]
Microsoft COCO: Common Objects in Context,
T.-Y . Lin, M. Maire, S. Belongie, J. Hays, P. Perona et al., “Microsoft COCO: Common Objects in Context,” in Proc. Eur. Conf. Comput. Vis. (ECCV), 2014
2014
-
[48]
POWERQUANT: Automorphism Search for Non-Uniform Quantization,
E. Yvinec, A. Dapogny, M. Cord, and K. Bailly, “POWERQUANT: Automorphism Search for Non-Uniform Quantization,” in Proc. Int. Conf. Learn. Represent. (ICLR), 2023
2023
-
[49]
M2-ViT: Accelerating Hybrid Vision Transformers With Two-Level Mixed Quantization,
Y . Liang, H. Shi, and Z. Wang, “M2-ViT: Accelerating Hybrid Vision Transformers With Two-Level Mixed Quantization,” IEEE Trans. Very Large Scale Integr. (VLSI) Syst., 2025
2025
-
[50]
ShiftAddLLM: Accelerating Pretrained LLMs via Post-Training Multiplication-Less Reparameterization,
H. You, Y . Guo, Y . Fu, W. Zhou, H. Shi et al., “ShiftAddLLM: Accelerating Pretrained LLMs via Post-Training Multiplication-Less Reparameterization,” arXiv preprint arXiv:2406.05981, 2024
-
[51]
PoTPTQ: A Two-Step Power-of-Two Post-Training for LLMs,
X. Wang, V . P. Nia, P. Lu, J. Huang, X.-W. Chang et al., “PoTPTQ: A Two-Step Power-of-Two Post-Training for LLMs,” arXiv preprint arXiv:2507.11959, 2025
-
[52]
Inter-Layer Hybrid Quantization Scheme for Hardware Friendly Implementation of Embedded Deep Neural Networks,
N. Nazari and M. E. Salehi, “Inter-Layer Hybrid Quantization Scheme for Hardware Friendly Implementation of Embedded Deep Neural Networks,” in Proc. Great Lakes Symp. VLSI (GLSVLSI), 2023
2023
-
[53]
Available: https://onnx.ai/, 2017, accessed: Apr
“ONNX,” [Online]. Available: https://onnx.ai/, 2017, accessed: Apr. 22, 2026
2017
-
[54]
FILM-QNN: Efficient FPGA Acceleration of Deep Neural Networks with Intra- Layer, Mixed-Precision Quantization,
M. Sun, Z. Li, A. Lu, Y . Li, S.-E. Chang et al., “FILM-QNN: Efficient FPGA Acceleration of Deep Neural Networks with Intra- Layer, Mixed-Precision Quantization,” in Proc. ACM/SIGDA Int. Symp. Field-Programmable Gate Arrays (FPGA), 2022
2022
-
[55]
A Hardware- Software Blueprint for Flexible Deep Learning Specialization,
T. Moreau, T. Chen, L. Vega, J. Roesch, E. Yan et al., “A Hardware- Software Blueprint for Flexible Deep Learning Specialization,” IEEE Micro, 2019
2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.