Recognition: unknown
Beyond Autoregressive RTG: Conditioning via Injection Outside Sequential Modeling in Decision Transformer
Pith reviewed 2026-05-08 13:52 UTC · model grok-4.3
The pith
SlimDT improves Decision Transformers by injecting RTG information into states rather than using it as an autoregressive token.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
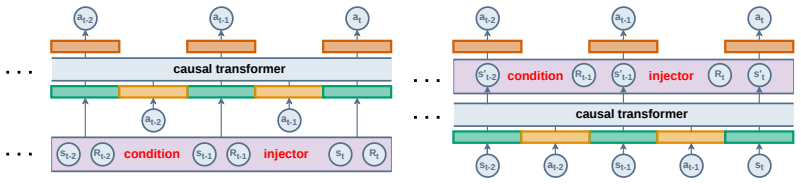
Decision Transformer formulates offline reinforcement learning as autoregressive sequence modeling over Return-to-Go, state, and action tokens. SlimDT decouples the Return-to-Go conditioning by injecting its information into the state representations outside the sequential modeling step. The Transformer then models only the compact state-action sequence. This approach reduces sequence length by one-third and produces higher performance on D4RL tasks compared to standard Decision Transformer while remaining competitive with state-of-the-art methods.
What carries the argument
The RTG injection into state representations, which embeds the Return-to-Go scalar directly into state vectors prior to Transformer sequential modeling to provide conditioning without adding a separate token to the autoregressive sequence.
If this is right
- Reduces sequence length by one-third for direct gains in inference efficiency.
- SlimDT surpasses standard DT across various D4RL tasks.
- SlimDT achieves performance comparable to existing state-of-the-art methods.
- Decoupling sparse conditioning signals from information-rich sequences yields computational gains and higher task performance.
Where Pith is reading between the lines
- This method of external injection could generalize to other conditioning signals in autoregressive models, such as in language or vision sequence tasks.
- In settings with limited compute, shorter sequences from such decoupling might allow scaling to longer horizons or larger models.
- The success suggests that explicit autoregressive tokens are not always necessary for effective conditioning in Transformers.
Load-bearing premise
The injected RTG information in the state representations retains sufficient conditioning power for the Transformer to accurately predict future actions without an explicit autoregressive RTG token.
What would settle it
An ablation study replacing the actual RTG values with random or constant values during injection and checking if task performance on D4RL drops significantly below that of the standard Decision Transformer.
Figures
read the original abstract
Decision Transformer (DT) formulates offline reinforcement learning as autoregressive sequence modeling, achieving promising results by predicting actions from a sequence of Return-to-Go (RTG), state, and action tokens. However, RTG is a scalar that summarizes future rewards, containing far less information than typical state or action vectors, yet it consumes the same computational budget per token. Worse, the self-attention cost of Transformers grows quadratically with sequence length, so including RTG as a separate token adds unnecessary overhead. We propose SlimDT, which removes RTG from the autoregressive sequence. Instead, we inject RTG information into the state representations before the sequential modeling step, allowing the Transformer to process only a compact (state, action) sequence. This reduces the sequence length by one-third, directly improving inference efficiency. On the D4RL benchmark, SlimDT surpasses standard DT across various tasks and achieves performance comparable to existing state-of-the-art methods. Decoupling a sparse conditioning signal from an information-rich sequence thus yields both computational gains and higher task performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SlimDT, a variant of Decision Transformer for offline RL. RTG is removed from the autoregressive token sequence and instead injected into state representations prior to Transformer processing, yielding a compact (state, action) sequence that is one-third shorter. The authors claim this yields both higher inference efficiency and improved task performance, with SlimDT surpassing standard DT on D4RL benchmarks while matching existing SOTA methods.
Significance. If the results hold, the work demonstrates that a sparse scalar conditioning signal can be decoupled from the main sequence without loss of performance, simultaneously cutting quadratic attention cost and improving returns. This architectural insight could influence subsequent Transformer-based offline RL designs by showing that explicit autoregressive tokens are not always necessary for effective return conditioning.
major comments (2)
- [Method / Architecture description] The injection operator that embeds RTG into state vectors before the first Transformer layer is described only at a high level. Without an explicit equation or pseudocode (e.g., in the method section) defining whether the operation is a learned linear projection, concatenation followed by a feed-forward layer, or simple addition, it is impossible to verify whether the static pre-injection can substitute for the dynamic, position-specific conditioning that the original RTG token receives in every self-attention layer across long horizons.
- [Experiments / Ablation studies] The central empirical claim—that SlimDT surpasses DT and matches SOTA on D4RL—rests on the assumption that pre-injection retains sufficient conditioning power. The manuscript must therefore report the precise injection mechanism together with ablations that isolate its effect (e.g., comparing learned vs. fixed injection, or measuring performance degradation when RTG is updated online during inference).
minor comments (2)
- The abstract asserts quantitative superiority and efficiency gains but supplies no numbers, tables, or runtime measurements; moving at least one key result (e.g., average normalized score or wall-clock speedup) into the abstract would strengthen the summary.
- A side-by-side diagram contrasting the token sequences of standard DT and SlimDT would clarify the claimed one-third length reduction and the exact location of the injection step.
Simulated Author's Rebuttal
We thank the referee for the constructive comments and for recognizing the potential significance of decoupling the RTG conditioning signal from the autoregressive sequence. We address each major comment below and will revise the manuscript accordingly to improve clarity and empirical validation.
read point-by-point responses
-
Referee: [Method / Architecture description] The injection operator that embeds RTG into state vectors before the first Transformer layer is described only at a high level. Without an explicit equation or pseudocode (e.g., in the method section) defining whether the operation is a learned linear projection, concatenation followed by a feed-forward layer, or simple addition, it is impossible to verify whether the static pre-injection can substitute for the dynamic, position-specific conditioning that the original RTG token receives in every self-attention layer across long horizons.
Authors: We agree that a more precise description is needed for reproducibility. In the revised manuscript, we will add an explicit equation in Section 3: the scalar RTG is embedded via a learned linear projection and added to the state embedding before the Transformer, formulated as e'_s,t = e_s,t + W_rtg * r_t, where W_rtg is a learnable matrix matching the embedding dimension. This static pre-injection integrates the conditioning into state representations, allowing self-attention layers to propagate the return information across the sequence without a dedicated token. We maintain that this can substitute for per-layer dynamic conditioning because the modified embeddings enable the model to attend to states with the appropriate future-return context throughout the horizon. revision: yes
-
Referee: [Experiments / Ablation studies] The central empirical claim—that SlimDT surpasses DT and matches SOTA on D4RL—rests on the assumption that pre-injection retains sufficient conditioning power. The manuscript must therefore report the precise injection mechanism together with ablations that isolate its effect (e.g., comparing learned vs. fixed injection, or measuring performance degradation when RTG is updated online during inference).
Authors: We will include the precise injection mechanism (as detailed above) in the revision. We will also add ablation studies comparing learned projection injection against fixed variants (e.g., zero injection or constant addition without learning). Regarding online RTG updates during inference, we note that standard offline RL evaluation uses fixed dataset-derived RTGs; however, we will add an experiment perturbing RTG values at test time to simulate online adjustments and report resulting performance changes. These additions will isolate the injection's contribution and further support that pre-injection retains sufficient conditioning power. revision: yes
Circularity Check
No circularity: direct architectural proposal with empirical validation
full rationale
The paper proposes SlimDT as a straightforward modification to Decision Transformer: remove the RTG token from the autoregressive sequence and inject RTG information into state representations before sequential modeling. No equations, derivations, or mathematical claims are presented that reduce performance results to fitted parameters, self-definitions, or self-citation chains. The central claims rest on D4RL benchmark comparisons, which are external and falsifiable. No uniqueness theorems, ansatzes smuggled via citation, or renamings of known results appear. The approach is self-contained as an empirical architecture change without load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Self-attention cost grows quadratically with sequence length
Reference graph
Works this paper leans on
-
[1]
Decision transformer: Reinforcement learning via sequence modeling.Advances in neural information processing systems, 34:15084–15097, 2021
Lili Chen, Kevin Lu, Aravind Rajeswaran, Kimin Lee, Aditya Grover, Misha Laskin, Pieter Abbeel, Aravind Srinivas, and Igor Mordatch. Decision transformer: Reinforcement learning via sequence modeling.Advances in neural information processing systems, 34:15084–15097, 2021
2021
-
[2]
Attention is all you need.Advances in neural information processing systems, 30, 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need.Advances in neural information processing systems, 30, 2017
2017
-
[3]
D4RL: Datasets for Deep Data-Driven Reinforcement Learning
Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, and Sergey Levine. D4rl: Datasets for deep data-driven reinforcement learning.arXiv preprint arXiv:2004.07219, 2020
work page internal anchor Pith review arXiv 2004
-
[4]
Off-policy deep reinforcement learning without explo- ration
Scott Fujimoto, David Meger, and Doina Precup. Off-policy deep reinforcement learning without explo- ration. InInternational conference on machine learning, pages 2052–2062. PMLR, 2019
2052
-
[5]
Stabilizing off-policy q-learning via bootstrapping error reduction.Advances in neural information processing systems, 32, 2019
Aviral Kumar, Justin Fu, Matthew Soh, George Tucker, and Sergey Levine. Stabilizing off-policy q-learning via bootstrapping error reduction.Advances in neural information processing systems, 32, 2019
2019
-
[6]
A minimalist approach to offline reinforcement learning.Advances in neural information processing systems, 34:20132–20145, 2021
Scott Fujimoto and Shixiang Shane Gu. A minimalist approach to offline reinforcement learning.Advances in neural information processing systems, 34:20132–20145, 2021
2021
-
[7]
Conservative q-learning for offline reinforcement learning.Advances in neural information processing systems, 33:1179–1191, 2020
Aviral Kumar, Aurick Zhou, George Tucker, and Sergey Levine. Conservative q-learning for offline reinforcement learning.Advances in neural information processing systems, 33:1179–1191, 2020
2020
-
[8]
Uncertainty-based offline reinforcement learning with diversified q-ensemble.Advances in neural information processing systems, 34:7436–7447, 2021
Gaon An, Seungyong Moon, Jang-Hyun Kim, and Hyun Oh Song. Uncertainty-based offline reinforcement learning with diversified q-ensemble.Advances in neural information processing systems, 34:7436–7447, 2021
2021
-
[9]
Offline Reinforcement Learning with Implicit Q-Learning
Ilya Kostrikov, Ashvin Nair, and Sergey Levine. Offline reinforcement learning with implicit q-learning. arXiv preprint arXiv:2110.06169, 2021
work page internal anchor Pith review arXiv 2021
-
[10]
Extreme q-learning: Maxent rl without entropy
Divyansh Garg, Joey Hejna, Matthieu Geist, and Stefano Ermon. Extreme q-learning: Maxent rl without entropy.arXiv preprint arXiv:2301.02328, 2023
-
[11]
Mopo: Model-based offline policy optimization.Advances in neural information processing systems, 33:14129–14142, 2020
Tianhe Yu, Garrett Thomas, Lantao Yu, Stefano Ermon, James Y Zou, Sergey Levine, Chelsea Finn, and Tengyu Ma. Mopo: Model-based offline policy optimization.Advances in neural information processing systems, 33:14129–14142, 2020
2020
-
[12]
Morel: Model-based offline reinforcement learning.Advances in neural information processing systems, 33:21810–21823, 2020
Rahul Kidambi, Aravind Rajeswaran, Praneeth Netrapalli, and Thorsten Joachims. Morel: Model-based offline reinforcement learning.Advances in neural information processing systems, 33:21810–21823, 2020
2020
-
[13]
Combo: Conservative offline model-based policy optimization.Advances in neural information processing systems, 34:28954–28967, 2021
Tianhe Yu, Aviral Kumar, Rafael Rafailov, Aravind Rajeswaran, Sergey Levine, and Chelsea Finn. Combo: Conservative offline model-based policy optimization.Advances in neural information processing systems, 34:28954–28967, 2021
2021
-
[14]
Generalized decision transformer for offline hindsight information matching
Hiroki Furuta, Yutaka Matsuo, and Shixiang Shane Gu. Generalized decision transformer for offline hindsight information matching. InInternational Conference on Learning Representations, 2022
2022
-
[15]
Decoupling return-to-go for efficient decision transformer.arXiv preprint arXiv:2601.15953, 2026
Yongyi Wang, Hanyu Liu, Lingfeng Li, Bozhou Chen, Ang Li, Qirui Zheng, Xionghui Yang, and Wenxin Li. Decoupling return-to-go for efficient decision transformer.arXiv preprint arXiv:2601.15953, 2026
-
[16]
Waypoint transformer: Reinforcement learning via supervised learning with intermediate targets.Advances in Neural Information Processing Systems, 36:78006–78027, 2023
Anirudhan Badrinath, Yannis Flet-Berliac, Allen Nie, and Emma Brunskill. Waypoint transformer: Reinforcement learning via supervised learning with intermediate targets.Advances in Neural Information Processing Systems, 36:78006–78027, 2023
2023
-
[17]
Elastic decision transformer.Advances in neural information processing systems, 36:18532–18550, 2023
Yueh-Hua Wu, Xiaolong Wang, and Masashi Hamaya. Elastic decision transformer.Advances in neural information processing systems, 36:18532–18550, 2023
2023
-
[18]
Q-learning decision transformer: Leveraging dynamic programming for conditional sequence modelling in offline rl
Taku Yamagata, Ahmed Khalil, and Raul Santos-Rodriguez. Q-learning decision transformer: Leveraging dynamic programming for conditional sequence modelling in offline rl. InInternational Conference on Machine Learning, pages 38989–39007. PMLR, 2023. 10
2023
-
[19]
Rethinking decision transformer via hierarchical reinforcement learning
Yi Ma, Jianye Hao, Hebin Liang, and Chenjun Xiao. Rethinking decision transformer via hierarchical reinforcement learning. InInternational Conference on Machine Learning, pages 33730–33745. PMLR, 2024
2024
-
[20]
You can’t count on luck: Why decision transformers and rvs fail in stochastic environments.Advances in neural information processing systems, 35:38966–38979, 2022
Keiran Paster, Sheila McIlraith, and Jimmy Ba. You can’t count on luck: Why decision transformers and rvs fail in stochastic environments.Advances in neural information processing systems, 35:38966–38979, 2022
2022
-
[21]
Dichotomy of control: Separating what you can control from what you cannot
Sherry Yang, Dale Schuurmans, Pieter Abbeel, and Ofir Nachum. Dichotomy of control: Separating what you can control from what you cannot. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[22]
Act: Empower- ing decision transformer with dynamic programming via advantage conditioning
Chen-Xiao Gao, Chenyang Wu, Mingjun Cao, Rui Kong, Zongzhang Zhang, and Yang Yu. Act: Empower- ing decision transformer with dynamic programming via advantage conditioning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 12127–12135, 2024
2024
-
[23]
Online decision transformer
Qinqing Zheng, Amy Zhang, and Aditya Grover. Online decision transformer. Ininternational conference on machine learning, pages 27042–27059. PMLR, 2022
2022
-
[24]
Critic-guided decision transformer for offline reinforcement learning
Yuanfu Wang, Chao Yang, Ying Wen, Yu Liu, and Yu Qiao. Critic-guided decision transformer for offline reinforcement learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 15706–15714, 2024
2024
-
[25]
Reinforcement learning gradients as vitamin for online finetuning decision transformers.Advances in Neural Information Processing Systems, 37:38590–38628, 2024
Kai Yan, Alex Schwing, and Yu-Xiong Wang. Reinforcement learning gradients as vitamin for online finetuning decision transformers.Advances in Neural Information Processing Systems, 37:38590–38628, 2024
2024
-
[26]
Online finetuning decision transformers with pure rl gradients.arXiv preprint arXiv:2601.00167, 2026
Junkai Luo and Yinglun Zhu. Online finetuning decision transformers with pure rl gradients.arXiv preprint arXiv:2601.00167, 2026
-
[27]
Value-guided decision transformer: A unified reinforcement learning framework for online and offline settings
Hongling Zheng, Li Shen, Yong Luo, Deheng Ye, Shuhan Xu, Bo Du, Jialie Shen, and Dacheng Tao. Value-guided decision transformer: A unified reinforcement learning framework for online and offline settings. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[28]
Decision convformer: Local filtering in metaformer is sufficient for decision making
Jeonghye Kim, Suyoung Lee, Woojun Kim, and Youngchul Sung. Decision convformer: Local filtering in metaformer is sufficient for decision making. InNeurIPS 2023 Foundation Models for Decision Making Workshop, 2023
2023
-
[29]
Mamba: Linear-time sequence modeling with selective state spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces. InFirst conference on language modeling, 2024
2024
-
[30]
Decision mamba: A multi- grained state space model with self-evolution regularization for offline rl.Advances in Neural Information Processing Systems, 37:22827–22849, 2024
Qi Lv, Xiang Deng, Gongwei Chen, Michael Yu Wang, and Liqiang Nie. Decision mamba: A multi- grained state space model with self-evolution regularization for offline rl.Advances in Neural Information Processing Systems, 37:22827–22849, 2024
2024
-
[31]
Decision mamba: Reinforcement learning via hybrid selective sequence modeling.Advances in Neural Information Processing Systems, 37:72688–72709, 2024
Sili Huang, Jifeng Hu, Zhejian Yang, Liwei Yang, Tao Luo, Hechang Chen, Lichao Sun, and Bo Yang. Decision mamba: Reinforcement learning via hybrid selective sequence modeling.Advances in Neural Information Processing Systems, 37:72688–72709, 2024
2024
-
[32]
Long-short decision transformer: Bridging global and local dependencies for generalized decision-making
Jincheng Wang, Penny Karanasou, Pengyuan Wei, Elia Gatti, Diego Martinez Plasencia, and Dimitrios Kanoulas. Long-short decision transformer: Bridging global and local dependencies for generalized decision-making. InICLR, pages 1–25. OpenReview. net, 2025
2025
-
[33]
Less is more: an attention-free sequence prediction modeling for offline embodied learning
Wei Huang, Jianshu Zhang, Leiyu Wang, Heyue Li, Luoyi Fan, Yichen Zhu, Nanyang Ye, and Qinying Gu. Less is more: an attention-free sequence prediction modeling for offline embodied learning. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[34]
Improving language understanding by generative pre-training
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever, et al. Improving language understanding by generative pre-training. 2018
2018
-
[35]
Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever, et al. Language models are unsupervised multitask learners.OpenAI blog, 1(8):9, 2019
2019
-
[36]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E Hinton. Layer normalization.arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review arXiv 2016
-
[37]
Modulating early visual processing by language.Advances in neural information processing systems, 30, 2017
Harm De Vries, Florian Strub, Jérémie Mary, Hugo Larochelle, Olivier Pietquin, and Aaron C Courville. Modulating early visual processing by language.Advances in neural information processing systems, 30, 2017. 11
2017
-
[38]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019
2019
-
[39]
Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
Prafulla Dhariwal and Alexander Nichol. Diffusion models beat gans on image synthesis.Advances in neural information processing systems, 34:8780–8794, 2021
2021
-
[40]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 4195–4205, 2023
2023
-
[41]
Starformer: Transformer with state-action-reward representations for visual reinforcement learning
Jinghuan Shang, Kumara Kahatapitiya, Xiang Li, and Michael S Ryoo. Starformer: Transformer with state-action-reward representations for visual reinforcement learning. InEuropean conference on computer vision, pages 462–479. Springer, 2022
2022
-
[42]
d3rlpy: An offline deep reinforcement learning library.Journal of Machine Learning Research, 23(315):1–20, 2022
Takuma Seno and Michita Imai. d3rlpy: An offline deep reinforcement learning library.Journal of Machine Learning Research, 23(315):1–20, 2022. 12 A Hyperparameters Hyperparameters Value Number of attention layers3 Attention heads1 Context lengthk20 Batch size128 Learning rate10 −4 Embedding dimension128 Dropout rate0.1 Activation ReLU Weight decay10 −4 Gr...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.