Recognition: unknown
Continuous Expert Assembly: Instance-Conditioned Low-Rank Residuals for All-in-One Image Restoration
Pith reviewed 2026-05-08 13:53 UTC · model grok-4.3
The pith
Continuous Expert Assembly adapts a shared restoration model to unknown, spatially varying degradations by synthesizing and densely combining instance-specific low-rank residuals at each image token.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
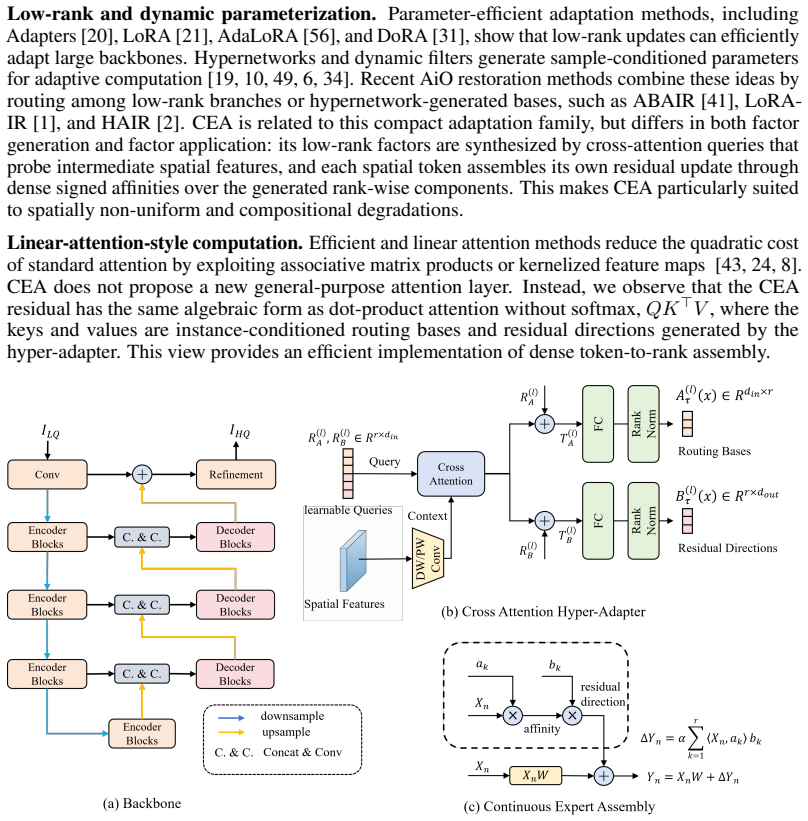
CEA employs a Cross-Attention Hyper-Adapter to probe intermediate spatial features and generate instance-conditioned low-rank routing bases together with residual directions; each token then assembles its residual update via dense signed dot-product affinities over the rank-wise components, without external prompts, static expert banks, or discrete Top-k selection, and the assembly admits a linear-attention interpretation.
What carries the argument
The Cross-Attention Hyper-Adapter that generates instance-conditioned low-rank routing bases and residual directions from intermediate features, followed by dense signed dot-product token-wise assembly.
If this is right
- Higher average restoration metrics on AIO-3, AIO-5, and CDD-11, especially where degradations change across the image.
- Lower or comparable parameter count, FLOPs, and runtime than static expert-pool methods.
- Avoidance of homogeneous updates and unstable sparse routing that can occur with discrete expert selection.
- A transparent linear-attention view of the routing process that follows directly from the dense affinity rule.
Where Pith is reading between the lines
- The same per-token continuous routing could be tested on video sequences where degradations also vary across both space and time.
- Replacing discrete expert banks with synthesized low-rank components may reduce memory footprint in other conditional vision models.
- The linear-attention equivalence suggests the method could be accelerated further with existing efficient attention kernels without changing the learned behavior.
Load-bearing premise
A lightweight cross-attention module can reliably extract effective low-rank bases and residual directions directly from the image's own intermediate features and that the resulting dense signed assembly stays stable and non-homogeneous.
What would settle it
No measurable quality gain, or outright worse results, on test sets containing spatially varying or compositional degradations when compared with strong prompt- and expert-based baselines under matched compute budgets.
Figures




read the original abstract
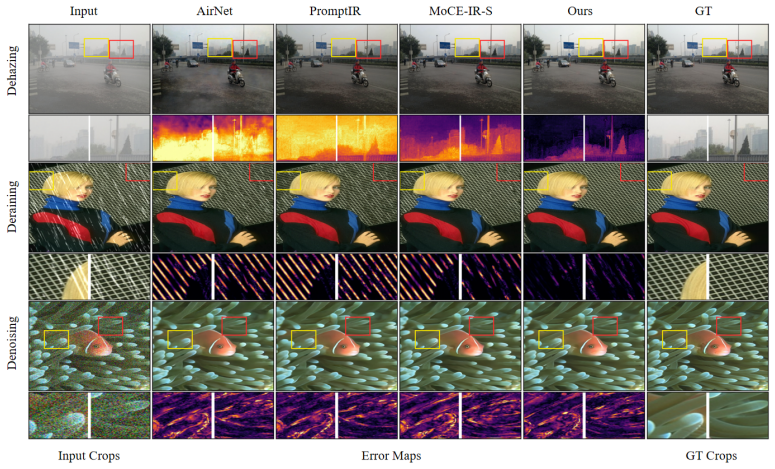
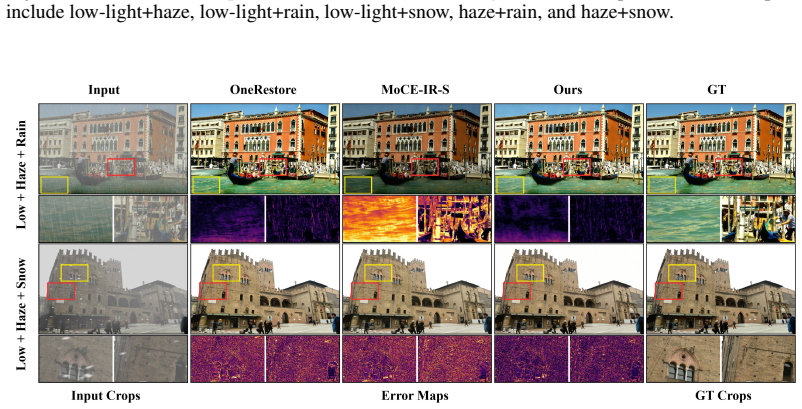
Real-world image degradation is often unknown, spatially non-uniform, and compositional, requiring all-in-one restoration models to adapt a single set of weights to diverse local corruption patterns without test-time degradation labels. Existing methods typically modulate a shared backbone with global prompts or degradation descriptors, or route features through predefined expert pools. However, compact global conditioning can bottleneck localized degradation evidence, while static expert routing may produce homogeneous updates or rely on unstable sparse assignments. We propose \textbf{Continuous Expert Assembly} (CEA), a token-wise dynamic parameterization framework for all-in-one image restoration. CEA employs a lightweight \textbf{Cross-Attention Hyper-Adapter} to probe intermediate spatial features and synthesize instance-conditioned low-rank routing bases and residual directions. Each spatial token then assembles its own residual update via dense signed dot-product affinities over the generated rank-wise components, avoiding external prompts, static expert banks, and discrete Top- selection. The resulting assembly rule also admits a linear-attention perspective, making its dense token-wise routing behavior transparent. Experiments on AIO-3, AIO-5, and CDD-11 show that CEA improves average restoration quality over strong prompt-, descriptor-, and expert-based baselines, with the clearest gains on spatially varying and compositional degradations, while maintaining favorable parameter, FLOP, and runtime efficiency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Continuous Expert Assembly (CEA) for all-in-one image restoration, addressing unknown, spatially non-uniform, and compositional degradations. It proposes a token-wise dynamic parameterization using a lightweight Cross-Attention Hyper-Adapter that synthesizes instance-conditioned low-rank routing bases and residual directions from intermediate spatial features. Each token then computes its residual update via dense signed dot-product affinities over these components, avoiding external prompts, static expert banks, and discrete Top-k selection. The assembly is also interpreted through a linear-attention lens. Experiments on AIO-3, AIO-5, and CDD-11 report average quality improvements over prompt-, descriptor-, and expert-based baselines, with stronger gains on spatially varying degradations, while claiming favorable parameter, FLOP, and runtime efficiency.
Significance. If the empirical gains and the mechanism's instance-specific adaptation hold under scrutiny, CEA could meaningfully advance all-in-one restoration by enabling more localized, non-homogeneous updates without the bottlenecks of global conditioning or fixed expert pools. The linear-attention view provides a useful transparency angle. The approach builds on low-rank adaptation ideas but applies them continuously and densely at the token level, which may generalize to other adaptive vision tasks if the synthesized bases prove meaningfully diverse.
major comments (3)
- [Experiments] Experiments (assumed §4): The abstract and introduction assert average restoration quality gains over strong baselines on AIO-3, AIO-5, and CDD-11 with clearest benefits on spatially varying degradations, yet no specific PSNR/SSIM numbers, per-degradation breakdowns, or statistical significance tests are referenced in the provided text. This makes it impossible to verify the magnitude of improvement or rule out that gains derive primarily from the shared backbone rather than the proposed assembly.
- [Method] Method (§3, Cross-Attention Hyper-Adapter description): The central claim requires that the adapter produces distinct, instance-conditioned low-rank bases and residual directions that vary meaningfully with local spatial features. No ablation or analysis (e.g., cosine similarity of generated bases across degradation types or spatial maps of assembled residuals) is described to confirm non-homogeneous updates; without this, the performance advantage over global prompt methods remains unproven.
- [Method] Method (dense signed dot-product assembly): The paper states that the dense assembly avoids unstable sparse assignments and admits a linear-attention perspective. However, no analysis of numerical stability, gradient flow, or comparison to sparse alternatives is provided, which is load-bearing for the claim that this routing is reliably superior for compositional degradations.
minor comments (2)
- [Abstract] Abstract: The phrase 'dense signed dot-product affinities over the generated rank-wise components' is introduced without a brief equation or notation preview, reducing immediate clarity for readers unfamiliar with the low-rank construction.
- [Method] Notation: The manuscript should explicitly define the dimensions of the synthesized low-rank bases (e.g., rank r, feature dimension d) and the exact form of the signed dot-product in the first method subsection to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment below and have revised the paper to strengthen the presentation of results and supporting analyses.
read point-by-point responses
-
Referee: [Experiments] Experiments (assumed §4): The abstract and introduction assert average restoration quality gains over strong baselines on AIO-3, AIO-5, and CDD-11 with clearest benefits on spatially varying degradations, yet no specific PSNR/SSIM numbers, per-degradation breakdowns, or statistical significance tests are referenced in the provided text. This makes it impossible to verify the magnitude of improvement or rule out that gains derive primarily from the shared backbone rather than the proposed assembly.
Authors: We appreciate this observation. The full manuscript in §4 and the associated tables report concrete PSNR/SSIM values, per-degradation breakdowns on AIO-3/AIO-5/CDD-11, and comparisons isolating the contribution of the assembly module from the shared backbone. In the revised version we will add explicit numerical references (e.g., average PSNR gains) and direct citations to these tables in both the abstract and introduction, along with a brief note on the consistency of improvements across datasets. This will make the magnitude and source of the gains immediately verifiable without altering the experimental claims. revision: yes
-
Referee: [Method] Method (§3, Cross-Attention Hyper-Adapter description): The central claim requires that the adapter produces distinct, instance-conditioned low-rank bases and residual directions that vary meaningfully with local spatial features. No ablation or analysis (e.g., cosine similarity of generated bases across degradation types or spatial maps of assembled residuals) is described to confirm non-homogeneous updates; without this, the performance advantage over global prompt methods remains unproven.
Authors: We agree that direct evidence of instance- and spatially-conditioned variation is important for substantiating the advantage over global prompt baselines. While the current manuscript emphasizes end-to-end performance, the revised version will incorporate an additional analysis subsection that includes (i) cosine-similarity statistics of the synthesized low-rank bases across different degradation types and (ii) qualitative spatial maps of the assembled residual updates. These additions will demonstrate that the Cross-Attention Hyper-Adapter generates meaningfully distinct, non-homogeneous components conditioned on local features. revision: yes
-
Referee: [Method] Method (dense signed dot-product assembly): The paper states that the dense assembly avoids unstable sparse assignments and admits a linear-attention perspective. However, no analysis of numerical stability, gradient flow, or comparison to sparse alternatives is provided, which is load-bearing for the claim that this routing is reliably superior for compositional degradations.
Authors: The dense signed dot-product formulation is presented precisely to circumvent the instability of discrete Top-k selection while admitting a linear-attention interpretation. We concur that explicit supporting analysis would reinforce this design choice. The revised manuscript will add a short discussion and comparison that reports training stability metrics, gradient-norm behavior, and performance differences versus a sparse Top-k variant, with particular attention to compositional degradation cases. This will provide concrete evidence for the reliability of the dense assembly. revision: yes
Circularity Check
No significant circularity; new architectural proposal with empirical validation
full rationale
The paper proposes a novel Continuous Expert Assembly (CEA) framework that introduces new components including a Cross-Attention Hyper-Adapter for synthesizing instance-conditioned low-rank routing bases and residual directions, followed by dense signed dot-product assembly. No equations, fitted parameters, or derivations are presented that reduce by construction to prior inputs, self-citations, or renamed known results. Claims rest on empirical gains over baselines on AIO-3, AIO-5, and CDD-11 rather than any load-bearing mathematical chain that loops back to the method's own definitions. This is a standard case of an independent architectural contribution.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Cross-Attention Hyper-Adapter
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Lora-ir: taming low-rank experts for efficient all-in-one image restoration,
Yuang Ai, Huaibo Huang, and Ran He. Lora-ir: Taming low-rank experts for efficient all-in-one image restoration.arXiv preprint arXiv:2410.15385, 2024. doi: 10.48550/arXiv.2410.15385
-
[3]
Taming Transformers for High-Resolution Image Synthesis , booktitle =
Hanting Chen, Yunhe Wang, Tianyu Guo, Chang Xu, Yiping Deng, Zhenhua Liu, Siwei Ma, Chunjing Xu, Chao Xu, and Wen Gao. Pre-trained image processing transformer. In2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12294– 12305, 2021. doi: 10.1109/CVPR46437.2021.01212
-
[4]
Hinet: Half instance normalization network for image restoration
Liangyu Chen, Xin Lu, Jie Zhang, Xiaojie Chu, and Chengpeng Chen. Hinet: Half instance normalization network for image restoration. In2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 182–192, June 2021. doi: 10.1109/ CVPRW53098.2021.00027
-
[5]
Dvs-voltmeter: Stochastic process-based event simulator for dynamic vision sensors,
Liangyu Chen, Xiaojie Chu, Xiangyu Zhang, and Jian Sun. Simple baselines for image restora- tion. InComputer Vision – ECCV 2022, pages 17–33, 2022. doi: 10.1007/978-3-031-20071-7\ _2
-
[6]
nuScenes: A multimodal dataset for autonomous driving,
Yinpeng Chen, Xiyang Dai, Mengchen Liu, Dongdong Chen, Lu Yuan, and Zicheng Liu. Dynamic convolution: Attention over convolution kernels. In2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 11027–11036, 2020. doi: 10.1109/ CVPR42600.2020.01104
-
[7]
Cross aggregation transformer for image restoration
Zheng Chen, Yulun Zhang, Jinjin Gu, Yongbing Zhang, Linghe Kong, and Xin Yuan. Cross aggregation transformer for image restoration. InAdvances in Neural Information Processing Systems (NeurIPS), volume 35, pages 25478–25490, 2022
2022
-
[8]
Colwell, and Adrian Weller
Krzysztof Choromanski, Valerii Likhosherstov, David Dohan, Xingyou Song, Andreea Gane, Tamás Sarlós, Peter Hawkins, Jared Davis, Afroz Mohiuddin, Lukasz Kaiser, David Belanger, Lucy J. Colwell, and Adrian Weller. Rethinking attention with performers. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[9]
Conde, Gregor Geigle, and Radu Timofte
Marcos V . Conde, Gregor Geigle, and Radu Timofte. Instructir: High-quality image restoration following human instructions. InComputer Vision – ECCV 2024, pages 1–21, 2024. doi: 10.1007/978-3-031-72764-1\_1
-
[10]
Dynamic filter net- works
Bert De Brabandere, Xu Jia, Tinne Tuytelaars, and Luc Van Gool. Dynamic filter net- works. InAdvances in Neural Information Processing Systems (NeurIPS), page 667–675,
-
[11]
10.48550/arXiv.1605.09673
-
[12]
FD-GAN: Generative adversarial networks with fusion-discriminator for single image dehazing
Yu Dong, Yihao Liu, He Zhang, Shifeng Chen, and Yu Qiao. FD-GAN: Generative adversarial networks with fusion-discriminator for single image dehazing. InProceedings of the AAAI Conference on Artificial Intelligence, 2020. doi: 10.1609/aaai.v34i07.6701
-
[13]
Uniprocessor: A text-induced unified low-level image processor
Huiyu Duan, Xiongkuo Min, Sijing Wu, Wei Shen, and Guangtao Zhai. Uniprocessor: A text-induced unified low-level image processor. InComputer Vision – ECCV 2024, pages 180–199, 2024. doi: 10.1007/978-3-031-72855-6\_11. 10
-
[14]
Qingnan Fan, Dongdong Chen, Lu Yuan, Gang Hua, Nenghai Yu, and Baoquan Chen. A general decoupled learning framework for parameterized image operators.IEEE Transactions on Pattern Analysis and Machine Intelligence, 43:33–47, 2021. doi: 10.1109/TPAMI.2019.2925793
-
[15]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23 (120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23 (120):1–39, 2022
2022
-
[16]
Dynamic scene deblurring with parameter selective sharing and nested skip connections
Hongyun Gao, Xin Tao, Xiaoyong Shen, and Jiaya Jia. Dynamic scene deblurring with parameter selective sharing and nested skip connections. In2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 3843–3851, 2019. URL 10.1109/ CVPR.2019.00397
-
[17]
Parameter efficient adaptation for image restoration with heterogeneous mixture-of-experts
Hang Guo, Tao Dai, Yuanchao Bai, Bin Chen, Xudong Ren, Zexuan Zhu, and Shu-Tao Xia. Parameter efficient adaptation for image restoration with heterogeneous mixture-of-experts. In Advances in Neural Information Processing Systems (NeurIPS), pages 13522–13547, 2024. doi: 10.52202/079017-0432
-
[18]
Mambair: A simple baseline for image restoration with state-space model
Hang Guo, Jinmin Li, Tao Dai, Zhihao Ouyang, Xudong Ren, and Shu-Tao Xia. Mambair: A simple baseline for image restoration with state-space model. InComputer Vision – ECCV 2024, 2024. doi: 10.1007/978-3-031-72649-1\_13
-
[19]
Onerestore: A universal restoration framework for composite degradation
Yu Guo, Yuan Gao, Yuxu Lu, Huilin Zhu, Ryan Wen Liu, and Shengfeng He. Onerestore: A universal restoration framework for composite degradation. InComputer Vision – ECCV 2024, pages 255–272, 2025. doi: 10.1007/978-3-031-72655-2\_15
-
[20]
David Ha, Andrew Dai, and Quoc V . Le. Hypernetworks. InInternational Conference on Learning Representations (ICLR), 2017
2017
-
[21]
Parameter-efficient transfer learning for NLP
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin De Laroussilhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient transfer learning for NLP. InProceedings of the 36th International Conference on Machine Learning (ICML), volume 97, pages 2790–2799, 2019
2019
-
[22]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. In International Conference on Learning Representations (ICLR), 2022. doi: 10.48550/arXiv.2106. 09685
-
[23]
In: Proceedings of the IEEE/CVF ICCV, pp
Liming Jiang, Bo Dai, Wayne Wu, and Chen Change Loy. Focal frequency loss for image reconstruction and synthesis. In2021 IEEE/CVF International Conference on Computer Vision (ICCV), pages 13899–13909, October 2021. doi: 10.1109/ICCV48922.2021.01366
-
[24]
Jeya Maria Jose Valanarasu, Rajeev Yasarla, and Vishal M. Patel. Transweather: Transformer- based restoration of images degraded by adverse weather conditions. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2343–2353, 2022. doi: 10.1109/CVPR52688.2022.00239
-
[25]
Transformers are RNNs: Fast autoregressive transformers with linear attention
Angelos Katharopoulos, Apoorv Vyas, Nikolaos Pappas, and François Fleuret. Transformers are RNNs: Fast autoregressive transformers with linear attention. InProceedings of the 37th International Conference on Machine Learning, volume 119 ofProceedings of Machine Learning Research, pages 5156–5165, 2020
2020
-
[26]
Adam: A Method for Stochastic Optimization
Diederik P. Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014. doi: 10.48550/arXiv.1412.6980
work page internal anchor Pith review doi:10.48550/arxiv.1412.6980 2014
-
[27]
Gshard: Scaling giant models with condi- tional computation and automatic sharding
Dmitry Lepikhin, HyoukJoong Lee, Yuanzhong Xu, Dehao Chen, Orhan Firat, Yanping Huang, Maxim Krikun, Noam Shazeer, and Zhifeng Chen. Gshard: Scaling giant models with condi- tional computation and automatic sharding. InInternational Conference on Learning Represen- tations (ICLR), 2021. 11
2021
-
[28]
Boyun Li, Xiao Liu, Peng Hu, Zhongqin Wu, Jiancheng Lv, and Xi Peng. All-in-one image restoration for unknown corruption. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17431–17441, 2022. doi: 10.1109/CVPR52688.2022. 01693
-
[29]
arXiv preprint arXiv:2312.05038 (2023) MMFE-IR 17
Zilong Li, Yiming Lei, Chenglong Ma, Junping Zhang, and Hongming Shan. Prompt-in- prompt learning for universal image restoration.arXiv preprint arXiv:2312.05038, 2023. doi: 10.48550/arXiv.2312.05038
-
[30]
Swinir: Image restoration using swin transformer
Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, and Radu Timofte. Swinir: Image restoration using swin transformer. In2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW), pages 1833–1844, 2021. doi: 10.1109/ICCVW54120. 2021.00210
-
[31]
TAPE: Task-agnostic prior embedding for image restoration
Lin Liu, Lingxi Xie, Xiaopeng Zhang, Shanxin Yuan, Xiangyu Chen, Wengang Zhou, Houqiang Li, and Qi Tian. TAPE: Task-agnostic prior embedding for image restoration. InComputer Vision – ECCV 2022, 2022. doi: 10.1007/978-3-031-19797-0\_26
-
[32]
F., Cheng, K.-T., and Chen, M.-H
Shih-Yang Liu, Chien-Yi Wang, Hongxu Yin, Pavlo Molchanov, Yu-Chiang Frank Wang, Kwang-Ting Cheng, and Min-Hung Chen. DoRA: Weight-decomposed low-rank adaptation. In Proceedings of the 41st International Conference on Machine Learning (ICML), volume 235, pages 32100–32121, 2024. doi: 10.48550/arXiv.2402.09353
-
[33]
Gustafsson, Zheng Zhao, Jens Sjölund, and Thomas B
Ziwei Luo, Fredrik K. Gustafsson, Zheng Zhao, Jens Sjölund, and Thomas B. Schön. Controlling vision-language models for multi-task image restoration. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[35]
Ben Mildenhall, Jonathan T. Barron, Jiawen Chen, Dillon Sharlet, Ren Ng, and Robert Carroll. Burst denoising with kernel prediction networks. In2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 2502–2510, 2018. doi: 10.1109/CVPR.2018. 00265
-
[36]
Chong Mou, Qian Wang, and Jian Zhang. Deep generalized unfolding networks for image restoration. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. doi: 10.1109/CVPR52688.2022.01688
-
[37]
Ozan Özdenizci and Robert Legenstein. Restoring vision in adverse weather conditions with patch-based denoising diffusion models.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(8):10346–10357, 2023. doi: 10.1109/TPAMI.2023.3238179
-
[38]
Vaishnav Potlapalli, Syed Waqas Zamir, Salman H. Khan, and Fahad Shahbaz Khan. Promptir: prompting for all-in-one blind image restoration. InAdvances in Neural Information Processing Systems (NeurIPS), pages 71275–71293, 2023. doi: 10.52202/075280-3121
-
[39]
From sparse to soft mixtures of experts
Joan Puigcerver, Carlos Riquelme Ruiz, Basil Mustafa, and Neil Houlsby. From sparse to soft mixtures of experts. InInternational Conference on Learning Representations, pages 28435–28445, 2024
2024
-
[40]
Bin Ren, Yawei Li, Xu Zheng, Yuqian Fu, Danda Pani Paudel, Hong Liu, Ming-Hsuan Yang, Luc Van Gool, and Nicu Sebe. Efficient degradation-agnostic image restoration via channel-wise functional decomposition and manifold regularization.arXiv preprint arXiv:2505.18679, 2026. doi: 10.48550/arXiv.2505.18679
-
[41]
Scaling vision with sparse mixture of experts
Carlos Riquelme, Joan Puigcerver, Basil Mustafa, Maxim Neumann, Rodolphe Jenatton, An- dré Susano Pinto, Daniel Keysers, and Neil Houlsby. Scaling vision with sparse mixture of experts. InAdvances in Neural Information Processing Systems (NeurIPS), pages 8583–8595,
-
[42]
10.48550/arXiv.2106.05974. 12
-
[43]
David Serrano-Lozano, Luis Herranz, Shaolin Su, and Javier Vazquez-Corral. Adaptive blind all-in-one image restoration.arXiv preprint arXiv:2411.18412, 2025. doi: 10.48550/arXiv. 2411.18412
work page internal anchor Pith review doi:10.48550/arxiv 2025
-
[44]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc V . Le, Geoffrey E. Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture- of-experts layer. InInternational Conference on Learning Representations (ICLR), 2017. 10.48550/arXiv.1701.06538
work page internal anchor Pith review doi:10.48550/arxiv.1701.06538 2017
-
[45]
Localized gaussian splatting editing with contextual awareness
Zhuoran Shen, Mingyuan Zhang, Haiyu Zhao, Shuai Yi, and Hongsheng Li. Efficient attention: Attention with linear complexities. In2021 IEEE Winter Conference on Applications of Computer Vision (WACV), pages 3530–3538, 2021. doi: 10.1109/W ACV48630.2021.00357
work page doi:10.1109/w 2021
-
[46]
Image denoising using deep CNN with batch renormalization.Neural Networks, 121:461–473, 2020
Chunwei Tian, Yong Xu, and Wangmeng Zuo. Image denoising using deep CNN with batch renormalization.Neural Networks, 121:461–473, 2020. doi: 10.1016/j.neunet.2019.08.022
-
[47]
Zhengzhong Tu, Hossein Talebi, Han Zhang, Feng Yang, Peyman Milanfar, Alan Bovik, and Yinxiao Li. MAXIM: Multi-axis MLP for image processing. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5759–5770, 2022. doi: 10.1109/ CVPR52688.2022.00568
-
[48]
Tao Wang, Kaihao Zhang, Ziqian Shao, Wenhan Luo, Bjorn Stenger, Tong Lu, Tae-Kyun Kim, Wei Liu, and Hongdong Li. Gridformer: Residual dense transformer with grid structure for image restoration in adverse weather conditions.International Journal of Computer Vision, 132:4541–4563, 2024. doi: 10.1007/s11263-024-02056-0
-
[49]
Uformer: A general u-shaped transformer for image restoration
Zhendong Wang, Xiaodong Cun, Jianmin Bao, Wengang Zhou, Jianzhuang Liu, and Houqiang Li. Uformer: A general u-shaped transformer for image restoration. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 17662–17672, June
-
[50]
doi: 10.1109/CVPR52688.2022.01716
-
[51]
Harmony in diversity: Improving all-in-one image restoration via multi-task collaboration
Gang Wu, Junjun Jiang, Kui Jiang, and Xianming Liu. Harmony in diversity: Improving all-in-one image restoration via multi-task collaboration. InProceedings of the 32nd ACM International Conference on Multimedia, 2024. doi: 10.1145/3664647.3680762
-
[52]
Le, and Jiquan Ngiam
Brandon Yang, Gabriel Bender, Quoc V . Le, and Jiquan Ngiam. Condconv: conditionally parameterized convolutions for efficient inference. In Hanna M. Wallach, Hugo Larochelle, Alina Beygelzimer, Florence d’Alché Buc, Emily B. Fox, and Roman Garnett, editors,Advances in Neural Information Processing Systems (NeurIPS), pages 1307–1318, 2019
2019
-
[53]
In: IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR)
Eduard Zamfir, Zongwei Wu, Nancy Mehta, Yuedong Tan, Danda Pani Paudel, Yulun Zhang, and Radu Timofte. Complexity experts are task-discriminative learners for any image restoration. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 12753–12763, 2025. doi: 10.1109/CVPR52734.2025.01190
-
[54]
Taming Transformers for High-Resolution Image Synthesis , booktitle =
Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, Ming- Hsuan Yang, and Ling Shao. Multi-stage progressive image restoration. In2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 14816–14826, 2021. doi: 10.1109/CVPR46437.2021.01458
-
[55]
Syed Waqas Zamir, Aditya Arora, Salman Khan, Munawar Hayat, Fahad Shahbaz Khan, and Ming-Hsuan Yang. Restormer: Efficient transformer for high-resolution image restoration. In2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5728–5739, 2022. doi: 10.1109/CVPR52688.2022.00564
-
[56]
In: IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR)
Haijin Zeng, Xiangming Wang, Yongyong Chen, Jingyong Su, and Jie Liu. Vision-language gradient descent-driven all-in-one deep unfolding networks. In2025 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2025. doi: 10.1109/CVPR52734.2025. 00705
-
[57]
Ingredient-oriented multi-degradation learning for image restoration
Jinghao Zhang, Jie Huang, Mingde Yao, Zizheng Yang, Hu Yu, Man Zhou, and Feng Zhao. Ingredient-oriented multi-degradation learning for image restoration. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 5825–5835. IEEE,
-
[58]
doi: 10.1109/CVPR52729.2023.00564. 13
-
[59]
Kai Zhang, Wangmeng Zuo, Yunjin Chen, Deyu Meng, and Lei Zhang. Beyond a gaussian denoiser: Residual learning of deep cnn for image denoising.IEEE Transactions on Image Processing, 26(7):3142–3155, 2017. doi: 10.1109/TIP.2017.2662206
-
[60]
AdaLoRA: Adaptive Budget Allocation for Parameter-Efficient Fine-Tuning
Qingru Zhang, Minshuo Chen, Alexander Bukharin, Nikos Karampatziakis, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adaptive budget allocation for parameter- efficient fine-tuning. InInternational Conference on Learning Representations (ICLR), 2023. 10.48550/arXiv.2303.10512
work page internal anchor Pith review doi:10.48550/arxiv.2303.10512 2023
-
[61]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)
Yurui Zhu, Tianyu Wang, Xueyang Fu, Xuanyu Yang, Xin Guo, Jifeng Dai, Yu Qiao, and Xiaowei Hu. Learning weather-general and weather-specific features for image restoration under multiple adverse weather conditions. In2023 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 21747–21758, 2023. doi: 10.1109/CVPR52729.2023. 02083. A A...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.