Recognition: unknown
BUILD-AND-FIND: An Effort-Aware Protocol for Evaluating Agent-Managed Codebases
Pith reviewed 2026-05-08 08:54 UTC · model grok-4.3
The pith
The BUILD-AND-FIND protocol evaluates whether downstream agents can recover intended design choices from generated code repositories and how much inspection effort that recovery requires.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
BUILD-AND-FIND separates behavioral correctness from artifact-side recovery by having a builder create a codebase from a hidden repository specification and a finder recover the intended choices using only the codebase and a traced question bank. It reports recovery accuracy, repeatability, implementation coverage, and inspection effort, with accuracy and stability acting as gates so effort is only interpreted when recovery succeeds reliably. Question-only and spec-only controls quantify generic priors and direct specification access, while audits separate omitted claims from finder failures and verify that correct answers cite artifact evidence.
What carries the argument
The BUILD-AND-FIND protocol, consisting of a builder who sees a hidden repository specification, a finder who sees only the generated codebase plus a specification-traced multiple-choice question bank, and metrics that gate effort behind reliable recovery accuracy.
If this is right
- Repositories that pass behavioral tests can still be ranked by how clearly they expose their design choices to future agents.
- Lower inspection effort for the same recovery accuracy indicates that one artifact makes the intended choices easier to locate than another.
- The protocol enables comparison of agent-generated codebases on communication quality once behavioral performance is saturated.
- Audits can distinguish design claims that were never implemented from claims that are present but hard to find.
Where Pith is reading between the lines
- Agents might be prompted or trained to generate code that minimizes future inspection effort, not just passes tests.
- The approach could extend to other persistent artifacts such as documentation or configuration files where clarity of intent matters.
- It reframes code as a communication medium between agents rather than a one-shot executable output.
Load-bearing premise
The specification-traced multiple-choice question bank faithfully captures the hidden repository specification and intended design choices without introducing its own biases or omissions.
What would settle it
If independent finders achieve near-saturation accuracy on the question bank when given a codebase that does not implement the specification, or if audits show that correct answers cite no specific evidence from the artifact, the protocol would fail to measure recovery from the generated repository.
Figures






read the original abstract
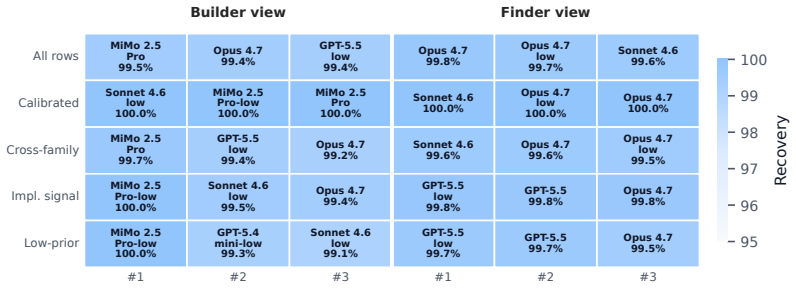
Most coding-agent benchmarks ask whether generated code behaves correctly. That remains essential, but repository-level engineering is increasingly agent-managed: one agent writes a repository, and later agents inspect, audit, or extend it as working context. In that setting, a generated repository is not only an answer to a task but also a communication artifact for future work. Even when strong agents nearly satisfy the visible behavioral objective, repositories can differ in how clearly they expose the intended behavior and design choices behind that behavior. We introduce BUILD-AND-FIND, a protocol for evaluating whether downstream agents can recover those intended choices from generated repositories, and how much inspection that recovery requires. For each task, a builder sees a hidden repository specification and creates a codebase; a finder sees only the codebase and a specification-traced multiple-choice question bank. The protocol separates behavioral correctness from artifact-side recovery and reports recovery accuracy, repeatability, implementation coverage, and inspection effort. Accuracy and stability act as gates: effort is interpreted only when recovery succeeds reliably. Among artifacts from which the same intent can be recovered, lower effort by the same finder suggests that the artifact makes that intent easier to locate. Question-only and spec-only controls quantify generic priors and specification access, while audits separate omitted claims from finder failures and check whether correct answers cite artifact evidence. In the released high-prior task pack, recovery accuracy is near saturation, so inspection effort and finder-specific effects provide the main panel-local comparison.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces BUILD-AND-FIND, a protocol for evaluating agent-managed codebases. A builder agent creates a repository from a hidden specification; a finder agent, given only the generated codebase and a specification-traced multiple-choice question bank, recovers the intended design choices. The protocol reports recovery accuracy, repeatability, implementation coverage, and inspection effort, with accuracy and stability serving as gates before interpreting effort. It includes question-only and spec-only controls to quantify priors and specification access, plus audits to separate omitted claims from finder failures and to verify that correct answers cite artifact evidence. In the released high-prior task pack, recovery accuracy is reported as near saturation.
Significance. If the protocol's assumptions hold, it would address a growing need in software engineering to evaluate not only functional correctness of agent-generated code but also how clearly repositories communicate design intent for downstream agent use. The separation of behavioral correctness from artifact-side recovery, combined with effort metrics and explicit controls, offers a structured approach to comparing repository clarity. The release of a high-prior task pack with near-saturation accuracy provides a concrete starting point for comparisons, though the protocol's value for effort-based claims hinges on validation of the question bank.
major comments (1)
- [Abstract] Abstract: The protocol's central claim that lower inspection effort indicates clearer artifact communication of intent (when recovery succeeds reliably) is load-bearing on the fidelity of the specification-traced MCQ bank as a complete, unbiased proxy for the hidden repository specification. While the abstract describes question-only and spec-only controls plus audits for omitted claims, it supplies no explicit coverage metric, inter-annotator agreement, or construction protocol for the question bank, leaving effort comparisons conditional on an unverified mapping from spec to questions.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting the need for greater explicitness in the abstract regarding the MCQ bank. We address the major comment below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The protocol's central claim that lower inspection effort indicates clearer artifact communication of intent (when recovery succeeds reliably) is load-bearing on the fidelity of the specification-traced MCQ bank as a complete, unbiased proxy for the hidden repository specification. While the abstract describes question-only and spec-only controls plus audits for omitted claims, it supplies no explicit coverage metric, inter-annotator agreement, or construction protocol for the question bank, leaving effort comparisons conditional on an unverified mapping from spec to questions.
Authors: We agree that the abstract would be strengthened by briefly referencing the MCQ bank's construction protocol, coverage metric, and inter-annotator agreement to better support the central claim about effort as a proxy for clarity. The full manuscript provides these details in the methods and validation sections, including how questions are directly traced from specification elements, the resulting coverage of specification content, and agreement statistics among annotators, along with the audits for omitted claims. To make this information accessible at the abstract level and remove any appearance of an unverified mapping, we will revise the abstract to include a concise clause summarizing the question-bank construction and validation steps. This change will be limited to the abstract and will not alter the underlying protocol or results. revision: yes
Circularity Check
No circularity: methodological protocol with no derivations or self-referential reductions
full rationale
The paper introduces BUILD-AND-FIND as a new evaluation protocol separating behavioral correctness from artifact-side recovery of intent via a specification-traced MCQ bank, with controls for priors and audits for omissions. No equations, fitted parameters, predictions, or derivation chains exist that could reduce to inputs by construction. The work contains no self-citations of prior uniqueness theorems or ansatzes by the same author, and the central claims rest on the protocol definition plus reported observations in the released task pack rather than tautological mappings. The MCQ bank is presented as an explicit design choice with stated controls, not a hidden assumption that forces results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Recovery of intended design choices can be measured via accuracy and effort on a specification-traced multiple-choice question bank.
invented entities (1)
-
BUILD-AND-FIND protocol
no independent evidence
Reference graph
Works this paper leans on
-
[1]
doi: 10.52202/079017-2610. URL https://proceedings.neurips.cc/paper_files/paper/2024/file/ 9547b09b722f2948ff3ddb5d86002bc0-Paper-Datasets_and_Benchmarks_Track.pdf. Jacob Austin, Augustus Odena, Maxwell Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie Cai, Michael Terry, Quoc Le, and Charles Sutton. Program synthesis with large lan...
-
[2]
doi: 10.1007/s10664-023-10381-0. Raymond P. L. Buse and Westley Weimer. Learning a metric for code readability.IEEE Transactions on Software Engineering, 36(4):546–558,
-
[3]
doi: 10.1109/TSE.2009.70. Jun Shern Chan, Neil Chowdhury, Oliver Jaffe, James Aung, Dane Sherburn, Evan Mays, Giulio Starace, Kevin Liu, Leon Maksin, Tejal Patwardhan, Aleksander Madry, and Lilian Weng. MLE- bench: Evaluating machine learning agents on machine learning engineering. InInternational Conference on Learning Representations,
-
[4]
Evaluating Large Language Models Trained on Code
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, et al. Evaluating large language models trained on code.arXiv preprint arXiv:2107.03374,
work page internal anchor Pith review arXiv
-
[5]
9 Jane Cleland-Huang, Orlena C. Z. Gotel, Jane Huffman Hayes, Patrick Mäder, and Andrea Zisman. Software traceability: Trends and future directions. InFuture of Software Engineering, FOSE 2014, pages 55–69,
2014
-
[6]
doi: 10.1145/2593882.2593891. Dan Hendrycks, Steven Basart, Saurav Kadavath, Mantas Mazeika, Akul Arora, Ethan Guo, Collin Burns, Samir Puranik, Horace He, Dawn Song, and Jacob Steinhardt. Measuring coding challenge competence with APPS. InAdvances in Neural Information Processing Systems,
-
[7]
doi: 10.1145/3726302.3730262. Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Armando Solar-Lezama, Koushik Sen, and Ion Stoica. LiveCodeBench: Holistic and contamination-free eval- uation of large language models for code. InInternational Conference on Learning Representations,
-
[8]
doi: 10.1145/1368088.1368130. Andrew J. Ko and Brad A. Myers. Extracting and answering why and why not questions about Java program output.ACM Transactions on Software Engineering and Methodology, 20(2):4:1–4:36,
-
[9]
doi: 10.1145/1824760.1824761. Yuhang Lai, Chengxi Li, Yiming Wang, Tianyi Zhang, Ruiqi Zhong, Luke Zettlemoyer, Wen-tau Yih, Daniel Fried, Sida Wang, and Tao Yu. DS-1000: A natural and reliable benchmark for data science code generation. InProceedings of the 40th International Conference on Machine Learning,
-
[10]
Tianyang Liu, Canwen Xu, and Julian McAuley
doi: 10.52202/079017-4087. Tianyang Liu, Canwen Xu, and Julian McAuley. RepoBench: Benchmarking repository-level code auto-completion systems. InInternational Conference on Learning Representations, 2024a. Yue Liu, Thanh Le-Cong, Ratnadira Widyasari, Chakkrit Tantithamthavorn, Li Li, Xuan-Bach D. Le, and David Lo. Refining ChatGPT-generated code: Characte...
-
[11]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, et al. Terminal-Bench: Benchmarking agents on hard, realistic tasks in command line interfaces.arXiv preprint arXiv:2601.11868,
work page internal anchor Pith review arXiv
-
[12]
Evaluating code readability and legibility: An examination of human-centric studies
Delano Oliveira, Reydne Bruno, Fernanda Madeiral, and Fernando Castor. Evaluating code readability and legibility: An examination of human-centric studies. InProceedings of the 2020 IEEE International Conference on Software Maintenance and Evolution, pages 348–359. IEEE,
2020
-
[13]
In: IEEE International Confer- ence on Software Maintenance and Evolution
doi: 10.1109/ICSME46990.2020.00041. 10 OpenAI. Introducing SWE-bench verified. https://openai.com/index/ introducing-swe-bench-verified/,
-
[14]
Weihan Peng, Yuling Shi, Yuhang Wang, Xinyun Zhang, Beijun Shen, and Xiaodong Gu
doi: 10.1145/361598.361623. Weihan Peng, Yuling Shi, Yuhang Wang, Xinyun Zhang, Beijun Shen, and Xiaodong Gu. SWE-QA: Can language models answer repository-level code questions?arXiv preprint arXiv:2509.14635,
-
[15]
doi: 10.1145/1181775.1181779. Giulio Starace, Oliver Jaffe, Dane Sherburn, James Aung, Jun Shern Chan, Leon Maksin, Rachel Dias, Evan Mays, Benjamin Kinsella, Wyatt Thompson, Johannes Heidecke, Amelia Glaese, and Tejal Patwardhan. PaperBench: Evaluating AI’s ability to replicate AI research.arXiv preprint arXiv:2504.01848,
-
[16]
Ruiqi Wang, Jiyu Guo, Cuiyun Gao, Guodong Fan, Chun Yong Chong, and Xin Xia
doi: 10.18653/v1/2024.acl-srw.28. Ruiqi Wang, Jiyu Guo, Cuiyun Gao, Guodong Fan, Chun Yong Chong, and Xin Xia. Can LLMs replace human evaluators? an empirical study of LLM-as-a-judge in software engineering tasks. Proceedings of the ACM on Software Engineering, 2(ISSTA):1955–1977,
-
[17]
M Resource usage diagnostics Vendor token counts are reported as diagnostics
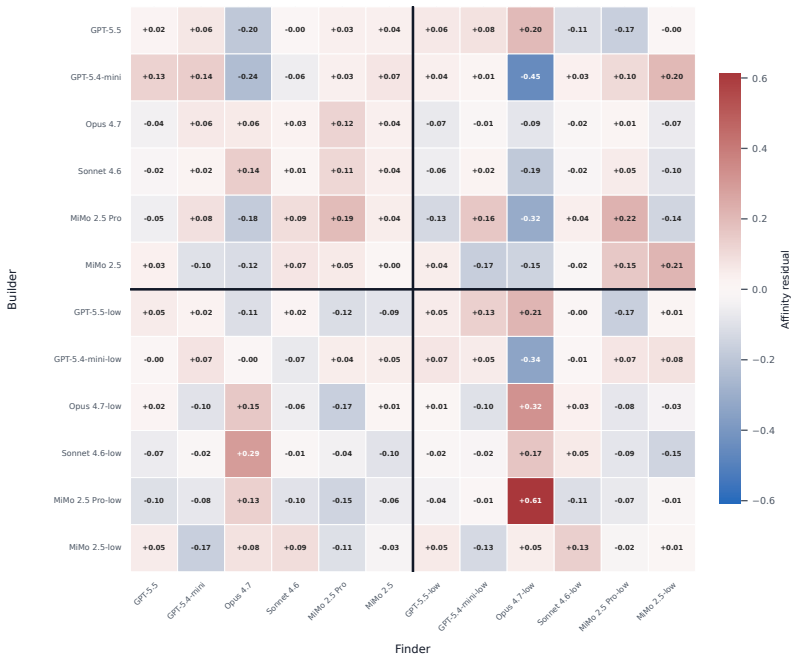
Residuals use the same matrix normalization as the main affinity diagnostic, with recovery scores recomputed on the audited low-prior question subset. M Resource usage diagnostics Vendor token counts are reported as diagnostics. They use provider-reported token totals when available, or the observed vendor-token total in the local efficiency record when p...
1922
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.