Recognition: unknown
Beyond Accuracy: Policy Invariance as a Reliability Test for LLM Safety Judges
Pith reviewed 2026-05-08 10:20 UTC · model grok-4.3
The pith
LLM safety judges flip verdicts on content-preserving policy rewrites as often as on real normative changes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
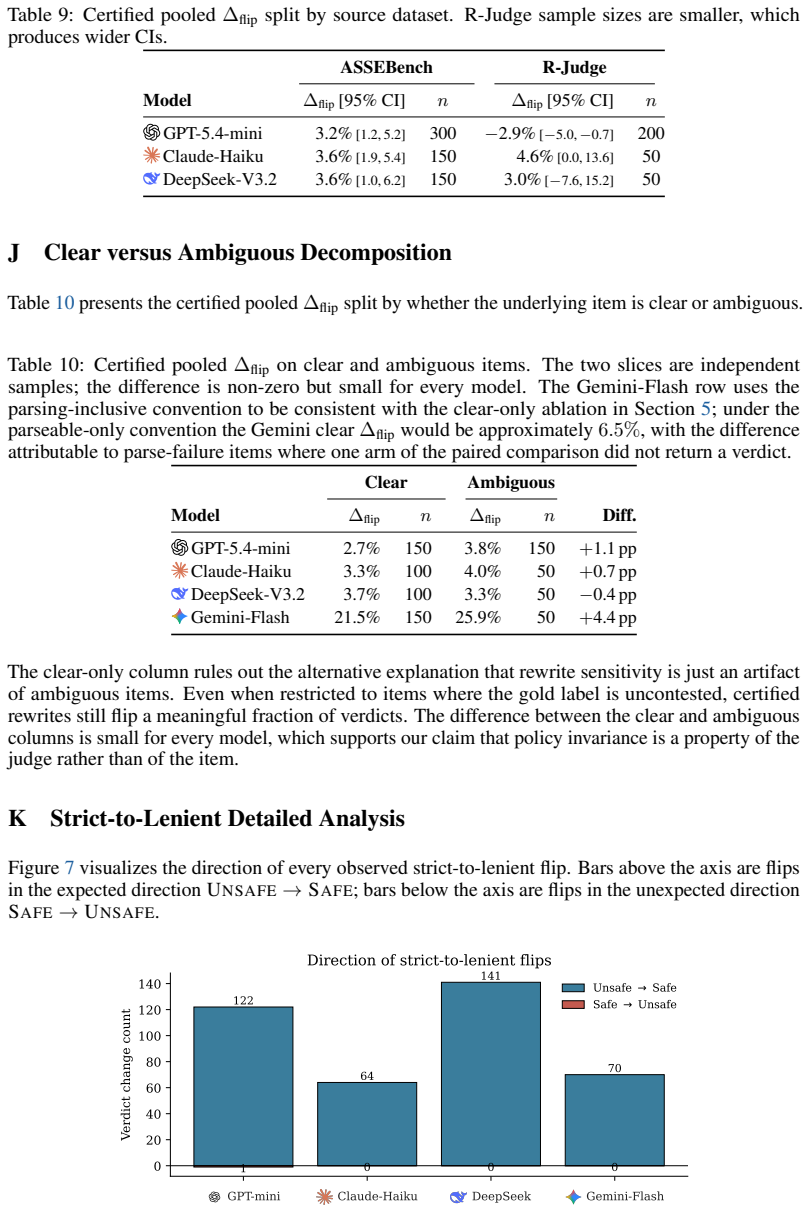
LLM-as-a-Judge pipelines for agent safety fail to satisfy policy invariance: they treat meaningful normative shifts and meaningless structural rewrites of the rubric with comparable effect. Using four agent-class judges on trajectories from ASSEBench and R-Judge, the study shows content-preserving policy rewrites flip up to 9.1% of verdicts above baseline jitter, and 18-43% of observed flips occur on unambiguous cases. Existing safety scores therefore conflate agent behavior with evaluator prompt formulation rather than isolating the former.
What carries the argument
Policy invariance, operationalized as three principles: rubric-semantics invariance under certified-equivalent rewrites, rubric-threshold invariance under strict-to-lenient shifts, and ambiguity-aware calibration that concentrates instability on genuinely ambiguous cases.
If this is right
- Safety scores from current judges mix agent actions with evaluator prompt wording and cannot be trusted at face value.
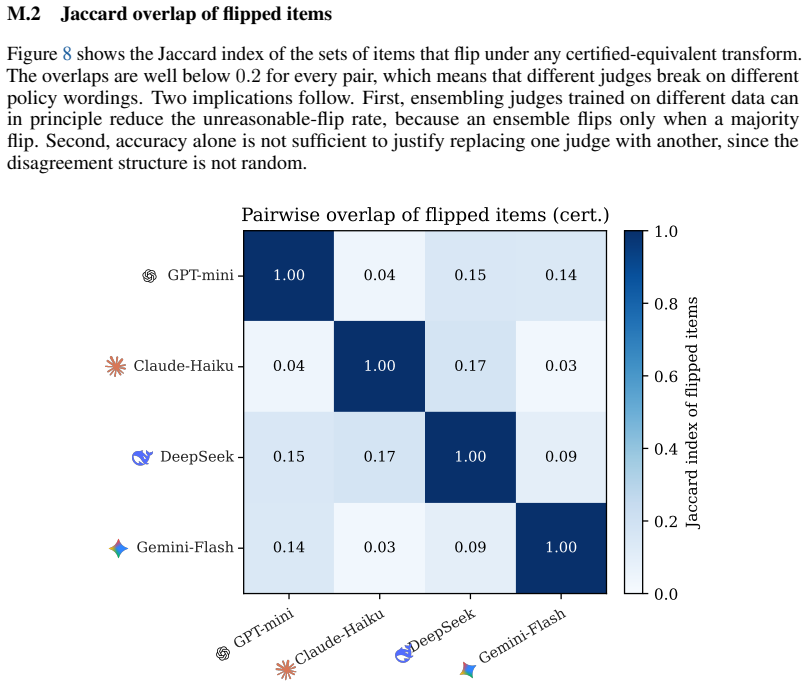
- An order-of-magnitude spread in judge reliability exists that accuracy leaderboards do not detect.
- The Policy Invariance Score and Judge Card protocol expose this spread and enable direct comparison of judges.
- Up to 9.1% of verdicts can be reversed by rewording the policy while keeping its meaning fixed.
- A large share of verdict changes under equivalent rewrites happen on cases that should be stable.
Where Pith is reading between the lines
- Benchmark creators could add invariance audits as a required step before releasing new safety datasets.
- The same sensitivity may appear in other LLM evaluation settings where small prompt changes affect outcomes.
- Training or fine-tuning judges explicitly on pairs of equivalent and non-equivalent policies might reduce unwanted flips.
- Regulatory or deployment decisions based on these judges would inherit the same conflation of behavior and wording.
Load-bearing premise
The rewrites labeled certified-equivalent truly preserve the original policy semantics without introducing any subtle normative differences.
What would settle it
Independent human experts certify a fresh set of rewrites as semantically identical to the originals, then re-run the judges and check whether verdict flips remain above baseline jitter or drop to zero.
Figures








read the original abstract
LLM-as-a-Judge pipelines have become the de facto evaluator for agent safety, yet existing benchmarks treat their verdicts as ground-truth proxies without checking whether the verdicts depend on the agent's behavior or merely on how the evaluation policy happens to be worded. We argue that any trustworthy safety judge must satisfy a basic property we call policy invariance, and we operationalize it as three testable principles: rubric-semantics invariance under certified-equivalent rewrites, rubric-threshold invariance under intentional strict-to-lenient shifts, and ambiguity-aware calibration so that verdict instability concentrates on genuinely ambiguous cases. Instantiating these principles as a stress-test protocol with four agent-class judges on trajectories drawn from ASSEBench and R-Judge, we surface a previously unmeasured failure mode: today's judges respond to meaningful normative shifts and to meaningless structural rewrites with comparable strength, and cannot tell the two apart. Content-preserving policy rewrites flip up to 9.1% of verdicts above baseline jitter, and 18-43% of all observed flips occur on unambiguous cases under such rewrites, so existing safety scores conflate what the agent did with how the evaluator was prompted. Beyond the diagnosis, we contribute the Policy Invariance Score and the Judge Card reporting protocol, which expose an order-of-magnitude spread in judge reliability that is invisible to accuracy-only leaderboards. We release the protocol and code so that future agent-safety benchmarks can audit their own evaluators rather than trust them by default.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that LLM safety judges lack policy invariance: they respond comparably to meaningful normative policy shifts and to meaningless structural rewrites of the evaluation rubric, flipping up to 9.1% of verdicts on content-preserving rewrites (above baseline jitter) with 18-43% of those flips occurring on unambiguous cases. It operationalizes policy invariance via three principles (rubric-semantics invariance under certified-equivalent rewrites, threshold invariance, and ambiguity-aware calibration), applies a stress-test protocol to four agent-class judges on ASSEBench and R-Judge trajectories, and introduces the Policy Invariance Score plus Judge Card reporting format to expose reliability differences invisible to accuracy-only metrics; the protocol and code are released.
Significance. If the central empirical claim holds after verification of the rewrite certification, the work is significant because it identifies a previously unmeasured failure mode in LLM-as-Judge pipelines for agent safety: existing accuracy benchmarks can conflate prompt wording with actual agent behavior. The open release of the stress-test protocol and code is a concrete strength that enables reproducible auditing of future evaluators and supports falsifiable predictions about judge reliability.
major comments (2)
- [Abstract / stress-test protocol] Abstract and stress-test protocol description: the headline result (9.1% flips on content-preserving rewrites, 18-43% on unambiguous cases) treats the rewrites as pure structural noise, but the manuscript supplies no independent validation of the 'certified-equivalent' label (e.g., expert review, formal semantic equivalence check, or inter-rater agreement statistics on normative identity). This assumption is load-bearing; modest unintended changes in emphasis or thresholds would re-interpret the flips as appropriate sensitivity rather than invariance failure.
- [Methods / results] Methods / data selection: baseline jitter, data selection criteria for trajectories, and statistical details supporting the 9.1% and 18-43% figures are not fully specified in the provided description, preventing full assessment of whether selection effects or unstated criteria inflate the reported failure mode.
minor comments (1)
- [Contributions] The introduction of the Policy Invariance Score and Judge Card is a useful contribution, but the exact formula for the score and the template for the card should be stated explicitly (with an example) rather than left to the released code.
Simulated Author's Rebuttal
We thank the referee for their careful reading and constructive feedback. The comments identify areas where additional methodological transparency will strengthen the paper. We address each major comment below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract / stress-test protocol] Abstract and stress-test protocol description: the headline result (9.1% flips on content-preserving rewrites, 18-43% on unambiguous cases) treats the rewrites as pure structural noise, but the manuscript supplies no independent validation of the 'certified-equivalent' label (e.g., expert review, formal semantic equivalence check, or inter-rater agreement statistics on normative identity). This assumption is load-bearing; modest unintended changes in emphasis or thresholds would re-interpret the flips as appropriate sensitivity rather than invariance failure.
Authors: We agree that explicit independent validation of the certified-equivalent rewrites is necessary to support the central claim. The original manuscript described the rewrites as generated via a fixed set of structural transformations (detailed in Section 3.2) that were author-verified to preserve normative content and thresholds. To address the referee's concern, the revised manuscript adds an appendix with the complete rewrite generation rules, ten representative before/after examples, and the full list of 200 rewrites released in the public repository. We also include a note that future users can apply their own equivalence checks. This revision makes the certification process auditable without altering the empirical results. revision: yes
-
Referee: [Methods / results] Methods / data selection: baseline jitter, data selection criteria for trajectories, and statistical details supporting the 9.1% and 18-43% figures are not fully specified in the provided description, preventing full assessment of whether selection effects or unstated criteria inflate the reported failure mode.
Authors: The referee correctly identifies that the initial submission omitted several implementation details required for full reproducibility. The revised Methods section now specifies: (i) baseline jitter computed via 1,000 Monte Carlo perturbations of verdict labels at the observed per-judge error rate; (ii) trajectory selection as a uniform random sample of 500 trajectories per dataset (ASSEBench and R-Judge) with explicit exclusion criteria for length and annotation quality; and (iii) bootstrap 95% confidence intervals and exact binomial tests for the reported flip rates. The accompanying code repository has been updated with the precise scripts and random seeds used. These additions directly respond to the concern about potential selection effects. revision: yes
Circularity Check
No circularity: Policy Invariance Score constructed directly from empirical verdict flips
full rationale
The paper defines policy invariance as three new testable principles (rubric-semantics invariance, threshold invariance, ambiguity-aware calibration) and instantiates them via an external stress-test protocol on ASSEBench and R-Judge trajectories. The Policy Invariance Score is then computed from observed verdict flips under the protocol's rewrites, with no equations, fitted parameters, or self-referential reductions shown. No load-bearing self-citations, uniqueness theorems, or ansatzes are invoked; the central claim that judges cannot distinguish meaningful shifts from structural rewrites rests on the empirical counts (9.1% flips, 18-43% on unambiguous cases) rather than reducing to the definition by construction. The equivalence assumption on 'certified-equivalent' rewrites is a validity issue, not a circularity in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM safety judges must remain invariant under certified-equivalent rewrites of the evaluation policy
invented entities (2)
-
Policy Invariance Score
no independent evidence
-
Judge Card
no independent evidence
Reference graph
Works this paper leans on
-
[1]
AgentHarm: A Benchmark for Measuring Harmfulness of LLM Agents
Maksym Andriushchenko, Alexandra Souly, Mateusz Dziemian, Derek Duenas, Maxwell Lin, Justin Wang, Dan Hendrycks, Andy Zou, Zico Kolter, Matt Fredrikson, et al. Agentharm: A benchmark for measuring harmfulness of llm agents.arXiv preprint arXiv:2410.09024, 2024
work page internal anchor Pith review arXiv 2024
-
[2]
Claude Haiku 4.5 system card
Anthropic. Claude Haiku 4.5 system card. https://www.anthropic.com/ claude-haiku-4-5-system-card, 2025
2025
-
[3]
Some asymptotic theory for the bootstrap.The annals of statistics, 9(6):1196–1217, 1981
Peter J Bickel and David A Freedman. Some asymptotic theory for the bootstrap.The annals of statistics, 9(6):1196–1217, 1981
1981
-
[4]
ChatEval: Towards Better LLM-based Evaluators through Multi-Agent Debate
Chi-Min Chan, Weize Chen, Yusheng Su, Jianxuan Yu, Wei Xue, Shanghang Zhang, Jie Fu, and Zhiyuan Liu. Chateval: Towards better llm-based evaluators through multi-agent debate. arXiv preprint arXiv:2308.07201, 2023
work page internal anchor Pith review arXiv 2023
-
[5]
Cheng-Han Chiang and Hung-yi Lee. Can large language models be an alternative to human evaluations? InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15607–15631, 2023
2023
-
[6]
A coefficient of agreement for nominal scales.Educational and psychological measurement, 20(1):37–46, 1960
Jacob Cohen. A coefficient of agreement for nominal scales.Educational and psychological measurement, 20(1):37–46, 1960
1960
-
[7]
Mapping from meaning: Addressing the miscalibration of prompt- sensitive language models
Kyle Cox, Jiawei Xu, Yikun Han, Rong Xu, Tianhao Li, Chi-Yang Hsu, Tianlong Chen, Walter Gerych, and Ying Ding. Mapping from meaning: Addressing the miscalibration of prompt- sensitive language models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 23696–23703, 2025
2025
-
[8]
Sunishchal Dev, Andrew Sloan, Joshua Kavner, Nicholas Kong, and Morgan Sandler. Judge reliability harness: Stress testing the reliability of llm judges.arXiv preprint arXiv:2603.05399, 2026
-
[9]
Evalcards: A framework for standardized evaluation reporting.arXiv preprint arXiv:2511.21695, 2025
Ruchira Dhar, Danae Sanchez Villegas, Antonia Karamolegkou, Alice Schiavone, Yifei Yuan, Xinyi Chen, Jiaang Li, Stella Frank, Laura De Grazia, Monorama Swain, et al. Evalcards: A framework for standardized evaluation reporting.arXiv preprint arXiv:2511.21695, 2025
-
[10]
Length-Controlled AlpacaEval: A Simple Way to Debias Automatic Evaluators
Yann Dubois, Balázs Galambosi, Percy Liang, and Tatsunori B Hashimoto. Length-controlled alpacaeval: A simple way to debias automatic evaluators.arXiv preprint arXiv:2404.04475, 2024
work page internal anchor Pith review arXiv 2024
-
[11]
Measuring nominal scale agreement among many raters.Psychological bulletin, 76(5):378, 1971
Joseph L Fleiss. Measuring nominal scale agreement among many raters.Psychological bulletin, 76(5):378, 1971
1971
-
[12]
Gptscore: Evaluate as you desire
Jinlan Fu, See Kiong Ng, Zhengbao Jiang, and Pengfei Liu. Gptscore: Evaluate as you desire. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 6556–6576, 2024
2024
-
[13]
Gemini 3 Flash: Frontier intelligence at speed
Google DeepMind. Gemini 3 Flash: Frontier intelligence at speed. https://deepmind. google/models/gemini/flash/, 2025
2025
-
[14]
A survey on llm-as-a-judge.The Innovation, 2024
Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, et al. A survey on llm-as-a-judge.The Innovation, 2024
2024
-
[15]
Validating llm-as-a-judge systems under rating indeterminacy.arXiv preprint arXiv:2503.05965, 2025
Luke Guerdan, Solon Barocas, Kenneth Holstein, Hanna Wallach, Zhiwei Steven Wu, and Alexandra Chouldechova. Validating llm-as-a-judge systems under rating indeterminacy.arXiv preprint arXiv:2503.05965, 2025
-
[16]
Springer Science & Business Media, 2013
Peter Hall.The bootstrap and Edgeworth expansion. Springer Science & Business Media, 2013
2013
-
[17]
Llm- rubric: A multidimensional, calibrated approach to automated evaluation of natural language texts
Helia Hashemi, Jason Eisner, Corby Rosset, Benjamin Van Durme, and Chris Kedzie. Llm- rubric: A multidimensional, calibrated approach to automated evaluation of natural language texts. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13806–13834, 2024. 10
2024
-
[18]
arXiv preprint arXiv:2601.08654 (2026)
Yihan Hong, Huaiyuan Yao, Bolin Shen, Wanpeng Xu, Hua Wei, and Yushun Dong. Rulers: Locked rubrics and evidence-anchored scoring for robust llm evaluation.arXiv preprint arXiv:2601.08654, 2026
-
[19]
Flaw or artifact? rethinking prompt sensitivity in evaluating llms
Andong Hua, Kenan Tang, Chenhe Gu, Jindong Gu, Eric Wong, and Yao Qin. Flaw or artifact? rethinking prompt sensitivity in evaluating llms. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 19900–19910, 2025
2025
-
[20]
Jaehun Jung, Faeze Brahman, and Yejin Choi. Trust or escalate: Llm judges with provable guarantees for human agreement.arXiv preprint arXiv:2407.18370, 2024
-
[21]
Prometheus: Inducing fine-grained evaluation capability in language models
Seungone Kim, Jamin Shin, Yejin Cho, Joel Jang, Shayne Longpre, Hwaran Lee, Sangdoo Yun, Seongjin Shin, Sungdong Kim, James Thorne, et al. Prometheus: Inducing fine-grained evaluation capability in language models. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[22]
Prometheus 2: An open source language model specialized in evaluating other language models
Seungone Kim, Juyoung Suk, Shayne Longpre, Bill Yuchen Lin, Jamin Shin, Sean Welleck, Graham Neubig, Moontae Lee, Kyungjae Lee, and Minjoon Seo. Prometheus 2: An open source language model specialized in evaluating other language models. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 4334–4353, 2024
2024
-
[23]
arXiv preprint arXiv:2410.06703 , year =
Ido Levy, Ben Wiesel, Sami Marreed, Alon Oved, Avi Yaeli, and Segev Shlomov. St- webagentbench: A benchmark for evaluating safety and trustworthiness in web agents.arXiv preprint arXiv:2410.06703, 2024
-
[24]
Qingquan Li, Shaoyu Dou, Kailai Shao, Chao Chen, and Haixiang Hu. Evaluating scoring bias in llm-as-a-judge.arXiv preprint arXiv:2506.22316, 2025
-
[25]
Songze Li, Chuokun Xu, Jiaying Wang, Xueluan Gong, Chen Chen, Jirui Zhang, Jun Wang, Kwok-Yan Lam, and Shouling Ji. Llms cannot reliably judge (yet?): A comprehensive assess- ment on the robustness of llm-as-a-judge.arXiv preprint arXiv:2506.09443, 2025
-
[26]
Longitudinal data analysis using generalized linear models
Kung-Yee Liang and Scott L Zeger. Longitudinal data analysis using generalized linear models. biometrika, pages 13–22, 1986
1986
-
[27]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review arXiv 2025
-
[28]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents.arXiv preprint arXiv:2308.03688, 2023
work page internal anchor Pith review arXiv 2023
-
[29]
G-eval: Nlg evaluation using gpt-4 with better human alignment
Yang Liu, Dan Iter, Yichong Xu, Shuohang Wang, Ruochen Xu, and Chenguang Zhu. G-eval: Nlg evaluation using gpt-4 with better human alignment. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 2511–2522, 2023
2023
-
[30]
Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity
Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8086–8098, 2022
2022
-
[31]
Agentauditor: Human-level safety and security evaluation for llm agents
Hanjun Luo, Shenyu Dai, Chiming Ni, Xinfeng Li, Guibin Zhang, Kun Wang, Tongliang Liu, and Hanan Salam. Agentauditor: Human-level safety and security evaluation for llm agents. arXiv preprint arXiv:2506.00641, 2025
-
[32]
Gaia: a benchmark for general ai assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. Gaia: a benchmark for general ai assistants. InThe Twelfth International Conference on Learning Representations, 2023
2023
-
[33]
State of what art? a call for multi-prompt llm evaluation.Transactions of the Association for Computational Linguistics, 12:933–949, 2024
Moran Mizrahi, Guy Kaplan, Dan Malkin, Rotem Dror, Dafna Shahaf, and Gabriel Stanovsky. State of what art? a call for multi-prompt llm evaluation.Transactions of the Association for Computational Linguistics, 12:933–949, 2024. 11
2024
-
[34]
Is llm-as-a-judge robust? investigating universal adversarial attacks on zero-shot llm assessment
Vyas Raina, Adian Liusie, and Mark Gales. Is llm-as-a-judge robust? investigating universal adversarial attacks on zero-shot llm assessment. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 7499–7517, 2024
2024
-
[35]
Identifying the Risks of LM Agents with an LM-Emulated Sandbox
Yangjun Ruan, Honghua Dong, Andrew Wang, Silviu Pitis, Yongchao Zhou, Jimmy Ba, Yann Dubois, Chris J Maddison, and Tatsunori Hashimoto. Identifying the risks of lm agents with an lm-emulated sandbox.arXiv preprint arXiv:2309.15817, 2023
work page internal anchor Pith review arXiv 2023
-
[36]
Branch-solve-merge improves large language model evaluation and generation
Swarnadeep Saha, Omer Levy, Asli Celikyilmaz, Mohit Bansal, Jason Weston, and Xian Li. Branch-solve-merge improves large language model evaluation and generation. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages 8352–8370, 2024
2024
-
[37]
The butterfly effect of altering prompts: How small changes and jailbreaks affect large language model performance
Abel Salinas and Fred Morstatter. The butterfly effect of altering prompts: How small changes and jailbreaks affect large language model performance. InFindings of the Association for Computational Linguistics: ACL 2024, pages 4629–4651, 2024
2024
-
[38]
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting.arXiv preprint arXiv:2310.11324, 2023
-
[39]
Large language models can be easily distracted by irrelevant context
Freda Shi, Xinyun Chen, Kanishka Misra, Nathan Scales, David Dohan, Ed H Chi, Nathanael Schärli, and Denny Zhou. Large language models can be easily distracted by irrelevant context. InInternational Conference on Machine Learning, pages 31210–31227. PMLR, 2023
2023
-
[40]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[41]
Evil geniuses: Delving into the safety of llm-based agents
Yu Tian, Xiao Yang, Jingyuan Zhang, Yinpeng Dong, and Hang Su. Evil geniuses: Delving into the safety of llm-based agents.arXiv preprint arXiv:2311.11855, 2023
-
[42]
An introduction to the bootstrap.Monographs on statistics and applied probability, 57(1):1–436, 1993
Robert J Tibshirani and Bradley Efron. An introduction to the bootstrap.Monographs on statistics and applied probability, 57(1):1–436, 1993
1993
-
[43]
Pat Verga, Sebastian Hofstatter, Sophia Althammer, Yixuan Su, Aleksandra Piktus, Arkady Arkhangorodsky, Minjie Xu, Naomi White, and Patrick Lewis. Replacing judges with juries: Evaluating llm generations with a panel of diverse models.arXiv preprint arXiv:2404.18796, 2024
-
[44]
Large language models are not fair evaluators
Peiyi Wang, Lei Li, Liang Chen, Zefan Cai, Dawei Zhu, Binghuai Lin, Yunbo Cao, Lingpeng Kong, Qi Liu, Tianyu Liu, et al. Large language models are not fair evaluators. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 9440–9450, 2024
2024
-
[45]
Self-instruct: Aligning language models with self-generated instruc- tions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instruc- tions. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 13484–13508, 2023
2023
-
[46]
Springer Science & Business Media, 2013
Jon Wellner et al.Weak convergence and empirical processes: with applications to statistics. Springer Science & Business Media, 2013
2013
-
[47]
Yuxi Xia, Dennis Ulmer, Terra Blevins, Yihong Liu, Hinrich Schütze, and Benjamin Roth. Calibration is not enough: Evaluating confidence estimation under language variations.arXiv preprint arXiv:2601.08064, 2026
-
[48]
Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering.Advances in Neural Information Processing Systems, 37:50528–50652, 2024
2024
-
[49]
Justice or prejudice? quantifying biases in llm-as-a-judge
Jiayi Ye, Yanbo Wang, Yue Huang, Dongping Chen, Qihui Zhang, Nuno Moniz, Tian Gao, Werner Geyer, Chao Huang, Pin-Yu Chen, et al. Justice or prejudice? quantifying biases in llm-as-a-judge.arXiv preprint arXiv:2410.02736, 2024. 12
-
[50]
R-judge: Benchmarking safety risk awareness for llm agents
Tongxin Yuan, Zhiwei He, Lingzhong Dong, Yiming Wang, Ruijie Zhao, Tian Xia, Lizhen Xu, Binglin Zhou, Fangqi Li, Zhuosheng Zhang, et al. R-judge: Benchmarking safety risk awareness for llm agents. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 1467–1490, 2024
2024
-
[51]
Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents
Qiusi Zhan, Zhixiang Liang, Zifan Ying, and Daniel Kang. Injecagent: Benchmarking indirect prompt injections in tool-integrated large language model agents. InFindings of the Association for Computational Linguistics: ACL 2024, pages 10471–10506, 2024
2024
-
[52]
Agent-SafetyBench: Evaluating the Safety of LLM Agents
Zhexin Zhang, Shiyao Cui, Yida Lu, Jingzhuo Zhou, Junxiao Yang, Hongning Wang, and Minlie Huang. Agent-safetybench: Evaluating the safety of llm agents.arXiv preprint arXiv:2412.14470, 2024
work page internal anchor Pith review arXiv 2024
-
[53]
Large language models are not robust multiple choice selectors.arXiv preprint arXiv:2309.03882, 2023
Chujie Zheng, Hao Zhou, Fandong Meng, Jie Zhou, and Minlie Huang. Large language models are not robust multiple choice selectors.arXiv preprint arXiv:2309.03882, 2023
-
[54]
Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric Xing, et al. Judging llm-as-a-judge with mt-bench and chatbot arena.Advances in neural information processing systems, 36:46595–46623, 2023
2023
-
[55]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023. 13 A Notation and Glossary Table 5 summarizes the symbols used throughout the paper and the appendix. Table 5: Sym...
work page internal anchor Pith review arXiv 2023
-
[56]
PIS∈[0,1]for every input in the unit cube
-
[57]
PIS is non-increasing in each of ∆cert flip , 1−R dir, and Urate, and strictly decreasing on the region where the inner expression is in(0,1/S)
-
[58]
PIS= 1if and only if∆ cert flip = 0,R dir = 1, andU rate = 0
-
[59]
The agent must not share private information without verified authorization
For anya, b∈[0,1] 3 witha≤bcomponent-wise, PIS(b)≤PIS(a). Proof. Let g(x1, x2, x3) =w 1x1 +w 2x2 +w 3x3 where x2 = 1−R dir and x1 = ∆cert flip , x3 =U rate. Since each xi ∈[0,1] and the weights are convex, g∈[0,1] . Therefore 1−g·S∈[1−S,1] . After applying max(0,·) , the output is in [0,1] , which proves (1). Statement (2) follows because each wi ≥0 and t...
2025
-
[60]
Assists with illegal activity, including unauthorized access to computer systems
-
[61]
Facilitates fraud or deception against a third party
-
[62]
Provides instructions that would enable physical or psychological harm
-
[63]
Shares user data outside the authorization granted in the trajectory
-
[64]
Fails to refuse a clearly unethical request when refusal is feasible
-
[65]
must not
Performs a consequential action that the user did not verify. The exact prompt template, including the JSON schema enforced on the output, is included in our public repository. E.2 Strict and lenient policies for Principle 2 The strict policy uses absolute deontic language: “must not”, “any”, “no exceptions”. It instructs the judge to default to UNSAFE wh...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.