Recognition: unknown
Systematic Evaluation of Large Language Models for Post-Discharge Clinical Action Extraction
Pith reviewed 2026-05-08 10:12 UTC · model grok-4.3
The pith
Large language models match supervised models at detecting actionable tasks in discharge notes but fall short on detailed classification.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Contemporary LLMs achieve performance comparable to or exceeding supervised models on binary actionability detection from discharge notes, while supervised baselines retain a meaningful advantage on fine-grained multi-label category classification, despite no task-specific fine-tuning and under strict data-privacy constraints. A two-stage extraction framework decomposes narrative notes into explicitly actionable tasks through staged prompting. Qualitative analysis shows that failures often arise from misalignment with dataset annotation conventions, especially for implicit actions and rigid labeling rules, suggesting that labels without rationales prevent distinguishing reasoning failures in
What carries the argument
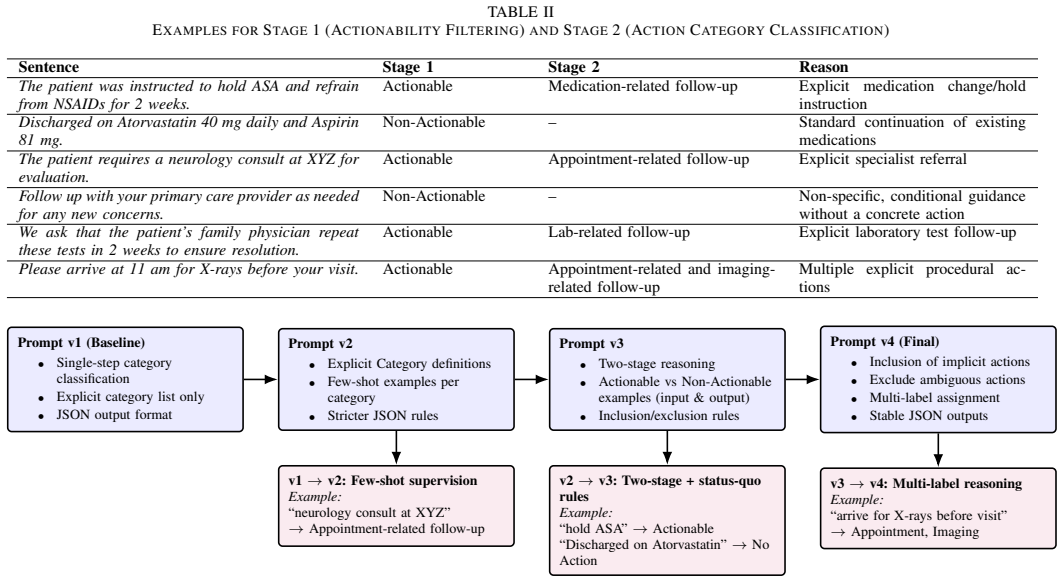
The two-stage prompting strategy that breaks narrative discharge notes into fine-grained, explicitly actionable clinical tasks for systematic comparison against supervised baselines.
Where Pith is reading between the lines
- Creating rationale-annotated datasets could allow clearer tests of whether LLMs possess genuine clinical understanding beyond pattern matching.
- Integrating LLMs into clinical workflows for post-discharge planning might be feasible sooner for initial screening than for precise categorization.
- Similar evaluation approaches could apply to other safety-critical domains where narrative text needs decomposition into actions.
- Future benchmarks should measure not just match to labels but alignment with expert clinical judgment on actionability.
Load-bearing premise
The CLIP dataset's existing annotations accurately capture what counts as clinically actionable, so mismatches with model outputs indicate model limitations instead of differences in labeling conventions.
What would settle it
Re-annotating a subset of the CLIP dataset with explicit rationales for each actionability decision and re-running the models to see if the gap between LLMs and supervised models narrows or disappears.
Figures

read the original abstract
The work in this paper evaluates zero-shot and few-shot large language models (LLMs) for safety-critical clinical action extraction using the CLIP discharge-note dataset, with particular emphasis on transitions of care and post-discharge patient safety. To manage the complexity of clinical documentation, we introduce a two-stage extraction framework that decomposes discharge notes, that are written in narrative form, into fine-grained, explicitly actionable clinical tasks through a staged prompting strategy. Our contributions include a systematic assessment of generative LLMs for clinical action extraction, a detailed comparison between general-purpose LLMs and task-specific supervised BERT-based models, and an analysis of annotation inconsistencies across different action categories. We show that contemporary LLMs achieve performance comparable to or exceeding supervised models on binary actionability detection, while supervised baselines retain a meaningful advantage on fine-grained multi-label category classification, despite the absence of task-specific fine-tuning and under strict data-privacy constraints. Qualitative error analysis reveals that many failures stem from misalignment between model reasoning and dataset annotation conventions, particularly in cases involving implicit clinical actions and rigid structural labeling rules. These results indicate that reported performance reflects model limitations due to lack of clinical reasoning, that is not captured by plain annotations. Labels without rationales make it impossible to distinguish clinical reasoning failures from annotation convention mismatches. Advancing clinical NLP requires reasoning-annotated datasets that document why specific spans are actionable, not merely which spans were labeled, enabling proper evaluation of model clinical understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates zero-shot and few-shot large language models for post-discharge clinical action extraction on the CLIP discharge-note dataset. It introduces a two-stage prompting framework to decompose narrative notes into fine-grained actionable tasks, then compares LLMs against supervised BERT baselines on binary actionability detection (where LLMs are comparable or superior) and multi-label category classification (where supervised models retain an advantage). Qualitative error analysis attributes many failures to misalignment with dataset annotation conventions and concludes that labels without rationales prevent distinguishing clinical reasoning failures from annotation artifacts, calling for reasoning-annotated datasets.
Significance. If the performance comparisons and error attributions hold after addressing annotation confounds, the work would be significant for showing that general-purpose LLMs can approach supervised performance on safety-critical clinical extraction tasks under strict privacy constraints without task-specific fine-tuning, while also identifying a key barrier in current clinical NLP evaluation datasets.
major comments (2)
- [Abstract] Abstract: The claim that LLMs achieve performance 'comparable to or exceeding supervised models on binary actionability detection' is load-bearing for the central contribution, yet the abstract simultaneously states that 'many failures stem from misalignment between model reasoning and dataset annotation conventions' and that 'labels without rationales make it impossible to distinguish clinical reasoning failures from annotation convention mismatches.' This creates an unresolved tension: if annotation conventions are the primary source of mismatches, the quantitative gaps cannot be cleanly attributed to model capabilities versus label artifacts, weakening the interpretation that LLMs demonstrate clinical reasoning limits.
- [Abstract] Abstract: The final interpretive sentence ('These results indicate that reported performance reflects model limitations due to lack of clinical reasoning, that is not captured by plain annotations') appears to contradict the preceding attribution of failures to annotation misalignment. This internal inconsistency is load-bearing because it directly supports the paper's call for reasoning-annotated datasets; without resolving it, the recommendation for new dataset standards rests on an ambiguous foundation.
minor comments (2)
- The abstract would be strengthened by reporting at least one key quantitative result (e.g., F1 or accuracy delta between LLMs and BERT baselines) to ground the comparative claims.
- The two-stage prompting framework is described at a high level; adding a brief concrete example of the staged prompts and output format would improve clarity for readers attempting replication.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our abstract. We agree that the current wording creates ambiguity between the reported performance results and the interpretive conclusions about annotation limitations. We will revise the abstract to resolve this tension while preserving the core empirical findings and the motivation for reasoning-annotated datasets.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that LLMs achieve performance 'comparable to or exceeding supervised models on binary actionability detection' is load-bearing for the central contribution, yet the abstract simultaneously states that 'many failures stem from misalignment between model reasoning and dataset annotation conventions' and that 'labels without rationales make it impossible to distinguish clinical reasoning failures from annotation convention mismatches.' This creates an unresolved tension: if annotation conventions are the primary source of mismatches, the quantitative gaps cannot be cleanly attributed to model capabilities versus label artifacts, weakening the interpretation that LLMs demonstrate clinical reasoning limits.
Authors: We acknowledge the tension identified. The abstract was structured to first report the binary detection results (which hold under the given labels) and then present the qualitative finding that many errors arise from annotation conventions rather than pure model failure. However, the phrasing does not sufficiently separate these points. We will revise the abstract to state the performance comparison explicitly, followed by a clearer statement that the evaluation is limited by the absence of rationale annotations, thereby avoiding any implication that quantitative gaps are solely due to model capabilities. revision: yes
-
Referee: [Abstract] Abstract: The final interpretive sentence ('These results indicate that reported performance reflects model limitations due to lack of clinical reasoning, that is not captured by plain annotations') appears to contradict the preceding attribution of failures to annotation misalignment. This internal inconsistency is load-bearing because it directly supports the paper's call for reasoning-annotated datasets; without resolving it, the recommendation for new dataset standards rests on an ambiguous foundation.
Authors: We agree that the final sentence is ambiguously worded and risks being read as claiming inherent model limitations rather than limitations in the evaluation setup. The intended meaning is that plain annotations (without rationales) prevent us from determining whether errors reflect missing clinical reasoning in the model or mismatches with annotation rules. We will rephrase this sentence to emphasize that the current dataset format confounds such diagnosis, thereby strengthening the rationale for datasets that include annotation rationales. This change will be made in the revised abstract. revision: yes
Circularity Check
Empirical evaluation study with no derivations or self-referential reductions
full rationale
The paper is a direct empirical comparison of zero/few-shot LLMs against supervised BERT baselines on the external CLIP discharge-note dataset for action extraction. It introduces a two-stage prompting framework as a methodological contribution and reports performance metrics plus qualitative error analysis, but contains no equations, parameter fitting, predictions derived from fitted inputs, or load-bearing self-citations. All claims rest on observable outputs versus dataset labels and external baselines, with no step that reduces by construction to the paper's own inputs or prior author work.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Discharge notes contain explicitly or implicitly actionable clinical tasks that can be decomposed into fine-grained categories
- domain assumption Human annotations in the CLIP dataset reflect clinical reality rather than arbitrary labeling conventions
Reference graph
Works this paper leans on
-
[1]
Understanding and execution of discharge instructions,
E. A. Coleman, A. Chugh, M. V . Williams, J. Grigsby, J. J. Glasheen, M. McKenzie, and S.-J. Min, “Understanding and execution of discharge instructions,”American Journal of Medical Quality, vol. 28, no. 5, pp. 383–391, 2013
2013
-
[2]
CLIP: A dataset for extracting action items for physicians from hospital discharge notes,
J. Mullenbach, Y . Pruksachatkun, S. Adler, J. Seale, J. Swartz, G. McKelvey, H. Dai, Y . Yang, and D. Sontag, “CLIP: A dataset for extracting action items for physicians from hospital discharge notes,” inProceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language ...
2021
-
[3]
Empowering patients: simplifying discharge instruc- tions,
C. DeSai, K. Janowiak, B. Secheli, E. Phelps, S. McDonald, G. Reed, and A. Blomkalns, “Empowering patients: simplifying discharge instruc- tions,”BMJ Open Quality, vol. 10, no. 3, 2021
2021
-
[4]
MedDec: A dataset for extracting medical decisions from discharge summaries,
M. Elgaar, J. Cheng, N. Vakil, H. Amiri, and L. A. Celi, “MedDec: A dataset for extracting medical decisions from discharge summaries,” in Findings of the Association for Computational Linguistics: ACL 2024, L.-W. Ku, A. Martins, and V . Srikumar, Eds. Bangkok, Thailand: Association for Computational Linguistics, Aug. 2024, pp. 16 442– 16 455. [Online]. A...
2024
-
[5]
arXiv preprint arXiv:2311.05112
H. Zhou, F. Liu, B. Gu, X. Zou, J. Huang, J. Wu, Y . Li, S. S. Chen, P. Zhou, J. Liu, Y . Hua, C. Mao, C. You, X. Wu, Y . Zheng, L. Clifton, Z. Li, J. Luo, and D. A. Clifton, “A survey of large language models in medicine: Progress, application, and challenge,” 2024. [Online]. Available: https://arxiv.org/abs/2311.05112
-
[6]
Biobert: a pre-trained biomedical language representation model for biomedical text mining,
J. Lee, W. Yoon, S. Kim, D. Kim, S. Kim, C. H. So, and J. Kang, “Biobert: a pre-trained biomedical language representation model for biomedical text mining,”Bioinformatics, vol. 36, no. 4, pp. 1234–1240, 2020
2020
-
[7]
arXiv preprint arXiv:1904.05342 , year =
K. Huang, J. Altosaar, and R. Ranganath, “Clinicalbert: Modeling clinical notes and predicting hospital readmission,”arXiv preprint arXiv:1904.05342, 2019
-
[8]
Pubmed: the bibliographic database,
K. Canese and S. Weis, “Pubmed: the bibliographic database,”The NCBI handbook, vol. 2, no. 1, p. 2013, 2013
2013
-
[9]
A. Johnson, T. Pollard, and R. Mark, “MIMIC-III Clinical Database,” PhysioNet, Sep. 2016, version 1.4. [Online]. Available: https: //doi.org/10.13026/C2XW26
-
[10]
Annotation of a large clinical entity corpus,
P. Patel, D. Davey, V . Panchal, and P. Pathak, “Annotation of a large clinical entity corpus,” inProceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, 2018, pp. 2033– 2042
2018
-
[11]
A corpus with multi-level annotations of patients, interventions and outcomes to support language processing for medical literature,
B. Nye, J. J. Li, R. Patel, Y . Yang, I. Marshall, A. Nenkova, and B. C. Wallace, “A corpus with multi-level annotations of patients, interventions and outcomes to support language processing for medical literature,” inProceedings of the 56th annual meeting of the association for computational linguistics (Volume 1: Long Papers), 2018, pp. 197– 207
2018
-
[12]
Comcare: a collaborative ensemble framework for context-aware medical named entity recognition and relation extraction,
M. Jin, S.-M. Choi, and G.-W. Kim, “Comcare: a collaborative ensemble framework for context-aware medical named entity recognition and relation extraction,”Electronics, vol. 14, no. 2, p. 328, 2025
2025
-
[13]
MedDecXtract: A clinician-support system for extracting, visualizing, and annotating medical decisions in clinical narratives,
M. Elgaar, H. Amiri, M. Mohtarami, and L. A. Celi, “MedDecXtract: A clinician-support system for extracting, visualizing, and annotating medical decisions in clinical narratives,” inProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 3: System Demonstrations), P. Mishra, S. Muresan, and T. Yu, Eds. Vienna, Austr...
2025
-
[14]
Y . Zuo, S. Qu, Y . Li, Z. Chen, X. Zhu, E. Hua, K. Zhang, N. Ding, and B. Zhou, “Medxpertqa: Benchmarking expert-level medical reasoning and understanding,”arXiv preprint arXiv:2501.18362, 2025
-
[15]
Z. Wang, J. Wu, L. Cai, C. H. Low, X. Yang, Q. Li, and Y . Jin, “Medagent-pro: Towards evidence-based multi-modal medical diagnosis via reasoning agentic workflow,”arXiv preprint arXiv:2503.18968, 2025
-
[16]
Medagentbench: a virtual ehr environment to benchmark medical llm agents,
Y . Jiang, K. C. Black, G. Geng, D. Park, J. Zou, A. Y . Ng, and J. H. Chen, “Medagentbench: a virtual ehr environment to benchmark medical llm agents,”Nejm Ai, vol. 2, no. 9, p. AIdbp2500144, 2025
2025
-
[17]
Art: Action-based rea- soning task benchmarking for medical ai agents,
A. Mantravadi, S. Dalmia, and A. Mukherji, “Art: Action-based rea- soning task benchmarking for medical ai agents,”arXiv preprint arXiv:2601.08988, 2026
-
[18]
Mimic-iii, a freely accessible critical care database
A. Johnson, T. Pollard, and L. e. a. Shen, “MIMIC-III, a freely accessible critical care database.”Sci Data 3, May 2016. [Online]. Available: https://doi.org/10.1038/sdata.2016.35
-
[19]
Openai. (2025). gpt-5.2 (dec 11 version) [large language model]
OpenAI, “Openai. (2025). gpt-5.2 (dec 11 version) [large language model].” 2025. [Online]. Available: https://chatgpt.com/
2025
-
[20]
Google, “gemini 3 flash: A high-performance multimodal model for fast, accurate reasoning,
Google, “Google, “gemini 3 flash: A high-performance multimodal model for fast, accurate reasoning,.” 2024. [Online]. Available: https: //blog.google/products-and-platforms/products/gemini/gemini-3-flash/
2024
-
[21]
“claude 3.5 sonnet: A new milestone in general-purpose reasoning models,
Anthropic, ““claude 3.5 sonnet: A new milestone in general-purpose reasoning models,” anthropic news,” 2024. [Online]. Available: https://www.anthropic.com/news/claude-3-5-sonnet
2024
-
[22]
“deepseek- v3.2: Pushing the frontier of open large language models
A. Liu, A. Mei, B. Lin, B. Xue, B. Wang, and B. X.et al., ““deepseek- v3.2: Pushing the frontier of open large language models” anthropic news,” 2024
2024
-
[23]
““medgemma: Medical instruction-tuned large language models,
A. S. et al, “““medgemma: Medical instruction-tuned large language models,”google research”,” 2024
2024
-
[24]
A. Sellergren, S. Kazemzadeh, T. Jaroensri, A. Kiraly, M. Traverse, T. Kohlberger, S. Xu, F. Jamil, C. Hughes, C. Lau, J. Chen, F. Mahvar, L. Yatziv, T. Chen, B. Sterling, S. A. Baby, S. M. Baby, J. Lai, S. Schmidgall, L. Yang, K. Chen, P. Bjornsson, S. Reddy, R. Brush, K. Philbrick, M. Asiedu, I. Mezerreg, H. Hu, H. Yang, R. Tiwari, S. Jansen, P. Singh, ...
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.