Recognition: no theorem link
When to Trust Imagination: Adaptive Action Execution for World Action Models
Pith reviewed 2026-05-12 01:19 UTC · model grok-4.3
The pith
A lightweight verifier lets world action models execute predicted actions for variable lengths by checking consistency with real observations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
FFDC is a causal-attention verifier that estimates whether the remaining predicted action sequence can still be trusted by reasoning over the joint distribution of future actions, future visual dynamics, current observations, and the language goal. When the verifier judges the rollout reliable, the robot executes the full predicted chunk; when it detects deviation, the robot interrupts and replans from the new observation. This mechanism emerges directly from prediction-observation consistency rather than from hand-tuned thresholds. The approach is trained with mixture-of-horizon supervision to ensure the verifier sees both short and long rollouts during learning.
What carries the argument
Future Forward Dynamics Causal Attention (FFDC), a verifier that jointly reasons over predicted future actions, predicted visual dynamics, real observations, and language instructions to decide whether the remaining action rollout remains trustworthy.
If this is right
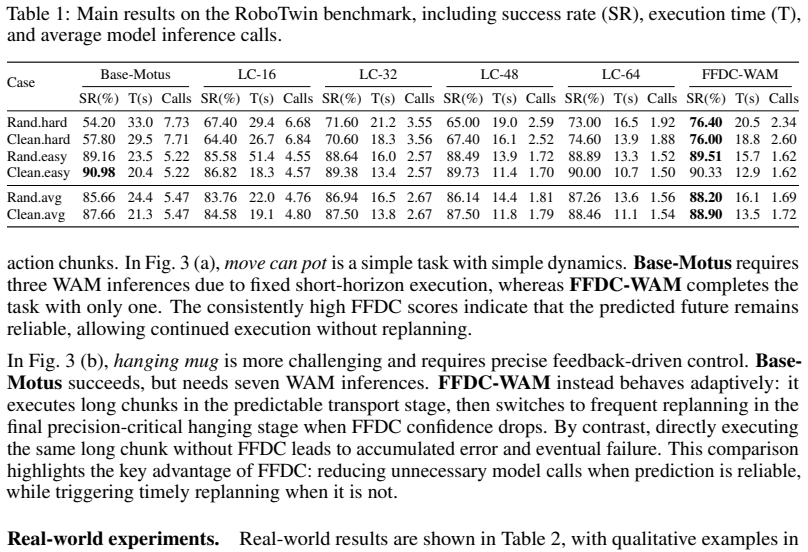
- WAM forward passes drop by 69.10% and execution time by 34.02% on the RoboTwin benchmark while success rises 2.54%.
- Real-world success rate increases by 35% compared with fixed-chunk execution.
- Long-horizon efficiency is retained in easy phases while early replanning restores responsiveness in contact-rich or uncertain phases.
- Mixture-of-horizon training produces a single model that supports reliable verification across a range of prediction lengths.
- Adaptive chunk size emerges automatically from the consistency check rather than from separate scheduling logic.
Where Pith is reading between the lines
- The same verification principle could be applied to other predictive planners that output both state and action sequences.
- If the verifier remains accurate at longer horizons, the method could reduce the frequency of expensive replanning in extended manipulation sequences.
- The approach supplies an explicit consistency signal that might be useful for safety monitoring or for triggering human intervention.
- Combining FFDC with uncertainty-aware models could further improve the reliability of the trust decision.
Load-bearing premise
The FFDC verifier can reliably judge whether a predicted action sequence will still succeed solely by comparing predicted actions and visuals against incoming real observations and the original instruction.
What would settle it
A controlled test in which FFDC assigns high trust scores to rollouts that subsequently fail, resulting in lower overall success rates than a fixed short-chunk baseline.
Figures



read the original abstract
World Action Models (WAMs) have recently emerged as a promising paradigm for robotic manipulation by jointly predicting future visual observations and future actions. However, current WAMs typically execute a fixed number of predicted actions after each model inference, leaving the robot blind to whether the imagined future remains consistent with the actual physical rollout. In this work, we formulate adaptive WAM execution as a future-reality verification problem: the robot should execute longer when the WAM-predicted future remains reliable, and replan earlier when reality deviates from imagination. To this end, we propose Future Forward Dynamics Causal Attention (FFDC), a lightweight verifier that jointly reasons over predicted future actions, predicted visual dynamics, real observations, and language instructions to estimate whether the remaining action rollout can still be trusted. FFDC enables adaptive action chunk sizes as an emergent consequence of prediction-observation consistency, preserving the efficiency of long-horizon execution while restoring responsiveness in contact-rich or difficult phases. We further introduce Mixture-of-Horizon Training to improve long-horizon trajectory coverage for adaptive execution. Experiments on the RoboTwin benchmark and in the real world demonstrate that our method achieves a strong robustness-efficiency trade-off: on RoboTwin, it reduces WAM forward passes by 69.10% and execution time by 34.02%, while improving success rate by 2.54% over the short-chunk baseline; in real-world experiments, it improves success rate by 35%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that World Action Models (WAMs) can be executed adaptively by using a Future Forward Dynamics Causal Attention (FFDC) verifier to assess consistency between predicted future actions/visuals and real observations (plus language), triggering replanning only when needed. Combined with Mixture-of-Horizon Training, this yields emergent variable chunk sizes that reduce WAM forward passes by 69.10% and execution time by 34.02% on RoboTwin while raising success rate by 2.54%, with a 35% success-rate gain in real-world trials.
Significance. If the FFDC verifier reliably detects prediction-observation mismatches from the four input streams, the approach would offer a practical way to retain the efficiency of long-horizon WAM rollouts while regaining reactivity in contact-rich phases, addressing a clear deployment bottleneck. The dual benchmark-plus-real-world evaluation and the reported efficiency gains are concrete strengths that would be valuable to the robotics community if the verifier's calibration and contribution are demonstrated.
major comments (2)
- [Experiments] Experiments section: the 69.10% reduction in forward passes, 34.02% time saving, and 2.54% success-rate improvement are stated without error bars, statistical significance tests, or an explicit definition of the short-chunk baseline, so the robustness of the efficiency-accuracy trade-off cannot be assessed from the given numbers.
- [Methods] Methods (FFDC and training description): the central claim that FFDC produces a scalar trustworthiness score via causal attention over predicted actions, predicted visuals, real observations, and language requires ground-truth trustworthiness labels, calibration plots of score versus actual rollout success, and an ablation isolating joint multi-modal reasoning; none of these are reported, leaving open whether the adaptive chunk sizes arise from genuine consistency detection or from training heuristics.
minor comments (2)
- [Abstract] Abstract: 'Mixture-of-Horizon Training' is introduced without a one-sentence gloss of its objective or loss, which would help readers immediately grasp its role in supporting adaptive execution.
- Notation: the four input streams to FFDC are described in prose but would benefit from an explicit equation or block diagram showing how they are concatenated or attended before the scalar output.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. The comments highlight important aspects of experimental reporting and methodological validation that we will address to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the 69.10% reduction in forward passes, 34.02% time saving, and 2.54% success-rate improvement are stated without error bars, statistical significance tests, or an explicit definition of the short-chunk baseline, so the robustness of the efficiency-accuracy trade-off cannot be assessed from the given numbers.
Authors: We agree that the reported aggregate metrics would benefit from additional statistical context. In the revised manuscript, we will include error bars as standard deviations computed over multiple random seeds, conduct and report statistical significance tests (e.g., paired t-tests) against the baseline, and provide an explicit definition of the short-chunk baseline as fixed single-action execution (chunk size of 1), consistent with prior WAM evaluation protocols. These changes will allow clearer assessment of the efficiency-accuracy trade-off. revision: yes
-
Referee: [Methods] Methods (FFDC and training description): the central claim that FFDC produces a scalar trustworthiness score via causal attention over predicted actions, predicted visuals, real observations, and language requires ground-truth trustworthiness labels, calibration plots of score versus actual rollout success, and an ablation isolating joint multi-modal reasoning; none of these are reported, leaving open whether the adaptive chunk sizes arise from genuine consistency detection or from training heuristics.
Authors: FFDC is trained end-to-end via the self-supervised Mixture-of-Horizon objective, which does not rely on explicit ground-truth trustworthiness labels; the scalar score arises directly from the causal attention comparisons across the four input streams. We acknowledge that additional supporting analyses would strengthen the claim. In the revision, we will include calibration plots correlating the trustworthiness score with observed rollout success and an ablation study that isolates the joint multi-modal attention from single-modality variants. These additions will clarify that the emergent adaptive chunking stems from consistency detection. revision: partial
Circularity Check
No significant circularity; FFDC and adaptive execution are introduced as independent modules
full rationale
The paper defines FFDC as a new lightweight verifier using joint causal attention over four distinct input streams (predicted actions, predicted visuals, real observations, language) to output a trustworthiness scalar. Adaptive chunk sizes are presented as an emergent outcome of applying this verifier during execution, not as a quantity fitted or defined from the same inputs. Mixture-of-Horizon Training is a separate data-augmentation strategy for long-horizon coverage. No equations, self-citations, or ansatzes reduce the central claim to a tautology or fitted parameter renamed as prediction. The derivation chain remains self-contained against external benchmarks and empirical results.
Axiom & Free-Parameter Ledger
invented entities (2)
-
Future Forward Dynamics Causal Attention (FFDC)
no independent evidence
-
Mixture-of-Horizon Training
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Motus: A Unified Latent Action World Model
Hongzhe Bi, Hengkai Tan, Shenghao Xie, Zeyuan Wang, Shuhe Huang, Haitian Liu, Ruowen Zhao, Yao Feng, Chendong Xiang, Yinze Rong, et al. Motus: A unified latent action world model.arXiv preprint arXiv:2512.13030, 2025
work page internal anchor Pith review arXiv 2025
-
[2]
$\pi_0$: A Vision-Language-Action Flow Model for General Robot Control
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
In9th Annual Conference on Robot Learning, 2025
Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Robert Equi, Chelsea Finn, Niccolo Fusai, Manuel Y Galliker, et al.π0.5: a vision-language-action model with open-world generalization. In9th Annual Conference on Robot Learning, 2025
work page 2025
-
[4]
Tianxing Chen, Zanxin Chen, Baijun Chen, Zijian Cai, Yibin Liu, Zixuan Li, Qiwei Liang, Xianliang Lin, Yiheng Ge, Zhenyu Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Yilun Du, Sherry Yang, Bo Dai, Hanjun Dai, Ofir Nachum, Josh Tenenbaum, Dale Schuurmans, and Pieter Abbeel. Learning universal policies via text-guided video generation.Advances in neural information processing systems, 36:9156–9172, 2023
work page 2023
-
[6]
Guang Gao, Jianan Wang, Jinbo Zuo, Junnan Jiang, Jingfan Zhang, Xianwen Zeng, Yuejiang Zhu, Lianyang Ma, Ke Chen, Minhua Sheng, et al. Towards human-level intelligence via human-like whole-body manipulation.arXiv preprint arXiv:2507.17141, 2025
-
[7]
Yanjiang Guo, Yucheng Hu, Jianke Zhang, Yen-Jen Wang, Xiaoyu Chen, Chaochao Lu, and Jianyu Chen. Prediction with action: Visual policy learning via joint denoising process.Advances in Neural Information Processing Systems, 37:112386–112410, 2024
work page 2024
-
[8]
Ryan Hoque, Ashwin Balakrishna, Ellen Novoseller, Albert Wilcox, Daniel S Brown, and Ken Goldberg. Thriftydagger: Budget-aware novelty and risk gating for interactive imitation learning.arXiv preprint arXiv:2109.08273, 2021
-
[9]
Mixture of horizons in action chunking.arXiv preprint arXiv:2511.19433, 2025
Dong Jing, Gang Wang, Jiaqi Liu, Weiliang Tang, Zelong Sun, Yunchao Yao, Zhenyu Wei, Yunhui Liu, Zhiwu Lu, and Mingyu Ding. Mixture of horizons in action chunking.arXiv preprint arXiv:2511.19433, 2025
-
[10]
Dart: Noise injection for robust imitation learning
Michael Laskey, Jonathan Lee, Roy Fox, Anca Dragan, and Ken Goldberg. Dart: Noise injection for robust imitation learning. InConference on robot learning, pages 143–156. PMLR, 2017
work page 2017
-
[11]
Diff-dagger: Uncertainty estimation with diffusion policy for robotic manipulation
Sung-Wook Lee, Xuhui Kang, and Yen-Ling Kuo. Diff-dagger: Uncertainty estimation with diffusion policy for robotic manipulation. In2025 IEEE International Conference on Robotics and Automation (ICRA), pages 4845–4852. IEEE, 2025
work page 2025
-
[12]
Causal World Modeling for Robot Control
Lin Li, Qihang Zhang, Yiming Luo, Shuai Yang, Ruilin Wang, Fei Han, Mingrui Yu, Zelin Gao, Nan Xue, Xing Zhu, et al. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998, 2026
work page internal anchor Pith review arXiv 2026
-
[13]
Shuang Li, Yihuai Gao, Dorsa Sadigh, and Shuran Song. Unified video action model.arXiv preprint arXiv:2503.00200, 2025
work page internal anchor Pith review arXiv 2025
-
[14]
Video generators are robot policies.arXiv preprint arXiv:2508.00795, 2025
Junbang Liang, Pavel Tokmakov, Ruoshi Liu, Sruthi Sudhakar, Paarth Shah, Rares Ambrus, and Carl V ondrick. Video generators are robot policies.arXiv preprint arXiv:2508.00795, 2025
-
[15]
Adaptive Action Chunking at Inference-time for Vision-Language-Action Models
Yuanchang Liang, Xiaobo Wang, Kai Wang, Shuo Wang, Xiaojiang Peng, Haoyu Chen, David Kim Huat Chua, and Prahlad Vadakkepat. Adaptive action chunking at inference-time for vision-language-action models.arXiv preprint arXiv:2604.04161, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[16]
Jiuming Liu, Mengmeng Liu, Siting Zhu, Yunpeng Zhang, Jiangtao Li, Michael Ying Yang, Francesco Nex, Hao Cheng, and Hesheng Wang. Arflow: Auto-regressive optical flow estimation for arbitrary-length videos via progressive next-frame forecasting. InThe Fourteenth International Conference on Learning Representations, 2026. 10
work page 2026
-
[17]
Qi Lv, Weijie Kong, Hao Li, Jia Zeng, Zherui Qiu, Delin Qu, Haoming Song, Qizhi Chen, Xiang Deng, and Jiangmiao Pang. F1: A vision-language-action model bridging understanding and generation to actions. arXiv preprint arXiv:2509.06951, 2025
-
[18]
Ensembledagger: A bayesian approach to safe imitation learning
Kunal Menda, Katherine Driggs-Campbell, and Mykel J Kochenderfer. Ensembledagger: A bayesian approach to safe imitation learning. In2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pages 5041–5048. IEEE, 2019
work page 2019
-
[19]
Jonas Pai, Liam Achenbach, Victoriano Montesinos, Benedek Forrai, Oier Mees, and Elvis Nava. mimic- video: Video-action models for generalizable robot control beyond vlas.arXiv preprint arXiv:2512.15692, 2025
-
[20]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[21]
A reduction of imitation learning and structured prediction to no-regret online learning
Stéphane Ross, Geoffrey Gordon, and Drew Bagnell. A reduction of imitation learning and structured prediction to no-regret online learning. InProceedings of the fourteenth international conference on artificial intelligence and statistics, pages 627–635. JMLR Workshop and Conference Proceedings, 2011
work page 2011
-
[22]
SmolVLA: A Vision-Language-Action Model for Affordable and Efficient Robotics
Mustafa Shukor, Dana Aubakirova, Francesco Capuano, Pepijn Kooijmans, Steven Palma, Adil Zouitine, Michel Aractingi, Caroline Pascal, Martino Russi, Andres Marafioti, et al. Smolvla: A vision-language- action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[23]
Being-h0.7: A latent world-action model from egocentric videos, 2026
BeingBeyond Team. Being-h0.7: A latent world-action model from egocentric videos, 2026. URL https://research.beingbeyond.com/being-h07. Accessed: 2026-04-27
work page 2026
-
[24]
Pdfactor: Learning tri-perspective view policy diffusion field for multi-task robotic manipulation
Jingyi Tian, Le Wang, Sanping Zhou, Sen Wang, Jiayi Li, Haowen Sun, and Wei Tang. Pdfactor: Learning tri-perspective view policy diffusion field for multi-task robotic manipulation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 15757–15767, 2025
work page 2025
-
[25]
Vla knows its limits.arXiv preprint arXiv:2602.21445, 2026
Haoxuan Wang, Gengyu Zhang, Yan Yan, Ramana Rao Kompella, and Gaowen Liu. Vla knows its limits. arXiv preprint arXiv:2602.21445, 2026
-
[26]
Open-Loop Planning, Closed-Loop Verification: Speculative Verification for VLA
Zihua Wang, Zhitao Lin, Ruibo Li, Yu Zhang, Xu Yang, Siya Mi, and Xiu-Shen Wei. Open-loop planning, closed-loop verification: Speculative verification for vla.arXiv preprint arXiv:2604.02965, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[27]
Zhichao Wu, Junyin Ye, Zhilong Zhang, Yihao Sun, Haoxin Lin, Jiaheng Luo, Haoxiang Ren, Lei Yuan, and Yang Yu. Speedup patch: Learning a plug-and-play policy to accelerate embodied manipulation.arXiv preprint arXiv:2603.20658, 2026
-
[28]
Gigaworld-policy: An efficient action- centered world–action model, 2026
Angen Ye, Boyuan Wang, Chaojun Ni, Guan Huang, Guosheng Zhao, Hao Li, Hengtao Li, Jie Li, Jindi Lv, Jingyu Liu, et al. Gigaworld-policy: An efficient action-centered world–action model.arXiv preprint arXiv:2603.17240, 2026
-
[29]
Latent Action Pretraining from Videos
Seonghyeon Ye, Joel Jang, Byeongguk Jeon, Sejune Joo, Jianwei Yang, Baolin Peng, Ajay Mandlekar, Reuben Tan, Yu-Wei Chao, Bill Yuchen Lin, et al. Latent action pretraining from videos.arXiv preprint arXiv:2410.11758, 2024
work page Pith review arXiv 2024
-
[30]
World Action Models are Zero-shot Policies
Seonghyeon Ye, Yunhao Ge, Kaiyuan Zheng, Shenyuan Gao, Sihyun Yu, George Kurian, Suneel Indupuru, You Liang Tan, Chuning Zhu, Jiannan Xiang, et al. World action models are zero-shot policies.arXiv preprint arXiv:2602.15922, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[31]
Fast-WAM: Do World Action Models Need Test-time Future Imagination?
Tianyuan Yuan, Zibin Dong, Yicheng Liu, and Hang Zhao. Fast-wam: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666, 2026
work page internal anchor Pith review arXiv 2026
-
[32]
Learning Fine-Grained Bimanual Manipulation with Low-Cost Hardware
Tony Z Zhao, Vikash Kumar, Sergey Levine, and Chelsea Finn. Learning fine-grained bimanual manipula- tion with low-cost hardware.arXiv preprint arXiv:2304.13705, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[33]
Unified World Models: Coupling Video and Action Diffusion for Pretraining on Large Robotic Datasets
Chuning Zhu, Raymond Yu, Siyuan Feng, Benjamin Burchfiel, Paarth Shah, and Abhishek Gupta. Unified world models: Coupling video and action diffusion for pretraining on large robotic datasets.arXiv preprint arXiv:2504.02792, 2025. 11 A Technical appendices and supplementary material A.1 Limitations The current FFDC design adopts a relatively lightweight me...
work page internal anchor Pith review arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.