Recognition: unknown
Correct Code, Vulnerable Dependencies: A Large Scale Measurement Study of LLM-Specified Library Versions
Pith reviewed 2026-05-08 08:49 UTC · model grok-4.3
The pith
LLMs specify library versions carrying known security vulnerabilities in 37 to 56 percent of generated tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
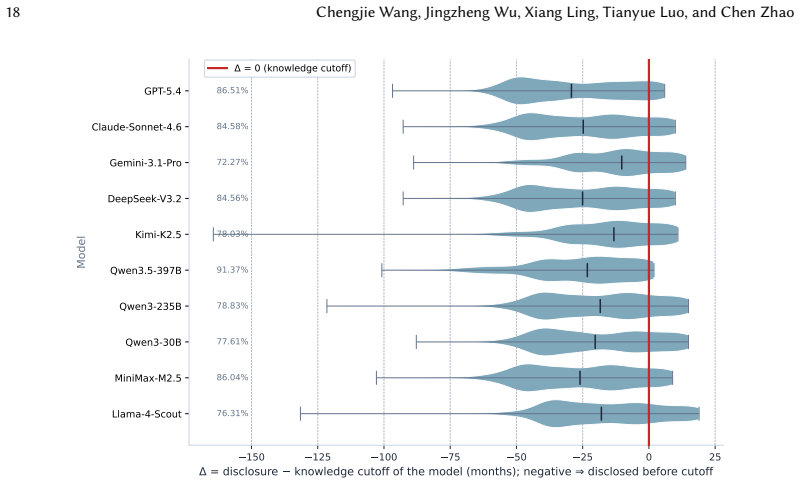
The authors show that LLMs include version identifiers in 26.83 to 95.18 percent of cases when prompted directly and in 6.45 to 59.19 percent of cases when asked to produce a manifest file. Among those specified versions, 36.70 to 55.70 percent of tasks contain at least one known CVE, and 62.75 to 74.51 percent of the CVEs are critical or high. In 72.27 to 91.37 percent of cases the CVEs were published before the model's knowledge cutoff. All ten models converge on the same small collection of risky release versions rather than distributing errors independently. Static compatibility checks pass in only 19.70 to 63.20 percent of cases, with installation failures as the main cause, and dynamic
What carries the argument
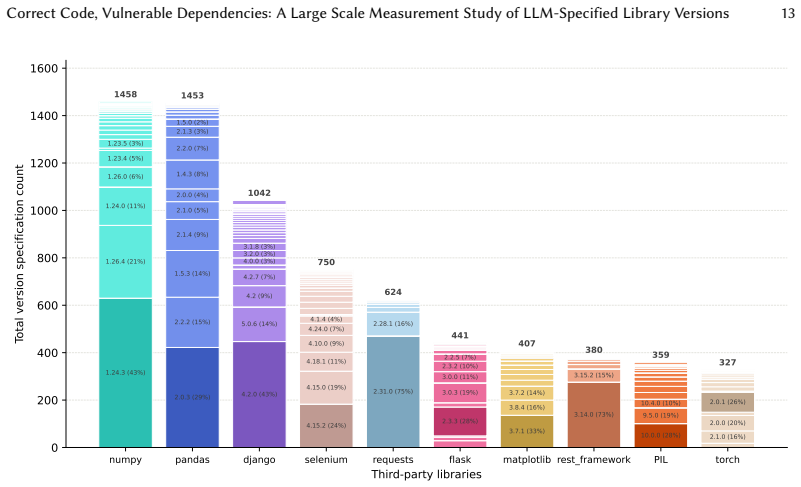
The PinTrace benchmark of 1,000 Stack Overflow tasks used to prompt models, extract version strings from generated code or manifests, and match them against public CVE records.
If this is right
- Externally supplied version constraints sharply reduce both CVE exposure and installation failures.
- Version selection errors are attributable to the chosen releases rather than to flaws in the surrounding code.
- Dynamic test pass rates drop to 6.49-48.62 percent, confirming that the risky versions actually break functionality.
- All evaluated models exhibit the same narrow preference for vulnerable releases, pointing to a shared training artifact.
- Compatibility failures remain high even when the generated code is otherwise correct.
Where Pith is reading between the lines
- Teams that let LLMs generate dependency files may need automated post-processing to replace risky versions with known-safe alternatives.
- The same convergence pattern could appear in other languages or ecosystems if the underlying training data favor popular but outdated releases.
- Prompt engineering that explicitly forbids version numbers or forces latest-stable constraints offers a lightweight mitigation.
- Long-term, training data curation that down-weights vulnerable historical releases might reduce the bias at its source.
Load-bearing premise
The 1,000 Stack Overflow tasks represent typical real-world prompts for library-dependent code, and the automated extraction of versions plus CVE lookup introduces negligible false positives or selection bias.
What would settle it
A follow-up experiment on a fresh set of prompts or with an independent CVE scanner that finds substantially lower vulnerable-version rates or no convergence across models would undermine the systemic-bias conclusion.
Figures






read the original abstract
Large language models (LLMs) are now largely involved in software development workflows, and the code they generate routinely includes third-party library (TPL) imports annotated with specific version identifiers. These version choices can carry security and compatibility risks, yet they have not been systematically studied. We present the first large-scale measurement study of version-level risk in LLM-generated Python code, evaluating 10 LLMs on PinTrace, a curated benchmark of 1,000 Stack Overflow programming tasks. LLMs tend to specify version identifiers when directly prompted at 26.83%-95.18%, while down to 6.45%-59.19% in creating a manifest file directly. Among the specified versions, 36.70%-55.70% of tasks contain at least one known CVE, and 62.75%-74.51% of them carry Critical or High severity ratings. In 72.27%-91.37% of cases, the associated CVEs were publicly disclosed before the model's knowledge cutoff. The statistics show all models converge on the same small set of risky release versions, indicating a systemic bias rather than isolated model error. Static compatibility rates range from 19.70% to 63.20%, with installation failure as the dominant cause. The dynamic test cases confirm the pattern by 6.49%-48.62% pass rates. Further experiments confirm that these failures are attributable to version selection rather than code quality, and that externally anchored version constraints substantially reduce both vulnerability exposure and compatibility failures. Our findings reveal LLM version selection as a first-class, previously overlooked risk surface in LLM-based development. We disclosed these findings to the community of the evaluated models, and several confirmed the issue. All the code and dataset have been released for open science at https://github.com/dw763j/PinTrace.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents the first large-scale measurement study of version-level security and compatibility risks in Python code generated by 10 LLMs, evaluated on the PinTrace benchmark of 1,000 curated Stack Overflow programming tasks. Key findings include LLMs specifying version identifiers at rates of 26.83%-95.18% (lower when generating manifests), with 36.70%-55.70% of tasks containing at least one known CVE among specified versions (62.75%-74.51% rated Critical or High), 72.27%-91.37% of which predate the models' knowledge cutoffs. All models converge on the same small set of risky versions; static compatibility ranges 19.70%-63.20% and dynamic pass rates 6.49%-48.62%, with experiments attributing failures primarily to version selection rather than code quality. Externally anchored constraints reduce risks, and the authors disclose findings to model providers while releasing code and data.
Significance. If the measurements are robust, the work establishes LLM version selection as a systemic, previously unquantified risk surface in LLM-assisted development, with high CVE exposure and compatibility failures that are not isolated errors but convergent behavior across models. The open release of the full dataset, code, and benchmark supports reproducibility and follow-on work; disclosure to vendors adds practical impact. This could inform secure prompting practices and training data curation in software engineering.
major comments (3)
- [§3] §3 (Benchmark Construction): The central claim that 36.70%-55.70% of tasks contain known CVEs depends on PinTrace's 1,000 Stack Overflow tasks being representative of real-world LLM prompting for library-dependent code, yet no validation (e.g., diversity metrics, comparison to actual usage logs, or sampling rationale) is reported. This is load-bearing for generalizing the risk surface beyond the benchmark.
- [§4] §4 (Version Extraction and CVE Matching): The automated pipeline for extracting version strings from generated code and matching to NVD/CVE databases reports no precision/recall figures, manual validation set, or inter-rater reliability checks. Without these, selection bias or false positives in parsing (e.g., advisory text treated as versions) could directly inflate the CVE percentages and severity distributions, which underpin the main empirical claims.
- [§5.2-5.3] §5.2-5.3 (Compatibility Experiments): The attribution of low static (19.70%-63.20%) and dynamic (6.49%-48.62%) compatibility rates to version selection rather than code quality relies on controlled experiments, but the construction of test cases and isolation of confounding factors (e.g., task selection bias) are not detailed sufficiently to rule out alternative explanations for the observed failures.
minor comments (3)
- [Abstract] Abstract: The reported ranges (e.g., 36.70%-55.70%) would benefit from explicit mapping to individual models or conditions for immediate interpretability.
- [Figures/Tables] Throughout: Some figure captions and table headers could more clearly distinguish between 'tasks with specified versions' versus 'all tasks' to avoid reader misinterpretation of the percentages.
- [§6] §6 (Discussion): The claim of 'systemic bias' from convergence on risky versions would be strengthened by a brief comparison to version distributions in non-LLM codebases or training data artifacts.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below, providing clarifications on our methodology and indicating where revisions will be made to improve transparency and robustness. Our goal is to ensure the measurements are presented with appropriate caveats while maintaining the core findings on LLM version selection risks.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The central claim that 36.70%-55.70% of tasks contain known CVEs depends on PinTrace's 1,000 Stack Overflow tasks being representative of real-world LLM prompting for library-dependent code, yet no validation (e.g., diversity metrics, comparison to actual usage logs, or sampling rationale) is reported. This is load-bearing for generalizing the risk surface beyond the benchmark.
Authors: PinTrace was constructed by curating 1,000 Stack Overflow tasks that explicitly involve third-party library imports in Python, selected to mirror common developer queries to LLMs. The curation prioritized diversity across domains such as data processing, web development, and scientific computing. We agree that additional details on sampling rationale and task characteristics would strengthen the paper. In revision, we will add a dedicated subsection describing the curation criteria, library distribution statistics, and a limitations discussion on generalizability. Direct comparison to proprietary usage logs from LLM providers is not possible without access to such data, but the observed convergence on risky versions across 10 distinct models supports the systemic nature of the risk independent of any single benchmark. revision: partial
-
Referee: [§4] §4 (Version Extraction and CVE Matching): The automated pipeline for extracting version strings from generated code and matching to NVD/CVE databases reports no precision/recall figures, manual validation set, or inter-rater reliability checks. Without these, selection bias or false positives in parsing (e.g., advisory text treated as versions) could directly inflate the CVE percentages and severity distributions, which underpin the main empirical claims.
Authors: Version strings are extracted via a hybrid approach using Python's ast parser for import statements combined with targeted regex for version specifiers (e.g., in requirements or comments). Matching to CVEs uses exact version lookup in the NVD database. We did not include validation metrics in the original submission. In the revised manuscript, we will report results from a manual audit of a random sample of 200 generated outputs, including precision and recall for extraction and matching, along with the validation protocol. No instances of advisory text being misparsed as versions were encountered during pipeline development. revision: yes
-
Referee: [§5.2-5.3] §5.2-5.3 (Compatibility Experiments): The attribution of low static (19.70%-63.20%) and dynamic (6.49%-48.62%) compatibility rates to version selection rather than code quality relies on controlled experiments, but the construction of test cases and isolation of confounding factors (e.g., task selection bias) are not detailed sufficiently to rule out alternative explanations for the observed failures.
Authors: The controlled experiments included ablations where the same generated code was tested under different version constraints, and separate runs with externally provided correct versions. Dynamic tests were derived directly from the functional requirements in the original Stack Overflow posts. We acknowledge that more detail on test construction and bias controls is needed. In revision, we will expand the experimental section with additional descriptions of test case derivation, how library-specific functionality was covered, and further results isolating version effects from code quality. These additions will better substantiate the attribution to version selection. revision: partial
Circularity Check
No circularity: purely empirical measurement study
full rationale
This paper conducts a large-scale empirical measurement of LLM-generated code for library version specifications, CVE presence, severity, compatibility, and related statistics across 10 models on a fixed benchmark of 1,000 Stack Overflow tasks. It reports observed frequencies (e.g., 36.70%-55.70% tasks with known CVEs) and percentages directly from automated extraction and database matching. No equations, fitted parameters, derivations, predictions, or ansatzes appear in the provided text. Central claims rest on direct counts and comparisons rather than any self-referential reduction or load-bearing self-citation chain. The study is self-contained against external benchmarks (NVD/CVE databases, static/dynamic testing) with no internal circularity.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The 1,000 curated Stack Overflow tasks accurately reflect typical programming scenarios that involve third-party library imports.
- domain assumption Public CVE databases provide complete and accurate vulnerability information for the library versions identified in generated code.
Reference graph
Works this paper leans on
-
[1]
Rahaf Alkhadra, Joud Abuzaid, Mariam AlShammari, and Nazeeruddin Mohammad. 2021. Solar winds hack: In-depth analysis and countermeasures. In2021 12th International Conference on Computing Communication and Networking Technologies (ICCCNT). IEEE, IEEE, Kharagpur, India, 1–7. doi:10.1109/ICCCNT51525.2021.9579611
-
[2]
Astral. 2024. uv: An Extremely Fast Python Package Installer and Resolver. https://docs.astral.sh/uv/
2024
-
[3]
Astral. 2025. ty: A Fast Type Checker and Language Server for Python. https://docs.astral.sh/ty/
2025
-
[4]
Bndr and contributors. 2024. pipreqs: Package-to-Import Name Mapping. https://github.com/bndr/pipreqs/blob/ master/pipreqs/mapping. Accessed: February 2026
2024
-
[5]
Shih-Chieh Dai, Jun Xu, and Guanhong Tao. 2026. Rethinking the Evaluation of Secure Code Generation. InProceedings of the 48th IEEE/ACM International Conference on Software Engineering. doi:10.48550/arXiv.2503.15554
-
[6]
Andreas Dann, Ben Hermann, and Eric Bodden. 2023. UpCy: Safely Updating Outdated Dependencies. InProceedings of the 45th International Conference on Software Engineering(Melbourne, Victoria, Australia)(ICSE ’23). IEEE Press, 233–244. doi:10.1109/ICSE48619.2023.00031
-
[7]
Yanjun Fu, Ethan Baker, Yu Ding, and Yizheng Chen. 2024. Constrained Decoding for Secure Code Generation. arXiv:2405.00218 doi:10.48550/arXiv.2405.00218
-
[8]
Yujia Fu, Peng Liang, Amjed Tahir, et al. 2025. Security Weaknesses of Copilot-Generated Code in GitHub Projects: An Empirical Study.ACM Transactions on Software Engineering and Methodology34, 8 (2025), 1–34. doi:10.1145/3716848
-
[9]
Kai Gao, Runzhi He, Bing Xie, and Minghui Zhou. 2024. Characterizing Deep Learning Package Supply Chains in PyPI: Domains, Clusters, and Disengagement.ACM Trans. Softw. Eng. Methodol.33, 4, Article 97 (April 2024), 27 pages. doi:10.1145/3640336
-
[10]
Ruofan Gao, Amjed Tahir, Peng Liang, Teo Susnjak, and Foutse Khomh. 2025. A Survey of Bugs in AI-Generated Code. arXiv:2512.05239 doi:10.48550/arXiv.2512.05239
-
[11]
GitHub. 2025. GitHub Copilot: AI Code Generation Statistics. https://github.blog/news-insights/research/
2025
-
[12]
GitHub. 2025. Octoverse 2025: A New Developer Joins GitHub Every Second as AI Leads TypeScript to #1. https: //github.blog/news-insights/octoverse/
2025
-
[13]
Google. 2021. OSV: Open Source Vulnerabilities. https://osv.dev
2021
-
[14]
Mohammad Saqib Hasan, Saikat Chakraborty, Santu Karmaker, and Niranjan Balasubramanian. 2025. Teaching an old LLM secure coding: Localized preference optimization on distilled preferences. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 26039–26057
2025
-
[15]
Hao He, Bogdan Vasilescu, and Christian Kästner. 2025. Pinning Is Futile: You Need More Than Local Dependency Versioning to Defend against Supply Chain Attacks.Proc. ACM Softw. Eng.2, FSE, Article FSE013 (June 2025), 24 pages. doi:10.1145/3715728
-
[16]
Junda He, Christoph Treude, and David Lo. 2025. LLM-Based Multi-Agent Systems for Software Engineering: Literature Review, Vision, and the Road Ahead.ACM Trans. Softw. Eng. Methodol.34, 5, Article 124 (May 2025), 30 pages. doi:10.1145/3712003
-
[17]
Jingxuan He, Mark Vero, Gabriela Krasnopolska, and Martin Vechev. 2024. Instruction Tuning for Secure Code Generation. InInternational Conference on Machine Learning. PMLR, 18043–18062
2024
-
[18]
Runzhi He, Hao He, Yuxia Zhang, and Minghui Zhou. 2023. Automating Dependency Updates in Practice: An Exploratory Study on GitHub Dependabot.IEEE Trans. Softw. Eng.49, 8 (Aug. 2023), 4004–4022. doi:10.1109/TSE.2023. 3278129
-
[19]
Xinyi Hou, Yanjie Zhao, Yue Liu, Zhou Yang, Kailong Wang, Li Li, Xiapu Luo, David Lo, John Grundy, and Haoyu Wang. 2024. Large Language Models for Software Engineering: A Systematic Literature Review.ACM Trans. Softw. Eng. Methodol.33, 8, Article 220 (Dec. 2024), 79 pages. doi:10.1145/3695988
-
[20]
Jinchang Hu, Lyuye Zhang, Chengwei Liu, Sen Yang, Song Huang, and Yang Liu. 2024. Empirical Analysis of Vulnerabilities Life Cycle in Golang Ecosystem. In2024 IEEE/ACM 46th International Conference on Software Engineering (ICSE). IEEE, Lisbon, Portugal, 2618–2630. doi:10.1145/3597503.363923
-
[21]
Nasif Imtiaz, Seaver Thorn, and Laurie Williams. 2021. A Comparative Study of Vulnerability Reporting by Software Composition Analysis Tools. InProceedings of the 15th ACM/IEEE International Symposium on Empirical Software Engineering and Measurement (ESEM). ACM, Bari, Italy, Article 5. doi:10.1145/3475716.3475769
-
[22]
Nasif Imtiaz and Laurie Williams. 2023. Are Your Dependencies Code Reviewed?: Measuring Code Review Coverage in Dependency Updates .IEEE Transactions on Software Engineering49, 11 (Nov. 2023), 4932–4945. doi:10.1109/TSE. 2023.3319509
work page doi:10.1109/tse 2023
- [23]
-
[24]
Damien Jaime, Pascal Poizat, Joyce El Haddad, and Thomas Degueule. 2024. Balancing the Quality and Cost of Updating Dependencies. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering , Vol. 1, No. 1, Article . Publication date: May 2026. Correct Code, Vulnerable Dependencies: A Large Scale Measurement Study of LLM-...
-
[25]
Nihal Jain, Robert Kwiatkowski, Baishakhi Ray, Murali Krishna Ramanathan, and Varun Kumar. 2025. On Mitigating Code LLM Hallucinations with API Documentation. In2025 IEEE/ACM 47th International Conference on Software Engineering: Software Engineering in Practice (ICSE-SEIP). 237–248. doi:10.1109/ICSE-SEIP66354.2025.00027
-
[26]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2026. A Survey on Large Language Models for Code Generation.ACM Trans. Softw. Eng. Methodol.35, 2, Article 58 (Jan. 2026), 72 pages. doi:10.1145/3747588
-
[28]
Sachit Kuhar, Wasi Uddin Ahmad, Zijian Wang, Nihal Jain, Haifeng Qian, Baishakhi Ray, Murali Krishna Ramanathan, Xiaofei Ma, and Anoop Deoras. 2025. LibEvolutionEval: A Benchmark and Study for Version-Specific Code Generation. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Huma...
-
[29]
Empirical Software Engineering23(1), 384–417 (2018)
Raula Gaikovina Kula, Daniel M. German, Ali Ouni, Takashi Ishio, and Katsuro Inoue. 2018. Do developers update their library dependencies?Empirical Softw. Engg.23, 1 (Feb. 2018), 384–417. doi:10.1007/s10664-017-9521-5
-
[30]
Piergiorgio Ladisa, Henrik Plate, Matias Martinez, and Olivier Barais. 2023. SoK: Taxonomy of Attacks on Open-Source Software Supply Chains. In2023 IEEE Symposium on Security and Privacy (SP). IEEE, San Francisco, CA, USA, 1509–1526. doi:10.1109/SP46215.2023.10179304
-
[31]
Jasmine Latendresse, Naoures Day, SayedHassan Khatoonabadi, and Emad Shihab. 2025. The Software Librarian: Python Package Insights for Copilot. InProceedings of the 47th IEEE/ACM International Conference on Software Engineering: Companion Proceedings. 17–20. doi:10.1109/ICSE-Companion66252.2025.00014
-
[32]
Jasmine Latendresse, SayedHassan Khatoonabadi, Ahmad Abdellatif, and Emad Shihab. 2024. Is ChatGPT a Good Soft- ware Librarian? An Exploratory Study on the Use of ChatGPT for Software Library Recommendations. arXiv:2408.05128 doi:10.48550/arXiv.2408.05128
-
[33]
Jasmine Latendresse, SayedHassan Khatoonabadi, and Emad Shihab. 2025. How Robust Are LLM-Generated Library Imports? An Empirical Study Using Stack Overflow. arXiv:2507.10818 doi:10.48550/arXiv.2507.10818
-
[34]
Dong Li, Shanfu Shu, Meng Yan, et al. 2025. Improving Co-Decoding Based Security Hardening of Code LLMs Leveraging Knowledge Distillation.IEEE Transactions on Software Engineering51, 9 (2025), 2634–2650. doi:10.1109/TSE.2025.3591791
-
[35]
Dong Li, Meng Yan, Yaosheng Zhang, et al. 2024. CoSec: On-the-Fly Security Hardening of Code LLMs via Supervised Co-Decoding. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis. 1428–1439. doi:10.1145/3650212.3680371
-
[36]
Wei Li, Xin Zhang, Zhongxin Guo, Shaoguang Mao, Wen Luo, Guangyue Peng, Yangyu Huang, Houfeng Wang, and Scarlett Li. 2025. FEA-Bench: A Benchmark for Evaluating Repository-Level Code Generation for Feature Implementation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Wanxiang Che, Joyce ...
-
[37]
Bo Lin, Shangwen Wang, Yihao Qin, Liqian Chen, and Xiaoguang Mao. 2025. Give LLMs a Security Course: Securing Retrieval-Augmented Code Generation via Knowledge Injection. InProceedings of the 2025 ACM SIGSAC Conference on Computer and Communications Security(Taipei, Taiwan)(CCS ’25). Association for Computing Machinery, New York, NY, USA, 3356–3370. doi:1...
-
[38]
Chengwei Liu, Sen Chen, Lingling Fan, Bihuan Chen, Yang Liu, and Xin Peng. 2022. Demystifying the Vulnerability Propagation and Its Evolution via Dependency Trees in the npm Ecosystem. InProceedings of the 44th International Conference on Software Engineering. IEEE, Pittsburgh, PA, USA, 672–684. doi:10.1145/3510003.3510142
-
[39]
Zeyu Leo Liu, Shrey Pandit, Xi Ye, Eunsol Choi, and Greg Durrett. 2025. CodeUpdateArena: Benchmarking Knowledge Editing on API Updates. arXiv:2407.06249 doi:10.48550/arXiv.2407.06249
-
[40]
Tarek Mahmud, Meiru Che, and Guowei Yang. 2023. Detecting Android API Compatibility Issues With API Differences. IEEE Transactions on Software Engineering49, 7 (2023), 3857–3871. doi:10.1109/TSE.2023.3274153
-
[41]
Tarek Mahmud, Bin Duan, Meiru Che, Awatif Yasmin, Anne H. H. Ngu, and Guowei Yang. 2026. Automated Update of Android Deprecated API Usages With Large Language Models.IEEE Transactions on Software Engineering52, 1 (2026), 70–85. doi:10.1109/TSE.2025.3627897
-
[42]
Muller, Irina Rish, Samira Ebrahimi Kahou, and Massimo Caccia
Diganta Misra, Nizar Islah, Victor May, Brice Rauby, Zihan Wang, Justine Gehring, Antonio Orvieto, Muawiz Sajjad Chaudhary, Eilif B. Muller, Irina Rish, Samira Ebrahimi Kahou, and Massimo Caccia. 2025. GitChameleon 2.0: Evaluating AI Code Generation Against Python Library Version Incompatibilities. InNeurIPS 2025 Fourth Workshop on Deep , Vol. 1, No. 1, A...
2025
-
[43]
Shradha Neupane, Grant Holmes, Elizabeth Wyss, Drew Davidson, and Lorenzo De Carli. 2023. Beyond typosquatting: an in-depth look at package confusion. InProceedings of the 32nd USENIX Conference on Security Symposium(Anaheim, CA, USA)(SEC ’23). USENIX Association, USA, Article 193, 18 pages
2023
-
[44]
NTIA. 2019. Framing Software Component Transparency: Establishing a Common Software Bill of Material (SBOM). https://ntia.gov/files/ntia/publications/framingsbom_20191112.pdf
2019
-
[45]
NVD. 2021. CVE-2021-44228 Detail: Apache Log4j2 Remote Code Execution Vulnerability. https://nvd.nist.gov/vuln/ detail/CVE-2021-44228
2021
-
[46]
OpenAI. 2022. Tiktoken. https://github.com/openai/tiktoken. Accessed: February 2026
2022
-
[47]
Ivan Pashchenko, Duc-Ly Vu, and Fabio Massacci. 2020. A Qualitative Study of Dependency Management and Its Security Implications. InProceedings of the 2020 ACM SIGSAC Conference on Computer and Communications Security(Virtual Event, USA)(CCS ’20). Association for Computing Machinery, New York, NY, USA, 1513–1531. doi:10.1145/3372297.3417232
-
[48]
Serena Elisa Ponta, Henrik Plate, and Antonino Sabetta. 2020. Detection, Assessment and Mitigation of Vulnerabilities in Open Source Dependencies.Empirical Software Engineering25, 5 (2020), 3175–3215. doi:10.1007/s10664-020-09830-x
-
[49]
Piotr Przymus and Thomas Durieux. 2025. Wolves in the Repository: A Software Engineering Analysis of the XZ Utils Supply Chain Attack. InProceedings of the 22nd IEEE/ACM International Conference on Mining Software Repositories (MSR). IEEE, Ottawa, ON, Canada, 91–102. doi:10.1109/MSR66628.2025.00026
-
[50]
pypa. 2021. pip-audit. https://github.com/pypa/pip-audit. Accessed: February 2026
2021
-
[51]
Python. 2002. The Python Package Index (PyPI). https://pypi.org/. Accessed: February 2026
2002
-
[52]
Python. 2023. Python Release Python 3.12. https://www.python.org/downloads/release/python-3120/. Accessed: February 2026
2023
-
[53]
Amirali Sajadi, Binh Le, Anh Nguyen, Kostadin Damevski, and Preetha Chatterjee. 2025. Do LLMs Consider Security? An Empirical Study on Responses to Programming Questions.Empirical Software Engineering30, 4 (2025), 101. doi:10.1007/s10664-025-10658-6
-
[55]
Yijun Shen, Xiang Gao, Hailong Sun, and Yu Guo. 2025. Understanding vulnerabilities in software supply chains. Empirical Software Engineering30, 1 (2025), 20. doi:10.1007/s10664-024-10581-2
-
[56]
Claudio Di Sipio, Juri Di Rocco, Davide Di Ruscio, and Vladyslav Bulhakov. 2025. Addressing Popularity Bias in Third- Party Library Recommendations Using LLMs . In2025 IEEE International Conference on Software Analysis, Evolution and Reengineering - Companion (SANER-C). IEEE Computer Society, Los Alamitos, CA, USA, 33–40. doi:10.1109/SANER- C66551.2025.00012
-
[57]
snyk. 2021. SolarWinds Orion Security Breach: A Shift In The Software Supply Chain Paradigm. https://snyk.io/blog/ solarwinds-orion-security-breach-a-shift-in-the-software-supply-chain-paradigm/
2021
-
[58]
Sonatype. 2026. 2026 Software Supply Chain Report. https://www.sonatype.com/state-of-the-software-supply-chain/
2026
-
[59]
Joseph Spracklen, Raveen Wijewickrama, AHM Nazmus Sakib, Anindya Maiti, Bimal Viswanath, and Murtuza Jadliwala
-
[60]
In Proceedings of the 34th USENIX Conference on Security Symposium(Seattle, WA, USA)(SEC ’25)
We have a package for you! a comprehensive analysis of package hallucinations by code generating LLMs. In Proceedings of the 34th USENIX Conference on Security Symposium(Seattle, WA, USA)(SEC ’25). USENIX Association, USA, Article 190, 20 pages
-
[61]
Stack Exchange, Inc. 2026. Stack Exchange Data Dump. https://stackoverflow.com/help/data-dumps. Snapshot: Jan 6, 2026
2026
-
[62]
Stack Exchange, Inc. 2026. Stack Exchange Data Query. https://data.stackexchange.com/stackoverflow/query/edit/ 1903717#resultSets. Snapshot: April 15, 2026
2026
-
[63]
Stack Overflow. 2025. 2025 Stack Overflow Developer Survey. https://survey.stackoverflow.co/2025/
2025
-
[64]
Zeyu Sun, Jingzheng Wu, Xiang Ling, Yilin Wei, Tianyue Luo, and Yanjun Wu. 2025. Research on Key Technologies of SBOM in Software Supply Chain.Journal of Software36, 6 (June 2025), 2604. doi:10.13328/j.cnki.jos.007308
-
[65]
Timothée Thiéblemont. 2021. Griffe: Signatures for Entire Python Programs. https://mkdocstrings.github.io/griffe/
2021
-
[66]
Bin Wang, Wenjie Yu, Yilu Zhong, et al. 2025. AI Code in the Wild: Measuring Security Risks and Ecosystem Shifts of AI-Generated Code in Modern Software. arXiv:2512.18567 doi:10.48550/arXiv.2512.18567
-
[68]
Chong Wang, Kaifeng Huang, Jian Zhang, Yebo Feng, Lyuye Zhang, Yang Liu, and Xin Peng. 2025. LLMs Meet Library Evolution: Evaluating Deprecated API Usage in LLM-Based Code Completion. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE). 885–897. doi:10.1109/ICSE55347.2025.00245 , Vol. 1, No. 1, Article . Publication date: May 2026...
-
[69]
Chengjie Wang, Jingzheng Wu, Hao Lyu, Xiang Ling, Tianyue Luo, Yanjun Wu, and Chen Zhao. 2026. A Large Scale Empirical Analysis on the Adherence Gap between Standards and Tools in SBOM.ACM Trans. Softw. Eng. Methodol. (Jan. 2026). doi:10.1145/3788692 Just Accepted
-
[70]
Shenao Wang, Yanjie Zhao, Xinyi Hou, and Haoyu Wang. 2025. Large Language Model Supply Chain: A Research Agenda.ACM Trans. Softw. Eng. Methodol.34, 5, Article 147 (May 2025), 46 pages. doi:10.1145/3708531
-
[71]
Tongtong Wu, Rongyi Chen, Wenjie Du, et al. 2026. Environment-Aware Code Generation: How Far Are We?. In Proceedings of the 48th IEEE/ACM International Conference on Software Engineering. doi:10.48550/arXiv.2601.12262
-
[72]
Tongtong Wu, Weigang Wu, Xingyu Wang, et al. 2024. VersiCode: Towards Version-Controllable Code Generation. arXiv:2406.07411 doi:10.48550/arXiv.2406.07411
-
[73]
Yulun Wu, Zeliang Yu, Ming Wen, Qiang Li, Deqing Zou, and Hai Jin. 2023. Understanding the Threats of Upstream Vulnerabilities to Downstream Projects in the Maven Ecosystem. InProceedings of the 45th International Conference on Software Engineering(Melbourne, Victoria, Australia)(ICSE ’23). IEEE Press, 1046–1058. doi:10.1109/ICSE48619.2023. 00095
-
[74]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2025. Demystifying LLM-Based Software Engineering Agents.Proc. ACM Softw. Eng.2, FSE, Article FSE037 (June 2025), 24 pages. doi:10.1145/3715754
-
[75]
Yifan Xia, Zichen Xie, Peiyu Liu, Kangjie Lu, Yan Liu, Wenhai Wang, and Shouling Ji. 2025. Beyond Static Pattern Matching? Rethinking Automatic Cryptographic API Misuse Detection in the Era of LLMs.Proc. ACM Softw. Eng.2, ISSTA, Article ISSTA006 (June 2025), 24 pages. doi:10.1145/3728875
-
[76]
Quanjun Zhang, Chunrong Fang, Yang Xie, Yaxin Zhang, Shengcheng Yu, Weisong Sun, Yun Yang, and Zhenyu Chen
-
[77]
A survey on large language models for software engineering.Science China Information Sciences69, 4 (2026), 141102
2026
-
[78]
Ziyao Zhang, Chong Wang, Yanlin Wang, Ensheng Shi, Yuchi Ma, Wanjun Zhong, Jiachi Chen, Mingzhi Mao, and Zibin Zheng. 2025. LLM Hallucinations in Practical Code Generation: Phenomena, Mechanism, and Mitigation.Proc. ACM Softw. Eng.2, ISSTA, Article ISSTA022 (June 2025), 23 pages. doi:10.1145/3728894
-
[79]
Jianguo Zhao, Yuqiang Sun, Cheng Huang, et al . 2025. Towards Secure Code Generation with LLMs: A Study on Common Weakness Enumeration.IEEE Transactions on Software Engineering(2025), 1–16. doi:10.1109/TSE.2025.3619281
-
[80]
Tingwei Zhu, Zhongzhen Wen, Shangqing Liu, Yi Li, Tian Zhang, and Xin Xia. 2026. Assessing the Capability of LLMs for Deprecated API Usage Updating from Natural Language Descriptions.ACM Trans. Softw. Eng. Methodol.(April 2026). doi:10.1145/3808230 Just Accepted
-
[81]
Terry Yue Zhuo, Vu Minh Chien, Jenny Chim, Han Hu, Wenhao Yu, Ratnadira Widyasari, Imam Nur Bani Yusuf, Haolan Zhan, Junda He, Indraneil Paul, Simon Brunner, Chen GONG, James Hoang, Armel Randy Zebaze, Xiaoheng Hong, Wen-Ding Li, Jean Kaddour, Ming Xu, Zhihan Zhang, Prateek Yadav, Naman Jain, Alex Gu, Zhoujun Cheng, Jiawei Liu, Qian Liu, Zijian Wang, Davi...
2025
-
[82]
Terry Yue Zhuo, Junda He, Jiamou Sun, Zhenchang Xing, David Lo, John Grundy, and Xiaoning Du. 2026. Identifying and Mitigating API Misuse in Large Language Models.IEEE Transactions on Software Engineering52, 3 (2026), 855–873. doi:10.1109/TSE.2026.3651566 , Vol. 1, No. 1, Article . Publication date: May 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.