Recognition: unknown
INEUS: Iterative Neural Solver for High-Dimensional PIDEs
Pith reviewed 2026-05-08 13:06 UTC · model grok-4.3
The pith
INEUS replaces explicit nonlocal integrals in PIDEs with single-jump sampling and solves them as recursive regression problems using neural networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
INEUS is a meshfree iterative neural solver for PIDEs that reformulates the equation solving as a sequence of recursive regression problems by replacing the explicit evaluation of nonlocal jump integrals with single-jump sampling. Like PINNs, it learns global solutions over the space-time domain but treats nonlocal terms more efficiently and avoids differentiating full PIDE residuals. A contraction-based convergence proof supports its use for linear PIDEs, and experiments confirm accurate solutions for both linear and nonlinear high-dimensional cases.
What carries the argument
Single-jump sampling that substitutes for full nonlocal integral evaluation, enabling the reformulation of PIDE solving into recursive regression problems solved iteratively by neural networks.
If this is right
- Accurate and scalable solutions are obtained for various high-dimensional linear and nonlinear PIDEs.
- Nonlocal terms are treated more efficiently without needing to differentiate full residuals.
- Convergence is guaranteed for linear PIDEs through a contraction-based proof.
- The method learns solutions globally over the entire space-time domain.
Where Pith is reading between the lines
- Applications in areas like option pricing under jump-diffusion models could benefit from this scalability in high dimensions.
- Extensions to other types of nonlocal equations might be possible by adapting the sampling strategy.
- Combining this with other neural PDE solvers could lead to hybrid methods for mixed local-nonlocal problems.
Load-bearing premise
Single-jump sampling can replace explicit nonlocal integral evaluation while preserving accuracy and allowing the recursive regressions to converge to the true solution.
What would settle it
Running INEUS on a high-dimensional linear PIDE with a known closed-form solution and observing whether the neural approximation converges to it as the number of iterations increases, consistent with the contraction proof.
Figures










read the original abstract
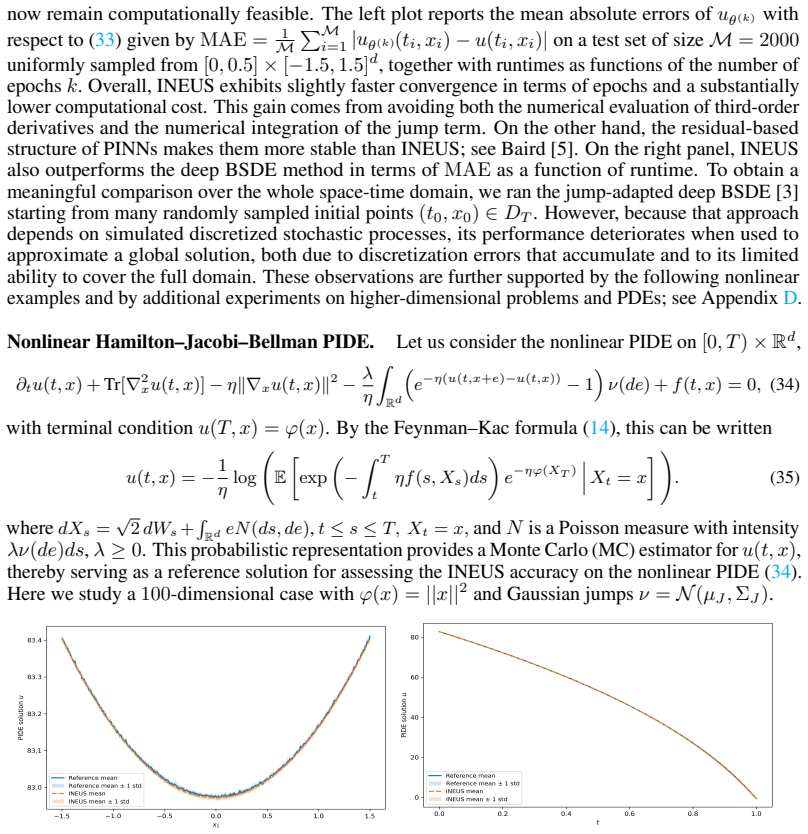
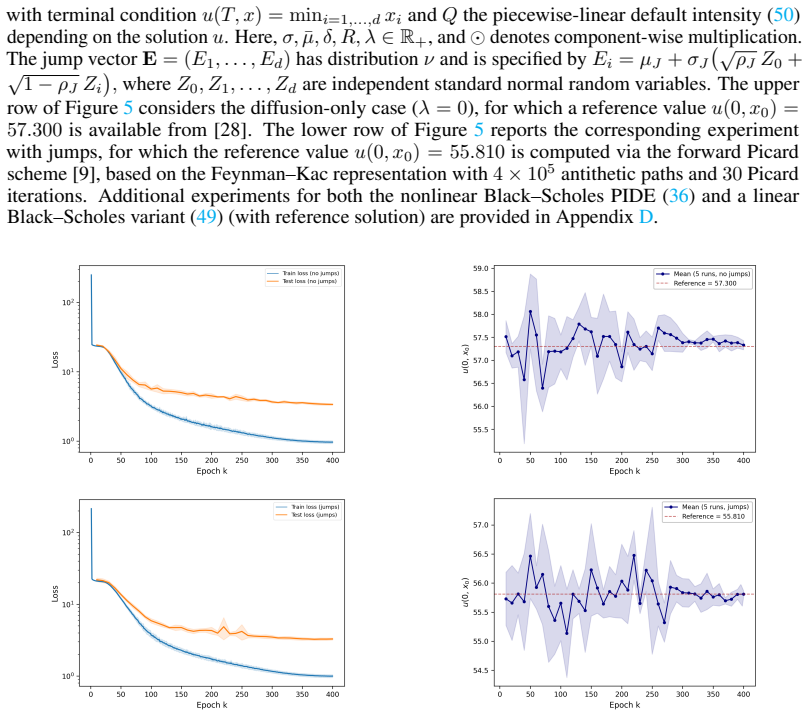
In this paper, we introduce INEUS, a meshfree iterative neural solver for partial integro-differential equations (PIDEs). The method replaces the explicit evaluation of nonlocal jump integrals with single-jump sampling and reformulates PIDE solving as a sequence of recursive regression problems. Like Physics-Informed Neural Networks (PINNs), INEUS learns global solutions over the entire space-time domain, yet it offers a more efficient treatment of nonlocal terms and avoids the computationally expensive differentiation of full PIDE residuals. These features make INEUS particularly well suited for high-dimensional PDEs and PIDEs. Supported by a contraction-based convergence proof for linear PIDEs, our numerical experiments show that INEUS delivers accurate and scalable solutions for various high-dimensional linear and nonlinear examples.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces INEUS, a meshfree iterative neural solver for high-dimensional partial integro-differential equations (PIDEs). It reformulates the PIDE as a sequence of recursive regression problems by replacing explicit nonlocal jump integrals with single-jump Monte Carlo sampling, avoiding full residual differentiation as in PINNs. A contraction-based convergence proof is given for linear PIDEs, and numerical experiments claim accurate, scalable solutions for both linear and nonlinear high-dimensional examples.
Significance. If the single-jump sampling preserves convergence to the viscosity solution, INEUS would represent a useful advance for high-dimensional PIDEs by providing an efficient, meshfree alternative that scales better than grid-based or explicit-integral methods. The iterative regression formulation and avoidance of expensive nonlocal evaluations are practical strengths; the contraction proof for the linear case adds rigor, though its applicability to the sampled implementation is central to the contribution.
major comments (3)
- [§4] §4 (Convergence analysis): The contraction mapping argument is stated for the exact integral operator of the linear PIDE. However, the algorithm in §3 approximates the nonlocal term by single-jump sampling, whose Monte Carlo variance does not vanish with iteration count and scales with dimension. No error bound or modified contraction estimate is provided that absorbs this stochastic perturbation, so the proof does not directly establish convergence of the implemented method.
- [§5] §5 (Numerical experiments, nonlinear cases): No theoretical guarantee is supplied for nonlinear PIDEs, yet the abstract and experiments claim accurate solutions for nonlinear high-dimensional examples. The recursive regressions rely on the same single-jump estimator; without an analysis showing that sampling error does not prevent convergence to the viscosity solution, the experimental results remain vulnerable to post-hoc tuning of sampling or network architecture.
- [§3] §3 (Method): The claim that single-jump sampling 'preserves accuracy' while enabling recursive regressions is load-bearing for both the linear proof and the nonlinear experiments. An explicit bound on the bias/variance introduced at each iteration, or a comparison against exact-integral baselines in moderate dimensions, is required to substantiate scalability claims in high dimensions.
minor comments (2)
- [§2-3] Notation for the jump measure and sampling distribution should be introduced once and used consistently across the method and proof sections.
- [Abstract] The abstract states 'supported by a contraction-based convergence proof,' but the proof applies only to linear PIDEs; this scope limitation should be stated explicitly in the abstract and introduction.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, providing clarifications on the scope of our results and committing to targeted revisions that acknowledge limitations while strengthening the manuscript's presentation of the method.
read point-by-point responses
-
Referee: [§4] The contraction mapping argument is stated for the exact integral operator of the linear PIDE. However, the algorithm in §3 approximates the nonlocal term by single-jump sampling, whose Monte Carlo variance does not vanish with iteration count and scales with dimension. No error bound or modified contraction estimate is provided that absorbs this stochastic perturbation, so the proof does not directly establish convergence of the implemented method.
Authors: We agree that the contraction mapping in §4 applies strictly to the exact integral operator. The single-jump sampling introduces persistent Monte Carlo variance that does not vanish with iterations and can scale with dimension. A full modified contraction estimate absorbing this stochastic error would require substantial additional analysis beyond the current scope. In the revision we will insert a new paragraph in §4 that explicitly discusses the approximation, notes that variance can be controlled by increasing samples per iteration, and highlights that the numerical experiments provide empirical support for convergence of the implemented algorithm despite the perturbation. revision: partial
-
Referee: [§5] No theoretical guarantee is supplied for nonlinear PIDEs, yet the abstract and experiments claim accurate solutions for nonlinear high-dimensional examples. The recursive regressions rely on the same single-jump estimator; without an analysis showing that sampling error does not prevent convergence to the viscosity solution, the experimental results remain vulnerable to post-hoc tuning of sampling or network architecture.
Authors: The referee is correct that our convergence analysis covers only the linear case. For nonlinear PIDEs we report only numerical accuracy. We will revise the abstract, §5, and the conclusion to state clearly that the nonlinear results are empirical observations without a supporting convergence proof. We will also add a short discussion of how sampling error is managed in practice through validation-based hyperparameter selection, thereby reducing the impression that the results rely on post-hoc tuning. revision: yes
-
Referee: [§3] The claim that single-jump sampling 'preserves accuracy' while enabling recursive regressions is load-bearing for both the linear proof and the nonlinear experiments. An explicit bound on the bias/variance introduced at each iteration, or a comparison against exact-integral baselines in moderate dimensions, is required to substantiate scalability claims in high dimensions.
Authors: To substantiate the accuracy claim we will add to §3 both an explicit variance expression for the single-jump Monte Carlo estimator and a new set of moderate-dimensional experiments (d=2 to d=5) that directly compare single-jump sampling against exact-integral evaluation on the same problems. These comparisons will quantify the introduced bias and variance and demonstrate that the error remains small enough to preserve the observed accuracy, thereby supporting the scalability statements for higher dimensions. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper's central claims rest on a contraction-mapping convergence proof for the iterative scheme applied to linear PIDEs (with the nonlocal term treated exactly) and on separate numerical experiments for both linear and nonlinear cases. No step in the provided abstract or description reduces a claimed prediction or uniqueness result to a fitted parameter, self-citation, or ansatz that is defined by the method itself. The single-jump sampling is presented as a practical replacement for the integral operator rather than as a quantity whose accuracy is guaranteed by construction; any gap between the exact proof and the stochastic estimator is a question of error analysis, not circularity. The derivation therefore remains self-contained against external mathematical benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Single-jump sampling replaces full integral evaluation without introducing bias that prevents convergence.
- domain assumption The sequence of regression problems contracts to the true PIDE solution for linear cases.
Reference graph
Works this paper leans on
-
[1]
Abergel and R
F. Abergel and R. Tachet. A nonlinear partial integro-differential equation from mathematical finance. Discrete and Continuous Dynamical Systems. Series A, 27(3):907–917, 2010
2010
-
[2]
Allen-Zhu, Y
Z. Allen-Zhu, Y . Li, and Z. Song. A convergence theory for deep learning via over-parameterization. In International Conference on Machine Learning, pages 242–252. PMLR, 2019
2019
-
[3]
Andersson, A
K. Andersson, A. Gnoatto, M. Patacca, and A. Picarelli. A deep solver for BSDEs with jumps.SIAM Journal on Financial Mathematics, 16(3):875–911, 2025
2025
-
[4]
Applebaum.Lévy Processes and Stochastic Calculus
D. Applebaum.Lévy Processes and Stochastic Calculus. Cambridge University Press, 2009
2009
-
[5]
L. Baird. Residual algorithms: Reinforcement learning with function approximation. InMachine Learning Proceedings 1995, pages 30–37. Elsevier, 1995
1995
-
[6]
Bansal, P
S. Bansal, P. Boro, and N. Srinivasan. Application of physics informed neural networks to partial integro- differential equations in financial modeling and decision making.Applied Soft Computing, 186:114208, 2026
2026
-
[7]
C. Beck, S. Becker, P. Cheridito, A. Jentzen, and A. Neufeld. Deep splitting method for parabolic PDEs. SIAM Journal on Scientific Computing, 43(5):A3135–A3154, 2021
2021
-
[8]
C. Beck, S. Becker, P. Grohs, N. Jaafari, and A. Jentzen. Solving the Kolmogorov PDE by means of deep learning.Journal of Scientific Computing, 88(3):73, 2021
2021
-
[9]
Bender and R
C. Bender and R. Denk. A forward scheme for backward SDEs.Stochastic Processes and Their Applica- tions, 117(12):1793–1812, 2007
2007
-
[10]
Berg and K
J. Berg and K. Nyström. A unified deep artificial neural network approach to partial differential equations in complex geometries.Neurocomputing, 317:28–41, 2018
2018
-
[11]
Blechschmidt and O
J. Blechschmidt and O. G. Ernst. Three ways to solve partial differential equations with neural networks—A review.GAMM-Mitteilungen, 44(2):e202100006, 2021
2021
-
[12]
Bouchard.Introduction to Stochastic Control of Mixed Diffusion Processes, Viscosity Solutions and Applications in Finance and Insurance
B. Bouchard.Introduction to Stochastic Control of Mixed Diffusion Processes, Viscosity Solutions and Applications in Finance and Insurance. Ceremade Lecture Notes, 2021
2021
-
[13]
S. Cai, Z. Mao, Z. Wang, M. Yin, and G. E. Karniadakis. Physics-informed neural networks (PINNs) for fluid mechanics: A review.Acta Mechanica Sinica, 37:1727–1738, 2021
2021
-
[14]
Chan-Wai-Nam, J
Q. Chan-Wai-Nam, J. Mikael, and X. Warin. Machine learning for semi linear PDEs.Journal of Scientific Computing, 79(3):1667–1712, 2019
2019
-
[15]
P. Cheridito, J.-L. Dupret, and D. Hainaut. Deep learning for continuous-time stochastic control with jumps.arXiv preprint arXiv:2505.15602, 2025
-
[16]
Cont and E
R. Cont and E. V oltchkova. A finite difference scheme for option pricing in jump diffusion and exponential Lévy models.SIAM Journal on Numerical Analysis, 43(4):1596–1626, 2005
2005
-
[17]
S. Du, J. Lee, H. Li, L. Wang, and X. Zhai. Gradient descent finds global minima of deep neural networks. InInternational Conference on Machine Learning, pages 1675–1685. PMLR, 2019
2019
-
[18]
Duarte, D
V . Duarte, D. Duarte, and D. H. Silva. Machine learning for continuous-time finance.The Review of Financial Studies, 37(11):3217–3271, 2024
2024
-
[19]
Dupret and D
J.-L. Dupret and D. Hainaut. Deep learning for high-dimensional continuous-time stochastic optimal control without explicit solution.Operations Research, 2026
2026
-
[20]
Durrett.Probability: Theory and Examples
R. Durrett.Probability: Theory and Examples. Cambridge University Press, fifth edition, 2019
2019
-
[21]
W. E and B. Yu. The deep Ritz method: A deep learning-based numerical algorithm for solving variational problems.Communications in Mathematics and Statistics, 6:1–12, 2018
2018
-
[22]
Frey and V
R. Frey and V . Köck. Deep neural network algorithms for parabolic PIDEs and applications in insurance and finance.Computation, 10(11):201, 2022
2022
-
[23]
Frey and V
R. Frey and V . Köck. Convergence analysis of the deep splitting scheme: The case of partial integro- differential equations and the associated forward backward SDEs with jumps.SIAM Journal on Scientific Computing, 47(1):A527–A552, 2025. 10
2025
-
[24]
A. Gnoatto, K. Oberpriller, and A. Picarelli. Convergence of a Deep BSDE solver with jumps.arXiv preprint arXiv:2501.09727, 2025
-
[25]
Gobet, J.-P
E. Gobet, J.-P. Lemor, and X. Warin. A regression-based Monte Carlo method to solve backward stochastic differential equations.The Annals of Applied Probability, 15(3):2172–2202, 2005
2005
-
[26]
Goswami, J
A. Goswami, J. Patel, and P. Shevgaonkar. A system of non-local parabolic PDE and application to option pricing.Stochastic Analysis and Applications, 34(5):893–905, 2016
2016
-
[27]
J. Han, A. Jentzen, et al. Deep learning-based numerical methods for high-dimensional parabolic partial differential equations and backward stochastic differential equations.Communications in Mathematics and Statistics, 5(4):349–380, 2017
2017
-
[28]
J. Han, A. Jentzen, and W. E. Solving high-dimensional partial differential equations using deep learning. Proceedings of the National Academy of Sciences, 115(34):8505–8510, 2018
2018
-
[29]
G. E. Karniadakis, I. G. Kevrekidis, L. Lu, P. Perdikaris, S. Wang, and L. Yang. Physics-informed machine learning.Nature Reviews Physics, 3(6):422–440, 2021
2021
-
[30]
Kartik and N
M. Kartik and N. T. Shah. Physics-informed neural networks for option pricing and hedging in illiquid jump markets. InProceedings of the 2025 3rd International Conference on Machine Learning and Pattern Recognition, pages 88–96, 2025
2025
-
[31]
N. I. Kavallaris and T. Suzuki.Non-local Partial Differential Equations for Engineering and Biology, volume 31 ofMathematics for Industry. Springer, 2018
2018
-
[32]
D. P. Kingma and J. Ba. Adam: A method for stochastic optimization. InProceedings of the 3rd International Conference on Learning Representations. arXiv preprint arXiv:1412.6980, 2015
work page internal anchor Pith review arXiv 2015
-
[33]
Kwon and Y
Y . Kwon and Y . Lee. A second-order finite difference method for option pricing under jump-diffusion models.SIAM Journal on Numerical Analysis, 49(6):2598–2617, 2011
2011
-
[34]
Liao and P
Y . Liao and P. Ming. Deep Nitsche method: Deep Ritz method with essential boundary conditions. Communications in Computational Physics, 29:1365–1384, 2021
2021
-
[35]
L. Lu, R. Pestourie, W. Yao, Z. Wang, F. Verdugo, and S. G. Johnson. Physics-informed neural networks with hard constraints for inverse design.SIAM Journal on Scientific Computing, 43(6):B1105–B1132, 2021
2021
-
[36]
L. Lu, H. Guo, X. Yang, and Y . Zhu. Temporal difference learning for high-dimensional PIDEs with jumps. SIAM Journal on Scientific Computing, 46(4):C349–C368, 2024
2024
-
[37]
L. Lyu, Z. Zhang, M. Chen, and J. Chen. MIM: A deep mixed residual method for solving high-order partial differential equations.Journal of Computational Physics, 452:110930, 2022
2022
-
[38]
Mishra and R
S. Mishra and R. Molinaro. Physics informed neural networks for simulating radiative transfer.Journal of Quantitative Spectroscopy and Radiative Transfer, 270:107705, 2021
2021
-
[39]
Mowlavi and S
S. Mowlavi and S. Nabi. Optimal control of PDEs using physics-informed neural networks.Journal of Computational Physics, 473:111731, 2023
2023
-
[40]
A. Neufeld, P. Schmocker, and S. Wu. Full error analysis of the random deep splitting method for nonlinear parabolic PDEs and PIDEs.arXiv preprint arXiv:2405.05192, 2024
-
[41]
Quarteroni and A
A. Quarteroni and A. Valli.Numerical Approximation of Partial Differential Equations. Springer Berlin Heidelberg, 1994
1994
-
[42]
M. Raissi. Forward-backward stochastic neural networks: Deep learning of high-dimensional partial differential equations. InPeter Carr Gedenkschrift: Research Advances in Mathematical Finance, pages 637–655. 2024
2024
-
[43]
M. Raissi, P. Perdikaris, and G. E. Karniadakis. Physics informed deep learning (Part 1): Data-driven solutions of nonlinear partial differential equations.arXiv preprint arXiv:1711.10561, 2017
work page Pith review arXiv 2017
-
[44]
Raissi, P
M. Raissi, P. Perdikaris, and G. E. Karniadakis. Physics-informed neural networks: A deep learning framework for solving forward and inverse problems involving nonlinear partial differential equations. Journal of Computational Physics, 378:686–707, 2019
2019
- [45]
-
[46]
Sirignano and K
J. Sirignano and K. Spiliopoulos. DGM: A deep learning algorithm for solving partial differential equations. Journal of Computational Physics, 375:1339–1364, 2018
2018
-
[47]
Šolín.Partial Differential Equations and the Finite Element Method
P. Šolín.Partial Differential Equations and the Finite Element Method. John Wiley & Sons, 2005
2005
-
[48]
S. Wang, X. Yu, and P. Perdikaris. When and why PINNs fail to train: A neural tangent kernel perspective. Journal of Computational Physics, 449:110768, 2022
2022
- [49]
-
[50]
C. Wu, M. Zhu, Q. Tan, Y . Kartha, and L. Lu. A comprehensive study of non-adaptive and residual-based adaptive sampling for physics-informed neural networks.Computer Methods in Applied Mechanics and Engineering, 403:115671, 2023
2023
- [51]
-
[52]
Yong and X
J. Yong and X. Y . Zhou.Stochastic Controls: Hamiltonian Systems and HJB Equations, volume 43. Springer Science & Business Media, 1999
1999
-
[53]
Z h 0 e− R s 0 c(Yu)du ∂tΨ +L[Ψ] +I[Ψ]−cΨ (Ys)ds Y0 =y # .(44) Rearranging (44) we have (ShΨ)(y)−Ψ(y) h = 1 h E
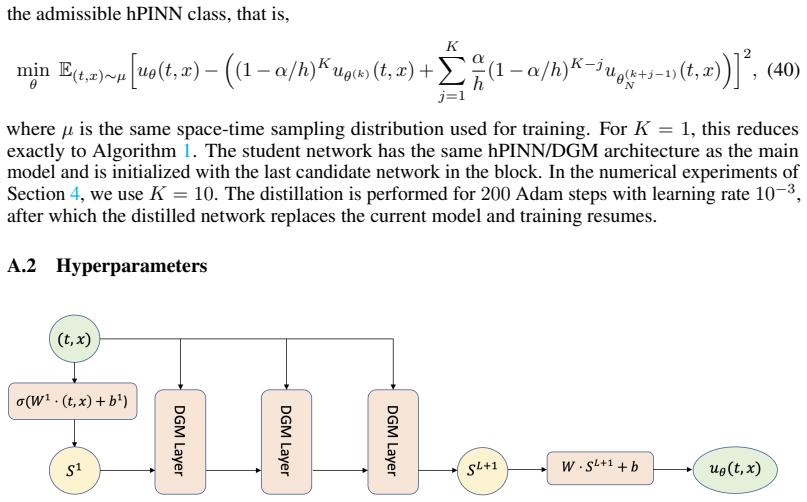
Y . Zang, G. Bao, X. Ye, and H. Zhou. Weak adversarial networks for high-dimensional partial differential equations.Journal of Computational Physics, 411:109409, 2020. 12 A Algorithm and network architecture A.1 INEUS algorithm We now describe the practical implementation of the full scheme in Proposition 3.5, which approxi- mates the relaxed contracting ...
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.