Recognition: unknown
A multi-scale information geometry reveals the structure of mutual information in neural populations
Pith reviewed 2026-05-08 03:12 UTC · model grok-4.3
The pith
A unique Riemannian geometry on stimulus space emerges from how distances contract with lost resolution and directly encodes mutual information in neural populations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A unique Riemannian representational geometry emerges from first principles governing how distances contract as stimulus resolution is lost through coarse-graining. This results in a multi-scale extension of the Fisher information metric that captures encoding structure from fine stimulus details to coarse global distinctions. The resulting geometry is exactly related to the mutual information encoded by the population: well-encoded stimulus directions are expanded while poorly encoded directions are contracted. The metric tensor can be estimated using diffusion models and, when applied to visual cortical responses, its eigenvectors identify the stimulus variations that contribute most to信息传
What carries the argument
The multi-scale Riemannian metric tensor obtained by enforcing first-principles contraction of distances under coarse-graining; it expands stimulus directions in proportion to their contribution to mutual information.
If this is right
- Eigenvectors of the estimated metric identify stimulus features that contribute most to mutual information transmission.
- The same geometry applies unchanged from fine local distinctions to coarse global ones.
- Diffusion-model estimation makes the metric computable for high-dimensional stimuli and large populations.
- Features recovered from cortical responses remain stable across different modelling choices.
Where Pith is reading between the lines
- The same contraction principle could be applied to artificial networks to test whether their internal geometries also expand informative directions.
- Behavioral discrimination thresholds measured at multiple scales could be compared directly against the predicted metric contractions.
- The framework offers a way to ask whether efficient coding theories should be stated at a single scale or across multiple coarse-graining levels simultaneously.
Load-bearing premise
Distances between stimuli must contract according to specific first principles whenever resolution is lost through coarse-graining.
What would settle it
Compute the metric tensor from a simple known neural population model whose mutual information contributions are calculated directly; the tensor eigenvectors will fail to align with the highest-information directions if the claim is false.
Figures
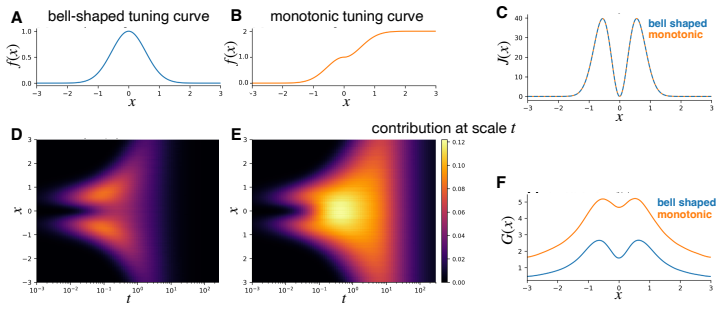


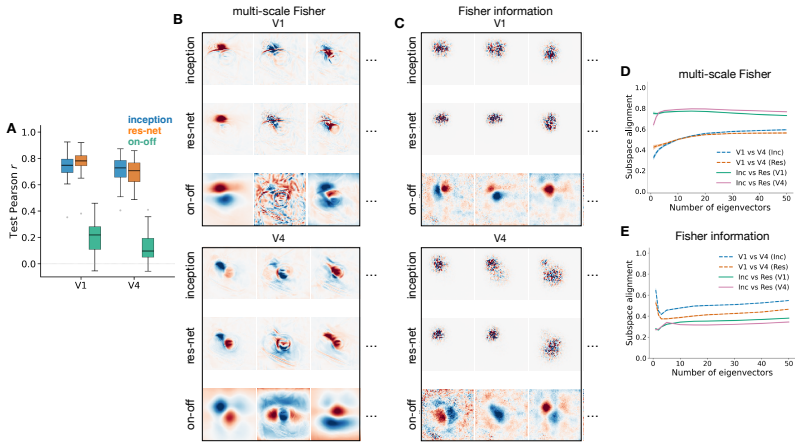
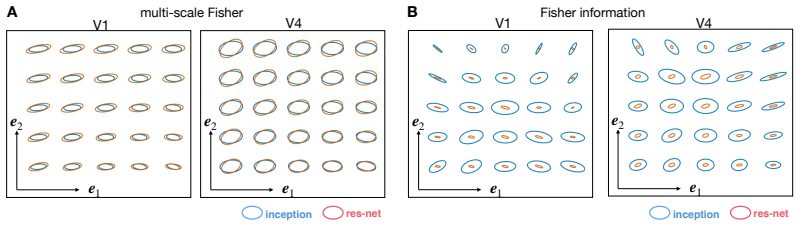

read the original abstract
Understanding how neural population responses represent sensory information is a central problem in systems neuroscience. One approach is to define a representational geometry on stimulus space in which distances reflect how reliably stimuli can be distinguished from neural activity. However, different constructions of these distances can lead to qualitatively different conclusions about the neural code. Here, we show that a unique Riemannian representational geometry emerges from first principles governing how distances contract as stimulus resolution is lost through coarse-graining. This results in a multi-scale extension of the Fisher information metric, capturing encoding structure from fine stimulus details to coarse global distinctions. The resulting geometry is exactly related to the mutual information encoded by the population: well encoded stimulus directions - those contributing more to mutual information - are expanded, whereas poorly encoded directions are contracted. The metric tensor can be estimated using diffusion models, making the framework practical for large neural populations and high-dimensional stimuli. Applied to visual cortical responses to natural images, the eigenvectors of the metric tensor identify stimulus variations that contribute most to information transmission, yielding interpretable features that are robust to modelling choices. Together, these results provide a principled, information-theoretic framework for characterising neural population codes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that a unique Riemannian representational geometry on stimulus space emerges from first principles on distance contraction under stimulus coarse-graining. This yields a multi-scale extension of the Fisher information metric whose local geometry is exactly related to the mutual information encoded by a neural population (well-encoded directions expanded, poorly encoded directions contracted). The metric tensor is estimated via diffusion models and applied to visual cortical responses to natural images, where its eigenvectors identify robust, interpretable stimulus features contributing most to information transmission.
Significance. If the derivation of uniqueness and the exact MI relation hold without auxiliary choices, the framework would supply a principled, parameter-free link between representational geometry and information content, extending Fisher geometry to multiple scales while remaining practical for high-dimensional data. The diffusion-model estimation and application to natural-image responses are concrete strengths that could make the approach widely usable in systems neuroscience.
major comments (2)
- [§3] §3 (derivation of the metric tensor): The contraction principles under coarse-graining are asserted to fix a unique Riemannian metric, but the text does not supply an explicit uniqueness proof or demonstrate that the stated axioms exclude other candidate metrics (e.g., other monotonic contractions or non-Riemannian extensions). Without this, the claim that the geometry 'emerges' uniquely remains unverified and load-bearing for the central result.
- [§4, Eq. (12)–(15)] §4, Eq. (12)–(15): The exact relation between the multi-scale metric and mutual information is presented as following directly from the contraction rule, yet the steps appear to introduce an additional identification (integration of the metric yielding KL terms). If this identification is not forced by the contraction axioms alone, the 'exactly related' assertion risks circularity and requires a clearer separation between derived and imposed elements.
minor comments (3)
- [Figure 2] Figure 2: the schematic of multi-scale coarse-graining lacks explicit stimulus examples or quantitative contraction factors, reducing clarity for readers unfamiliar with the construction.
- [Notation] Notation: the multi-scale parameter is introduced as λ but later appears as a vector in some equations; consistent vector/scalar distinction would aid readability.
- [Methods] The abstract states that the metric 'can be estimated using diffusion models' but the main text does not compare estimation error or bias against direct sampling methods; a short paragraph on this would strengthen the practical claim.
Simulated Author's Rebuttal
We thank the referee for their thoughtful and constructive comments, which have helped us clarify key aspects of the derivation and strengthen the manuscript. We address each major comment point by point below. Revisions have been made to incorporate explicit proofs and clearer logical separations where the original text was insufficiently detailed.
read point-by-point responses
-
Referee: [§3] §3 (derivation of the metric tensor): The contraction principles under coarse-graining are asserted to fix a unique Riemannian metric, but the text does not supply an explicit uniqueness proof or demonstrate that the stated axioms exclude other candidate metrics (e.g., other monotonic contractions or non-Riemannian extensions). Without this, the claim that the geometry 'emerges' uniquely remains unverified and load-bearing for the central result.
Authors: We agree that the original presentation would benefit from an explicit uniqueness argument. In the revised manuscript, we have added a new subsection in §3 that provides a rigorous uniqueness proof. Starting from the contraction axioms (monotonicity under coarse-graining, locality, and smoothness), we derive a functional equation for the metric tensor and show that its unique solution (up to global scaling) is the multi-scale extension of the Fisher metric. We further demonstrate that alternative monotonic contractions or non-Riemannian structures violate either the locality condition or the requirement that distances reduce to the Fisher metric in the infinitesimal limit. This establishes that the geometry emerges uniquely from the stated principles. revision: yes
-
Referee: [§4, Eq. (12)–(15)] §4, Eq. (12)–(15): The exact relation between the multi-scale metric and mutual information is presented as following directly from the contraction rule, yet the steps appear to introduce an additional identification (integration of the metric yielding KL terms). If this identification is not forced by the contraction axioms alone, the 'exactly related' assertion risks circularity and requires a clearer separation between derived and imposed elements.
Authors: We thank the referee for identifying the need for clearer separation. In the revised §4, we have restructured the derivation into two distinct stages. First, the metric tensor is obtained solely from the contraction axioms without reference to mutual information. Second, we show that integrating this metric along stimulus-space paths yields the mutual information contribution exactly, because the integral equals the expected KL divergence between the neural response distributions conditioned on nearby stimuli (a direct consequence of the definition of MI and the contraction rule). No auxiliary identification is imposed; the equality follows from the chain rule for KL divergences under the coarse-graining map. The revised text includes an explicit paragraph delineating these steps and a new equation clarifying the integration. revision: yes
Circularity Check
Derivation self-contained from independent contraction principles
full rationale
The paper states that a unique Riemannian geometry emerges from first principles on how distances contract under coarse-graining of stimulus resolution, yielding a multi-scale Fisher extension whose local properties relate to mutual information contributions. No quoted equations or steps reduce the claimed uniqueness or exact MI relation to a fitted parameter, self-citation chain, or definitional tautology; the contraction rules are presented as external inputs that fix the metric tensor, after which the MI link is derived rather than presupposed. The framework remains independent of the target result and does not rename known patterns or smuggle ansatzes via self-citation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Distances between stimuli contract in a specific, first-principles-governed manner when stimulus resolution is lost through coarse-graining.
Reference graph
Works this paper leans on
-
[1]
Matching categorical object representations in inferior temporal cortex of man and monkey.Neuron, 60(6):1126–1141, 2008
Nikolaus Kriegeskorte, Marieke Mur, Douglas A Ruff, Roozbeh Kiani, Jerzy Bodurka, Hossein Esteky, Keiji Tanaka, and Peter A Bandettini. Matching categorical object representations in inferior temporal cortex of man and monkey.Neuron, 60(6):1126–1141, 2008
2008
-
[2]
Quantifying differences in neural population activity with shape metrics.bioRxiv, pages 2025–01, 2025
Joao Barbosa, Amin Nejatbakhsh, Lyndon Duong, Sarah E Harvey, Scott L Brincat, Markus Siegel, Earl K Miller, and Alex H Williams. Quantifying differences in neural population activity with shape metrics.bioRxiv, pages 2025–01, 2025
2025
-
[3]
SVCCA: Singular vector canonical correlation analysis for deep learning dynamics and interpretability.Advances in Neural Information Processing Systems, 30, 2017
Maithra Raghu, Justin Gilmer, Jason Yosinski, and Jascha Sohl-Dickstein. SVCCA: Singular vector canonical correlation analysis for deep learning dynamics and interpretability.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[4]
Insights on representational similarity in neural networks with canonical correlation
Ari S Morcos, Maithra Raghu, and Samy Bengio. Insights on representational similarity in neural networks with canonical correlation. InAdvances in Neural Information Processing Systems, volume 31, pages 5732–5741, 2018
2018
-
[5]
Deep supervised, but not unsuper- vised, models may explain it cortical representation.PLoS computational biology, 10(11): e1003915, 2014
Seyed-Mahdi Khaligh-Razavi and Nikolaus Kriegeskorte. Deep supervised, but not unsuper- vised, models may explain it cortical representation.PLoS computational biology, 10(11): e1003915, 2014
2014
-
[6]
Similarity of neural network representations revisited
Simon Kornblith, Mohammad Norouzi, Honglak Lee, and Geoffrey Hinton. Similarity of neural network representations revisited. InInternational Conference on Machine Learning, pages 3519–3529. PMLR, 2019
2019
-
[7]
Springer, 2016
Shun-ichi Amari.Information geometry and its applications. Springer, 2016
2016
-
[8]
Neural tuning and representational geometry.Nature Reviews Neuroscience, 22(11):703–718, 2021
Nikolaus Kriegeskorte and Xue-Xin Wei. Neural tuning and representational geometry.Nature Reviews Neuroscience, 22(11):703–718, 2021
2021
-
[9]
Cambridge University Press, Cambridge, 2nd edition, 2009
David Applebaum.Lévy Processes and Stochastic Calculus, volume 116 ofCambridge Studies in Advanced Mathematics. Cambridge University Press, Cambridge, 2nd edition, 2009
2009
-
[10]
Evans.Partial Differential Equations, volume 19 ofGraduate Studies in Mathe- matics
Lawrence C. Evans.Partial Differential Equations, volume 19 ofGraduate Studies in Mathe- matics. American Mathematical Society, Providence, Rhode Island, 2nd edition, 2010
2010
-
[11]
Decompos- ing stimulus-specific sensory neural information via diffusion models
Steeve Laquitaine, Simone Azeglio, Carlo Paris, Ulisse Ferrari, and Matthew Chalk. Decompos- ing stimulus-specific sensory neural information via diffusion models. InAdvances in Neural Information Processing Systems, volume 38, 2025
2025
-
[12]
Tweedie’s formula and selection bias.Journal of the American Statistical Association, 106(496):1602–1614, 2011
Bradley Efron. Tweedie’s formula and selection bias.Journal of the American Statistical Association, 106(496):1602–1614, 2011
2011
-
[13]
Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems, 33:6840–6851, 2020
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in Neural Information Processing Systems, 33:6840–6851, 2020
2020
-
[14]
Classifier-free diffusion guidance
Jonathan Ho and Tim Salimans. Classifier-free diffusion guidance. InNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021
2021
-
[15]
Longxuan Yu, Xing Shi, Xianghao Kong, Tong Jia, and Greg Ver Steeg. Mmg: Mutual information estimation via the mmse gap in diffusion.arXiv preprint arXiv:2509.20609, 2025
-
[16]
Interpretable dif- fusion via information decomposition
Xianghao Kong, Ollie Liu, Han Li, Dani Yogatama, and Greg Ver Steeg. Interpretable dif- fusion via information decomposition. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[17]
Diffusion pid: Interpreting diffusion via partial information decomposition
Shaurya Dewan, Rushikesh Zawar, Prakanshul Saxena, Yingshan Chang, Andrew Luo, and Yonatan Bisk. Diffusion pid: Interpreting diffusion via partial information decomposition. Advances in Neural Information Processing Systems, 37:2045–2079, 2024
2045
-
[18]
Diffusion posterior sampling for general noisy inverse problems
Hyungjin Chung, Jeongsol Kim, Michael T McCann, Marc L Klasky, and Jong Chul Ye. Diffusion posterior sampling for general noisy inverse problems. InInternational Conference on Learning Representations, 2023. 11
2023
-
[19]
An extensive dataset of spiking activity to reveal the syntax of the ventral stream.Neuron, 113(4):539–553, 2025
Paolo Papale, Feng Wang, Matthew W Self, and Pieter R Roelfsema. An extensive dataset of spiking activity to reveal the syntax of the ventral stream.Neuron, 113(4):539–553, 2025
2025
-
[20]
Going deeper with convolutions
Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, and Andrew Rabinovich. Going deeper with convolutions. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1–9, 2015
2015
-
[21]
Deep residual learning for im- age recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for im- age recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016
2016
-
[22]
On the bures–wasserstein distance between positive definite matrices.Expositiones mathematicae, 37(2):165–191, 2019
Rajendra Bhatia, Tanvi Jain, and Yongdo Lim. On the bures–wasserstein distance between positive definite matrices.Expositiones mathematicae, 37(2):165–191, 2019
2019
-
[23]
Eigen-distortions of hierarchical representations.Advances in Neural Information Processing Systems, 30, 2017
Alexander Berardino, Valero Laparra, Johannes Ballé, and Eero Simoncelli. Eigen-distortions of hierarchical representations.Advances in Neural Information Processing Systems, 30, 2017
2017
-
[24]
Mutual information and minimum mean- square error in gaussian channels.IEEE Transactions on Information Theory, 51(4):1261–1282, 2005
Dongning Guo, Shlomo Shamai, and Sergio Verdú. Mutual information and minimum mean- square error in gaussian channels.IEEE Transactions on Information Theory, 51(4):1261–1282, 2005
2005
-
[25]
Information-theoretic diffusion
Xianghao Kong, Rob Brekelmans, and Greg Ver Steeg. Information-theoretic diffusion. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[26]
Fiquet, Florentin Guth, Jona Ballé, and Eero P
Guy Ohayon, Pierre-Étienne H. Fiquet, Florentin Guth, Jona Ballé, and Eero P. Simoncelli. Learning a distance measure from the information-estimation geometry of data. InThe F our- teenth International Conference on Learning Representations, 2026
2026
-
[27]
Statistical inference on representational geometries.Elife, 12:e82566, 2023
Heiko H Schütt, Alexander D Kipnis, Jörn Diedrichsen, and Nikolaus Kriegeskorte. Statistical inference on representational geometries.Elife, 12:e82566, 2023
2023
-
[28]
Generalized shape metrics on neural representations.Advances in Neural Information Processing Systems, 34:4738–4750, 2021
Alex H Williams, Erin Kunz, Simon Kornblith, and Scott Linderman. Generalized shape metrics on neural representations.Advances in Neural Information Processing Systems, 34:4738–4750, 2021
2021
-
[29]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 586–595, 2018
2018
-
[30]
Tuning landscapes of the ventral stream.Cell Reports, 41(6), 2022
Binxu Wang and Carlos R Ponce. Tuning landscapes of the ventral stream.Cell Reports, 41(6), 2022
2022
-
[31]
Discriminating image representations with principal distortions
Jenelle Feather, David Lipshutz, Sarah E Harvey, Alex H Williams, and Eero P Simoncelli. Discriminating image representations with principal distortions. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[32]
Comparing neural models using their perceptual discriminability predictions
Jingyang Zhou, Chanwoo Chun, Ajay Subramanian, and Eero P Simoncelli. Comparing neural models using their perceptual discriminability predictions. InProceedings of UniReps: the First Workshop on Unifying Representations in Neural Models, volume 243, pages 170–181. PMLR, 2024
2024
-
[33]
Information geometry of the retinal representation manifold.Advances in Neural Information Processing Systems, 36:44310–44322, 2023
Xuehao Ding, Dongsoo Lee, Joshua Melander, George Sivulka, Surya Ganguli, and Stephen Baccus. Information geometry of the retinal representation manifold.Advances in Neural Information Processing Systems, 36:44310–44322, 2023
2023
-
[34]
arXiv preprint arXiv:2206.08666 , year=
Konstantin F Willeke, Paul G Fahey, Mohammad Bashiri, Laura Pede, Max F Burg, Christoph Blessing, Santiago A Cadena, Zhiwei Ding, Konstantin-Klemens Lurz, Kayla Ponder, et al. The sensorium competition on predicting large-scale mouse primary visual cortex activity.arXiv preprint arXiv:2206.08666, 2022
-
[35]
The dynamic sensorium competition for predicting large-scale mouse visual cortex activity from videos.ArXiv, pages arXiv–2305, 2024
Polina Turishcheva, Paul G Fahey, Michaela Vystrˇcilová, Laura Hansel, Rachel Froebe, Kayla Ponder, Yongrong Qiu, Konstantin F Willeke, Mohammad Bashiri, Eric Wang, et al. The dynamic sensorium competition for predicting large-scale mouse visual cortex activity from videos.ArXiv, pages arXiv–2305, 2024. 12
2024
-
[36]
Majaj, Rishi Rajalingham, Elias B
Martin Schrimpf, Jonas Kubilius, Ha Hong, Najib J. Majaj, Rishi Rajalingham, Elias B. Issa, Kohitij Kar, Pouya Bashivan, Jonathan Prescott-Roy, Franziska Geiger, Kailyn Schmidt, Daniel L. K. Yamins, and James J. DiCarlo. Brain-score: Which artificial neural network for object recognition is most brain-like?bioRxiv, page 407007, 2018
2018
-
[37]
OmniMouse: Scaling properties of multi-modal, multi-task Brain Models on 150B Neural Tokens
Konstantin F Willeke, Polina Turishcheva, Alex Gilbert, Goirik Chakrabarty, Hasan A Bedel, Paul G Fahey, Yongrong Qiu, Marissa A Weis, Michaela Vystrˇcilová, Taliah Muhammad, et al. Omnimouse: Scaling properties of multi-modal, multi-task brain models on 150b neural tokens. arXiv preprint arXiv:2604.18827, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
The renormalization group: A probabilistic view.Il Nuovo Cimento B (1971-1996), 26(1):99–119, 1975
G Jona-Lasinio. The renormalization group: A probabilistic view.Il Nuovo Cimento B (1971-1996), 26(1):99–119, 1975
1971
-
[39]
Information loss under coarse graining: A geometric approach.Physical Review E, 98(5):052112, 2018
Archishman Raju, Benjamin B Machta, and James P Sethna. Information loss under coarse graining: A geometric approach.Physical Review E, 98(5):052112, 2018
2018
-
[40]
Information geometry and the renormalization group.Physical Review E, 92(5):052101, 2015
Reevu Maity, Subhash Mahapatra, and Tapobrata Sarkar. Information geometry and the renormalization group.Physical Review E, 92(5):052101, 2015
2015
-
[41]
Ya Le and Xuan S. Yang. Tiny imagenet visual recognition challenge. 2015. URL https: //api.semanticscholar.org/CorpusID:16664790
2015
-
[42]
Things: A database of 1,854 object concepts and more than 26,000 naturalistic object images.PloS one, 14(10):e0223792, 2019
Martin N Hebart, Adam H Dickter, Alexis Kidder, Wan Y Kwok, Anna Corriveau, Caitlin Van Wicklin, and Chris I Baker. Things: A database of 1,854 object concepts and more than 26,000 naturalistic object images.PloS one, 14(10):e0223792, 2019
2019
-
[43]
Re- thinking the inception architecture for computer vision
Christian Szegedy, Vincent Vanhoucke, Sergey Ioffe, Jon Shlens, and Zbigniew Wojna. Re- thinking the inception architecture for computer vision. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2818–2826, 2016
2016
-
[44]
Using goal-driven deep learning models to understand sensory cortex.Nature Neuroscience, 19(3):356–365, 2016
Daniel LK Yamins and James J DiCarlo. Using goal-driven deep learning models to understand sensory cortex.Nature Neuroscience, 19(3):356–365, 2016
2016
-
[45]
Torchvision: Pytorch’s computer vision library
TorchVision maintainers and contributors. Torchvision: Pytorch’s computer vision library. https://github.com/pytorch/vision, 2016
2016
-
[46]
Plenoptic: A platform for synthesizing model-optimized visual stimuli.Journal of Vision, 23(9):5822–5822, 2023
Lyndon Duong, Kathryn Bonnen, William Broderick, Pierre-Étienne Fiquet, Nikhil Parthasarathy, Thomas Yerxa, Xinyuan Zhao, and Eero Simoncelli. Plenoptic: A platform for synthesizing model-optimized visual stimuli.Journal of Vision, 23(9):5822–5822, 2023
2023
-
[47]
JHU press, 2013
Gene H Golub and Charles F Van Loan.Matrix computations. JHU press, 2013
2013
-
[48]
What representational similarity measures imply about decodable information
Sarah E Harvey, David Lipshutz, and Alex H Williams. What representational similarity measures imply about decodable information. InProceedings of UniReps: the Second Edition of the Workshop on Unifying Representations in Neural Models, volume 285, pages 140–151. PMLR, 2024. 13 A Relation between geometry and mutual information Recently, Laquitaine et al....
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.