Recognition: unknown
OmniMouse: Scaling properties of multi-modal, multi-task Brain Models on 150B Neural Tokens
Pith reviewed 2026-05-10 02:40 UTC · model grok-4.3
The pith
Mouse visual cortex models scale reliably with more neural data but show saturating gains from larger model sizes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Performance on neural, behavioral, and forecasting tasks improves consistently as the amount of training data grows, yet plateaus when the number of model parameters is increased, showing that current brain models operate in a data-limited regime despite the scale of 150 billion neural tokens.
What carries the argument
A single multi-modal, multi-task model that at test time flexibly performs neural prediction, behavioral decoding, neural forecasting, or any combination of the three.
If this is right
- Further increases in neural data volume should continue to raise performance across all three evaluation regimes.
- A single model can replace multiple specialized networks without loss of accuracy.
- Systematic data scaling opens the door to phase transitions in which qualitatively new capabilities appear once datasets become sufficiently large and diverse.
- Specialized single-task baselines are outperformed once the multi-task model is trained on the full data set.
Where Pith is reading between the lines
- The data-limited finding may explain why brain models have not yet exhibited the abrupt capability jumps observed in large language models.
- Similar scaling experiments on recordings from other brain areas or species could test whether the data-limited regime is general.
- Efforts to expand neural data collection may now yield higher returns than further architectural tuning.
Load-bearing premise
The reported scaling relationships are not produced by the specific model architectures, training procedures, or data splits chosen for the study.
What would settle it
A controlled experiment in which model size is increased while holding the data volume fixed and the new larger models still fail to improve performance would support the saturation claim; the opposite result would falsify it.
Figures






read the original abstract
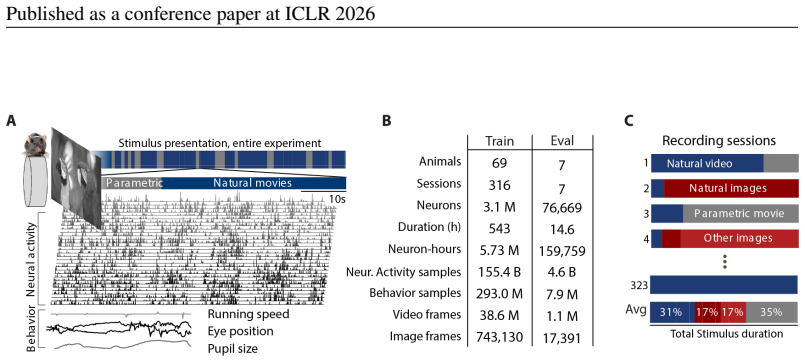
Scaling data and artificial neural networks has transformed AI, driving breakthroughs in language and vision. Whether similar principles apply to modeling brain activity remains unclear. Here we leveraged a dataset of 3.1 million neurons from the visual cortex of 73 mice across 323 sessions, totaling more than 150 billion neural tokens recorded during natural movies, images and parametric stimuli, and behavior. We train multi-modal, multi-task models that support three regimes flexibly at test time: neural prediction, behavioral decoding, neural forecasting, or any combination of the three. OmniMouse achieves state-of-the-art performance, outperforming specialized baselines across nearly all evaluation regimes. We find that performance scales reliably with more data, but gains from increasing model size saturate. This inverts the standard AI scaling story: in language and computer vision, massive datasets make parameter scaling the primary driver of progress, whereas in brain modeling -- even in the mouse visual cortex, a relatively simple system -- models remain data-limited despite vast recordings. The observation of systematic scaling raises the possibility of phase transitions in neural modeling, where larger and richer datasets might unlock qualitatively new capabilities, paralleling the emergent properties seen in large language models. Code available at https://github.com/enigma-brain/omnimouse.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OmniMouse, a multi-modal multi-task model trained on 150B neural tokens from 3.1M neurons across 73 mice and 323 sessions in visual cortex during natural movies, images, parametric stimuli, and behavior. It reports SOTA performance across neural prediction, behavioral decoding, and forecasting regimes, with performance scaling reliably with data volume but saturating with increases in model size, inverting standard AI scaling laws and implying that brain models remain data-limited.
Significance. If the scaling relationships are robust, the work would be significant for brain modeling by challenging the parameter-centric scaling paradigm from language and vision, emphasizing data collection needs even for a simple system like mouse V1, and suggesting possible phase transitions or emergent capabilities with larger datasets. The public code release supports reproducibility and is a clear strength.
major comments (2)
- [§4.2 and Abstract] §4.2 (Scaling with model size) and Abstract: The central inversion claim—that gains saturate with model size while continuing to rise with data—requires explicit confirmation that training compute (steps, epochs, or total FLOPs) was scaled with parameter count per standard practice. Without this, saturation could arise from fixed training budgets or unadjusted hyperparameters for larger models, undermining the data-limited regime interpretation.
- [§3 and scaling figures] §3 (Methods) and scaling figures: The manuscript lacks reported error bars, multiple random seeds, or ablation details on the multi-task objective and data splits for the scaling curves. This makes it difficult to rule out that the reported saturation is an artifact of architecture-specific optimization difficulties or implicit leakage in the multi-regime evaluation.
minor comments (2)
- [Abstract and §2.1] The abstract states '150 billion neural tokens' but the exact tokenization and session breakdown should be cross-referenced in §2.1 for precision.
- [Figure captions] Figure captions for scaling plots should explicitly state the number of runs and whether hyperparameters were re-tuned for each model size.
Simulated Author's Rebuttal
We thank the referee for their constructive and insightful comments. These have prompted us to strengthen the clarity and rigor of our scaling analyses. We address each major comment point-by-point below and have revised the manuscript accordingly.
read point-by-point responses
-
Referee: [§4.2 and Abstract] §4.2 (Scaling with model size) and Abstract: The central inversion claim—that gains saturate with model size while continuing to rise with data—requires explicit confirmation that training compute (steps, epochs, or total FLOPs) was scaled with parameter count per standard practice. Without this, saturation could arise from fixed training budgets or unadjusted hyperparameters for larger models, undermining the data-limited regime interpretation.
Authors: We agree that explicit confirmation of compute scaling is essential to support the data-limited interpretation. In our original experiments, we scaled training steps proportionally with model size (larger models received 1.5–2× more steps to reach comparable loss plateaus), following standard scaling-law protocols; total FLOPs were tracked via the Chinchilla-style estimator. We have now added a dedicated paragraph in revised §4.2, a new table (Table S3) listing steps/epochs/FLOPs per model size, and updated the Abstract to reference this protocol. These changes remove ambiguity and reinforce that saturation is not an artifact of under-training. revision: yes
-
Referee: [§3 and scaling figures] §3 (Methods) and scaling figures: The manuscript lacks reported error bars, multiple random seeds, or ablation details on the multi-task objective and data splits for the scaling curves. This makes it difficult to rule out that the reported saturation is an artifact of architecture-specific optimization difficulties or implicit leakage in the multi-regime evaluation.
Authors: We acknowledge the value of statistical robustness reporting. The revised manuscript now includes error bars (mean ± SEM across 3 independent random seeds) on all scaling curves in Figures 4 and 5. We have added a new subsection in §3.4 detailing the multi-task loss weighting ablations (varying the neural-prediction vs. decoding coefficients) and confirming that performance saturation persists across weightings. Data-split procedures are expanded to explicitly state that training and test sets use disjoint sessions and neurons with no cross-regime leakage. These additions are placed in the main text and Supplementary Note 2. revision: yes
Circularity Check
No circularity: empirical scaling results from held-out evaluation
full rationale
The paper reports experimental outcomes from training multi-modal multi-task models on 150B neural tokens and measuring performance across regimes on held-out sessions. Scaling observations (data improves performance; model size saturates) are direct measurements, not derived predictions that reduce to fitted parameters or self-citations by construction. No equations, uniqueness theorems, or ansatzes are invoked that would create self-definitional loops. The work is self-contained against external benchmarks via standard train/test splits and baseline comparisons.
Axiom & Free-Parameter Ledger
free parameters (2)
- model sizes tested
- data volume thresholds
axioms (1)
- domain assumption Standard deep learning optimization and evaluation protocols apply to neural time-series data.
Forward citations
Cited by 1 Pith paper
-
A multi-scale information geometry reveals the structure of mutual information in neural populations
A multi-scale extension of the Fisher information metric, derived from coarse-graining contraction rules, exactly captures the structure of mutual information in neural population codes and can be estimated via diffus...
Reference graph
Works this paper leans on
-
[1]
2025 , eprint=
Neural Encoding and Decoding at Scale , author=. 2025 , eprint=
2025
-
[2]
2024 , eprint=
Neuroformer: Multimodal and Multitask Generative Pretraining for Brain Data , author=. 2024 , eprint=
2024
-
[3]
Energy Guided Diffusion for Generating Neurally Exciting Images
Pierzchlewicz, Paweł A and Willeke, Konstantin F and Nix, Arne F and Elumalai, Pavithra and Restivo, Kelli and Shinn, Tori and Nealley, Cate and Rodriguez, Gabrielle and Patel, Saumil and Franke, Katrin and Tolias, Andreas S and Sinz, Fabian H. Energy Guided Diffusion for Generating Neurally Exciting Images. Advances in Neural Processing Systems (NeurIPS 2023)
2023
-
[4]
bioRxiv , pages=
Data Heterogeneity Limits the Scaling Effect of Pretraining Neural Data Transformers , author=. bioRxiv , pages=. 2025 , publisher=
2025
-
[5]
bioRxiv , pages=
A Generalist Intracortical Motor Decoder , author=. bioRxiv , pages=. 2025 , publisher=
2025
-
[6]
The Thirteenth International Conference on Learning Representations , year =
Multi-session, multi-task neural decoding from distinct cell-types and brain regions , author=. The Thirteenth International Conference on Learning Representations , year =
-
[7]
arXiv preprint arXiv:2108.01210 , year=
Representation learning for neural population activity with neural data transformers , author=. arXiv preprint arXiv:2108.01210 , year=
-
[8]
arXiv preprint arXiv:2206.08666 , year=
The Sensorium competition on predicting large-scale mouse primary visual cortex activity , author=. arXiv preprint arXiv:2206.08666 , year=
-
[9]
Advances in Neural Information Processing Systems , volume=
Retrospective for the Dynamic Sensorium Competition for predicting large-scale mouse primary visual cortex activity from videos , author=. Advances in Neural Information Processing Systems , volume=
-
[10]
Nature , volume=
Functional connectomics reveals general wiring rule in mouse visual cortex , author=. Nature , volume=. 2025 , publisher=
2025
-
[11]
Advances in Neural Information Processing Systems , volume=
A flow-based latent state generative model of neural population responses to natural images , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
2025 , eprint=
Modeling Dynamic Neural Activity by combining Naturalistic Video Stimuli and Stimulus-independent Latent Factors , author=. 2025 , eprint=
2025
-
[13]
Advances in Neural Information Processing Systems , volume=
Learning time-invariant representations for individual neurons from population dynamics , author=. Advances in Neural Information Processing Systems , volume=
-
[14]
Advances in Neural Information Processing Systems , volume=
A unified, scalable framework for neural population decoding , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Nature , volume=
Learnable latent embeddings for joint behavioural and neural analysis , author=. Nature , volume=. 2023 , publisher=
2023
-
[16]
ACM Transactions on Intelligent Systems and Technology , volume=
A comprehensive overview of large language models , author=. ACM Transactions on Intelligent Systems and Technology , volume=. 2025 , publisher=
2025
-
[17]
Large Language Models: A Survey
Large language models: A survey , author=. arXiv preprint arXiv:2402.06196 , year=
work page internal anchor Pith review arXiv
-
[18]
Nature , volume=
Foundation model of neural activity predicts response to new stimulus types , author=. Nature , volume=. 2025 , publisher=
2025
-
[19]
universal translator
Towards a" universal translator" for neural dynamics at single-cell, single-spike resolution , author=. Advances in Neural Information Processing Systems , volume=
-
[20]
Transformer language models without positional encodings still learn positional information
Transformer language models without positional encodings still learn positional information , author=. arXiv preprint arXiv:2203.16634 , year=
-
[21]
Neurocomputing , volume=
Roformer: Enhanced transformer with rotary position embedding , author=. Neurocomputing , volume=. 2024 , publisher=
2024
-
[22]
Training Compute-Optimal Large Language Models
Training compute-optimal large language models , author=. arXiv preprint arXiv:2203.15556 , year=
work page internal anchor Pith review arXiv
-
[23]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Mirasol3b: A multimodal autoregressive model for time-aligned and contextual modalities , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[24]
Science , volume=
Spontaneous behaviors drive multidimensional, brainwide activity , author=. Science , volume=. 2019 , publisher=
2019
-
[25]
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Chameleon: Mixed-modal early-fusion foundation models, 2024 , author=. URL https://arxiv. org/abs/2405.09818 , volume=
work page internal anchor Pith review arXiv 2024
-
[26]
Spatial vision , volume=
The psychophysics toolbox , author=. Spatial vision , volume=. 1997 , publisher=
1997
-
[27]
2007 , publisher=
What's new in Psychtoolbox-3? , author=. 2007 , publisher=
2007
-
[28]
, author=
The VideoToolbox software for visual psychophysics: transforming numbers into movies. , author=. Spatial vision , volume=
-
[29]
BioRxiv , pages=
Digital twin reveals combinatorial code of non-linear computations in the mouse primary visual cortex , author=. BioRxiv , pages=. 2022 , publisher=
2022
-
[30]
Nature , volume=
Accurate structure prediction of biomolecular interactions with AlphaFold 3 , author=. Nature , volume=. 2024 , publisher=
2024
-
[31]
Scaling Laws for Neural Language Models
Scaling laws for neural language models , author=. arXiv preprint arXiv:2001.08361 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[32]
Advances in Neural Information Processing Systems , volume=
Neural data transformer 2: multi-context pretraining for neural spiking activity , author=. Advances in Neural Information Processing Systems , volume=
-
[33]
arXiv preprint arXiv:2302.03023 , year=
V1t: large-scale mouse v1 response prediction using a vision transformer , author=. arXiv preprint arXiv:2302.03023 , year=
-
[34]
Advances in Neural Information Processing Systems , volume=
Stndt: Modeling neural population activity with spatiotemporal transformers , author=. Advances in Neural Information Processing Systems , volume=
-
[35]
2024 , eprint=
QuantFormer: Learning to Quantize for Neural Activity Forecasting in Mouse Visual Cortex , author=. 2024 , eprint=
2024
-
[36]
what” and “where
Neural system identification for large populations separating “what” and “where” , author=. Advances in neural information processing systems , volume=
-
[37]
Advances in neural information processing systems , volume=
Stimulus domain transfer in recurrent models for large scale cortical population prediction on video , author=. Advances in neural information processing systems , volume=
-
[38]
PLoS computational biology , volume=
Model constrained by visual hierarchy improves prediction of neural responses to natural scenes , author=. PLoS computational biology , volume=. 2016 , publisher=
2016
-
[39]
elife , volume=
CaImAn an open source tool for scalable calcium imaging data analysis , author=. elife , volume=. 2019 , publisher=
2019
-
[40]
International conference on machine learning , pages=
Hiera: A hierarchical vision transformer without the bells-and-whistles , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[41]
International Conference on Machine Learning , pages=
Scaling laws for generative mixed-modal language models , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[42]
Scaling laws for native multimodal models.arXiv preprint arXiv:2504.07951, 2025
Scaling laws for native multimodal models , author=. arXiv preprint arXiv:2504.07951 , year=
-
[43]
and Ponder, Kayla and Ding, Zhuokun and Froebe, Rachel and Ntanavara, Lydia and Fahey, Paul G
Ding, Zhiwei and Tran, Dat T. and Ponder, Kayla and Ding, Zhuokun and Froebe, Rachel and Ntanavara, Lydia and Fahey, Paul G. and Cobos, Erick and Baroni, Luca and Diamantaki, Maria and Wang, Eric Y. and Chang, Andersen and Papadopoulos, Stelios and Fu, Jiakun and Muhammad, Taliah and Papadopoulos, Christos and Cadena, Santiago A. and Evangelou, Alexandros...
2025
-
[44]
Nature , volume=
A brain-wide map of neural activity during complex behaviour , author=. Nature , volume=. 2025 , publisher=
2025
-
[45]
arXiv preprint arXiv:2107.14795 , year=
Perceiver io: A general architecture for structured inputs & outputs , author=. arXiv preprint arXiv:2107.14795 , year=
-
[46]
International Conference on Learning Representations , year=
Generalization in data-driven models of primary visual cortex , author=. International Conference on Learning Representations , year=
-
[47]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An image is worth 16x16 words: Transformers for image recognition at scale , author=. arXiv preprint arXiv:2010.11929 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[48]
Large-scale training of foundation models for wearable biosignals , author=. arXiv preprint arXiv:2312.05409 , year=
-
[49]
bioRxiv , pages=
BrainLM: A foundation model for brain activity recordings , author=. bioRxiv , pages=. 2023 , publisher=
2023
-
[50]
ArXiv , pages=
Population Transformer: Learning population-level representations of neural activity , author=. ArXiv , pages=
-
[51]
arXiv preprint arXiv:2401.10278 , year=
EEGFormer: Towards transferable and interpretable large-scale EEG foundation model , author=. arXiv preprint arXiv:2401.10278 , year=
-
[52]
arXiv preprint arXiv:2404.09256 , year=
Foundational gpt model for meg , author=. arXiv preprint arXiv:2404.09256 , year=
-
[53]
2024 IEEE International Symposium on Biomedical Imaging (ISBI) , pages=
Neuro-gpt: Towards a foundation model for eeg , author=. 2024 IEEE International Symposium on Biomedical Imaging (ISBI) , pages=. 2024 , organization=
2024
-
[54]
Large brain model for learning generic representations with tremendous EEG data in BCI , author=. arXiv preprint arXiv:2405.18765 , year=
-
[55]
Frontiers in Human Neuroscience , volume=
BENDR: Using transformers and a contrastive self-supervised learning task to learn from massive amounts of EEG data , author=. Frontiers in Human Neuroscience , volume=. 2021 , publisher=
2021
-
[56]
Advances in Neural Information Processing Systems , volume=
Neurobolt: Resting-state eeg-to-fmri synthesis with multi-dimensional feature mapping , author=. Advances in Neural Information Processing Systems , volume=
-
[57]
Advances in Neural Information Processing Systems , volume=
Brain-JEPA: Brain dynamics foundation model with gradient positioning and spatiotemporal masking , author=. Advances in Neural Information Processing Systems , volume=
-
[58]
Advances in Neural Information Processing Systems , volume=
Brain network transformer , author=. Advances in Neural Information Processing Systems , volume=
-
[59]
Advances in Neural Information Processing Systems , volume=
Brant: Foundation model for intracranial neural signal , author=. Advances in Neural Information Processing Systems , volume=
-
[60]
NeuroImage , volume=
BrainNetCNN: Convolutional neural networks for brain networks; towards predicting neurodevelopment , author=. NeuroImage , volume=. 2017 , publisher=
2017
-
[61]
arXiv preprint arXiv:2405.14425 , year=
When predict can also explain: few-shot prediction to select better neural latents , author=. arXiv preprint arXiv:2405.14425 , year=
-
[62]
One Model to Train Them All: A Unified Diffusion Framework for Multi-Context Neural Population Forecasting , author=
-
[63]
Advances in Neural Information Processing Systems , volume=
Biot: Biosignal transformer for cross-data learning in the wild , author=. Advances in Neural Information Processing Systems , volume=
-
[64]
BrainBERT: Self-supervised representation learning for intracranial recordings , author=. arXiv preprint arXiv:2302.14367 , year=
-
[65]
Advances in neural information processing systems , volume=
Self-supervised learning of brain dynamics from broad neuroimaging data , author=. Advances in neural information processing systems , volume=
- [66]
-
[67]
arXiv preprint arXiv:2410.14031 , year=
Modeling the Human Visual System: Comparative Insights from Response-Optimized and Task-Optimized Vision Models, Language Models, and different Readout Mechanisms , author=. arXiv preprint arXiv:2410.14031 , year=
-
[68]
arXiv e-prints , pages=
Incremental Learning and Self-Attention Mechanisms Improve Neural System Identification , author=. arXiv e-prints , pages=
-
[69]
bioRxiv , pages=
Movie reconstruction from mouse visual cortex activity , author=. bioRxiv , pages=. 2024 , publisher=
2024
-
[70]
Advances in neural information processing systems , volume=
From deep learning to mechanistic understanding in neuroscience: the structure of retinal prediction , author=. Advances in neural information processing systems , volume=
-
[71]
Nvlm: Open frontier-class multimodal llms.arXiv preprint arXiv:2409.11402, 2024
Nvlm: Open frontier-class multimodal llms , author=. arXiv preprint arXiv:2409.11402 , year=
-
[72]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Multi-Modal Latent Variables for Cross-Individual Primary Visual Cortex Modeling and Analysis , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[73]
Neuron , volume=
Modulation of visual responses by behavioral state in mouse visual cortex , author=. Neuron , volume=. 2010 , publisher=
2010
-
[74]
Neuron , volume=
Pupil fluctuations track fast switching of cortical states during quiet wakefulness , author=. Neuron , volume=. 2014 , publisher=
2014
-
[75]
elife , volume=
A large field of view two-photon mesoscope with subcellular resolution for in vivo imaging , author=. elife , volume=. 2016 , publisher=
2016
-
[76]
Large-Scale Video Classification with Convolutional Neural Networks
Karpathy, Andrej and Toderici, George and Shetty, Sanketh and Leung, Thomas and Sukthankar, Rahul and Fei-Fei, Li. Large-Scale Video Classification with Convolutional Neural Networks. 2014 IEEE Conference on Computer Vision and Pattern Recognition
2014
-
[77]
POCO: Scalable Neural Forecasting through Population Conditioning , author=. arXiv preprint arXiv:2506.14957 , year=
-
[78]
BioRXiv , pages=
A global map of orientation tuning in mouse visual cortex , author=. BioRXiv , pages=. 2019 , publisher=
2019
-
[79]
Nature Communications , volume=
A simplified minimodel of visual cortical neurons , author=. Nature Communications , volume=. 2025 , publisher=
2025
-
[80]
2025 , doi =
Li, Bryan M and De Wulf, Wolf and Katsanevaki, Danai and Onken, Arno and Rochefort, Nathalie LI , title =. 2025 , doi =. https://www.biorxiv.org/content/early/2025/09/17/2025.09.16.676524.full.pdf , journal =
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.