Recognition: unknown
LLM-Based Educational Simulation: Evaluating Temporal Student Persona Stability Across ADHD Profiles
Pith reviewed 2026-05-08 07:08 UTC · model grok-4.3
The pith
LLM-generated ADHD student personas hold self-reported traits steady over time, but their observed behaviors drift in unscripted conversations unless interactions use explicit scripted task prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
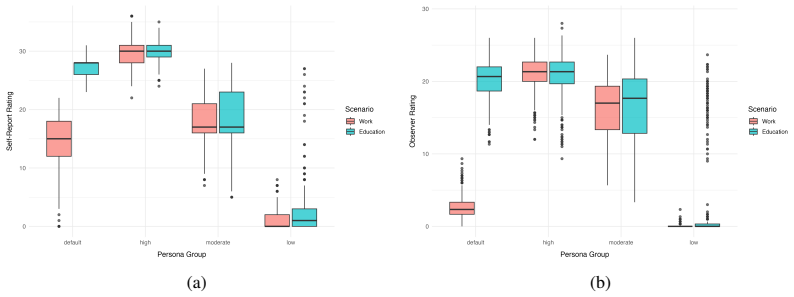
Across two experiments with four clinically grounded ADHD persona conditions, five LLMs, and three prompt designs, self-reported characteristics remain stable for high intensities. This supplies a necessary prerequisite for valid behavioral simulation. Observer-rated behavioral expression instead shows selective instability, with within-conversation drift appearing in unscripted dialog for high and moderate ADHD personas. Scripted interactions that include explicit task prompts remove this drift completely.
What carries the argument
A dual-assessment framework that tracks self-reported characteristics separately from observer-rated behavioral expressions, applied to between-conversation stability (N=4,968) and within-conversation stability across nine turns (N=3,952).
If this is right
- High-intensity ADHD personas can serve as reliable starting points for long-running educational simulations when self-description is the primary measure.
- Unscripted dialog introduces behavioral drift that limits the use of open-ended exchanges for moderate or high ADHD profiles.
- Adding explicit task prompts restores behavioral coherence, making scripted formats preferable for applications that require path-dependent learner interactions.
- The same structured design choice applies directly to teacher training scenarios and adaptive tutoring systems that depend on consistent persona behavior over multiple turns.
Where Pith is reading between the lines
- Prompt engineering that favors explicit tasks may prove useful for maintaining consistency in any LLM application that simulates sustained human traits over time.
- The observed difference between self-report stability and behavioral drift suggests that future tests could compare these measures against actual human student data to check external validity.
- If scripting eliminates drift, similar structured constraints might reduce unwanted variation when LLMs simulate other neurodiverse or personality-based roles outside education.
Load-bearing premise
Observer ratings of behavioral expressions accurately and without bias capture how well the generated text matches the intended persona, free from rater expectations or artifacts of LLM text generation.
What would settle it
A replication in which multiple independent raters score identical sets of LLM outputs for the same persona conditions and produce markedly different alignment scores would indicate that the observer-based stability findings rest on unreliable measurement.
Figures


read the original abstract
Student simulation with Large language models (LLMs) offers a scalable alternative for educational research and teacher training. Yet, its validity depends on whether models maintain stable personas across extended interactions. We test this prerequisite using a dual-assessment framework measuring self-reported characteristics and observer-rated behavioral expressions. Across two experiments testing four clinically-grounded ADHD persona conditions, five LLMs, and three prompt designs, we quantify between-conversation stability (N=4,968) and within-conversation stability (N=3,952 across 9 turns). Self-reported characteristics remain stable for high intensities, constituting a necessary prerequisite for valid behavioral simulation. Observer-rated behavioral expression reveals selective instability: within-conversation drift occurs in unscripted dialog for high and moderate ADHD personas. Scripted interactions with explicit task prompts eliminate this drift entirely. Stable, persona-aligned simulated learners benefit from a structured interaction design to maintain behavioral coherence, which holds significant implications for teacher training, adaptive tutoring, and any application requiring sustained, path-dependent learner interactions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript evaluates the temporal stability of LLM-simulated student personas across ADHD intensity profiles using a dual-assessment framework of self-reported characteristics and observer-rated behavioral expressions. Two experiments test four clinically-grounded ADHD conditions, five LLMs, and three prompt designs, measuring between-conversation stability (N=4968) and within-conversation stability over 9 turns (N=3952). The central claims are that self-reported traits remain stable for high-intensity personas and that observer-rated behaviors show selective within-conversation drift in unscripted dialog for high and moderate ADHD personas, with this drift eliminated entirely by scripted interactions containing explicit task prompts.
Significance. If the observer-rated results hold after addressing measurement concerns, the work offers actionable guidance for designing coherent LLM-based educational simulations and teacher-training tools. The large sample sizes, multi-LLM testing, and dual-assessment approach provide a stronger empirical basis than typical single-model persona studies. The finding that structured prompts can eliminate drift has direct implications for adaptive tutoring systems requiring sustained persona alignment.
major comments (2)
- [Methods] Methods section (observer-rated behavioral expression protocol): The description does not state whether raters were blinded to persona intensity (high/moderate/low) or prompt type (scripted/unscripted). This is load-bearing for the selective-instability claim, because unblinded raters could introduce expectation biases that artifactually produce the reported drift pattern in unscripted conditions while making scripted outputs appear more stable.
- [Results] Results section (within-conversation stability, N=3952): No inter-rater reliability statistics (e.g., Cohen's kappa or ICC) are reported for the observer ratings. Without these, it is impossible to separate genuine persona drift from rater variability or LLM generation artifacts that may exaggerate ADHD-like traits, undermining the contrast between scripted and unscripted conditions.
minor comments (2)
- [Abstract] Abstract: Sample sizes are given but no statistical tests, effect sizes, confidence intervals, or error analysis are mentioned, making it difficult to evaluate the strength of the stability and drift claims from the summary alone.
- [Methods] The operationalization of 'drift' (e.g., exact rating scales, behavioral dimensions, or quantitative thresholds) could be stated more explicitly in the Methods to allow replication.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback on our manuscript evaluating temporal stability in LLM-simulated ADHD student personas. Their comments highlight important aspects of methodological transparency that we will address to strengthen the paper. We respond point by point to the major comments below.
read point-by-point responses
-
Referee: [Methods] Methods section (observer-rated behavioral expression protocol): The description does not state whether raters were blinded to persona intensity (high/moderate/low) or prompt type (scripted/unscripted). This is load-bearing for the selective-instability claim, because unblinded raters could introduce expectation biases that artifactually produce the reported drift pattern in unscripted conditions while making scripted outputs appear more stable.
Authors: We appreciate the referee identifying this important detail. The rating protocol provided raters with persona intensity and prompt type information to enable accurate identification of ADHD-related behavioral expressions against the clinically grounded profiles. We acknowledge that this constitutes a lack of blinding and could introduce expectation biases. In the revised manuscript, we will explicitly describe the rater instructions, confirm the absence of blinding, and add a dedicated paragraph in the Limitations section discussing how a standardized rubric, multiple independent raters, and consistency of drift patterns across five LLMs help mitigate such biases. This will provide greater transparency for the selective-instability findings. revision: yes
-
Referee: [Results] Results section (within-conversation stability, N=3952): No inter-rater reliability statistics (e.g., Cohen's kappa or ICC) are reported for the observer ratings. Without these, it is impossible to separate genuine persona drift from rater variability or LLM generation artifacts that may exaggerate ADHD-like traits, undermining the contrast between scripted and unscripted conditions.
Authors: We agree that the absence of inter-rater reliability statistics is a significant gap. We will compute and report appropriate statistics (Cohen's kappa for categorical behavioral codes and ICC for continuous ratings) in the revised Results section for the observer-rated measures. These will be presented alongside the within-conversation stability results to demonstrate that rating consistency is high and that the observed drift in unscripted high/moderate ADHD conditions is not attributable to rater variability. This addition directly supports the contrast with scripted conditions and the overall validity of the dual-assessment framework. revision: yes
Circularity Check
No significant circularity: empirical stability measurements with no derivations or fitted predictions
full rationale
The paper reports results from controlled experiments quantifying between-conversation stability (N=4,968) and within-conversation stability (N=3,952) of LLM-simulated ADHD personas using self-report and observer-rated measures across prompt designs and models. No equations, first-principles derivations, parameter fitting, or predictions appear in the provided text or abstract. Central claims rest on direct empirical contrasts (e.g., drift eliminated by scripted prompts) rather than any self-definitional, fitted-input, or self-citation reduction. This is self-contained empirical work with no load-bearing steps that collapse to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs can be prompted to adopt and maintain clinically grounded ADHD personas
- domain assumption Observer ratings provide an unbiased measure of behavioral expression alignment
Reference graph
Works this paper leans on
-
[1]
Consistently Simulating Human Personas with Multi-Turn Reinforcement Learning, October
Marwa Abdulhai, Ryan Cheng, Donovan Clay, Tim Althoff, Sergey Levine, and Natasha Jaques. Consistently Simulating Human Personas with Multi-Turn Reinforcement Learning, October
- [2]
-
[3]
American Psychiatric Association.Diagnostisches und statistisches Manual psychischer Störungen – Textrevision – DSM-5-TR®. hogrefe, Göttingen, 1. auflage edition, 2025. doi: 10.1026/03217-000
-
[4]
Jacy Reese Anthis, Ryan Liu, Sean M. Richardson, Austin C. Kozlowski, Bernard Koch, James Evans, Erik Brynjolfsson, and Michael Bernstein. LLM Social Simulations Are a Promising Research Method, June 2025. arXiv:2504.02234 [cs]
-
[5]
Flexible Coding of in-depth Interviews: A Twenty- rst Century Approach
Lisa P. Argyle, Ethan C. Busby, Nancy Fulda, Joshua R. Gubler, Christopher Rytting, and David Wingate. Out of One, Many: Using Language Models to Simulate Human Samples.Political Analysis, 31(3):337–351, July 2023. doi: 10.1017/pan.2023.2
-
[6]
A foundation model to predict and capture human cognition.Nature, 644: 1002–1009, 2025
Marcel Binz, Elif Akata, Matthias Bethge, Franziska Brändle, Fred Callaway, Julian Coda- Forno, Peter Dayan, Can Demircan, Maria K. Eckstein, Noémi Éltet ˝o, Thomas L. Griffiths, Susanne Haridi, Akshay K. Jagadish, Li Ji-An, Alexander Kipnis, Sreejan Kumar, Tobias Ludwig, Marvin Mathony, Marcelo Mattar, Alireza Modirshanechi, Surabhi S. Nath, Joshua C. Pe...
-
[7]
Keith Conners, Drew Erhardt, and Elizabeth Sparrow
C. Keith Conners, Drew Erhardt, and Elizabeth Sparrow. Conners’ Adult ADHD Rating Scales, May 2012. Institution: American Psychological Association
2012
-
[8]
The threat of analytic flexibility in using large language models to simulate human data: A call to attention, September 2025
Jamie Cummins. The threat of analytic flexibility in using large language models to simulate human data: A call to attention, September 2025
2025
-
[9]
Melissa L. Danielson, Angelika H. Claussen, Rebecca H. Bitsko, Samuel M. Katz, Kimberly Newsome, Stephen J. Blumberg, Michael D. Kogan, and Reem Ghandour. ADHD Prevalence Among U.S. Children and Adolescents in 2022: Diagnosis, Severity, Co-Occurring Disorders, and Treatment.Journal of Clinical Child & Adolescent Psychology, 53(3):343–360, May 2024. doi: 1...
-
[10]
FACET: Multi-Agent AI Supporting Teachers in Scaling Differentiated Learning for Diverse Students, 2026
Jana Gonnermann-Müller, Jennifer Haase, Nicolas Leins, Moritz Igel, Konstantin Fackeldey, and Sebastian Pokutta. FACET: Multi-Agent AI Supporting Teachers in Scaling Differentiated Learning for Diverse Students, 2026. Version Number: 1. 10
2026
-
[11]
Stable Personas: Dual-Assessment of Temporal Stability in LLM-Based Human Simulation, January 2026
Jana Gonnermann-Müller, Jennifer Haase, Nicolas Leins, Thomas Kosch, and Sebastian Pokutta. Stable Personas: Dual-Assessment of Temporal Stability in LLM-Based Human Simulation, January 2026. arXiv:2601.22812 [cs]
-
[12]
SimBench: Benchmarking the Ability of Large Language Models to Simulate Human Behaviors
Tiancheng Hu, Joachim Baumann, Lorenzo Lupo, Nigel Collier, Dirk Hovy, and Paul Röttger. SimBench: Benchmarking the Ability of Large Language Models to Simulate Human Behaviors, October 2025. arXiv:2510.17516 [cs]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[13]
Jebb, Vincent Ng, and Louis Tay
Andrew T. Jebb, Vincent Ng, and Louis Tay. A Review of Key Likert Scale Development Advances: 1995–2019.Frontiers in Psychology, 12, May 2021. doi: 10.3389/fpsyg.2021. 637547
-
[14]
Can LLMs Estimate Student Struggles? Human-AI Difficulty Alignment with Proficiency Simulation for Item Difficulty Prediction, December 2025
Ming Li, Han Chen, Yunze Xiao, Jian Chen, Hong Jiao, and Tianyi Zhou. Can LLMs Estimate Student Struggles? Human-AI Difficulty Alignment with Proficiency Simulation for Item Difficulty Prediction, December 2025
2025
-
[15]
Can LLMs Effectively Simulate Human Learners? Teachers’ Insights from Tutoring LLM Students
Daria Martynova, Jakub Macina, Nico Daheim, Nilay Yalcin, Xiaoyu Zhang, and Mrinmaya Sachan. Can LLMs Effectively Simulate Human Learners? Teachers’ Insights from Tutoring LLM Students. In Ekaterina Kochmar, Bashar Alhafni, Marie Bexte, Jill Burstein, Andrea Horbach, Ronja Laarmann-Quante, Anaïs Tack, Victoria Yaneva, and Zheng Yuan, editors, Proceedings ...
-
[16]
Louis S. Matza, David L. Van Brunt, Charlotte Cates, and Lindsey T. Murray. Test–Retest Reliability of Two Patient-Report Measures for Use in Adults With ADHD.Journal of Attention Disorders, 15(7):557–563, October 2011. doi: 10.1177/1087054710372488
-
[17]
Beatrice Mörstedt, Salvatore Corbisiero, Hannes Bitto, and Rolf-Dieter Stieglitz. Attention- Deficit/Hyperactivity Disorder (ADHD) in Adulthood: Concordance and Differences between Self- and Informant Perspectives on Symptoms and Functional Impairment.PLOS ONE, 10 (11):e0141342, November 2015. doi: 10.1371/journal.pone.0141342
-
[18]
Olino and Daniel N
Thomas M. Olino and Daniel N. Klein. Psychometric Comparison of Self- and Informant- Reports of Personality.Assessment, 22(6):655–664, December 2015. doi: 10.1177/ 1073191114567942
2015
-
[19]
Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R
Mrinank Sharma, Meg Tong, Tomasz Korbak, David Duvenaud, Amanda Askell, Samuel R. Bowman, Newton Cheng, Esin Durmus, Zac Hatfield-Dodds, Scott R. Johnston, Shauna Kravec, Timothy Maxwell, Sam McCandlish, Kamal Ndousse, Oliver Rausch, Nicholas Schiefer, Da Yan, Miranda Zhang, and Ethan Perez. Towards Understanding Sycophancy in Language Models, May 2025
2025
-
[20]
International Classification of Diseases (ICD), 2022
World Health Organisation. International Classification of Diseases (ICD), 2022. URL https: //www.who.int/standards/classifications/classification-of-diseases
2022
-
[21]
Embracing Imperfection: Simulating Students with Diverse Cognitive Levels Using LLM-based Agents, August 2025
Tao Wu, Jingyuan Chen, Wang Lin, Mengze Li, Yumeng Zhu, Ang Li, Kun Kuang, and Fei Wu. Embracing Imperfection: Simulating Students with Diverse Cognitive Levels Using LLM-based Agents, August 2025
2025
-
[22]
Cecilia Wåhlstedt, Lisa B. Thorell, and Gunilla Bohlin. Heterogeneity in ADHD: Neuropsycho- logical Pathways, Comorbidity and Symptom Domains.Journal of Abnormal Child Psychology, 37(4):551–564, May 2009. doi: 10.1007/s10802-008-9286-9
-
[23]
A LLM-Driven Multi-Agent Systems for Professional Development of Mathematics Teachers, July 2025
Kaiqi Yang, Hang Li, Yucheng Chu, Ahreum Han, Yasemin Copur-Gencturk, Jiliang Tang, and Hui Liu. A LLM-Driven Multi-Agent Systems for Professional Development of Mathematics Teachers, July 2025
2025
-
[24]
Mathvc: An llm-simulated multi-character virtual classroom for mathematics education,
Murong Yue, Wenhan Lyu, Jennifer Suh, Yixuan Zhang, and Ziyu Yao. MathVC: An LLM- Simulated Multi-Character Virtual Classroom for Mathematics Education, October 2025. arXiv:2404.06711 [cs]. 11
-
[25]
Zheyuan Zhang, Daniel Zhang-Li, Jifan Yu, Linlu Gong, Jinchang Zhou, Zhanxin Hao, Jianxiao Jiang, Jie Cao, Huiqin Liu, Zhiyuan Liu, Lei Hou, and Juanzi Li. Simulating Classroom Education with LLM-Empowered Agents. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors, Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Associati...
-
[26]
I interrupt others when talking
-
[27]
I am always on the go as if driven by a motor
-
[28]
It’s hard for me to stay in one place very long
-
[29]
It’s hard for me to keep track of several things at once
-
[30]
I have a short fuse/hot temper
-
[31]
I still throw tantrums
-
[32]
I avoid new challenges because I lack faith in my abilities
-
[33]
I seek out fast paced, exciting activities
-
[34]
I feel restless inside even if I am sitting still
-
[35]
Things I hear or see distract me from what I’m doing
-
[36]
Many things set me off easily
-
[37]
I am an underachiever
-
[38]
I get down on myself
-
[39]
I act okay on the outside, but inside I’m unsure of myself
-
[40]
I can’t get things done unless there’s an absolute deadline
-
[41]
I have trouble getting started on a task
-
[42]
I intrude on others’ activities
-
[43]
My moods are unpredictable
-
[44]
I’m absent-minded in daily activities
-
[45]
Sometimes my attention narrows so much that I’m oblivious to everything else; other times it’s so broad that everything distracts me
-
[46]
I tend to squirm or fidget
-
[47]
I can’t keep my mind on something unless it’s really interesting
-
[48]
I wish I had greater confidence in my abilities
-
[49]
BEGIN when ready and output only the JSON
My past failures make it hard for me to believe in myself. BEGIN when ready and output only the JSON. Observer Prompt You are a trained observer conducting a behavioral assessment. You will receive a conversation of two individuals. Based on this conversation, rate each of the following assessment items using the scale below. Conversation between two indi...
-
[50]
Loses things necessary for tasks or activities (e.g., to-do lists, pencils, books, or tools). 17
-
[51]
Is always on the go as if driven by a motor
-
[52]
Gets rowdy or boisterous during leisure activities
-
[53]
Has a short fuse/hot temper
-
[54]
Leaves seat when not supposed to
-
[55]
Has trouble waiting in line or taking turns with others
-
[56]
Has trouble keeping attention focused when working or at leisure
-
[57]
Avoids new challenges because of lack of faith in his/her abilities
-
[58]
Appears restless inside even when sitting still
-
[59]
Is distracted by sights or sounds when trying to concentrate
-
[60]
Is forgetful in daily activities
-
[61]
Has trouble listening to what other people are saying
-
[62]
Can’t get things done unless there’s an absolute deadline
-
[63]
Fidgets (with hands or feet) or squirms in seat
-
[64]
Makes careless mistakes or has trouble paying close attention to detail
-
[65]
Intrudes on others’ activities
-
[66]
Doesn’t like academic studies/work projects where effort at thinking a lot is required
-
[67]
Is restless or overactive
-
[68]
Sometimes overfocuses on details, at other times appears distracted by everything going on around him/her
-
[69]
Can’t keep his/her mind on something unless it’s really interesting
-
[70]
Gives answers to questions before the questions have been completed
-
[71]
Has trouble finishing job tasks or schoolwork
-
[72]
Interrupts others when they are working or busy
-
[73]
Expresses lack of confidence in self because of past failures
-
[74]
Appears distracted when things are going on around him/her
-
[75]
responses
Has problems organizing tasks and activities. INSTRUCTIONS: - Carefully review the conversation segment - Rate each item based solely on observable evidence in the conversation - Use your best clinical judgment when evidence is limited or ambiguous - Provide a rating (0-3) for every item Output your assessment strictly in the following JSON format: {{ "re...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.