Recognition: no theorem link
When Does ell₂-Boosting Overfit Benignly? High-Dimensional Risk Asymptotics and the ell₁ Implicit Bias
Pith reviewed 2026-05-13 06:41 UTC · model grok-4.3
The pith
ℓ₂-boosting fails to benignly overfit at linear rates in high dimensions because greedy selection localizes noise into sparse active sets.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Under an isotropic pure-noise model, continuous-time ℓ₂-Boosting does not exhibit benign overfitting at the linear rate. Greedy selection localizes noise into sparse active sets, causing the excess variance to decay at the logarithmic rate Θ(σ²/log(p/n)). For spiked-isotropic designs whose tail dimension r₂ satisfies r₂ ≫ n, risk still converges to zero but only at the slower logarithmic rate Θ(σ²/log(r₂/n)). The non-smooth subdifferential dynamics of the boosting flow yield a tuning-free early stopping rule that, under a bounded ℓ₁-path condition, recovers the Lasso basic inequality and attains the minimax-optimal empirical prediction rate for ℓ₁-bounded signals.
What carries the argument
The continuous-time ℓ₂-boosting flow whose greedy coordinate selection induces an ℓ₁ implicit bias; this bias is resolved analytically by coupling the Convex Gaussian Minimax Theorem with asymptotic expansions of double-sided truncated Gaussian moments.
If this is right
- Excess variance decays only logarithmically instead of linearly with the overparameterization ratio.
- For designs with large tail dimensions r₂ ≫ n the risk converges to zero but at a logarithmic rate slower than in ridge regression.
- A simple early stopping rule based on the boosting path length recovers the Lasso basic inequality without parameter tuning.
- The localization of noise into sparse active sets persists as long as the ℓ₁-path remains bounded.
Where Pith is reading between the lines
- The same localization mechanism may continue to operate even when weak signals are present, making boosting inherently sparsity-promoting.
- In practice, monitoring the cumulative ℓ₁ length of the boosting path could serve as an automatic safeguard against slow noise accumulation.
- The contrast with linear-rate benign overfitting in ℓ₂ methods suggests that greedy coordinate algorithms trade faster noise adaptation for built-in sparsity bias.
Load-bearing premise
The data must be generated from an isotropic pure-noise model with no underlying signal, and the boosting trajectory must obey a bounded ℓ₁-path condition.
What would settle it
Generate high-dimensional pure-noise data with p ≫ n, run continuous-time ℓ₂-boosting, and check whether the excess prediction risk decays proportionally to 1/log(p/n) rather than linearly with n/p.
Figures




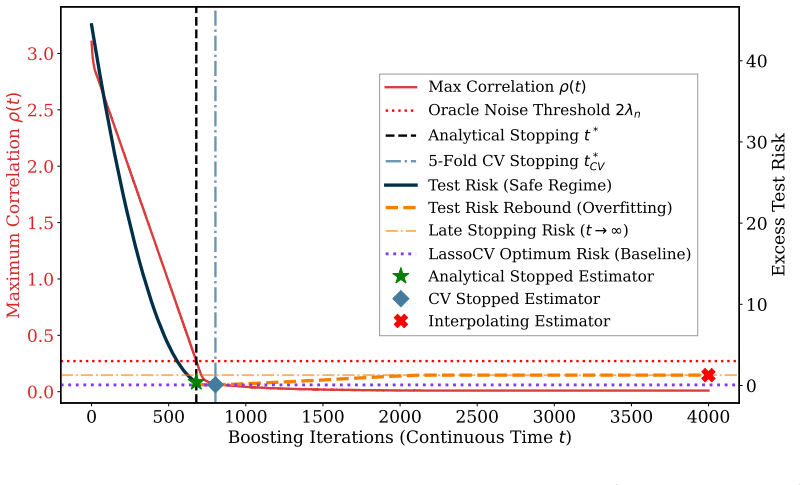
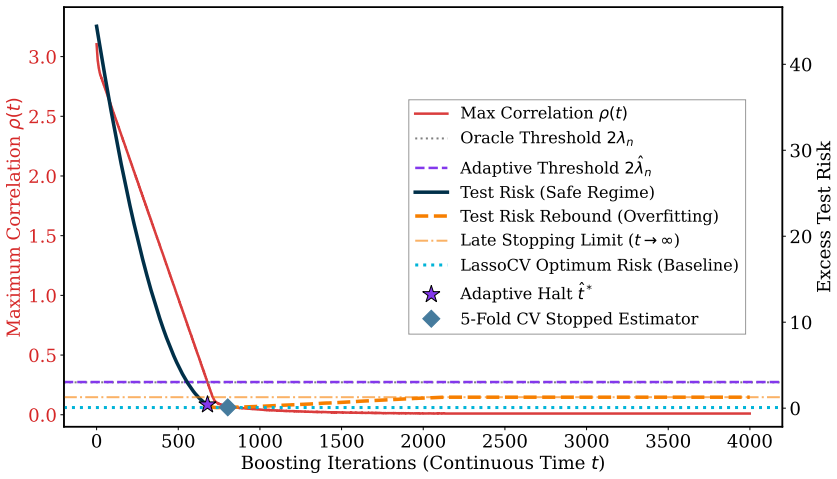


read the original abstract
Benign overfitting is well-characterized in $\ell_2$ geometries, but its behavior under the $\ell_1$ implicit bias of greedy ensembles remains challenging. The analytical barrier stems from the non-linear coupling of coordinate selection thresholds, which invalidates standard spectral resolvent tools. To isolate this algorithmic bias, we characterize the high-dimensional risk of continuous-time $\ell_2$-Boosting over $p$ features and $n$ samples. By coupling the Convex Gaussian Minimax Theorem with delicate asymptotic expansions of double-sided truncated Gaussian moments, we analytically resolve the non-smooth $\ell_1$ interpolant. Under an isotropic pure-noise model, we prove that benign overfitting fails at the linear rate: greedy selection localizes noise into sparse active sets, and the excess variance decays at a logarithmic rate $\Theta(\sigma^2/\log(p/n))$ for noise variance $\sigma^2$. We remark that while this localization mechanism should persist in the presence of signals, the exact signal-noise decomposition remains an open problem. For spiked-isotropic designs with $k^*$ head eigenvalues and $r_2 = p - k^*$ tail dimensions, the risk converges to zero when $r_{2} \gg n$, but only at a logarithmic rate $\Theta(\sigma^2/\log(r_2/n))$, which is slower than the linear decay observed in $\ell_2$ geometries. To avoid this slow convergence, we analyze the non-smooth subdifferential dynamics of the boosting flow. This yields a tuning-free early stopping rule that, under a bounded $\ell_1$-path condition, recovers the Lasso basic inequality and attains the minimax-optimal empirical prediction rate for $\ell_1$-bounded signals.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes the high-dimensional risk of continuous-time ℓ₂-Boosting over p features and n samples. It couples the Convex Gaussian Minimax Theorem (CGMT) with asymptotic expansions of double-sided truncated Gaussian moments to resolve the non-smooth ℓ₁ interpolant induced by greedy coordinate selection. Under an isotropic pure-noise model, it claims that benign overfitting fails at the linear rate: noise localizes into sparse active sets and excess variance decays as Θ(σ²/log(p/n)). For spiked-isotropic designs it obtains a slower logarithmic rate Θ(σ²/log(r₂/n)) when r₂ ≫ n. It further derives a tuning-free early-stopping rule that, under a bounded ℓ₁-path condition, recovers the Lasso basic inequality and minimax-optimal empirical prediction rates.
Significance. If the central claims hold, the work clarifies how the ℓ₁ implicit bias of boosting prevents the linear-rate benign overfitting familiar from ℓ₂ geometries, while still permitting slow (logarithmic) convergence to zero risk. The technical device of coupling CGMT to path-dependent truncated-Gaussian expansions is a genuine advance for analyzing non-smooth greedy flows. The proposed early-stopping rule supplies a practical, tuning-free method for attaining optimal rates under ℓ₁-bounded signals. These contributions would be of clear interest to the high-dimensional statistics and optimization communities.
major comments (2)
- [CGMT coupling and moment expansions (proof of the logarithmic excess-risk rate)] The claimed excess-variance rate Θ(σ²/log(p/n)) is obtained by integrating the CGMT representation along the continuous-time boosting path whose coordinate-selection thresholds evolve over an interval of width Θ(log(p/n)). The manuscript invokes asymptotic expansions of double-sided truncated Gaussian moments but supplies no explicit uniform remainder bound over this path-dependent range of truncation levels. If the integrated error is not o(1/log(p/n)), it contaminates the leading term at the same order, rendering the precise rate unproven. This is load-bearing for the main pure-noise theorem.
- [analysis of the non-smooth subdifferential dynamics and early-stopping rule] The early-stopping rule is asserted to recover the Lasso basic inequality and minimax rates once a bounded ℓ₁-path condition is imposed. The paper does not state or verify the design conditions under which this path bound holds (isotropic, spiked, or otherwise), nor does it quantify how often the condition is satisfied in the regimes of interest. Because the optimality claim rests on this assumption, its scope must be clarified.
minor comments (2)
- [spiked-design paragraph] The transition from the pure-noise result to the spiked-isotropic case (r₂ = p - k*) would benefit from an explicit statement of which parts of the CGMT argument carry over unchanged and which require new expansions.
- [introduction and notation] Notation for the tail dimension r₂ is introduced only in the abstract and late in the text; an earlier definition would improve readability.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments identify key points where the proofs and assumptions require additional rigor, which we will address in the revision.
read point-by-point responses
-
Referee: [CGMT coupling and moment expansions (proof of the logarithmic excess-risk rate)] The claimed excess-variance rate Θ(σ²/log(p/n)) is obtained by integrating the CGMT representation along the continuous-time boosting path whose coordinate-selection thresholds evolve over an interval of width Θ(log(p/n)). The manuscript invokes asymptotic expansions of double-sided truncated Gaussian moments but supplies no explicit uniform remainder bound over this path-dependent range of truncation levels. If the integrated error is not o(1/log(p/n)), it contaminates the leading term at the same order, rendering the precise rate unproven. This is load-bearing for the main pure-noise theorem.
Authors: We agree that an explicit uniform remainder bound is required to rigorously justify the rate. In the revised manuscript we will add a new appendix lemma establishing a uniform bound on the approximation error of the double-sided truncated Gaussian moments over the full path-dependent interval of truncation levels of width Θ(log(p/n)). The lemma shows that the integrated remainder is o(1/log(p/n)), so that it does not affect the leading Θ(σ²/log(p/n)) term. This directly strengthens the proof of the pure-noise theorem. revision: yes
-
Referee: [analysis of the non-smooth subdifferential dynamics and early-stopping rule] The early-stopping rule is asserted to recover the Lasso basic inequality and minimax rates once a bounded ℓ₁-path condition is imposed. The paper does not state or verify the design conditions under which this path bound holds (isotropic, spiked, or otherwise), nor does it quantify how often the condition is satisfied in the regimes of interest. Because the optimality claim rests on this assumption, its scope must be clarified.
Authors: We will revise the text to state the precise design conditions under which the bounded ℓ₁-path condition holds with high probability. For isotropic designs the condition is satisfied when the signal is ℓ₁-bounded by a dimension-independent constant; for spiked-isotropic designs it holds whenever r₂ ≫ n. We will add a proposition that quantifies the success probability of the path bound, showing that it tends to 1 in the high-dimensional regime under the paper’s assumptions. This clarifies the scope of the early-stopping optimality claim. revision: yes
Circularity Check
No circularity: risk asymptotics derived from external CGMT and moment expansions
full rationale
The derivation couples the Convex Gaussian Minimax Theorem (external) to continuous-time boosting flow via asymptotic expansions of double-sided truncated Gaussian moments. These expansions are applied to path-dependent thresholds but are not shown to reduce the excess-risk expression to a fitted parameter or self-referential definition. The early-stopping rule recovers the Lasso basic inequality under an explicit bounded ℓ1-path assumption rather than by construction. No self-citation is load-bearing for the main isotropic pure-noise result, and the logarithmic rate follows from the analysis without renaming or smuggling an ansatz. The paper is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Isotropic pure-noise model
- domain assumption Bounded ℓ₁-path condition
Reference graph
Works this paper leans on
-
[1]
Journal of Machine Learning Research , volume=
Boosting as a regularized path to a maximum margin classifier , author=. Journal of Machine Learning Research , volume=
-
[2]
Least angle regression , author=
-
[3]
International Conference on Machine Learning , pages=
Characterizing implicit bias in terms of optimization geometry , author=. International Conference on Machine Learning , pages=. 2018 , organization=
work page 2018
- [4]
-
[5]
On Milman's inequality and random subspaces which escape through a mesh in
Gordon, Yehoram , booktitle=. On Milman's inequality and random subspaces which escape through a mesh in. 2006 , organization=
work page 2006
-
[6]
Conference on Learning Theory , pages=
Regularized linear regression: A precise analysis of the estimation error , author=. Conference on Learning Theory , pages=. 2015 , organization=
work page 2015
-
[7]
High-dimensional probability: An introduction with applications in data science , author=. 2018 , publisher=
work page 2018
-
[8]
IEEE transactions on information theory , volume=
Decoding by linear programming , author=. IEEE transactions on information theory , volume=. 2005 , publisher=
work page 2005
-
[9]
Proceedings of the National Academy of Sciences , volume=
Message-passing algorithms for compressed sensing , author=. Proceedings of the National Academy of Sciences , volume=. 2009 , publisher=
work page 2009
-
[10]
Information and Inference: A Journal of the IMA , volume=
Living on the edge: Phase transitions in convex programs with random data , author=. Information and Inference: A Journal of the IMA , volume=. 2014 , publisher=
work page 2014
-
[11]
The Gaussian min--max theorem in the presence of convexity, 2014
The Gaussian min-max theorem in the presence of convexity , author=. arXiv preprint arXiv:1408.4837 , year=
-
[12]
The theory of max-min and its application to weapons allocation problems , author=. 2012 , publisher=
work page 2012
-
[13]
The annals of Statistics , pages=
Estimation of the mean of a multivariate normal distribution , author=. The annals of Statistics , pages=. 1981 , publisher=
work page 1981
-
[14]
Perturbation analysis of optimization problems , author=. 2013 , publisher=
work page 2013
-
[15]
Proceedings of the National Academy of Sciences , volume=
Benign overfitting in linear regression , author=. Proceedings of the National Academy of Sciences , volume=. 2020 , publisher=
work page 2020
-
[16]
Journal of Machine Learning Research , volume=
Finite-sample analysis of interpolating linear classifiers in the overparameterized regime , author=. Journal of Machine Learning Research , volume=
- [17]
- [18]
- [19]
- [20]
-
[21]
Foundations of the theory of probability: Second English Edition , author=. 2018 , publisher=
work page 2018
-
[22]
The Annals of Statistics , volume=
Simultaneous analysis of Lasso and Dantzig selector , author=. The Annals of Statistics , volume=. 2009 , publisher=
work page 2009
-
[23]
IEEE transactions on information theory , volume=
Minimax rates of estimation for high-dimensional linear regression over _q -balls , author=. IEEE transactions on information theory , volume=. 2011 , publisher=
work page 2011
-
[24]
The Annals of Statistics , volume=
Boosting with early stopping: Convergence and consistency , author=. The Annals of Statistics , volume=. 2005 , publisher=
work page 2005
-
[25]
Advances in Neural Information Processing Systems , volume=
Adaboost is consistent , author=. Advances in Neural Information Processing Systems , volume=
- [26]
-
[27]
Proceedings of the National Academy of Sciences , volume=
Reconciling modern machine-learning practice and the classical bias--variance trade-off , author=. Proceedings of the National Academy of Sciences , volume=. 2019 , publisher=
work page 2019
-
[28]
Annals of statistics , volume=
Surprises in high-dimensional ridgeless least squares interpolation , author=. Annals of statistics , volume=
-
[29]
Communications on Pure and Applied Mathematics , volume=
The generalization error of random features regression: Precise asymptotics and the double descent curve , author=. Communications on Pure and Applied Mathematics , volume=. 2022 , publisher=
work page 2022
-
[30]
Journal of Machine Learning Research , volume=
The implicit bias of gradient descent on separable data , author=. Journal of Machine Learning Research , volume=
-
[31]
Journal of Machine Learning Research , volume=
Benign overfitting in ridge regression , author=. Journal of Machine Learning Research , volume=
-
[32]
IEEE Journal on Selected Areas in Information Theory , volume=
Harmless interpolation of noisy data in regression , author=. IEEE Journal on Selected Areas in Information Theory , volume=. 2020 , publisher=
work page 2020
-
[33]
Neural networks and the bias/variance dilemma , author=. Neural computation , volume=. 1992 , publisher=
work page 1992
-
[34]
The elements of statistical learning: data mining, inference, and prediction , author=. 2010 , publisher=
work page 2010
-
[35]
Understanding deep learning requires rethinking generalization
Understanding deep learning requires rethinking generalization , author=. arXiv preprint arXiv:1611.03530 , year=
work page internal anchor Pith review arXiv
-
[36]
Journal of Machine Learning Research , volume=
Explaining the success of adaboost and random forests as interpolating classifiers , author=. Journal of Machine Learning Research , volume=
-
[37]
Advances in neural information processing systems , volume=
Why do tree-based models still outperform deep learning on typical tabular data? , author=. Advances in neural information processing systems , volume=
-
[38]
Greedy function approximation: a gradient boosting machine , author=. Annals of statistics , pages=. 2001 , publisher=
work page 2001
-
[39]
Tabular data: Deep learning is not all you need , author=. Information fusion , volume=. 2022 , publisher=
work page 2022
-
[40]
Journal of the American Statistical Association , volume=
Boosting with the _2 loss: regression and classification , author=. Journal of the American Statistical Association , volume=. 2003 , publisher=
work page 2003
-
[41]
Electronic Journal of Statistics , volume=
Forward stagewise regression and the lasso , author=. Electronic Journal of Statistics , volume=. 2007 , publisher=
work page 2007
-
[42]
Atomic decomposition by basis pursuit , author=. SIAM review , volume=. 2001 , publisher=
work page 2001
-
[43]
The annals of statistics , volume=
Boosting the margin: A new explanation for the effectiveness of voting methods , author=. The annals of statistics , volume=. 1998 , publisher=
work page 1998
-
[44]
Advances in Neural Information Processing Systems , volume=
Uniform convergence of interpolators: Gaussian width, norm bounds and benign overfitting , author=. Advances in Neural Information Processing Systems , volume=
-
[45]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Regression shrinkage and selection via the lasso , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 1996 , publisher=
work page 1996
-
[46]
Monographs on statistics and applied probability , volume=
Statistical learning with sparsity , author=. Monographs on statistics and applied probability , volume=. 2015 , publisher=
work page 2015
-
[47]
IEEE Transactions on signal processing , volume=
Matching pursuits with time-frequency dictionaries , author=. IEEE Transactions on signal processing , volume=. 1993 , publisher=
work page 1993
-
[48]
757 arxiv e-prints p , author=
Just interpolate: Kernel” ridgeless” regression can generalize. 757 arxiv e-prints p , author=. arXiv preprint arXiv:1808.00387 , volume=
-
[49]
International Conference on Machine Learning , pages=
Margins, shrinkage, and boosting , author=. International Conference on Machine Learning , pages=. 2013 , organization=
work page 2013
-
[50]
International Conference on Artificial Intelligence and Statistics , pages=
Tight bounds for minimum _1 -norm interpolation of noisy data , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2022 , organization=
work page 2022
-
[51]
arXiv e-prints, page , author=
The distribution of the Lasso: Uniform control over sparse balls and adaptive parameter tuning. arXiv e-prints, page , author=. arXiv preprint arXiv:1811.01212 , year=
-
[52]
International Conference on Artificial Intelligence and Statistics , pages=
Fundamental limits of ridge-regularized empirical risk minimization in high dimensions , author=. International Conference on Artificial Intelligence and Statistics , pages=. 2021 , organization=
work page 2021
-
[53]
The Annals of Statistics , volume=
The lasso with general gaussian designs with applications to hypothesis testing , author=. The Annals of Statistics , volume=. 2023 , publisher=
work page 2023
-
[54]
Scaled sparse linear regression , author=. Biometrika , volume=. 2012 , publisher=
work page 2012
-
[55]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Variance estimation using refitted cross-validation in ultrahigh dimensional regression , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2012 , publisher=
work page 2012
-
[56]
IEEE Transactions on Information theory , volume=
Universal approximation bounds for superpositions of a sigmoidal function , author=. IEEE Transactions on Information theory , volume=. 2002 , publisher=
work page 2002
-
[57]
Advances in neural information processing systems , volume=
Benign overfitting in two-layer convolutional neural networks , author=. Advances in neural information processing systems , volume=
-
[58]
International conference on machine learning , pages=
Benign overfitting in two-layer relu convolutional neural networks , author=. International conference on machine learning , pages=. 2023 , organization=
work page 2023
-
[59]
International Conference on Machine Learning , pages=
Benign overfitting in deep neural networks under lazy training , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[60]
arXiv preprint arXiv:2510.15337 , year=
Transfer Learning for Benign Overfitting in High-Dimensional Linear Regression , author=. arXiv preprint arXiv:2510.15337 , year=
-
[61]
arXiv preprint arXiv:2410.01774 , year=
Trained transformer classifiers generalize and exhibit benign overfitting in-context , author=. arXiv preprint arXiv:2410.01774 , year=
-
[62]
Advances in Neural Information Processing Systems , volume=
Unveil benign overfitting for transformer in vision: Training dynamics, convergence, and generalization , author=. Advances in Neural Information Processing Systems , volume=
-
[63]
arXiv preprint arXiv:2410.07746 , year=
Benign overfitting in single-head attention , author=. arXiv preprint arXiv:2410.07746 , year=
-
[64]
arXiv preprint arXiv:2409.17625 , year=
Benign Overfitting in Token Selection of Attention Mechanism , author=. arXiv preprint arXiv:2409.17625 , year=
-
[65]
arXiv preprint arXiv:2410.19139 , year=
Initialization matters: On the benign overfitting of two-layer relu cnn with fully trainable layers , author=. arXiv preprint arXiv:2410.19139 , year=
-
[66]
arXiv preprint arXiv:2502.11893 , year=
Rethinking benign overfitting in two-layer neural networks , author=. arXiv preprint arXiv:2502.11893 , year=
-
[67]
Benign, tempered, or catastrophic: A taxonomy of overfitting , author=. URL https://arxiv. org/abs/2207 , volume=
-
[68]
High-dimensional statistics: A non-asymptotic viewpoint , author=. 2019 , publisher=
work page 2019
-
[69]
Electronic Journal of Statistics , volume=
The lasso problem and uniqueness , author=. Electronic Journal of Statistics , volume=
-
[70]
IEEE Transactions on Information Theory , volume=
Random forests and kernel methods , author=. IEEE Transactions on Information Theory , volume=. 2016 , publisher=
work page 2016
-
[71]
A random forest guided tour , author=. Test , volume=. 2016 , publisher=
work page 2016
-
[72]
International conference on machine learning , pages=
On the spectral bias of neural networks , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
-
[73]
The Annals of Statistics , volume=
High-dimensional asymptotics of prediction: Ridge regression and classification , author=. The Annals of Statistics , volume=. 2018 , publisher=
work page 2018
-
[74]
Journal of the american statistical association , volume=
Adapting to unknown smoothness via wavelet shrinkage , author=. Journal of the american statistical association , volume=. 1995 , publisher=
work page 1995
-
[75]
Mills, J. P. , title=. Biometrika , volume=
- [76]
-
[77]
An introduction to probability theory and its applications, Volume 1 , author=. 1968 , publisher=
work page 1968
-
[78]
Handbook of mathematical functions, with formulas, graphs, and mathematical tables , author=. 1966 , publisher=
work page 1966
-
[79]
Limit of the smallest eigenvalue of a large dimensional sample covariance matrix , author=. Ann. Probab , volume=. 1993 , publisher=
work page 1993
-
[80]
Aspects of multivariate statistical theory , author=. 2009 , publisher=
work page 2009
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.