Recognition: 2 theorem links
· Lean TheoremLoop, Think, & Generalize: Implicit Reasoning in Recurrent-Depth Transformers
Pith reviewed 2026-05-10 17:46 UTC · model grok-4.3
The pith
Recurrent-depth transformers achieve systematic generalization and depth extrapolation in implicit reasoning by iterating over shared layers.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
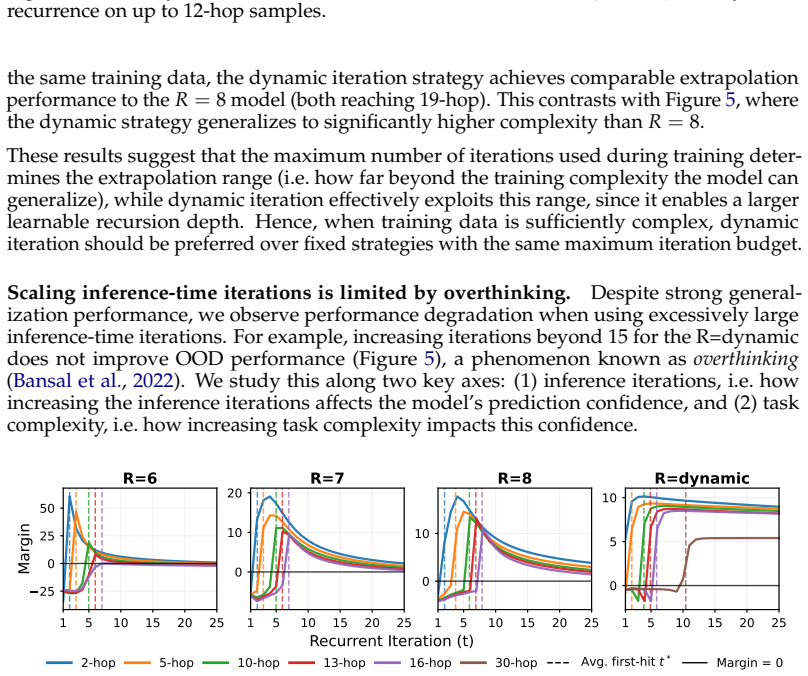
Recurrent-depth transformers enable effective implicit reasoning on compositional tasks by allowing iterative computation over the same transformer layers. While vanilla transformers struggle with systematic generalization to unseen knowledge combinations and with depth extrapolation beyond training depths, recurrent-depth models succeed. Systematic generalization emerges via a three-stage process of memorization, in-distribution generalization, and finally out-of-distribution systematic generalization. Depth extrapolation is unlocked by scaling the number of recurrent iterations at inference time, with training strategies influencing the extent of generalization, though excessive recurrence
What carries the argument
Recurrent-depth transformers, which reuse the same set of transformer layers for multiple iterations inside one forward pass to support iterative computation.
If this is right
- Models trained only on shallow reasoning depths can handle deeper compositions when more recurrent iterations are used at test time.
- Systematic generalization to novel knowledge combinations appears after the model passes through memorization and in-distribution stages.
- Training choices such as the recurrence depth used during training control how far extrapolation extends.
- Excessive recurrence produces overthinking that degrades accuracy and caps generalization at very high depths.
Where Pith is reading between the lines
- The same iterative reuse might let large pre-trained models handle longer multi-hop chains on natural text without full retraining.
- The three-stage grokking pattern could appear as measurable shifts in attention or hidden-state similarity during training on real data.
- Overthinking might be mitigated by learned stopping criteria or depth-dependent regularization that the paper does not explore.
Load-bearing premise
The controlled results from models trained from scratch on synthetic tasks will transfer to the implicit reasoning behavior of large pre-trained language models on natural language.
What would settle it
Train a recurrent-depth transformer on synthetic compositional questions with a maximum of five reasoning hops and then measure whether raising the number of inference-time iterations produces accurate answers on ten-hop questions that require both deeper chaining and novel combinations of training knowledge.
Figures

















read the original abstract
We study implicit reasoning, i.e. the ability to combine knowledge or rules within a single forward pass. While transformer-based large language models store substantial factual knowledge and rules, they often fail to compose this knowledge for implicit multi-hop reasoning, suggesting a lack of compositional generalization over their parametric knowledge. To address this limitation, we study recurrent-depth transformers, which enables iterative computation over the same transformer layers. We investigate two compositional generalization challenges under the implicit reasoning scenario: systematic generalization, i.e. combining knowledge that is never used for compositions during training, and depth extrapolation, i.e. generalizing from limited reasoning depth (e.g. training on up to 5-hop) to deeper compositions (e.g. 10-hop). Through controlled studies with models trained from scratch, we show that while vanilla transformers struggle with both generalization challenges, recurrent-depth transformers can effectively make such generalization. For systematic generalization, we find that this ability emerges through a three-stage grokking process, transitioning from memorization to in-distribution generalization and finally to systematic generalization, supported by mechanistic analysis. For depth extrapolation, we show that generalization beyond training depth can be unlocked by scaling inference-time recurrence, with more iterations enabling deeper reasoning. We further study how training strategies affect extrapolation, providing guidance on training recurrent-depth transformers, and identify a key limitation, overthinking, where excessive recurrence degrades predictions and limits generalization to very deep compositions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper studies implicit reasoning in transformers by introducing recurrent-depth models that perform iterative computation over shared layers. On synthetic compositional tasks trained from scratch, it claims vanilla transformers fail at systematic generalization (combining unseen knowledge compositions) and depth extrapolation (generalizing to deeper hops than trained), while recurrent-depth variants succeed: systematic generalization emerges via a three-stage grokking process (memorization to in-distribution to systematic), and depth extrapolation is unlocked by scaling inference-time recurrence steps, with additional analysis of training strategies and the overthinking limitation.
Significance. If the empirical results and mechanistic analysis hold, the work provides concrete evidence that architectural recurrence can unlock compositional generalization behaviors absent in standard transformers, including a documented grokking trajectory and a practical inference-time scaling mechanism for depth extrapolation. The controlled synthetic setup and identification of overthinking offer useful guidance for future architectural variants.
major comments (2)
- [Introduction] Introduction and abstract: the opening diagnosis of transformer LLMs failing on implicit multi-hop composition over parametric knowledge is not followed by any experiments, fine-tuning, or mechanistic analysis on pre-trained models or natural-language data; all results are confined to from-scratch training on synthetic tasks, so the claimed relevance to LLM implicit reasoning rests on an untested transfer assumption.
- [Experiments] Experimental sections (methods and results): the controlled studies are described at a high level without reported effect sizes, exact data splits, ablation tables, or statistical tests for the three-stage grokking trajectory and recurrence-scaling claims; this makes it difficult to assess whether post-hoc task definitions or narrow synthetic distributions drive the reported generalization advantages.
minor comments (2)
- [Abstract] The abstract and conclusion could explicitly qualify that all findings are demonstrated only in the synthetic from-scratch regime to avoid overgeneralization to pre-trained LLMs.
- [Methods] Notation for recurrence depth and inference-time iteration count should be unified across sections to prevent confusion between training and test-time usage.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address the major comments point by point below, providing clarifications and committing to revisions that strengthen the manuscript without misrepresenting our synthetic, from-scratch experimental scope.
read point-by-point responses
-
Referee: [Introduction] Introduction and abstract: the opening diagnosis of transformer LLMs failing on implicit multi-hop composition over parametric knowledge is not followed by any experiments, fine-tuning, or mechanistic analysis on pre-trained models or natural-language data; all results are confined to from-scratch training on synthetic tasks, so the claimed relevance to LLM implicit reasoning rests on an untested transfer assumption.
Authors: We acknowledge that all experiments use from-scratch training on synthetic tasks. This controlled setup was deliberately chosen to isolate the mechanisms of implicit reasoning, systematic generalization, and depth extrapolation, allowing precise manipulation of knowledge compositions and reasoning depths that are infeasible to control in pre-trained LLMs. The synthetic tasks are constructed to directly instantiate the multi-hop composition challenges described in the introduction. We agree that transfer to LLMs remains an assumption at this stage. In the revision we will add an explicit limitations paragraph in the introduction and a dedicated Limitations section that states this assumption, discusses why synthetic studies provide foundational mechanistic evidence, and outlines future work on fine-tuning or analyzing pre-trained models. revision: partial
-
Referee: [Experiments] Experimental sections (methods and results): the controlled studies are described at a high level without reported effect sizes, exact data splits, ablation tables, or statistical tests for the three-stage grokking trajectory and recurrence-scaling claims; this makes it difficult to assess whether post-hoc task definitions or narrow synthetic distributions drive the reported generalization advantages.
Authors: We agree that greater experimental detail is needed for reproducibility and to rule out concerns about task construction or distribution narrowness. In the revised manuscript we will expand the Methods and Results sections to report: exact data generation procedures and train/validation/test splits; quantitative effect sizes (accuracy deltas with confidence intervals); full ablation tables covering training strategies, recurrence steps, and model variants; and statistical tests (e.g., paired t-tests or bootstrap resampling across random seeds) supporting the three-stage grokking trajectory and inference-time scaling results. These additions will make the robustness of the findings clearer. revision: yes
Circularity Check
No circularity: empirical study with experimental outcomes on synthetic tasks
full rationale
The paper reports controlled experiments training models from scratch on synthetic compositional tasks to evaluate systematic generalization and depth extrapolation in recurrent-depth transformers versus vanilla transformers. Claims rest on observed training dynamics (e.g., three-stage grokking), mechanistic analysis, and inference-time scaling results rather than any mathematical derivation, equation, or parameter fit that reduces to its own inputs by construction. No self-definitional steps, fitted quantities renamed as predictions, or load-bearing self-citations appear in the methodology or results chain.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanreality_from_one_distinction unclearrecurrent-depth transformers... iterative computation over the same transformer layers... scaling inference-time recurrence... three-stage grokking process
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearJcost uniqueness... phi-ladder... 8-tick period
Forward citations
Cited by 3 Pith papers
-
SMolLM: Small Language Models Learn Small Molecular Grammar
A 53K-parameter model generates 95% valid SMILES on ZINC-250K, outperforming larger models, by resolving chemical constraints in fixed order: brackets first, rings second, valence last.
-
Memory-Efficient Looped Transformer: Decoupling Compute from Memory in Looped Language Models
MELT decouples reasoning depth from memory in looped LLMs by sharing a single gated KV cache per layer and using two-phase chunk-wise distillation from Ouro, delivering constant memory use while matching or beating st...
-
Hyperloop Transformers
Hyperloop Transformers outperform standard and mHC Transformers with roughly 50% fewer parameters by looping a middle block of layers and applying hyper-connections only after each loop.
Reference graph
Works this paper leans on
-
[1]
URLhttps://openreview.net/forum?id=2edigk8yoU. Leo Gao, Stella Biderman, Sid Black, Laurence Golding, Travis Hoppe, Charles Foster, Jason Phang, Horace He, Anish Thite, Noa Nabeshima, et al. The pile: An 800gb dataset of diverse text for language modeling.arXiv preprint arXiv:2101.00027, 2020. Jonas Geiping, Sean Michael McLeish, Neel Jain, John Kirchenba...
-
[2]
Prabha, D., Aswini, J., Maheswari, B., Subramanian, R
URLhttps://aclanthology.org/2025.naacl-long.420/. Brenden Lake and Marco Baroni. Generalization without systematicity: On the composi- tional skills of sequence-to-sequence recurrent networks. InInternational conference on machine learning, pp. 2873–2882. PMLR, 2018. Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, and Radu Sori...
-
[3]
URLhttps://aclanthology.org/2024.acl-long.550/. Yuekun Yao, Yupei Du, Dawei Zhu, Michael Hahn, and Alexander Koller. Language models can learn implicit multi-hop reasoning, but only if they have lots of training data. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng (eds.), Proceedings of the 2025 Conference on Empirical M...
-
[4]
Using 3 representative tasks, Dziri et al
and a proxy for analyzing how models can learn internal mechanisms for combining facts instead of emitting long rationales in the form of CoT. Using 3 representative tasks, Dziri et al. (2023) demonstrate that transformers reduce compositional tasks to linearized subgraph matching that fails with increasing complexity. Wang et al. (2024a) show that transf...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.