Recognition: unknown
Teaching Thinking Models to Reason with Tools: A Full-Pipeline Recipe for Tool-Integrated Reasoning
Pith reviewed 2026-05-08 10:23 UTC · model grok-4.3
The pith
A full training recipe lets strong thinking models adopt tool use without losing their text-only reasoning strengths.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
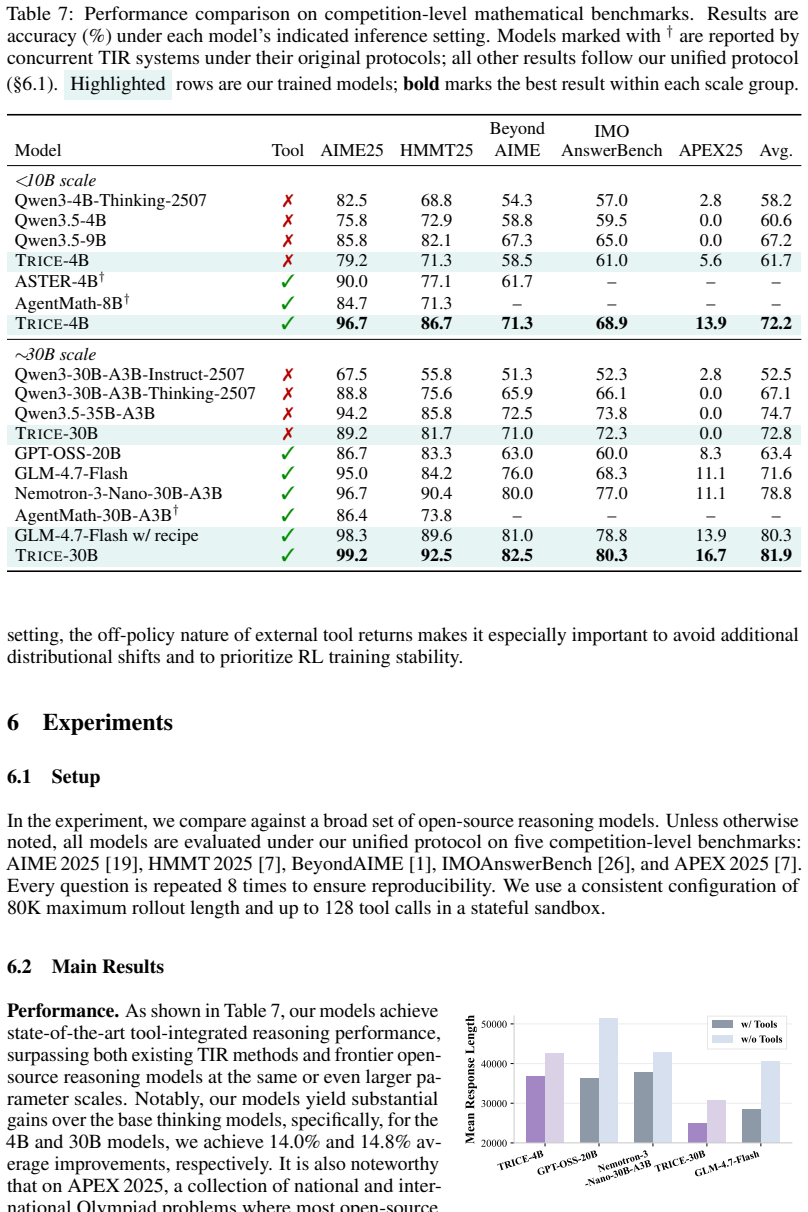
We present a comprehensive tool-integrated reasoning recipe that prioritizes learnable teacher trajectories for supervised fine-tuning, controls the proportion of tool-use data to prevent forgetting of text-only capabilities, optimizes for pass@k and response length rather than loss, and follows with a stable reinforcement learning stage using verifiable rewards. When applied to thinking models at 4B and 30B scales, this recipe yields models that achieve state-of-the-art performance among open-source models on multiple benchmarks, including 96.7 percent on AIME 2025 for the 4B model and 99.2 percent for the 30B model.
What carries the argument
The TIR full-pipeline recipe, which combines selective SFT on tool-augmented trajectories with proportion control and a safeguarded RLVR stage to enable tool use while maintaining original reasoning.
If this is right
- Thinking models can be extended to use tools effectively on problems suited for them.
- Catastrophic forgetting of no-tool reasoning can be mitigated by balancing training data proportions.
- Optimizing training for pass@k and length rather than loss leaves room for further RL improvements.
- Stable RL with verifiable rewards provides effective final gains after proper SFT initialization.
- Open-source models can reach performance levels like 99 percent on advanced math benchmarks such as AIME 2025.
Where Pith is reading between the lines
- This method may allow smaller models to compete with larger ones by adding tool capabilities strategically.
- Similar balancing techniques could apply to integrating other modalities or capabilities without interference.
- Future work might test if the recipe generalizes to non-math domains like coding or science question answering.
- Explicit safeguards against mode collapse in RL could become standard for tool-augmented training.
Load-bearing premise
That suitable teacher trajectories exist which are inherently learnable for tool solutions and that simply controlling their training proportion will reliably avoid forgetting without needing extra checks.
What would settle it
If models trained with the full recipe show either no improvement in tool-use tasks or significant drops in performance on pure text reasoning benchmarks compared to the base thinking models.
Figures







read the original abstract
Tool-integrated reasoning (TIR) offers a direct way to extend thinking models beyond the limits of text-only reasoning. Paradoxically, we observe that tool-enabled evaluation can degrade reasoning performance even when the strong thinking models make almost no actual tool calls. In this paper, we investigate how to inject natural tool-use behavior into a strong thinking model without sacrificing its no-tool reasoning ability, and present a comprehensive TIR recipe. We highlight that (i) the effectiveness of TIR supervised fine-tuning (SFT) hinges on the learnability of teacher trajectories, which should prioritize problems inherently suited for tool-augmented solutions; (ii) controlling the proportion of tool-use trajectories could mitigate the catastrophic forgetting of text-only reasoning capacity; (iii) optimizing for pass@k and response length instead of training loss could maximize TIR SFT gains while preserving headroom for reinforcement learning (RL) exploration; (iv) a stable RL with verifiable rewards (RLVR) stage, built upon suitable SFT initialization and explicit safeguards against mode collapse, provides a simple yet remarkably effective solution. When applied to Qwen3 thinking models at 4B and 30B scales, our recipe yields models that achieve state-of-the-art performance in a wide range of benchmarks among open-source models, such as 96.7% and 99.2% on AIME 2025 for 4B and 30B, respectively.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a full-pipeline recipe for tool-integrated reasoning (TIR) in thinking models. Key components include: (i) SFT on teacher trajectories selected for inherent learnability (prioritizing problems suited to tool-augmented solutions), (ii) controlling the proportion of tool-use trajectories during SFT to mitigate catastrophic forgetting of text-only reasoning, (iii) optimizing SFT for pass@k and response length rather than training loss to preserve RL headroom, and (iv) a stable RLVR stage with safeguards against mode collapse. Applied to Qwen3 thinking models at 4B and 30B scales, the recipe is claimed to yield open-source SOTA results, including 96.7% and 99.2% on AIME 2025 for the respective scales.
Significance. If the reported gains prove robust under controlled ablations, the work could meaningfully advance practical TIR training by addressing the observed paradox of tool-enabled evaluation degrading performance. The emphasis on trajectory learnability, proportion control, and pass@k optimization offers concrete, reproducible guidance for practitioners. The large-scale application to Qwen3 models and the comprehensive pipeline (SFT + RLVR) are strengths that distinguish it from narrower TIR studies.
major comments (2)
- [Abstract] Abstract: The headline SOTA claims (96.7% AIME 2025 for 4B, 99.2% for 30B) are presented without any reported base-model numbers, ablation results isolating the contribution of trajectory selection or proportion control, error bars, or data-split details. These omissions are load-bearing for the central empirical claim that the full TIR recipe (rather than the strong Qwen3 base) produces the gains.
- [SFT stage description] SFT stage description (points (i) and (ii)): The assertions that 'effectiveness hinges on the learnability of teacher trajectories' and that 'controlling the proportion of tool-use trajectories could mitigate catastrophic forgetting' are stated without concrete selection criteria for learnable trajectories, the specific proportion values employed, or quantitative forgetting metrics (e.g., no-tool benchmark deltas before/after SFT). This directly underpins the recipe's claimed reliability.
minor comments (1)
- [Abstract] The abstract refers to 'a wide range of benchmarks' but provides concrete numbers only for AIME 2025; adding one or two additional headline results with base-model comparisons would improve readability.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive comments. We agree that the presentation of results and methodological details can be strengthened for clarity and reproducibility. Below, we provide point-by-point responses to the major comments and outline the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline SOTA claims (96.7% AIME 2025 for 4B, 99.2% for 30B) are presented without any reported base-model numbers, ablation results isolating the contribution of trajectory selection or proportion control, error bars, or data-split details. These omissions are load-bearing for the central empirical claim that the full TIR recipe (rather than the strong Qwen3 base) produces the gains.
Authors: We agree with the referee that the abstract would benefit from additional context to support the central claims. We will revise the abstract to include the base model performances on AIME 2025 and other benchmarks, as well as a brief mention of the ablation studies that isolate the effects of trajectory selection and proportion control. Furthermore, we will incorporate error bars from our experimental runs and provide data-split details in the methods section of the revised manuscript. These changes will clarify that the gains are attributable to the TIR recipe rather than solely the base model strength. revision: yes
-
Referee: [SFT stage description] SFT stage description (points (i) and (ii)): The assertions that 'effectiveness hinges on the learnability of teacher trajectories' and that 'controlling the proportion of tool-use trajectories could mitigate catastrophic forgetting' are stated without concrete selection criteria for learnable trajectories, the specific proportion values employed, or quantitative forgetting metrics (e.g., no-tool benchmark deltas before/after SFT). This directly underpins the recipe's claimed reliability.
Authors: We appreciate this feedback on the SFT stage description. The current manuscript presents these points at a high level based on our iterative development process. To enhance reproducibility and address the concern, we will expand the description with concrete selection criteria for learnable trajectories, the specific proportion values employed, and quantitative metrics on forgetting (e.g., no-tool benchmark deltas before/after SFT). These details will be added to the revised SFT stage section along with supporting tables or figures. revision: yes
Circularity Check
No circularity: empirical training recipe with benchmark outcomes
full rationale
The paper describes an empirical pipeline for tool-integrated reasoning (TIR) on Qwen3 models, consisting of observations about tool-use degradation, SFT on learnable trajectories, proportion control, pass@k optimization, and RLVR. Performance numbers (e.g., 96.7%/99.2% on AIME 2025) are reported as direct training results on benchmarks. No equations, derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would reduce any claim to its inputs by construction. The central claims remain falsifiable experimental outcomes rather than tautological re-statements.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
BeyondAIME: Advancing math reasoning evaluation beyond high school olympiads
ByteDance-Seed. BeyondAIME: Advancing math reasoning evaluation beyond high school olympiads. https://huggingface.co/datasets/ByteDance-Seed/BeyondAIME, 2025. Hugging Face dataset
2025
-
[2]
P1: Mastering physics olympiads with reinforcement learning.arXiv preprint arXiv:2511.13612, 2025
Jiacheng Chen, Qianjia Cheng, Fangchen Yu, Haiyuan Wan, Yuchen Zhang, Shenghe Zheng, Junchi Yao, Qingyang Zhang, Haonan He, Yun Luo, et al. P1: Mastering physics olympiads with reinforcement learning.arXiv preprint arXiv:2511.13612, 2025
-
[3]
Process Reinforcement through Implicit Rewards
Ganqu Cui, Lifan Yuan, Zefan Wang, Hanbin Wang, Yuchen Zhang, Jiacheng Chen, Wendi Li, Bingxiang He, Yuchen Fan, Tianyu Yu, et al. Process reinforcement through implicit rewards. arXiv preprint arXiv:2502.01456, 2025
work page internal anchor Pith review arXiv 2025
-
[4]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, et al. The entropy mechanism of reinforcement learning for reasoning language models.arXiv preprint arXiv:2505.22617, 2025
work page internal anchor Pith review arXiv 2025
-
[5]
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, Damai D...
work page internal anchor Pith review arXiv 2025
-
[6]
DeepSeek-AI, Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenhao Xu, Chong Ruan, Damai Dai, Daya Guo, Dejian Yang, Deli Chen, 10 Erhang Li, Fangqi Zhou, Fangyun Lin, Fucong Dai, Guangbo Hao, Guanting Chen, Guowei Li, H. Zhang, Hanwei Xu,...
work page internal anchor Pith review arXiv 2025
-
[7]
Beyond Benchmarks: MathArena as an Evaluation Platform for Mathematics with LLMs
Jasper Dekoninck, Nikola Jovanovi´c, Tim Gehrunger, Kári Rögnvalddson, Ivo Petrov, Chenhao Sun, and Martin Vechev. Beyond benchmarks: Matharena as an evaluation platform for mathematics with llms. 2026. URLhttps://arxiv.org/abs/2605.00674
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[8]
Agentic reinforced policy optimization.arXiv preprint arXiv:2507.19849, 2025
Guanting Dong, Hangyu Mao, Kai Ma, Licheng Bao, Yifei Chen, Zhongyuan Wang, Zhongxia Chen, Jiazhen Du, Huiyang Wang, Fuzheng Zhang, et al. Agentic reinforced policy optimization. arXiv preprint arXiv:2507.19849, 2025
-
[9]
Wei Du, Shubham Toshniwal, Branislav Kisacanin, Sadegh Mahdavi, Ivan Moshkov, George Armstrong, Stephen Ge, Edgar Minasyan, Feng Chen, and Igor Gitman. Nemotron-math: Efficient long-context distillation of mathematical reasoning from multi-mode supervision. arXiv preprint arXiv:2512.15489, 2025
-
[10]
Generalizable end-to-end tool-use rl with synthetic codegym.arXiv preprint arXiv:2509.17325, 2025
Weihua Du, Hailei Gong, Zhan Ling, Kang Liu, Lingfeng Shen, Xuesong Yao, Yufei Xu, Dingyuan Shi, Yiming Yang, and Jiecao Chen. Generalizable end-to-end tool-use rl with synthetic codegym.arXiv preprint arXiv:2509.17325, 2025
-
[11]
ReTool: Reinforcement Learning for Strategic Tool Use in LLMs
Jiazhan Feng, Shijue Huang, Xingwei Qu, Ge Zhang, Yujia Qin, Baoquan Zhong, Chengquan Jiang, Jinxin Chi, and Wanjun Zhong. Retool: Reinforcement learning for strategic tool use in llms, 2025. URLhttps://arxiv.org/abs/2504.11536
work page internal anchor Pith review arXiv 2025
-
[12]
PAL: Program-aided language models
Luyu Gao, Aman Madaan, Shuyan Zhou, Uri Alon, Pengfei Liu, Yiming Yang, Jamie Callan, and Graham Neubig. PAL: Program-aided language models. In Andreas Krause, Emma Brunskill, Kyunghyun Cho, Barbara Engelhardt, Sivan Sabato, and Jonathan Scarlett, editors,Proceedings 11 of the 40th International Conference on Machine Learning, volume 202 ofProceedings of ...
2023
-
[13]
How to train long-context language models (effectively)
Tianyu Gao, Alexander Wettig, Howard Yen, and Danqi Chen. How to train long-context language models (effectively). InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 7376–7399, 2025
2025
-
[14]
OpenThoughts: Data Recipes for Reasoning Models
Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, et al. Openthoughts: Data recipes for reasoning models.arXiv preprint arXiv:2506.04178, 2025
work page internal anchor Pith review arXiv 2025
-
[15]
JustRL: Scaling a 1.5B LLM with a simple RL recipe.arXiv preprint arXiv:2512.16649, 2025
Bingxiang He, Zekai Qu, Zeyuan Liu, Yinghao Chen, Yuxin Zuo, Cheng Qian, Kaiyan Zhang, Weize Chen, Chaojun Xiao, Ganqu Cui, et al. Justrl: Scaling a 1.5 b llm with a simple rl recipe. arXiv preprint arXiv:2512.16649, 2025
-
[16]
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code
Naman Jain, King Han, Alex Gu, Wen-Ding Li, Fanjia Yan, Tianjun Zhang, Sida Wang, Ar- mando Solar-Lezama, Koushik Sen, and Ion Stoica. Livecodebench: Holistic and contamination free evaluation of large language models for code, 2024. URL https://arxiv.org/abs/ 2403.07974
work page internal anchor Pith review arXiv 2024
-
[17]
Rocode: Integrating backtracking mechanism and program analysis in large language models for code generation
Xue Jiang, Yihong Dong, Yongding Tao, Huanyu Liu, Zhi Jin, and Ge Li. Rocode: Integrating backtracking mechanism and program analysis in large language models for code generation. In2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE), pages 334–346. IEEE, 2025
2025
-
[18]
Cort: Code-integrated reasoning within thinking, 2025
Chengpeng Li, Zhengyang Tang, Ziniu Li, Mingfeng Xue, Keqin Bao, Tian Ding, Ruoyu Sun, Benyou Wang, Xiang Wang, Junyang Lin, and Dayiheng Liu. Cort: Code-integrated reasoning within thinking, 2025. URLhttps://arxiv.org/abs/2506.09820
-
[19]
Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions.Hugging Face repository, 13:9, 2024
Jia Li, Edward Beeching, Lewis Tunstall, Ben Lipkin, Roman Soletskyi, Shengyi Huang, Kashif Rasul, Longhui Yu, Albert Q Jiang, Ziju Shen, et al. Numinamath: The largest public dataset in ai4maths with 860k pairs of competition math problems and solutions.Hugging Face repository, 13:9, 2024
2024
-
[20]
Discovery and reinforcement of tool-integrated reasoning chains via rollout trees, 2026
Kun Li, Zenan Xu, Junan Li, Zengrui Jin, Jinghao Deng, Zexuan Qiu, and Bo Zhou. Discovery and reinforcement of tool-integrated reasoning chains via rollout trees, 2026. URL https: //arxiv.org/abs/2601.08274
-
[21]
Yingru Li, Jiawei Xu, Jiacai Liu, Yuxuan Tong, Ziniu Li, Tianle Cai, Ge Zhang, Qian Liu, and Baoxiang Wang. Taming the tail: Stable llm reinforcement learning via dynamic vocabulary pruning.arXiv preprint arXiv:2512.23087, 2025
-
[22]
arXiv preprint arXiv:2508.19201 , year=
Heng Lin and Zhongwen Xu. Understanding tool-integrated reasoning, 2025. URL https: //arxiv.org/abs/2508.19201
-
[23]
When speed kills stability: Demystifying rl collapse from the training-inference mismatch.Notion Blog, 2025
Jiacai Liu, Yingru Li, Yuqian Fu, Jiawei Wang, Qian Liu, and Yu Shen. When speed kills stability: Demystifying rl collapse from the training-inference mismatch.Notion Blog, 2025
2025
-
[24]
Renjie Luo, Jiaxi Li, Chen Huang, and Wei Lu. Through the valley: Path to effective long CoT training for small language models. In Christos Christodoulopoulos, Tanmoy Chakraborty, Carolyn Rose, and Violet Peng, editors,Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 4972–4992, Suzhou, China, November 2025. As...
-
[25]
Yun Luo, Futing Wang, Qianjia Cheng, Fangchen Yu, Haodi Lei, Jianhao Yan, Chenxi Li, Jiacheng Chen, Yufeng Zhao, Haiyuan Wan, et al. P1-vl: bridging visual perception and scientific reasoning in physics olympiads.arXiv preprint arXiv:2602.09443, 2026
-
[26]
Thang Luong, Dawsen Hwang, Hoang H. Nguyen, Golnaz Ghiasi, Yuri Chervonyi, Insuk Seo, Junsu Kim, Garrett Bingham, Jonathan Lee, Swaroop Mishra, Alex Zhai, Clara Huiyi Hu, Henryk Michalewski, Jimin Kim, Jeonghyun Ahn, Junhwi Bae, Xingyou Song, Trieu H. Trinh, 12 Quoc V . Le, and Junehyuk Jung. Towards robust mathematical reasoning. InProceedings of the 202...
2025
-
[27]
Wenhan Ma, Hailin Zhang, Liang Zhao, Yifan Song, Yudong Wang, Zhifang Sui, and Fuli Luo. Stabilizing moe reinforcement learning by aligning training and inference routers, 2025. URL https://arxiv.org/abs/2510.11370
-
[28]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI. gpt-oss-120b and gpt-oss-20b model card, 2025. URL https://arxiv.org/abs/ 2508.10925
work page internal anchor Pith review arXiv 2025
-
[29]
OpenAI, Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Flo- rencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, Red Avila, Igor Babuschkin, Suchir Balaji, Valerie Balcom, Paul Baltescu, Haiming Bao, Mohammad Bavarian, Jeff Belgum, Irwan Bello, Jake Berdine, Gabriel Bernadett-Shapiro, Christopher Bern...
work page internal anchor Pith review arXiv 2024
-
[30]
Gpqa: A graduate-level google-proof q&a benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark. InFirst Conference on Language Modeling, 2024
2024
-
[31]
rstar2-agent: Agentic reasoning technical report, 2025
Ning Shang, Yifei Liu, Yi Zhu, Li Lyna Zhang, Weijiang Xu, Xinyu Guan, Buze Zhang, Bingcheng Dong, Xudong Zhou, Bowen Zhang, et al. rstar2-agent: Agentic reasoning technical report.arXiv preprint arXiv:2508.20722, 2025
-
[32]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. URL https://arxiv.org/abs/ 2402.03300
work page internal anchor Pith review arXiv 2024
-
[33]
MIT press, 2018
Richard S Sutton and Andrew G Barto.Reinforcement learning: An introduction. MIT press, 2018
2018
-
[34]
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
5 Team, Aohan Zeng, Xin Lv, Qinkai Zheng, Zhenyu Hou, Bin Chen, Chengxing Xie, Cunxiang Wang, Da Yin, Hao Zeng, Jiajie Zhang, Kedong Wang, Lucen Zhong, Mingdao Liu, Rui Lu, Shulin Cao, Xiaohan Zhang, Xuancheng Huang, Yao Wei, Yean Cheng, Yifan An, Yilin Niu, Yuanhao Wen, Yushi Bai, Zhengxiao Du, Zihan Wang, Zilin Zhu, Bohan Zhang, Bosi Wen, Bowen Wu, Bowe...
work page internal anchor Pith review arXiv 2025
-
[35]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, S. H. Cai, Yuan Cao, Y . Charles, H. S. Che, Cheng Chen, Guanduo Chen, Huarong Chen, Jia Chen, Jiahao Chen, Jianlong Chen, Jun Chen, Kefan Chen, Liang Chen, Ruijue Chen, Xinhao Chen, Yanru Chen, Yanxu Chen, Yicun Chen, Yimin Chen, Yingjiang Chen, Yuankun Chen, Yujie Chen, Yutian Chen, Zhirong Chen, Ziwei Che...
work page internal anchor Pith review arXiv 2026
-
[36]
Minimax m2.7: Early echoes of self-evolution
Minimax Team. Minimax m2.7: Early echoes of self-evolution. https://www.minimax.io/news/minimax-m27-en, 2026
2026
-
[37]
Guoqing Wang, Sunhao Dai, Guangze Ye, Zeyu Gan, Wei Yao, Yong Deng, Xiaofeng Wu, and Zhenzhe Ying. Information gain-based policy optimization: A simple and effective approach for multi-turn llm agents.arXiv preprint arXiv:2510.14967, 2025
-
[38]
Miles Wang, Robi Lin, Kat Hu, Joy Jiao, Neil Chowdhury, Ethan Chang, and Tejal Patwardhan
Miles Wang, Robi Lin, Kat Hu, Joy Jiao, Neil Chowdhury, Ethan Chang, and Tejal Patwardhan. Frontierscience: Evaluating ai’s ability to perform expert-level scientific tasks.arXiv preprint arXiv:2601.21165, 2026
-
[39]
Peng Xia, Kaide Zeng, Jiaqi Liu, Can Qin, Fang Wu, Yiyang Zhou, Caiming Xiong, and Huaxiu Yao. Agent0: Unleashing self-evolving agents from zero data via tool-integrated reasoning. arXiv preprint arXiv:2511.16043, 2025
-
[40]
Zhenghai Xue, Longtao Zheng, Qian Liu, Yingru Li, Xiaosen Zheng, Zejun Ma, and Bo An. Simpletir: End-to-end reinforcement learning for multi-turn tool-integrated reasoning, 2025. URLhttps://arxiv.org/abs/2509.02479
-
[41]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review arXiv 2025
-
[42]
Demystifying reinforcement learning in agentic reasoning.arXiv preprint arXiv:2510.11701, 2025
Zhaochen Yu, Ling Yang, Jiaru Zou, Shuicheng Yan, and Mengdi Wang. Demystifying reinforcement learning in agentic reasoning.arXiv preprint arXiv:2510.11701, 2025. 15
-
[43]
arXiv preprint arXiv:2509.25123 , year=
Lifan Yuan, Weize Chen, Yuchen Zhang, Ganqu Cui, Hanbin Wang, Ziming You, Ning Ding, Zhiyuan Liu, Maosong Sun, and Hao Peng. From f(x) and g(x) to f(g(x)) : Llms learn new skills in rl by composing old ones.arXiv preprint arXiv:2509.25123, 2025
-
[44]
SimpleRL-Zoo: Investigating and Taming Zero Reinforcement Learning for Open Base Models in the Wild
Weihao Zeng, Yuzhen Huang, Qian Liu, Wei Liu, Keqing He, Zejun Ma, and Junxian He. Simplerl-zoo: Investigating and taming zero reinforcement learning for open base models in the wild, 2025. URLhttps://arxiv.org/abs/2503.18892
work page internal anchor Pith review arXiv 2025
-
[45]
Kaiyan Zhang, Yuxin Zuo, Bingxiang He, Youbang Sun, Runze Liu, Che Jiang, Yuchen Fan, Kai Tian, Guoli Jia, Pengfei Li, et al. A survey of reinforcement learning for large reasoning models.arXiv preprint arXiv:2509.08827, 2025
-
[46]
Wenhao Zhang, Yuexiang Xie, Yuchang Sun, Yanxi Chen, Guoyin Wang, Yaliang Li, Bolin Ding, and Jingren Zhou. On-policy rl meets off-policy experts: Harmonizing supervised fine- tuning and reinforcement learning via dynamic weighting, 2026. URL https://arxiv.org/ abs/2508.11408
-
[47]
Xuqin Zhang, Quan He, Zhenrui Zheng, Zongzhang Zhang, Xu He, and Dong Li. Aster: Agentic scaling with tool-integrated extended reasoning, 2026. URL https://arxiv.org/ abs/2602.01204
-
[48]
Yabo Zhang, Yihan Zeng, Qingyun Li, Zhen Hu, Kavin Han, and Wangmeng Zuo. Tool-r1: Sample-efficient reinforcement learning for agentic tool use.arXiv preprint arXiv:2509.12867, 2025
-
[49]
Chujie Zheng, Kai Dang, Bowen Yu, Mingze Li, Huiqiang Jiang, Junrong Lin, Yuqiong Liu, Hao Lin, Chencan Wu, Feng Hu, et al. Stabilizing reinforcement learning with llms: Formulation and practices.arXiv preprint arXiv:2512.01374, 2025
-
[50]
slime: An llm post-training framework for rl scaling
Zilin Zhu, Chengxing Xie, Xin Lv, and slime Contributors. slime: An llm post-training framework for rl scaling. https://github.com/THUDM/slime, 2025. GitHub repository. Corresponding author: Xin Lv
2025
-
[51]
Let’s think step by step and output the final answer within \boxed{}
Yuxin Zuo, Kaiyan Zhang, Li Sheng, Shang Qu, Ganqu Cui, Xuekai Zhu, Haozhan Li, Yuchen Zhang, Xinwei Long, Ermo Hua, Biqing Qi, Youbang Sun, Zhiyuan Ma, Lifan Yuan, Ning Ding, and Bowen Zhou. Ttrl: Test-time reinforcement learning, 2025. URL https://arxiv. org/abs/2504.16084. 16 Appendix A Data Processing A.1 SFT Data Construction 0.3 0.4 0.5 0.6 0.7 Aver...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.