Recognition: unknown
Fine-Tuning Small Language Models for Solution-Oriented Windows Event Log Analysis
Pith reviewed 2026-05-08 09:09 UTC · model grok-4.3
The pith
Fine-tuned small language models outperform large ones in identifying Windows event log issues and suggesting fixes while using fewer resources.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By creating a large-scale synthetic Windows event log dataset that includes remediation actions via a high-performing LLM and then fine-tuning multiple small language models and large language models with the LoRA technique, the work establishes that the fine-tuned small models consistently outperform the large models in both identifying issues and providing relevant remediation, while requiring fewer computational resources, and that expert assessment confirms the dataset reflects real-world scenarios.
What carries the argument
LoRA parameter-efficient fine-tuning of small language models on a synthetic dataset of Windows event logs paired with remediation actions, scored against expert judgment.
Load-bearing premise
That a synthetic dataset generated by a high-performing LLM accurately reflects real-world Windows event log scenarios and that expert assessment provides an unbiased, reliable ground truth for evaluating remediation quality.
What would settle it
Running the fine-tuned models on a collection of real production Windows event logs from varied environments and measuring whether their issue detections and remediation suggestions match the judgments of independent human experts or actual system recovery outcomes.
Figures


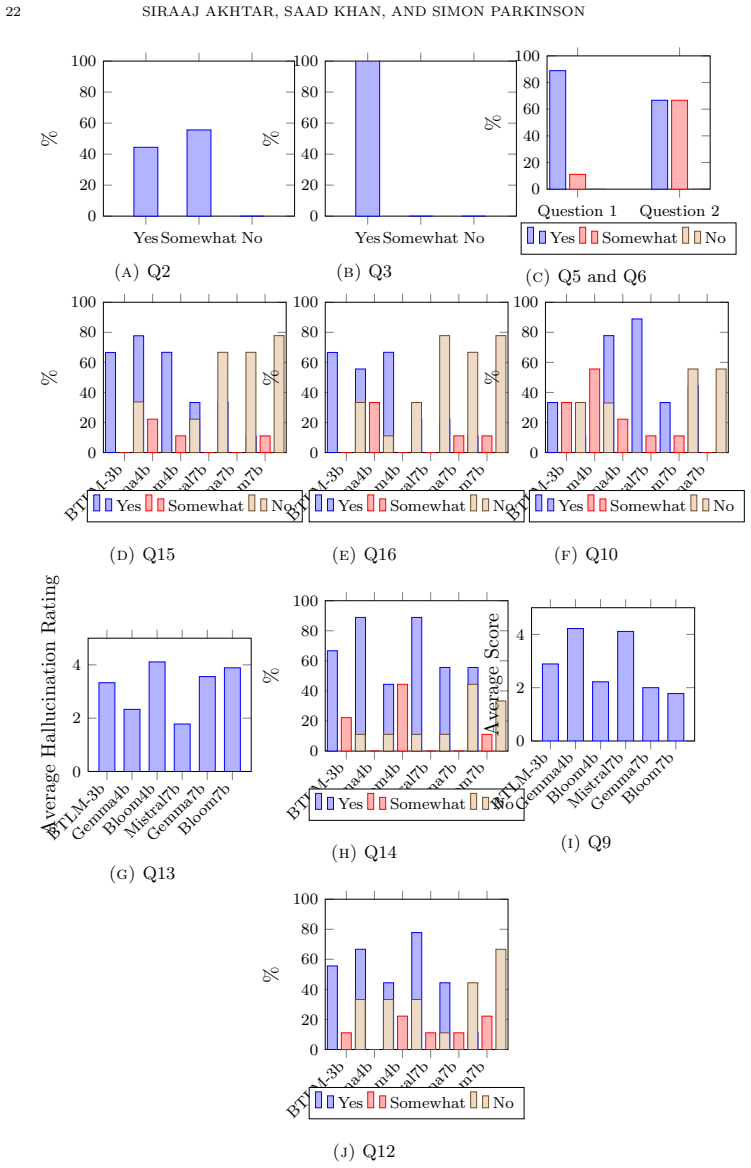




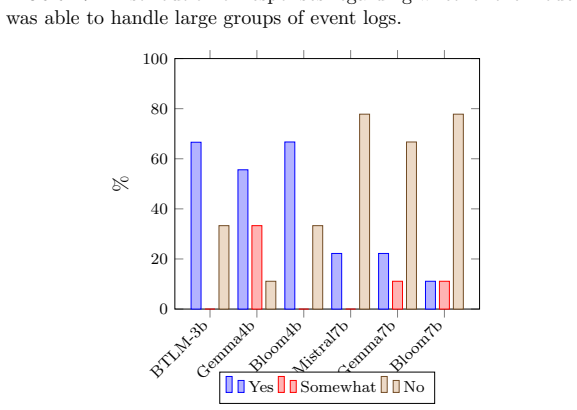
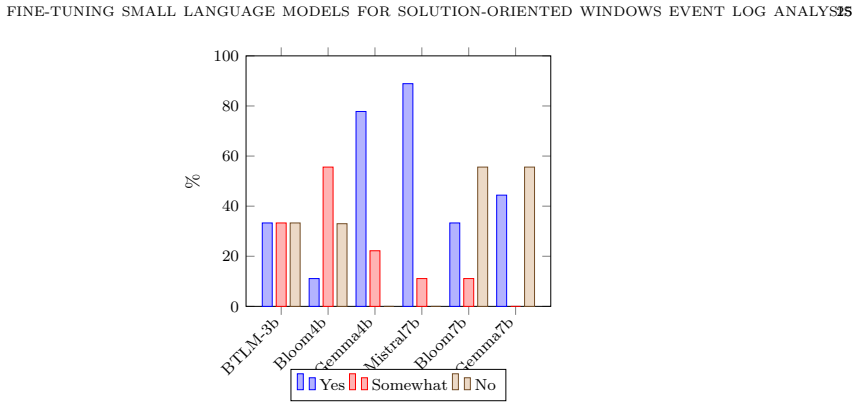
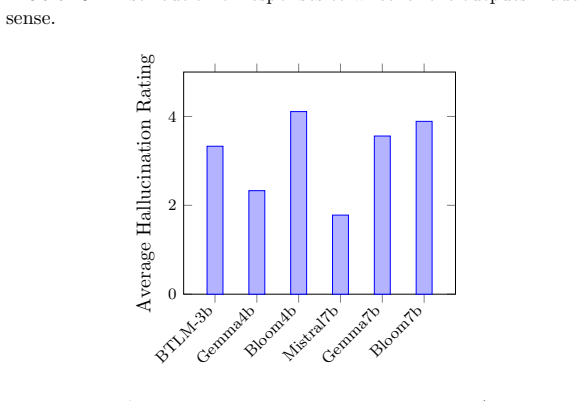
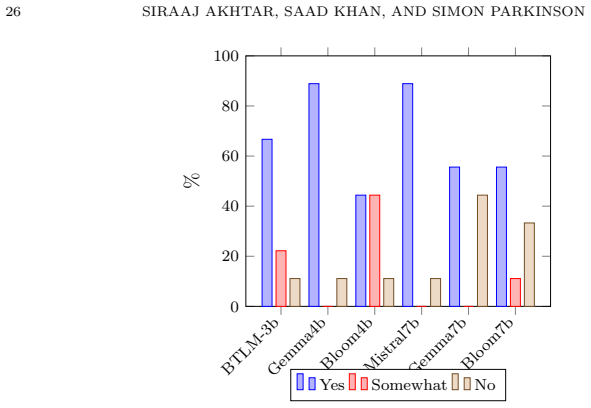
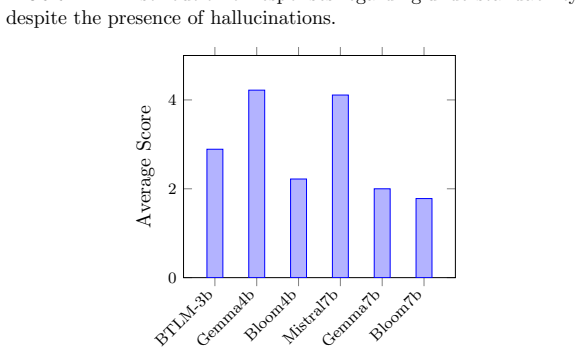


read the original abstract
Large language models (LLMs) have shown promise for event log analysis, but their high computational requirements, reliance on cloud infrastructure, and security concerns limit practical deployment. In addition, most existing approaches focus only on the identification of the problem and do not provide actionable remediation. Small language models (SLMs) present a light-weight alternative that can be fine-tuned for a specific purpose and hosted locally. This paper investigates whether SLMs, when fine-tuned for a specific task, can serve as a practical alternative for event log analysis while also generating solutions. We first create a large-scale synthetic Windows event log dataset that contains remediation actions using a high-performing LLM. We then fine-tune multiple SLMs and LLMs using the LoRA parameter-efficient fine-tuning technique and evaluate their performance by comparing with expert assessment. The results show that the dataset accurately reflects real-world scenarios and that fine-tuned SLMs consistently outperform LLMs in identifying issues and providing relevant remediation, while requiring fewer computational resources.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to generate a large-scale synthetic Windows event log dataset with remediation actions using a high-performing LLM, then fine-tune multiple SLMs and LLMs via LoRA, and demonstrate via expert assessment that the synthetic data accurately reflects real-world scenarios while fine-tuned SLMs outperform LLMs on issue identification and remediation with lower computational cost.
Significance. If the central claims were supported by rigorous validation, the work would be significant for enabling practical, local deployment of lightweight AI tools in cybersecurity event log analysis, addressing cloud dependency and security issues while extending beyond problem identification to actionable remediation. The approach of using synthetic data for domain-specific fine-tuning has potential broader applicability, but the absence of quantitative grounding currently limits its contribution.
major comments (3)
- [Abstract / Dataset generation] Abstract and dataset generation section: the claim that the synthetic dataset 'accurately reflects real-world scenarios' is load-bearing for all performance conclusions yet is unsupported by any quantitative validation such as frequency histograms of event IDs, KL divergence on message structures or severity distributions, or coverage statistics for rare error classes against real Windows event logs.
- [Evaluation] Evaluation section: no model sizes, dataset statistics (e.g., number of logs, class balance), evaluation protocol details, performance metrics, or inter-rater reliability scores for the expert assessments are reported, preventing assessment of the claim that fine-tuned SLMs 'consistently outperform LLMs' in identifying issues and providing relevant remediation.
- [Results] Results and expert assessment: reliance on expert assessment as ground truth for remediation quality lacks reported agreement metrics (e.g., Cohen's kappa or Fleiss' kappa), which is critical because any bias in the LLM-generated synthetic data could be amplified rather than mitigated by the evaluation process.
minor comments (2)
- [Abstract] The abstract would benefit from including at least one key quantitative result (e.g., accuracy delta or resource savings) to substantiate the performance claims.
- [Methods] Notation for LoRA hyperparameters and the exact SLM/LLM architectures used should be clarified with explicit parameter counts and training details for reproducibility.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. We have carefully considered each comment and made substantial revisions to the manuscript to address the concerns about validation, reporting, and evaluation rigor. Our responses are detailed below.
read point-by-point responses
-
Referee: [Abstract / Dataset generation] Abstract and dataset generation section: the claim that the synthetic dataset 'accurately reflects real-world scenarios' is load-bearing for all performance conclusions yet is unsupported by any quantitative validation such as frequency histograms of event IDs, KL divergence on message structures or severity distributions, or coverage statistics for rare error classes against real Windows event logs.
Authors: We agree that additional quantitative validation would strengthen the manuscript. In the revised version, we have included a dedicated subsection comparing the synthetic dataset to real-world Windows event logs sourced from public repositories. This includes frequency histograms for common event IDs, severity distributions, message structure analysis via KL divergence, and coverage statistics for rare error classes. These additions provide empirical support for the claim that the dataset reflects real-world scenarios, while we note limitations in replicating all proprietary or highly specific events. revision: yes
-
Referee: [Evaluation] Evaluation section: no model sizes, dataset statistics (e.g., number of logs, class balance), evaluation protocol details, performance metrics, or inter-rater reliability scores for the expert assessments are reported, preventing assessment of the claim that fine-tuned SLMs 'consistently outperform LLMs' in identifying issues and providing relevant remediation.
Authors: We appreciate this feedback on missing details. The revised manuscript now reports: model sizes and architectures for all evaluated models (e.g., 7B, 13B parameters), dataset statistics including the total number of synthetic logs generated (approximately 50,000), class balance across issue categories, a detailed evaluation protocol outlining the prompting strategy and inference settings, quantitative metrics such as accuracy for issue detection and semantic similarity scores for remediation suggestions, and inter-rater reliability using Fleiss' kappa (value reported as 0.78 indicating substantial agreement). These enhancements allow for a more transparent assessment of our results. revision: yes
-
Referee: [Results] Results and expert assessment: reliance on expert assessment as ground truth for remediation quality lacks reported agreement metrics (e.g., Cohen's kappa or Fleiss' kappa), which is critical because any bias in the LLM-generated synthetic data could be amplified rather than mitigated by the evaluation process.
Authors: We acknowledge the validity of this concern regarding potential bias propagation. We have added the inter-rater agreement metrics (Fleiss' kappa) to the Results section. Furthermore, we have expanded the discussion to address how the evaluation mitigates bias: experts evaluated remediation steps based on their technical accuracy and applicability, cross-referenced with official Microsoft documentation where possible, rather than relying solely on the synthetic context. We believe this, combined with the quantitative metrics now included, strengthens the validity of our conclusions. revision: yes
Circularity Check
No circularity; derivation relies on external expert assessment
full rationale
The paper's chain proceeds by generating a synthetic dataset via LLM, fine-tuning SLMs/LLMs with LoRA, and evaluating outputs against independent expert assessments for issue identification and remediation quality. No equations, fitted parameters, or self-citations are invoked in a load-bearing way that reduces the performance claims or the 'reflects real-world' assertion to the inputs by construction. The evaluation metric is external rather than self-referential, and the central result (SLM outperformance) is not forced by renaming or ansatz smuggling. This is a standard non-circular empirical pipeline.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Prompting llm to enforce and validate cis critical security control
Mohiuddin Ahmed, Jinpeng Wei, and Ehab Al-Shaer. Prompting llm to enforce and validate cis critical security control. InProceedings of the 29th ACM Symposium on Access Control Models and Technologies, pages 93–104, 2024
2024
-
[2]
Evaluating prompt engineering for event log parsing with large language models: A comparative study.Available at SSRN 5351870, 2025
Siraaj Akhtar, Saad Khan, and Simon Parkinson. Evaluating prompt engineering for event log parsing with large language models: A comparative study.Available at SSRN 5351870, 2025
2025
-
[3]
Llm-based event log analysis techniques: A survey.arXiv preprint arXiv:2502.00677, 2025
Siraaj Akhtar, Saad Khan, and Simon Parkinson. Llm-based event log analysis techniques: A survey.arXiv preprint arXiv:2502.00677, 2025
-
[4]
High-precision online log pars- ing with large language models
Xiaolei Chen, Jie Shi, Jia Chen, Peng Wang, and Wei Wang. High-precision online log pars- ing with large language models. InProceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering: Companion Proceedings, pages 354–355, 2024
2024
-
[5]
Emerging trends: A gentle introduction to fine-tuning.Natural Language Engineering, 27(6):763–778, 2021
Kenneth Ward Church, Zeyu Chen, and Yanjun Ma. Emerging trends: A gentle introduction to fine-tuning.Natural Language Engineering, 27(6):763–778, 2021
2021
-
[6]
Btlm-3b-8k: 7b parameter performance in a 3b parameter model.arXiv preprint arXiv:2309.11568, 2023
Nolan Dey, Daria Soboleva, Faisal Al-Khateeb, Bowen Yang, Ribhu Pathria, Hemant Khachane, Shaheer Muhammad, Robert Myers, Jacob Robert Steeves, Natalia Vassilieva, et al. Btlm-3b-8k: 7b parameter performance in a 3b parameter model.arXiv preprint arXiv:2309.11568, 2023. FINE-TUNING SMALL LANGUAGE MODELS FOR SOLUTION-ORIENTED WINDOWS EVENT LOG ANALYSIS 19
-
[7]
A real-time log correlation system for security information and event man- agement, 2021
Cl´ emence Dubuc. A real-time log correlation system for security information and event man- agement, 2021
2021
-
[8]
Bloomllm: Large language models based question generation combining supervised fine-tuning and bloom’s taxonomy
Nghia Duong-Trung, Xia Wang, and Miloˇ s Kravˇ c´ ık. Bloomllm: Large language models based question generation combining supervised fine-tuning and bloom’s taxonomy. InEuropean Conference on Technology Enhanced Learning, pages 93–98. Springer, 2024
2024
-
[9]
Metric selection and anomaly detection for cloud operations using log and metric correlation analysis.Journal of Systems and Software, 137:531–549, 2018
Mostafa Farshchi, Jean-Guy Schneider, Ingo Weber, and John Grundy. Metric selection and anomaly detection for cloud operations using log and metric correlation analysis.Journal of Systems and Software, 137:531–549, 2018
2018
-
[10]
Fine tuning: Definition and explanation in ai & machine learning.https: //www.glean.com/ai-glossary/fine-tuning, n.d
Glean AI Glossary. Fine tuning: Definition and explanation in ai & machine learning.https: //www.glean.com/ai-glossary/fine-tuning, n.d
-
[11]
Gpt powered log analysis: Enhancing soc decision making for malicious and benign security log classification
Arthur Hermann. Gpt powered log analysis: Enhancing soc decision making for malicious and benign security log classification. B.S. thesis, University of Twente, 2024
2024
-
[12]
Matthew Ho, Chen Si, Zhaoxiang Feng, Fangxu Yu, Yichi Yang, Zhijian Liu, Zhiting Hu, and Lianhui Qin. Arcmemo: Abstract reasoning composition with lifelong llm memory.arXiv preprint arXiv:2509.04439, 2025
-
[13]
Peyman Hosseini, Ignacio Castro, Iacopo Ghinassi, and Matthew Purver. Efficient solutions for an intriguing failure of llms: Long context window does not mean llms can analyze long sequences flawlessly.arXiv preprint arXiv:2408.01866, 2024
-
[14]
MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies
Shengding Hu, Yuge Tu, Xu Han, Chaoqun He, Ganqu Cui, Xiang Long, Zhi Zheng, Yewei Fang, Yuxiang Huang, Weilin Zhao, et al. Minicpm: Unveiling the potential of small language models with scalable training strategies.arXiv preprint arXiv:2404.06395, 2024
work page internal anchor Pith review arXiv 2024
-
[15]
Estimating training time for fine tuning.https://discuss
Hugging Face Community Forum. Estimating training time for fine tuning.https://discuss. huggingface.co/t/estimating-training-time-for-fine-tuning/1808, 2020
2020
-
[16]
Using llm to convert bahasa indone- sia commands into json structures for gis system api
Asril Jarin, Agung Santosa, and Yaniasih Yaniasih. Using llm to convert bahasa indone- sia commands into json structures for gis system api. In2024 International Conference on Computer, Control, Informatics and its Applications (IC3INA), pages 394–399. IEEE, 2024
2024
-
[17]
Phi-2: The surprising power of small language models.Microsoft Research Blog, 1(3):3, 2023
Mojan Javaheripi, S´ ebastien Bubeck, Marah Abdin, Jyoti Aneja, Sebastien Bubeck, Caio C´ esar Teodoro Mendes, Weizhu Chen, Allie Del Giorno, Ronen Eldan, Sivakanth Gopi, et al. Phi-2: The surprising power of small language models.Microsoft Research Blog, 1(3):3, 2023
2023
-
[18]
Benchmarking large language models for log analysis, security, and interpretation.Journal of Network and Sys- tems Management, 32(3):59, 2024
Egil Karlsen, Xiao Luo, Nur Zincir-Heywood, and Malcolm Heywood. Benchmarking large language models for log analysis, security, and interpretation.Journal of Network and Sys- tems Management, 32(3):59, 2024
2024
-
[19]
Managing threats in cloud computing: A cybersecurity risk mitigation framework.International Journal of Advanced Research in Computer Science, 15(5), 2025
Md Imran Khan. Managing threats in cloud computing: A cybersecurity risk mitigation framework.International Journal of Advanced Research in Computer Science, 15(5), 2025
2025
-
[20]
Causal connections mining within security event logs
Saad Khan and Simon Parkinson. Causal connections mining within security event logs. In Proceedings of the 9th Knowledge Capture Conference, pages 1–4, 2017
2017
-
[21]
Mining causality of network events in log data.IEEE Transactions on Network and Service Management, 15(1):53–67, 2017
Satoru Kobayashi, Kazuki Otomo, Kensuke Fukuda, and Hiroshi Esaki. Mining causality of network events in log data.IEEE Transactions on Network and Service Management, 15(1):53–67, 2017
2017
-
[22]
Xinyu Li, Yingtong Huo, Chenxi Mao, Shiwen Shan, Yuxin Su, Dan Li, and Zibin Zheng. Anomalygen: An automated semantic log sequence generation framework with llm for anom- aly detection.arXiv preprint arXiv:2504.12250, 2025
-
[23]
Feature selection for fault detection and prediction based on event log analysis.ACM SIGKDD Explorations Newsletter, 24(2):96–104, 2022
Zhong Li and Matthijs van Leeuwen. Feature selection for fault detection and prediction based on event log analysis.ACM SIGKDD Explorations Newsletter, 24(2):96–104, 2022
2022
-
[24]
Ying Fu Lim, Jiawen Zhu, and Guansong Pang. Adapting large language models for parameter-efficient log anomaly detection.arXiv preprint arXiv:2503.08045, 2025
-
[25]
Adaptivelog: An adaptive log analysis framework with the col- laboration of large and small language model.ACM Transactions on Software Engineering and Methodology, 2025
Lipeng Ma, Weidong Yang, Yixuan Li, Ben Fei, Mingjie Zhou, Shuhao Li, Sihang Jiang, Bo Xu, and Yanghua Xiao. Adaptivelog: An adaptive log analysis framework with the col- laboration of large and small language model.ACM Transactions on Software Engineering and Methodology, 2025
2025
-
[26]
Root cause prediction from log data using large language models, 2024
Aswath Mandakath Gopinath. Root cause prediction from log data using large language models, 2024
2024
-
[27]
Commandsense: Actions-objects-results prediction from natural language commands using fine-tuned gpt-3.5 turbo
Baranidharan Manibalan, J Angel Arul Jothi, and V Mary Anita Rajam. Commandsense: Actions-objects-results prediction from natural language commands using fine-tuned gpt-3.5 turbo. In2024 IEEE 3rd World Conference on Applied Intelligence and Computing (AIC), pages 75–80. IEEE, 2024
2024
-
[28]
Windows event log dataset.https://www.kaggle.com/datasets/ mehulkatara/windows-event-log, 2025
Mehul Katara. Windows event log dataset.https://www.kaggle.com/datasets/ mehulkatara/windows-event-log, 2025. 20 SIRAAJ AKHTAR, SAAD KHAN, AND SIMON PARKINSON
2025
-
[29]
How long does it typically take to train a dataset for a single pdf when fine-tuning a model with azure ai?, 2024
Microsoft Q&A. How long does it typically take to train a dataset for a single pdf when fine-tuning a model with azure ai?, 2024
2024
-
[30]
Mldataforge: Accelerating large-scale dataset preprocessing and access for multimodal foundation model training.RANLP 2025, page 175, 2025
Andrea Blasi N´ unez, Lukas Paul Achatius Galke, and Peter Schneider-Kamp. Mldataforge: Accelerating large-scale dataset preprocessing and access for multimodal foundation model training.RANLP 2025, page 175, 2025
2025
-
[31]
Anomaly detection and root cause analysis in cloud-native environments using large language models and bayesian net- works.IEEE Access, 2025
Diego Frazatto Pedroso, Lu´ ıs Almeida, Lucas Eduardo Gulka Pulcinelli, William Aki- hiro Alves Aisawa, Inˆ es Dutra, and Sarita Mazzini Bruschi. Anomaly detection and root cause analysis in cloud-native environments using large language models and bayesian net- works.IEEE Access, 2025
2025
-
[32]
Clogllm: A large language model enabled approach to cybersecurity log anomaly analysis
Hengyi Ren, Kun Lan, Zhi Sun, and Shan Liao. Clogllm: A large language model enabled approach to cybersecurity log anomaly analysis. In2024 4th International Conference on Electronic Information Engineering and Computer Communication (EIECC), pages 963–
-
[33]
Runpod.https://www.runpod.io/, 2025
Runpod. Runpod.https://www.runpod.io/, 2025
2025
-
[34]
Alexander Matt Turner, Lisa Thiergart, Gavin Leech, David Udell, Ulisse Mini, and Monte MacDi- armid
Yunfan Shao, Linyang Li, Junqi Dai, and Xipeng Qiu. Character-llm: A trainable agent for role-playing.arXiv preprint arXiv:2310.10158, 2023
-
[35]
Lora vs full fine-tuning: An illusion of equivalence
Reece Shuttleworth, Jacob Andreas, Antonio Torralba, and Pratyusha Sharma. Lora vs full fine-tuning: An illusion of equivalence.arXiv preprint arXiv:2410.21228, 2024
-
[36]
Hydralora: An asym- metric lora architecture for efficient fine-tuning.Advances in Neural Information Processing Systems, 37:9565–9584, 2024
Chunlin Tian, Zhan Shi, Zhijiang Guo, Li Li, and Cheng-Zhong Xu. Hydralora: An asym- metric lora architecture for efficient fine-tuning.Advances in Neural Information Processing Systems, 37:9565–9584, 2024
2024
-
[37]
arXiv preprint arXiv:2409.03454 , year=
Inacio Vieira, Will Allred, S´ eamus Lankford, Sheila Castilho, and Andy Way. How much data is enough data? fine-tuning large language models for in-house translation: Performance evaluation across multiple dataset sizes.arXiv preprint arXiv:2409.03454, 2024
-
[38]
Fali Wang, Zhiwei Zhang, Xianren Zhang, Zongyu Wu, Tzuhao Mo, Qiuhao Lu, Wanjing Wang, Rui Li, Junjie Xu, Xianfeng Tang, et al. A comprehensive survey of small language models in the era of large language models: Techniques, enhancements, applications, col- laboration with llms, and trustworthiness.ACM Transactions on Intelligent Systems and Technology, 2024
2024
-
[39]
Prompt engineering in consistency and reliability with the evidence-based guideline for llms
Li Wang, Xi Chen, XiangWen Deng, Hao Wen, MingKe You, WeiZhi Liu, Qi Li, and Jian Li. Prompt engineering in consistency and reliability with the evidence-based guideline for llms. npj Digital Medicine, 7(1):41, 2024
2024
-
[40]
LoRA ensembles for large language model fine-tuning.arXiv preprint arXiv:2310.00035,
Xi Wang, Laurence Aitchison, and Maja Rudolph. Lora ensembles for large language model fine-tuning.arXiv preprint arXiv:2310.00035, 2023
-
[41]
Yifeng Wang, Yuanbo Guo, and Chen Fang. An end-to-end method for advanced persistent threats reconstruction in large-scale networks based on alert and log correlation.Journal of Information Security and Applications, 71:103373, 2022
2022
-
[42]
Retrieval meets long context large language models.arXiv preprint arXiv:2310.03025, 2023
Peng Xu, Wei Ping, Xianchao Wu, Lawrence McAfee, Chen Zhu, Zihan Liu, Sandeep Sub- ramanian, Evelina Bakhturina, Mohammad Shoeybi, and Bryan Catanzaro. Retrieval meets long context large language models.arXiv preprint arXiv:2310.03025, 2023
-
[43]
De- pcomm: Graph summarization on system audit logs for attack investigation
Zhiqiang Xu, Pengcheng Fang, Changlin Liu, Xusheng Xiao, Yu Wen, and Dan Meng. De- pcomm: Graph summarization on system audit logs for attack investigation. In2022 IEEE symposium on security and privacy (SP), pages 540–557. IEEE, 2022
2022
-
[44]
Collaborate slm and llm with latent answers for event detection
Youcheng Yan, Jinshuo Liu, Donghong Ji, Jinguang Gu, Ahmed Abubakar Aliyu, Xinyan Wang, and Jeff Z Pan. Collaborate slm and llm with latent answers for event detection. Knowledge-Based Systems, 305:112684, 2024
2024
-
[45]
Raquib Bin Yousuf, Aadyant Khatri, Shengzhe Xu, Mandar Sharma, and Naren Ramakr- ishnan. Can an llm induce a graph? investigating memory drift and context length.arXiv preprint arXiv:2510.03611, 2025
-
[46]
Pengfei Yu and Heng Ji. Self information update for large language models through mitigating exposure bias.ArXiv preprint, abs/2305.18582, 2023
-
[47]
On the structural memory of llm agents.arXiv preprint arXiv:2412.15266, 2024
Ruihong Zeng, Jinyuan Fang, Siwei Liu, and Zaiqiao Meng. On the structural memory of llm agents.arXiv preprint arXiv:2412.15266, 2024
-
[48]
Hao Zhang, Dongjun Yu, Lei Zhang, Guoping Rong, Yongda Yu, Haifeng Shen, He Zhang, Dong Shao, and Hongyu Kuang. Logfilm: Fine-tuning a large language model for automated generation of log statements.arXiv preprint arXiv:2412.18835, 2024
-
[49]
Summn: A multi-stage summarization FINE-TUNING SMALL LANGUAGE MODELS FOR SOLUTION-ORIENTED WINDOWS EVENT LOG ANALYSIS 21 framework for long input dialogues and documents
Yusen Zhang, Ansong Ni, Ziming Mao, Chen Henry Wu, Chenguang Zhu, Budhaditya Deb, Ahmed Awadallah, Dragomir Radev, and Rui Zhang. Summn: A multi-stage summarization FINE-TUNING SMALL LANGUAGE MODELS FOR SOLUTION-ORIENTED WINDOWS EVENT LOG ANALYSIS 21 framework for long input dialogues and documents. InProceedings of the 60th annual meeting of the Associat...
2022
-
[50]
Llm×mapreduce: Simplified long-sequence processing using large language models
Zihan Zhou, Chong Li, Xinyi Chen, Shuo Wang, Yu Chao, Zhili Li, Haoyu Wang, Qi Shi, Zhixing Tan, Xu Han, et al. Llm×mapreduce: Simplified long-sequence processing using large language models. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 27664–27678, 2025. School of Computing and E...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.