Recognition: unknown
Is Escalation Worth It? A Decision-Theoretic Characterization of LLM Cascades
Pith reviewed 2026-05-08 12:51 UTC · model grok-4.3
The pith
LLM cascades achieve their cost-quality frontier as the pointwise envelope of pairwise two-model thresholds, with performance limited by always paying for the cheap model first.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper develops a decision-theoretic framework grounded in constrained optimization and duality. For a two-model cascade it establishes piecewise concavity of the cost-quality frontier on decreasing-benefit regions of the confidence support, with reciprocal shadow prices linking budget- and quality-constrained formulations. Given a pool of k models the frontier achievable by deterministic two-model threshold cascades is the pointwise envelope over all pairwise cascades, with switching points where the optimal pair changes. For k-model cascades first-order conditions require a single shadow price that equalizes marginal quality-per-cost across stage boundaries. Empirical validation on five
What carries the argument
The pointwise envelope over all pairwise two-model threshold cascades, derived via constrained optimization and duality, that characterizes the achievable frontier for any model pool.
If this is right
- The optimal deterministic cascade policy is always one of the pairwise threshold cascades, with the best pair selected per region.
- Full fixed k-model chains lie strictly inside or on the pairwise envelope and therefore cannot improve the frontier.
- Optimized subsequence cascades deliver no practically meaningful held-out gains beyond the pairwise envelope.
- A pre-generation router that avoids running the cheap model on queries routed directly to larger models exceeds the best cascade on four of five datasets.
- Cascade performance is limited primarily by the structural cost of always invoking the cheap model before any escalation decision rather than by a shortage of intermediate stages.
Where Pith is reading between the lines
- Designers could explore routers that choose the initial model without first paying for a cheap one, potentially shifting the frontier outward.
- The shadow-price equalization condition suggests a natural way to set dynamic per-query pricing in multi-model serving systems.
- The envelope result implies that exhaustive search over pairs is often enough; practitioners need not maintain long fixed chains.
- If confidence scores are noisy, the framework predicts the frontier will flatten earlier, making early-exit routers even more attractive.
Load-bearing premise
Deterministic threshold-based deferral using confidence scores is sufficient to trace the relevant cost-quality frontier.
What would settle it
A held-out experiment in which a learned or stochastic deferral policy produces a cost-quality curve strictly above the pairwise envelope on any of the five benchmarks.
Figures





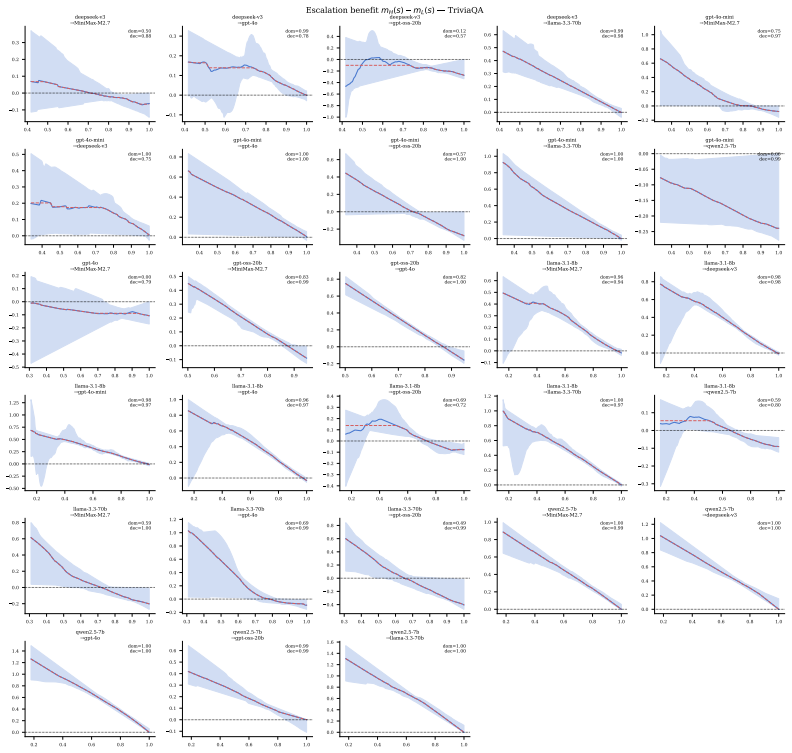
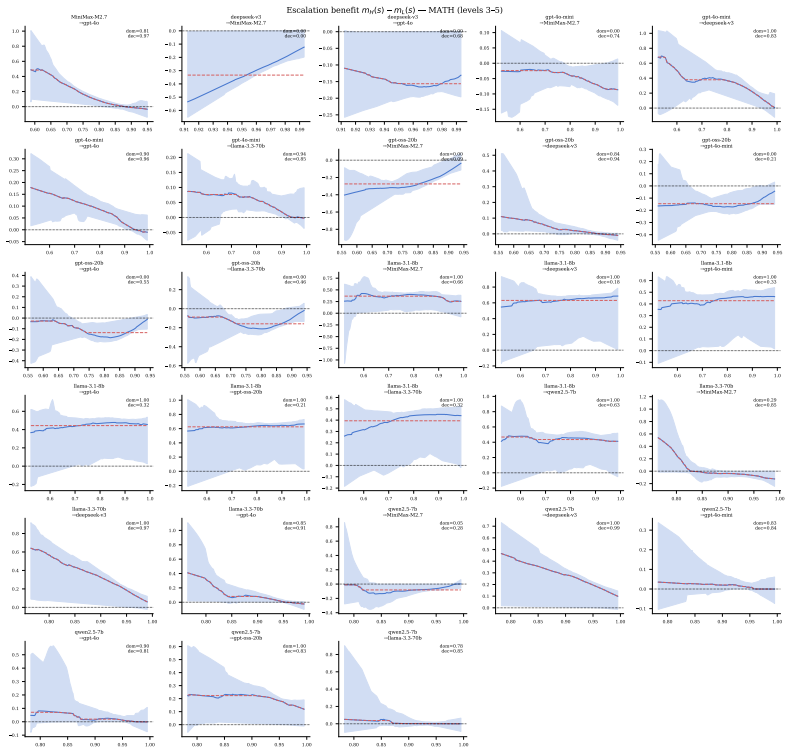




read the original abstract
Model cascades, in which a cheap LLM defers to an expensive one on low-confidence queries, are widely used to navigate the cost-quality tradeoff at deployment. Existing approaches largely treat the deferral threshold as an empirical hyperparameter, with limited guidance on the geometry of the resulting cost-quality frontier over a model pool. We develop a decision-theoretic framework grounded in constrained optimization and duality. For a two-model cascade, we establish piecewise concavity of the cost-quality frontier on decreasing-benefit regions of the confidence support, with reciprocal shadow prices linking the budget- and quality-constrained formulations. Given a pool of $k$ models, we characterize the frontier achievable by deterministic two-model threshold cascades as the pointwise envelope over $\binom{k}{2}$ pairwise cascades, with switching points where the optimal pair changes. For $k$-model cascades, we derive first-order conditions in which a single shadow price equalizes marginal quality-per-cost across stage boundaries. We validate the framework on five benchmarks (MATH, MMLU, TriviaQA, SimpleQA, LiveCodeBench) across eight models from five providers. Within the deterministic threshold-cascade class, full fixed chains underperform the pairwise envelope, and optimized subsequence cascades do not deliver practically meaningful held-out gains over it. A lightweight pre-generation router exceeds the best cascade policy on four of five datasets, mainly because it avoids the cheap model's generation cost on queries sent directly to a larger model rather than because of a stronger routing signal. These results suggest that cascade performance is limited primarily by structural cost, since cascades pay the cheap model before any escalation decision, rather than by a shortage of intermediate stages.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper develops a decision-theoretic framework for LLM cascades grounded in constrained optimization and duality. For two-model cascades it establishes piecewise concavity of the cost-quality frontier on decreasing-benefit regions together with reciprocal shadow prices between budget- and quality-constrained formulations. For a pool of k models it shows that the frontier achievable by deterministic two-model threshold cascades is the pointwise envelope over all pairwise cascades, with switching points where the optimal pair changes, and derives first-order conditions that equalize marginal quality-per-cost across stage boundaries for k-model cascades. Empirically, on five benchmarks (MATH, MMLU, TriviaQA, SimpleQA, LiveCodeBench) with eight models, full fixed chains underperform the pairwise envelope, optimized subsequence cascades yield no practically meaningful held-out gains, and a lightweight pre-generation router outperforms the best cascade policy on four datasets primarily by skipping the cheap model's generation cost.
Significance. If the characterizations hold, the work supplies a precise geometric and duality-based description of cascade frontiers that directly explains why structural cost (mandatory invocation of the cheap model before any deferral decision) dominates performance limits more than the number of intermediate stages. The empirical patterns across multiple benchmarks and model providers lend concrete support to this structural-cost interpretation and suggest that future routing research should prioritize pre-generation decisions over multi-stage escalation. The explicit scoping to the deterministic threshold-cascade class and the use of standard optimization duality are strengths that make the theoretical results falsifiable and extensible.
major comments (2)
- [§4] §4 (multi-model characterization): the claim that the k-model frontier is exactly the pointwise envelope over pairwise cascades assumes that no three-or-more-model subsequence can improve upon the best pairwise envelope at any operating point; while the first-order conditions in §5 are consistent with this, the manuscript does not provide a formal proof that the envelope is globally optimal within the deterministic-threshold class, which is load-bearing for the conclusion that 'shortage of intermediate stages' is not the limiting factor.
- [Empirical results] Empirical section (results on subsequence cascades): the statement that optimized subsequence cascades 'do not deliver practically meaningful held-out gains' is central to the structural-cost claim, yet the manuscript reports only qualitative patterns without effect sizes, confidence intervals, or statistical tests on the held-out differences; this weakens the ability to rule out that small but consistent gains exist on some datasets.
minor comments (3)
- [§3] The abstract and §3 refer to 'decreasing-benefit regions of the confidence support' without a precise definition or example of how these regions are identified from the empirical confidence distribution.
- [Figures] Figure captions and axis labels for the cost-quality frontiers should explicitly state whether the plotted points are in-sample or held-out and whether thresholds were chosen by grid search or by the derived first-order conditions.
- [Empirical results] The pre-generation router is described as 'lightweight' but the manuscript does not report its training procedure, feature set, or computational overhead relative to the cascade policies.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The recommendation for minor revision is appreciated, and we address each major comment below with proposed revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [§4] §4 (multi-model characterization): the claim that the k-model frontier is exactly the pointwise envelope over pairwise cascades assumes that no three-or-more-model subsequence can improve upon the best pairwise envelope at any operating point; while the first-order conditions in §5 are consistent with this, the manuscript does not provide a formal proof that the envelope is globally optimal within the deterministic-threshold class, which is load-bearing for the conclusion that 'shortage of intermediate stages' is not the limiting factor.
Authors: We thank the referee for this observation. Section 4 characterizes the frontier achievable by deterministic two-model threshold cascades as the pointwise envelope over all pairwise cascades, with switching points where the optimal pair changes. The first-order conditions in Section 5 for k-model cascades equalize marginal quality-per-cost across stage boundaries via a single shadow price. These conditions are consistent with the interpretation that optimal multi-stage policies effectively operate as sequences of pairwise segments. However, we agree that an explicit formal proof establishing global optimality of the pairwise envelope within the full deterministic-threshold class (i.e., that no three-or-more-model subsequence can strictly improve upon it at any operating point) is not provided. In the revised manuscript we will add a concise proof sketch in §4 or an appendix, showing that any k-stage cascade's (cost, quality) points are bounded above by the pairwise envelope using the established piecewise concavity and duality results for pairs. This will directly bolster the claim that shortage of intermediate stages is not the primary limitation. revision: yes
-
Referee: [Empirical results] Empirical section (results on subsequence cascades): the statement that optimized subsequence cascades 'do not deliver practically meaningful held-out gains' is central to the structural-cost claim, yet the manuscript reports only qualitative patterns without effect sizes, confidence intervals, or statistical tests on the held-out differences; this weakens the ability to rule out that small but consistent gains exist on some datasets.
Authors: We agree that the current empirical presentation of the subsequence-cascade results relies primarily on qualitative patterns across the five benchmarks. To strengthen this central claim, the revised manuscript will augment the empirical section with quantitative details: absolute and relative differences in accuracy and cost between optimized subsequence cascades and the pairwise envelope, bootstrap-derived 95% confidence intervals on the held-out sets, and results from paired statistical tests (e.g., Wilcoxon signed-rank or McNemar's test) to assess whether observed differences are statistically significant. These additions will allow readers to evaluate the practical magnitude of any gains more rigorously and will reinforce the structural-cost interpretation. revision: yes
Circularity Check
No significant circularity
full rationale
The paper derives its decision-theoretic results (piecewise concavity, reciprocal shadow prices, pointwise envelope over pairwise cascades, and first-order marginal conditions) directly from standard constrained optimization and duality applied to the deterministic threshold-cascade formulation. These characterizations are obtained prior to and independently of any data fitting; the empirical sections optimize thresholds per pair and validate on benchmarks but do not redefine or force the theoretical claims by construction. No self-citations are invoked as load-bearing uniqueness theorems, no ansatz is smuggled, and no fitted quantity is relabeled as a prediction. The structural-cost conclusion follows from the model structure (always invoking the cheap model first) rather than from circular reduction to the observed performance numbers.
Axiom & Free-Parameter Ledger
free parameters (1)
- deferral thresholds
axioms (1)
- domain assumption LLM confidence scores are sufficiently calibrated to support meaningful deferral decisions
Reference graph
Works this paper leans on
-
[1]
Viola, Paul and Jones, Michael J. , title =. Int. J. Comput. Vision , month = may, pages =. 2004 , issue_date =. doi:10.1023/B:VISI.0000013087.49260.fb , abstract =
-
[2]
2024 , eprint=
When Does Confidence-Based Cascade Deferral Suffice? , author=. 2024 , eprint=
2024
-
[3]
2024 , eprint=
Efficient Contextual LLM Cascades through Budget-Constrained Policy Learning , author=. 2024 , eprint=
2024
-
[4]
Kusner and Kilian Q
Zhixiang (Eddie) Xu and Matt J. Kusner and Kilian Q. Weinberger and Minmin Chen and Olivier Chapelle , title =. Journal of Machine Learning Research , year =
-
[5]
Proceedings of the 37th International Conference on Machine Learning , pages =
Consistent Estimators for Learning to Defer to an Expert , author =. Proceedings of the 37th International Conference on Machine Learning , pages =. 2020 , editor =
2020
-
[6]
Deb, K. and Pratap, A. and Agarwal, S. and Meyarivan, T. , title =. Trans. Evol. Comp , month = apr, pages =. 2002 , issue_date =. doi:10.1109/4235.996017 , abstract =
-
[7]
2021 , eprint=
Measuring Massive Multitask Language Understanding , author=. 2021 , eprint=
2021
-
[8]
2021 , eprint=
Measuring Mathematical Problem Solving With the MATH Dataset , author=. 2021 , eprint=
2021
-
[9]
2017 , eprint=
TriviaQA: A Large Scale Distantly Supervised Challenge Dataset for Reading Comprehension , author=. 2017 , eprint=
2017
-
[10]
2024 , eprint=
Measuring short-form factuality in large language models , author=. 2024 , eprint=
2024
-
[11]
2024 , eprint=
Language Model Cascades: Token-level uncertainty and beyond , author=. 2024 , eprint=
2024
-
[12]
2023 , eprint=
FrugalGPT: How to Use Large Language Models While Reducing Cost and Improving Performance , author=. 2023 , eprint=
2023
-
[13]
2025 , eprint=
C3PO: Optimized Large Language Model Cascades with Probabilistic Cost Constraints for Reasoning , author=. 2025 , eprint=
2025
-
[14]
2025 , eprint=
RouteLLM: Learning to Route LLMs with Preference Data , author=. 2025 , eprint=
2025
-
[15]
2026 , eprint=
Robust Batch-Level Query Routing for Large Language Models under Cost and Capacity Constraints , author=. 2026 , eprint=
2026
-
[16]
2025 , eprint=
OmniRouter: Budget and Performance Controllable Multi-LLM Routing , author=. 2025 , eprint=
2025
-
[17]
2026 , eprint=
Knowledge Access Beats Model Size: Memory Augmented Routing for Persistent AI Agents , author=. 2026 , eprint=
2026
-
[18]
2026 , eprint=
Pay for Hints, Not Answers: LLM Shepherding for Cost-Efficient Inference , author=. 2026 , eprint=
2026
-
[19]
2025 , eprint=
Privacy-preserved LLM Cascade via CoT-enhanced Policy Learning , author=. 2025 , eprint=
2025
-
[20]
2024 , eprint=
Large Language Model Cascades with Mixture of Thoughts Representations for Cost-efficient Reasoning , author=. 2024 , eprint=
2024
-
[21]
2026 , eprint=
Dynamic Model Routing and Cascading for Efficient LLM Inference: A Survey , author=. 2026 , eprint=
2026
-
[22]
2025 , eprint=
A Unified Approach to Routing and Cascading for LLMs , author=. 2025 , eprint=
2025
-
[23]
2025 , eprint=
BEST-Route: Adaptive LLM Routing with Test-Time Optimal Compute , author=. 2025 , eprint=
2025
-
[24]
2025 , eprint=
When to Reason: Semantic Router for vLLM , author=. 2025 , eprint=
2025
-
[25]
2024 , eprint=
EmbedLLM: Learning Compact Representations of Large Language Models , author=. 2024 , eprint=
2024
-
[26]
2025 , eprint=
GraphRouter: A Graph-based Router for LLM Selections , author=. 2025 , eprint=
2025
-
[27]
2025 , eprint=
CP-Router: An Uncertainty-Aware Router Between LLM and LRM , author=. 2025 , eprint=
2025
-
[28]
2025 , eprint=
AutoMix: Automatically Mixing Language Models , author=. 2025 , eprint=
2025
-
[29]
Portfolio Selection , urldate =
Harry Markowitz , journal =. Portfolio Selection , urldate =
-
[30]
Journal of Machine Learning Research , year =
Dylan Bouchard and Mohit Singh Chauhan and David Skarbrevik and Ho-Kyeong Ra and Viren Bajaj and Zeya Ahmad , title =. Journal of Machine Learning Research , year =
-
[31]
2025 , eprint=
Atomic Calibration of LLMs in Long-Form Generations , author=. 2025 , eprint=
2025
-
[32]
2026 , eprint=
Functional Entropy: Predicting Functional Correctness in LLM-Generated Code with Uncertainty Quantification , author=. 2026 , eprint=
2026
-
[33]
Scikit-learn: Machine Learning in Python , journal =
Fabian Pedregosa and Ga. Scikit-learn: Machine Learning in Python , journal =. 2011 , volume =
2011
-
[34]
2024 , eprint=
Calibration and Correctness of Language Models for Code , author=. 2024 , eprint=
2024
-
[35]
2025 , eprint=
UNCERTAINTY-LINE: Length-Invariant Estimation of Uncertainty for Large Language Models , author=. 2025 , eprint=
2025
-
[36]
2025 , eprint=
Reconsidering LLM Uncertainty Estimation Methods in the Wild , author=. 2025 , eprint=
2025
-
[37]
2025 , eprint=
Assessing Correctness in LLM-Based Code Generation via Uncertainty Estimation , author=. 2025 , eprint=
2025
-
[38]
2020 , eprint=
CodeBLEU: a Method for Automatic Evaluation of Code Synthesis , author=. 2020 , eprint=
2020
-
[39]
2023 , eprint=
Just Ask for Calibration: Strategies for Eliciting Calibrated Confidence Scores from Language Models Fine-Tuned with Human Feedback , author=. 2023 , eprint=
2023
-
[40]
2025 , eprint=
NaturalReasoning: Reasoning in the Wild with 2.8M Challenging Questions , author=. 2025 , eprint=
2025
-
[41]
2019 , eprint=
DROP: A Reading Comprehension Benchmark Requiring Discrete Reasoning Over Paragraphs , author=. 2019 , eprint=
2019
-
[42]
2023 , eprint=
FActScore: Fine-grained Atomic Evaluation of Factual Precision in Long Form Text Generation , author=. 2023 , eprint=
2023
-
[43]
2018 , eprint=
HotpotQA: A Dataset for Diverse, Explainable Multi-hop Question Answering , author=. 2018 , eprint=
2018
-
[44]
2026 , version =
Open R1 , author =. 2026 , version =
2026
-
[45]
2024 , eprint=
LiveCodeBench: Holistic and Contamination Free Evaluation of Large Language Models for Code , author=. 2024 , eprint=
2024
-
[46]
Uncertainty Quantification for Language Models: A Suite of Black-Box, White-Box,
Dylan Bouchard and Mohit Singh Chauhan , journal=. Uncertainty Quantification for Language Models: A Suite of Black-Box, White-Box,. 2025 , url=
2025
-
[47]
2026 , eprint=
Fine-Grained Uncertainty Quantification for Long-Form Language Model Outputs: A Comparative Study , author=. 2026 , eprint=
2026
-
[48]
2025 , eprint=
EAGER: Entropy-Aware GEneRation for Adaptive Inference-Time Scaling , author=. 2025 , eprint=
2025
-
[49]
Benchmarking Uncertainty Quantification Methods for Large Language Models with LM -Polygraph
Vashurin, Roman and Fadeeva, Ekaterina and Vazhentsev, Artem and Rvanova, Lyudmila and Vasilev, Daniil and Tsvigun, Akim and Petrakov, Sergey and Xing, Rui and Sadallah, Abdelrahman and Grishchenkov, Kirill and Panchenko, Alexander and Baldwin, Timothy and Nakov, Preslav and Panov, Maxim and Shelmanov, Artem , year=. Benchmarking Uncertainty Quantificatio...
-
[50]
2024 , eprint=
RED-CT: A Systems Design Methodology for Using LLM-labeled Data to Train and Deploy Edge Classifiers for Computational Social Science , author=. 2024 , eprint=
2024
-
[51]
2025 , eprint=
Uncertainty Quantification for LLMs through Minimum Bayes Risk: Bridging Confidence and Consistency , author=. 2025 , eprint=
2025
-
[52]
Akiba, Takuya and Sano, Shotaro and Yanase, Toshihiko and Ohta, Takeru and Koyama, Masanori , booktitle =. doi:10.1145/3292500.3330701 , pages =
-
[53]
OpenAI.com , author=
-
[54]
Google Cloud , author=
-
[55]
2025 , eprint=
UQLM: A Python Package for Uncertainty Quantification in Large Language Models , author=. 2025 , eprint=
2025
-
[56]
OpenAI.com , author=
Introducing GPT-4.5 | OpenAI , url=. OpenAI.com , author=
-
[57]
2024 , eprint=
Graph-based Uncertainty Metrics for Long-form Language Model Outputs , author=. 2024 , eprint=
2024
-
[58]
Hughes, Simon and Bae, Minseok and Li, Miaoran , month = nov, title =
-
[59]
2024 , eprint=
DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models , author=. 2024 , eprint=
2024
-
[60]
2024 , eprint=
A Survey of Uncertainty Estimation in LLMs: Theory Meets Practice , author=. 2024 , eprint=
2024
-
[61]
2024 , eprint=
A Survey on Uncertainty Quantification of Large Language Models: Taxonomy, Open Research Challenges, and Future Directions , author=. 2024 , eprint=
2024
-
[62]
2023 , eprint=
A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions , author=. 2023 , eprint=
2023
-
[63]
2024 , eprint=
A Comprehensive Survey of Hallucination Mitigation Techniques in Large Language Models , author=. 2024 , eprint=
2024
-
[64]
2025 , eprint=
A Survey on LLM-as-a-Judge , author=. 2025 , eprint=
2025
-
[65]
2023 , eprint=
Quantifying Uncertainty in Answers from any Language Model and Enhancing their Trustworthiness , author=. 2023 , eprint=
2023
-
[66]
Farquhar, Sebastian and Kossen, Jannik and Kuhn, Lorenz and Gal, Yarin , title=. Nature , year=. doi:10.1038/s41586-024-07421-0 , url=
-
[67]
2024 , eprint=
LUQ: Long-text Uncertainty Quantification for LLMs , author=. 2024 , eprint=
2024
-
[68]
2023 , eprint=
SelfCheckGPT: Zero-Resource Black-Box Hallucination Detection for Generative Large Language Models , author=. 2023 , eprint=
2023
-
[69]
2024 , eprint=
Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs , author=. 2024 , eprint=
2024
-
[70]
2024 , eprint=
Generating with Confidence: Uncertainty Quantification for Black-box Large Language Models , author=. 2024 , eprint=
2024
-
[71]
2023 , eprint=
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation , author=. 2023 , eprint=
2023
-
[72]
2024 , eprint=
Semantic Density: Uncertainty Quantification for Large Language Models through Confidence Measurement in Semantic Space , author=. 2024 , eprint=
2024
-
[73]
2023 , eprint=
Selectively Answering Ambiguous Questions , author=. 2023 , eprint=
2023
-
[74]
2024 , eprint=
CLUE: Concept-Level Uncertainty Estimation for Large Language Models , author=. 2024 , eprint=
2024
-
[75]
ROUGE : A Package for Automatic Evaluation of Summaries
Lin, Chin-Yew. ROUGE : A Package for Automatic Evaluation of Summaries. Text Summarization Branches Out. 2004
2004
-
[76]
Proceedings of the 40th Annual Meeting on Association for Computational Linguistics , pages =
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing , title =. Proceedings of the 40th Annual Meeting on Association for Computational Linguistics , pages =. 2002 , publisher =. doi:10.3115/1073083.1073135 , abstract =
-
[77]
, booktitle=
Qurashi, Abdul Wahab and Holmes, Violeta and Johnson, Anju P. , booktitle=. Document Processing: Methods for Semantic Text Similarity Analysis , year=
-
[78]
METEOR : An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments
Banerjee, Satanjeev and Lavie, Alon. METEOR : An Automatic Metric for MT Evaluation with Improved Correlation with Human Judgments. Proceedings of the ACL Workshop on Intrinsic and Extrinsic Evaluation Measures for Machine Translation and/or Summarization. 2005
2005
-
[79]
2019 , eprint=
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks , author=. 2019 , eprint=
2019
-
[80]
2020 , eprint=
BERTScore: Evaluating Text Generation with BERT , author=. 2020 , eprint=
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.