Recognition: unknown
Lecture Notes on Statistical Physics and Neural Networks
Pith reviewed 2026-05-08 03:21 UTC · model grok-4.3
The pith
Statistical physics taught through probability theory reveals that neural networks share energy functions with spin-glass models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
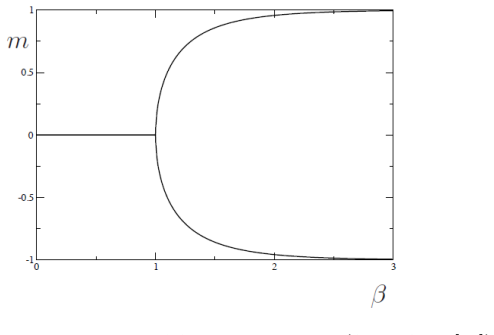
By formulating statistical mechanics purely in terms of probability distributions over finite configuration spaces, the notes make phase transitions and renormalization group transformations accessible through marginalization and limits. This framework unifies spin-glass models with Hopfield networks and Boltzmann machines via a common energy function, and interprets the training of restricted Boltzmann machines as a renormalization procedure that eliminates hidden degrees of freedom. The notes extend this perspective to multilayer deep networks whose structure builds on these ideas.
What carries the argument
The energy function shared by spin-glass models, Hopfield networks, and Boltzmann machines, together with the marginalization over hidden neurons that parallels renormalization group coarse-graining.
If this is right
- Readers without physics training can define and identify phase transitions using only finite probability spaces.
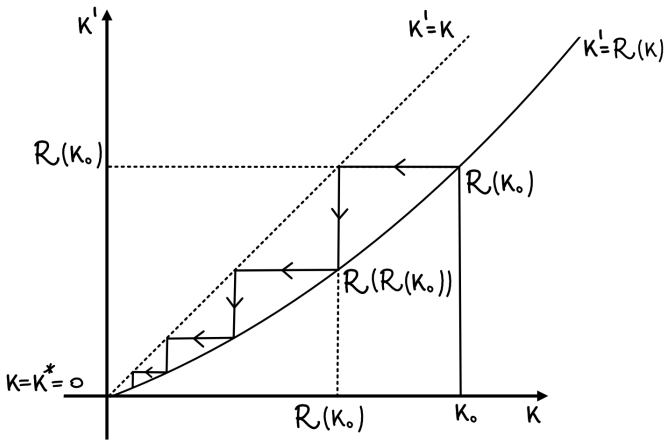
- The contrastive divergence learning in restricted Boltzmann machines corresponds to integrating out variables as in renormalization.
- Deep learning architectures with many hidden layers extend the restricted Boltzmann machine structure.
- Large language models can be viewed through the lens of these statistical mechanics connections.
Where Pith is reading between the lines
- Training dynamics in deep networks may display critical behavior similar to phase transitions.
- This view suggests analyzing optimization in neural networks using thermodynamic potentials.
- Extensions could include applying renormalization ideas to other generative models beyond Boltzmann machines.
Load-bearing premise
That phase transitions and the renormalization group can be grasped by readers with no physics background when presented solely as properties of probability distributions on finite configuration spaces.
What would settle it
If integrating out the hidden neurons in a restricted Boltzmann machine does not yield an effective energy function resembling a coarse-grained spin-glass model, the claimed parallel to the renormalization group would not hold.
Figures




read the original abstract
These lecture notes introduce some topics of classical statistical physics, particularly those that are relevant for neural networks and deep learning. Statistical physics is treated as a branch of probability theory or statistics, with the goal of making concepts such as phase transitions and the renormalization group accessible to readers without prior knowledge of physics. We introduce the Boltzmann-Gibbs distribution and the thermodynamic potentials on a finite configuration space, notably for Ising spins and spin-glass models on a lattice, and then define phase transitions as discontinuities that arise in the limit that the number of lattice points goes to infinity. We further introduce Hopfield networks and Boltzmann machines, which are governed by the same energy function as spin-glass models, and discuss the learning algorithm for restricted Boltzmann machines. In this algorithm hidden neurons are integrated out as in the renormalization group. Finally, modern deep learning is introduced, whose early developments were in part motivated by restricted Boltzmann machines in that they carry many layers of hidden neurons. A description of large language models is given.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. These lecture notes treat classical statistical physics as probability theory on finite configuration spaces. They introduce the Boltzmann-Gibbs distribution and thermodynamic potentials for Ising spins and spin-glass models on a lattice, define phase transitions via discontinuities in the thermodynamic limit, present Hopfield networks and Boltzmann machines sharing the same energy functions as spin glasses, discuss the RBM learning algorithm in which hidden units are integrated out in a manner analogous to the renormalization group, and conclude with an introduction to modern deep learning and large language models motivated in part by multilayer RBMs.
Significance. If the derivations and analogies hold without gaps, the notes could usefully bridge statistical physics and machine learning for readers whose background is primarily in probability and statistics. The explicit mapping of spin-glass energy functions onto Hopfield and Boltzmann machine models, together with the pedagogical use of the renormalization-group parallel for marginalization in RBM training, supplies concrete links that are often left implicit in the literature.
Simulated Author's Rebuttal
We thank the referee for their positive and encouraging report, which accurately summarizes the scope and pedagogical intent of the lecture notes. We are pleased that the referee finds the explicit mappings between spin-glass models and neural network architectures, as well as the renormalization-group analogy for RBM training, to be useful bridges between the fields.
Circularity Check
No significant circularity; standard recasting of known models
full rationale
The lecture notes present classical statistical physics (Boltzmann-Gibbs measures, Ising models, spin glasses, phase transitions via thermodynamic limit) as probability on finite configuration spaces, then apply the identical formalism to Hopfield networks and Boltzmann machines using their standard energy functions. The RBM learning step is described via exact marginalization of hidden units, presented only as a pedagogical parallel to renormalization-group integration rather than a new theorem. No equations derive novel predictions from fitted parameters, no uniqueness theorems are invoked via self-citation, and no ansatz is smuggled in; all steps follow textbook constructions without reduction to the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Axioms of probability theory on finite spaces
Reference graph
Works this paper leans on
-
[1]
https://www.nobelprize.org/prizes/physics/2024/summary/
2024
-
[2]
An exact mapping between the Variational Renormalization Group and Deep Learning
P. Mehta and D. J. Schwab, “An exact mapping between the Variational Renormalization Group and Deep Learning,” [arXiv:1410.3831 [stat.ML]]
-
[3]
Deep Learning and the Information Bottleneck Principle
N. Tishby and N. Zaslavsky, “Deep learning and the information bottleneck principle,” [arXiv:1503.02406 [cs.LG]]
-
[4]
Mutual information, neural networks and the renormal- ization group,
M. Koch-Janusz and Z. Ringel, “Mutual information, neural networks and the renormal- ization group,” Nature Physics 14.6 (2018): 578-582
2018
-
[5]
Neural network renormalization group,
L. Shuo-Hui and L. Wang, “Neural network renormalization group,” Physical Review Let- ters 121.26 (2018): 260601
2018
-
[6]
Scale-invariant Feature Extraction of Neural Network and Renormalization Group Flow,
S. Iso, S. Shiba and S. Yokoo, “Scale-invariant Feature Extraction of Neural Network and Renormalization Group Flow,” Phys. Rev. E97, no.5, 053304 (2018) [arXiv:1801.07172 [hep-th]]. 52
-
[7]
Is Deep Learning a Renormalization Group Flow?,
E. d. Koch, R. de Mello Koch and L. Cheng, “Is Deep Learning a Renormalization Group Flow?,” [arXiv:1906.05212 [cs.LG]]
-
[8]
J. Halverson, A. Maiti and K. Stoner, “Neural Networks and Quantum Field Theory,” Mach. Learn. Sci. Tech.2, no.3, 035002 (2021) [arXiv:2008.08601 [cs.LG]]
-
[9]
J. Erdmenger, K. T. Grosvenor and R. Jefferson, “Towards quantifying information flows: relative entropy in deep neural networks and the renormalization group,” SciPost Phys. 12, no.1, 041 (2022) [arXiv:2107.06898 [hep-th]]
-
[10]
Renormalization group flow as optimal transport,
J. Cotler and S. Rezchikov, “Renormalization group flow as optimal transport,” Phys. Rev. D108, no.2, 025003 (2023) [arXiv:2202.11737 [hep-th]]
-
[11]
The Inverse of Exact Renormalization Group Flows as Statistical Inference,
D. S. Berman and M. S. Klinger, “The Inverse of Exact Renormalization Group Flows as Statistical Inference,” Entropy26, no.5, 389 (2024) [arXiv:2212.11379 [hep-th]]
-
[12]
The principles of deep learning theory,
D. Roberts, S. Yaida and B. Hanin, “The principles of deep learning theory,” Vol. 46. Cam- bridge, MA, USA: Cambridge University Press, 2022
2022
-
[13]
D. S. Berman, M. S. Klinger and A. G. Stapleton, “Bayesian renormalization,” Mach. Learn. Sci. Tech.4, no.4, 045011 (2023) [arXiv:2305.10491 [hep-th]]
-
[14]
NCoder—a quantum field theory ap- proach to encoding data,
D. S. Berman, M. S. Klinger and A. G. Stapleton, “NCoder—a quantum field theory ap- proach to encoding data,” Mach. Learn. Sci. Tech.6, no.2, 025059 (2025) [arXiv:2402.00944 [hep-th]]
-
[15]
Phase Transitions in Large Language Models and theO(N) Model,
Y. Sun and B. Haghighat, “Phase Transitions in Large Language Models and theO(N) Model,” [arXiv:2501.16241 [cs.LG]]
-
[16]
Statistical Mechanics,
F. Schwabl, “Statistical Mechanics,” Springer Berlin Heidelberg, 2006
2006
-
[17]
Information, Physics, and Computation,
M. Mezard and A. Montanari, “Information, Physics, and Computation,” Oxford Univer- sity Press, 2009
2009
-
[18]
Quantum electrodynamics at small distances,
M. Gell-Mann and F. E. Low, “Quantum electrodynamics at small distances,” Phys. Rev. 95, 1300-1312 (1954)
1954
-
[19]
Non-Lagrangian models of current algebra,
K. G. Wilson, “Non-Lagrangian models of current algebra,” Phys. Rev.179, 1499-1512 (1969)
1969
-
[20]
Scaling laws for Ising models near T(c),
L. P. Kadanoff, “Scaling laws for Ising models near T(c),” Physics Physique Fizika2, 263-272 (1966)
1966
-
[21]
The renormalization group: Critical phenomena and the Kondo problem,
K. Wilson, “The renormalization group: Critical phenomena and the Kondo problem,” Reviews of Modern Physics 47.4 (1975): 773
1975
-
[22]
The renormalization group and critical phenomena,
K. Wilson, “The renormalization group and critical phenomena,” Reviews of Modern Physics 55.3 (1983): 583
1983
-
[23]
Lectures on phase transitions and the renormalization group,
N. Goldenfeld, “Lectures on phase transitions and the renormalization group,” CRC Press, 2018. 53
2018
-
[24]
Neural networks and physical systems with emergent collective computa- tional abilities,
J. J. Hopfield, “Neural networks and physical systems with emergent collective computa- tional abilities,” Proceedings of the National Academy of Sciences 79.8 (1982): 2554-2558
1982
-
[25]
A learning algorithm for Boltzmann machines,
D. H. Ackley, G. E. Hinton, and T. J. Sejnowski, “A learning algorithm for Boltzmann machines,” Cognitive Science 9.1 (1985): 147-169
1985
-
[26]
Nobel lecture: Boltzmann machines,
G. Hinton, “Nobel lecture: Boltzmann machines,” Reviews of Modern Physics 97.3 (2025): 030502
2025
-
[27]
Learning representations by back-propagating errors,
D. Rumelhart, G. Hinton, and R. Williams, “Learning representations by back-propagating errors,” Nature 323.6088 (1986): 533-536
1986
-
[28]
A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser and I. Polosukhin, “Attention is all you need,” [arXiv:1706.03762 [cs.CL]], Advances in Neural Information Processing Systems 30 (2017)
work page internal anchor Pith review arXiv 2017
-
[29]
Scaling Laws for Neural Language Models
J. Kaplan, S. McCandlish, T. Henighan, T. B. Brown, B. Chess, R. Child, S. Gray, A. Rad- ford, J. Wu and D. Amodei, “Scaling Laws for Neural Language Models,” [arXiv:2001.08361 [cs.LG]]
work page internal anchor Pith review arXiv 2001
-
[30]
Test of universality in the Ising spin glass using high temperature graph expansion,
Daboul, Daniel, Iksoo Chang, and Amnon Aharony, “Test of universality in the Ising spin glass using high temperature graph expansion,” The European Physical Journal B- Condensed Matter and Complex Systems 41.2 (2004): 231-254
2004
-
[31]
Statistical mechanics of lattice systems: a concrete mathematical introduction,
Friedli, Sacha, and Yvan Velenik, “Statistical mechanics of lattice systems: a concrete mathematical introduction,” Cambridge University Press, 2017
2017
-
[32]
The Yang–Mills Millennium problem,
M. R. Douglas, “The Yang–Mills Millennium problem,” Nature Rev. Phys.8, no.2, 86-97 (2026) doi:10.1038/s42254-025-00909-2
-
[33]
Lectures on Computation,
R. Feynman, “Lectures on Computation,” CRC Press, 2018
2018
-
[34]
L. Onsager, “Crystal statistics. 1. A Two-dimensional model with an order disorder tran- sition,” Phys. Rev.65, 117-149 (1944) doi:10.1103/PhysRev.65.117
-
[35]
Perceptrons: An Introduction to Computational Geometry,
M. Minsky and S. Papert, “Perceptrons: An Introduction to Computational Geometry,” The MIT Press, Cambridge MA (1988)
1988
-
[36]
https://www.quantamagazine.org/the-strange-physics-that-gave-birth-to-ai-20250430/
-
[37]
Theoretical Neuroscience: Computational and Mathematical Modeling of Neural Systems,
P. Dayan and L. F. Abbott, “Theoretical Neuroscience: Computational and Mathematical Modeling of Neural Systems,” MIT Press (2005)
2005
-
[38]
Neuronal dynamics: From single neurons to networks and models of cognition,
W. Gerstner, W. M. Kistler, R. Naud, and L. Paninski, “Neuronal dynamics: From single neurons to networks and models of cognition,” Cambridge University Press (2014)
2014
-
[39]
Neural Networks and Deep Learning,
M. Nielsen, “Neural Networks and Deep Learning,” Vol. 25. San Francisco, CA, USA: Determination press, (2015)
2015
-
[40]
G. Cybenko, “Approximation by superpositions of a sigmoidal function,”Mathematics of Control, Signals and Systems2(1989), 303–314. doi:10.1007/BF02551274 54
-
[41]
Mul- tilayer feedforward networks are universal approximators
K. Hornik, M. Stinchcombe, and H. White, “Multilayer feedforward networks are uni- versal approximators,”Neural Networks2(1989), no. 5, 359–366. doi:10.1016/0893- 6080(89)90020-8
-
[42]
M. R. Douglas, “Large Language Models,” [arXiv:2307.05782 [cs.CL]]
-
[43]
arXiv preprint arXiv:2207.09238 , year=
Phuong, Mary, and Marcus Hutter, “Formal algorithms for transformers,” [arXiv:2207.09238]
-
[44]
Neural Machine Translation by Jointly Learning to Align and Translate
D. Bahdanau, K. Cho and Y. Bengio, “Neural Machine Translation by Jointly Learning to Align and Translate,” [arXiv:1409.0473 [cs.CL]]
work page internal anchor Pith review arXiv
-
[45]
A logical calculus of the ideas immanent in nervous activity,
W. S. McCulloch and W. Pitts, “A logical calculus of the ideas immanent in nervous activity,” Bull. Math. Biol.5, no.4, 115-133 (1943)
1943
-
[46]
Imagenet classification with deep convolu- tional neural networks,
A. Krizhevsky, I. Sutskever, and G. Hinton, “Imagenet classification with deep convolu- tional neural networks,” Advances in Neural Information Processing Systems 25 (2012)
2012
-
[47]
Probability: Elements of the Mathematical Theory,
C. R. Heathcote, “Probability: Elements of the Mathematical Theory,” Dover Publications (1971)
1971
-
[48]
Reconciling modern machine-learning practice and the classical bias– variance trade-off,
M. Belkin, et al., “Reconciling modern machine-learning practice and the classical bias– variance trade-off,” [arXiv:1812.11118 [stat.ML]], Proceedings of the National Academy of Sciences 116.32 (2019). 55
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.