Recognition: unknown
GATHER: Convergence-Centric Hyper-Entity Retrieval for Zero-Shot Cell-Type Annotation
Pith reviewed 2026-05-08 10:09 UTC · model grok-4.3
The pith
A graph method that locates nodes reachable from many genes at once annotates cell types from expression sets using only one LLM call.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
GATHER identifies topological convergence nodes in a biological knowledge graph as high-information hyper-entities for queries consisting of gene sets. By performing global multi-source traversal and scoring nodes and paths without any LLM involvement during retrieval, it supplies compact evidence of gene synergy that a single downstream LLM call can use to determine cell-type labels, outperforming path-expansion baselines on the Immune and Lung datasets.
What carries the argument
Convergence nodes found by global multi-source traversal from all input genes, scored by node- and path-importance to select evidence without LLM reasoning.
Load-bearing premise
The self-constructed cell-centric knowledge graph contains sufficiently complete and accurate relations so that convergence nodes reliably capture gene-set synergy for cell-type labels.
What would settle it
Re-running the experiments after removing or randomizing relations tied to specific cell types in the knowledge graph and checking whether exact-match accuracy falls to the level of the baselines.
Figures

read the original abstract
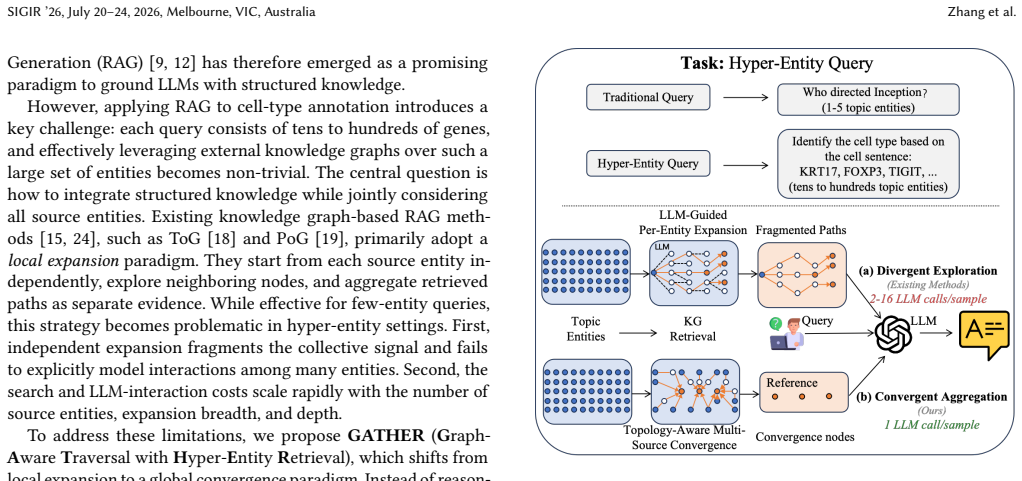
Zero-shot single-cell cell-type annotation aims to determine a cell's type from a given set of expressed genes without any training. Existing knowledge-graph-based RAG approaches retrieve evidence by expanding from source entities and relying on iterative LLM reasoning. However, in this setting each query contains tens to hundreds of genes, where no single gene is decisive and the label emerges only from their collective co-occurrence. Such hyper-entity queries fundamentally challenge local, entity-wise exploration strategies, which reason from individual genes, leading to poor scalability and substantial LLM cost. We propose GATHER (Graph-Aware Traversal with Hyper-Entity Retrieval), a convergence-centric retriever tailored to hyper-entity queries. It performs global multi-source graph traversal and identifies topological convergence points -- nodes jointly reachable from many input genes. These convergence nodes act as high-information hyper-entities that capture entity synergy. By incorporating node- and path-importance scoring, GATHER selects informative evidence entirely without LLM involvement during retrieval. Instantiated on a self-constructed cell-centric biological knowledge graph (VCKG), GATHER outperforms strong KG-RAG baselines (ToG, ToG-2, RoG, PoG) on two datasets (Immune and Lung), achieving the highest exact-match accuracy (27.45% and 59.64%) with only a single LLM call per sample, compared to 2--61 calls for KG-RAG baselines. Our results demonstrate that convergence nodes compress multi-entity signals into compact, high-information evidence that conveys more per item than multi-hop paths, providing an efficient global alternative to local entity-wise reasoning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GATHER, a convergence-centric retriever for zero-shot cell-type annotation from gene sets. It builds a self-constructed cell-centric biological KG (VCKG), performs global multi-source traversal to find topological convergence nodes (jointly reachable from many input genes) as high-information hyper-entities, scores them by node- and path-importance, and feeds the selected evidence to an LLM for annotation using only one LLM call per sample. On Immune and Lung datasets it reports highest exact-match accuracies (27.45% and 59.64%) while using far fewer LLM calls than KG-RAG baselines (ToG, ToG-2, RoG, PoG).
Significance. If the central performance claims hold after proper validation, the work offers a practical, low-cost alternative to iterative entity-wise KG-RAG for hyper-entity queries in single-cell biology. The convergence-node idea provides a global, non-iterative way to compress multi-gene signals and could generalize to other multi-source retrieval settings; the reported reduction to a single LLM call per sample is a concrete efficiency gain.
major comments (3)
- [§3.2] §3.2 (VCKG Construction): The manuscript provides no quantitative validation of VCKG (edge coverage against GO/KEGG/Reactome, precision of gene–pathway or regulatory links, or tissue-specific completeness), yet the headline claim that convergence nodes reliably surface cell-type-relevant hyper-entities rests entirely on the assumption that VCKG edges are sufficiently complete and accurate. Without such metrics or an ablation on graph quality, it is impossible to rule out that reported gains are driven by idiosyncrasies of the self-constructed graph rather than the convergence-centric algorithm.
- [§4.2–4.3] §4.2–4.3 (Experimental Results, Tables 1–2): Exact-match accuracies are reported as point estimates (27.45%, 59.64%) with no error bars, no statistical significance tests against baselines, and no details on baseline re-implementations (prompt templates, stopping criteria, or LLM versions). Because the central claim is empirical superiority with reduced LLM cost, these omissions make it impossible to assess whether the differences are robust or reproducible.
- [§4.4] §4.4 (Ablations): No ablation isolates the contribution of convergence-node selection versus VCKG construction choices or importance-scoring hyperparameters. Given that the method introduces new entities (“convergence nodes”) whose utility depends on graph topology, the absence of such controls leaves open the possibility that performance is not attributable to the proposed retrieval strategy.
minor comments (2)
- [§3.3] Notation for node- and path-importance scores (Eqs. 3–5) is introduced without a clear statement of whether the formulas are parameter-free or contain tunable thresholds; a short paragraph clarifying this would improve reproducibility.
- [Figure 2] Figure 2 (convergence-node illustration) would benefit from an explicit legend distinguishing source genes, convergence nodes, and selected evidence paths.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which have helped us identify areas to strengthen the manuscript. We address each major comment below and commit to incorporating the suggested revisions to improve clarity, rigor, and reproducibility.
read point-by-point responses
-
Referee: [§3.2] §3.2 (VCKG Construction): The manuscript provides no quantitative validation of VCKG (edge coverage against GO/KEGG/Reactome, precision of gene–pathway or regulatory links, or tissue-specific completeness), yet the headline claim that convergence nodes reliably surface cell-type-relevant hyper-entities rests entirely on the assumption that VCKG edges are sufficiently complete and accurate. Without such metrics or an ablation on graph quality, it is impossible to rule out that reported gains are driven by idiosyncrasies of the self-constructed graph rather than the convergence-centric algorithm.
Authors: We appreciate this observation. The VCKG integrates curated links from established sources (GO, KEGG, Reactome, STRING, and cell-type databases) using deterministic extraction rules. We agree that explicit validation metrics were omitted. In the revised manuscript we will add to §3.2: (i) coverage statistics (percentage of source edges retained), (ii) precision estimates from manual literature checks on a random sample of 200 edges, and (iii) an ablation that substitutes VCKG with a public KG (BioKG) while keeping the convergence-node algorithm fixed. These additions will allow readers to assess whether performance gains stem primarily from the retrieval strategy rather than graph construction details. revision: yes
-
Referee: [§4.2–4.3] §4.2–4.3 (Experimental Results, Tables 1–2): Exact-match accuracies are reported as point estimates (27.45%, 59.64%) with no error bars, no statistical significance tests against baselines, and no details on baseline re-implementations (prompt templates, stopping criteria, or LLM versions). Because the central claim is empirical superiority with reduced LLM cost, these omissions make it impossible to assess whether the differences are robust or reproducible.
Authors: We acknowledge these omissions. In the revision we will: (1) rerun all methods with three random seeds and report mean ± standard deviation for exact-match accuracy and LLM-call counts; (2) add McNemar’s tests (or paired t-tests where appropriate) for statistical significance against each baseline; and (3) include an appendix with complete baseline re-implementation details—exact prompt templates, stopping criteria for iterative KG-RAG methods, and the precise LLM versions (GPT-4o, temperature 0) used across all experiments. These changes will make the empirical claims reproducible and allow proper assessment of robustness. revision: yes
-
Referee: [§4.4] §4.4 (Ablations): No ablation isolates the contribution of convergence-node selection versus VCKG construction choices or importance-scoring hyperparameters. Given that the method introduces new entities (“convergence nodes”) whose utility depends on graph topology, the absence of such controls leaves open the possibility that performance is not attributable to the proposed retrieval strategy.
Authors: We agree that stronger isolation of components is needed. The revised §4.4 will contain three new ablations: (a) convergence-node selection versus standard multi-hop retrieval on identical VCKG, (b) GATHER on VCKG versus the same convergence algorithm on BioKG, and (c) sensitivity sweeps over the node- and path-importance weighting hyperparameters. These controls will directly quantify the incremental benefit of the convergence-centric design independent of graph construction and scoring choices. revision: yes
Circularity Check
No significant circularity in GATHER derivation chain
full rationale
The paper describes GATHER as a multi-source graph traversal algorithm that identifies convergence nodes on a self-constructed VCKG, with all performance claims (exact-match accuracies of 27.45% and 59.64%) resting on direct empirical comparison against external KG-RAG baselines (ToG, RoG, etc.) on held-out Immune and Lung datasets. No equations, fitted parameters, or predictions are present that reduce to self-definition or construction. No self-citations, uniqueness theorems, or ansatzes are invoked as load-bearing premises. The method and results are self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The self-constructed VCKG accurately represents gene-cell-type relationships sufficient for convergence-based retrieval.
invented entities (1)
-
Convergence nodes
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Floren- cia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. 2023. GPT-4 Technical Report. arXiv preprint arXiv:2303.08774. doi:10.48550/arXiv.2303.08774
-
[2]
Dvir Aran, Agnieszka P Looney, Leqian Liu, Esther Wu, Valerie Fong, Austin Hsu, Suzanna Chak, Ram P Naikawadi, Paul J Wolters, Adam R Abate, et al. 2019. Reference-based analysis of lung single-cell sequencing reveals a transitional profibrotic macrophage.Nature immunology20, 2 (2019), 163–172
2019
-
[3]
Michael Ashburner, Catherine A Ball, Judith A Blake, David Botstein, Heather Butler, J Michael Cherry, Allan P Davis, Kara Dolinski, Selina S Dwight, Janan T Eppig, et al. 2000. Gene ontology: tool for the unification of biology.Nature genetics25, 1 (2000), 25–29
2000
-
[4]
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. 2020. Language models are few-shot learners.Advances in neural information processing systems33 (2020), 1877–1901
2020
-
[5]
Payal Chandak, Kexin Huang, and Marinka Zitnik. 2023. Building a knowledge graph to enable precision medicine.Scientific Data10, 1 (2023), 67
2023
-
[6]
The Tabula Sapiens Consortium*, Robert C Jones, Jim Karkanias, Mark A Krasnow, Angela Oliveira Pisco, Stephen R Quake, Julia Salzman, Nir Yosef, Bryan Bulthaup, Phillip Brown, et al . 2022. The Tabula Sapiens: A multiple-organ, single-cell transcriptomic atlas of humans.Science376, 6594 (2022), eabl4896
2022
-
[7]
Haotian Cui, Chloe Wang, Hassaan Maan, Kuan Pang, Fengning Luo, Nan Duan, and Bo Wang. 2024. scGPT: toward building a foundation model for single-cell multi-omics using generative AI.Nature methods21, 8 (2024), 1470–1480
2024
-
[8]
C Domínguez Conde, Chao Xu, Louie B Jarvis, Daniel B Rainbow, Sara B Wells, Tamir Gomes, SK Howlett, O Suchanek, K Polanski, HW King, et al. 2022. Cross- tissue immune cell analysis reveals tissue-specific features in humans.Science 376, 6594 (2022), eabl5197
2022
-
[9]
Wenqi Fan, Yujuan Ding, Liangbo Ning, Shijie Wang, Hengyun Li, Dawei Yin, Tat- Seng Chua, and Qing Li. 2024. A survey on rag meeting llms: Towards retrieval- augmented large language models. InProceedings of the 30th ACM SIGKDD conference on knowledge discovery and data mining. Association for Computing Machinery, New York, NY, USA, 6491–6501. doi:10.1145...
-
[10]
Wenpin Hou and Zhicheng Ji. 2024. Assessing GPT-4 for cell type annotation in single-cell RNA-seq analysis.Nature methods21, 8 (2024), 1462–1465
2024
-
[11]
Congxue Hu, Tengyue Li, Yingqi Xu, Xinxin Zhang, Feng Li, Jing Bai, Jing Chen, Wenqi Jiang, Kaiyue Yang, Qi Ou, et al. 2023. CellMarker 2.0: an updated database of manually curated cell markers in human/mouse and web tools based on scRNA- seq data.Nucleic acids research51, D1 (2023), D870–D876
2023
-
[12]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, et al. 2020. Retrieval-augmented generation for knowledge-intensive nlp tasks. Advances in neural information processing systems33 (2020), 9459–9474
2020
-
[13]
Linhao Luo, Yuan-Fang Li, Gholamreza Haffari, and Shirui Pan. 2024. Reasoning on Graphs: Faithful and Interpretable Large Language Model Reasoning. In International Conference on Learning Representations. OpenReview.net, Vienna, Austria, 14400–14423
2024
-
[14]
Shengjie Ma, Chengjin Xu, Xuhui Jiang, Muzhi Li, Huaren Qu, Cehao Yang, Jiaxin Mao, and Jian Guo. 2025. Think-on-Graph 2.0: Deep and Faithful Large Language Model Reasoning with Knowledge-guided Retrieval Augmented Gen- eration. InThe Thirteenth International Conference on Learning Representations. OpenReview.net, Singapore, 52782–52806
2025
-
[15]
Shirui Pan, Linhao Luo, Yufei Wang, Chen Chen, Jiapu Wang, and Xindong Wu
-
[16]
Unifying large language models and knowledge graphs: A roadmap.IEEE Transactions on Knowledge and Data Engineering36, 7 (2024), 3580–3599
2024
-
[17]
Giovanni Pasquini, Jesus Eduardo Rojo Arias, Patrick Schäfer, and Volker Busskamp. 2021. Automated methods for cell type annotation on scRNA-seq data.Computational and Structural Biotechnology Journal19 (2021), 961–969
2021
-
[18]
Syed Asad Rizvi, Daniel Levine, Aakash Patel, Shiyang Zhang, Eric Wang, Cur- tis Jamison Perry, Nicole Mayerli Constante, Sizhuang He, David Zhang, Cerise Tang, et al. 2025. Scaling large language models for next-generation single-cell analysis. 2025–04 pages
2025
-
[19]
Jiashuo Sun, Chengjin Xu, Lumingyuan Tang, Saizhuo Wang, Chen Lin, Yeyun Gong, Lionel Ni, Heung-Yeung Shum, and Jian Guo. 2024. Think-on-Graph: Deep and Responsible Reasoning of Large Language Model on Knowledge Graph. In The Twelfth International Conference on Learning Representations. OpenReview.net, Vienna, Austria, 3868–3898
2024
-
[20]
Xingyu Tan, Xiaoyang Wang, Qing Liu, Xiwei Xu, Xin Yuan, and Wenjie Zhang
-
[21]
InProceedings of the ACM on Web Conference 2025(Sydney NSW, Australia)(WWW ’25)
Paths-over-graph: Knowledge graph empowered large language model reasoning. InProceedings of the ACM on Web Conference 2025(Sydney NSW, Australia)(WWW ’25). Association for Computing Machinery, New York, NY, USA, 3505–3522. doi:10.1145/3696410.3714892
-
[22]
Christina V Theodoris, Ling Xiao, Anant Chopra, Mark D Chaffin, Zeina R Al Sayed, Matthew C Hill, Helene Mantineo, Elizabeth M Brydon, Zexian Zeng, X Shirley Liu, et al . 2023. Transfer learning enables predictions in network biology.Nature618, 7965 (2023), 616–624
2023
-
[23]
Fan Yang, Wenchuan Wang, Fang Wang, Yuan Fang, Duyu Tang, Junzhou Huang, Hui Lu, and Jianhua Yao. 2022. scBERT as a large-scale pretrained deep language model for cell type annotation of single-cell RNA-seq data.Nature Machine Intelligence4, 10 (2022), 852–866
2022
-
[24]
Xinxin Zhang, Yujia Lan, Jinyuan Xu, Fei Quan, Erjie Zhao, Chunyu Deng, Tao Luo, Liwen Xu, Gaoming Liao, Min Yan, et al . 2019. CellMarker: a manually curated resource of cell markers in human and mouse.Nucleic acids research47, D1 (2019), D721–D728
2019
-
[25]
Suyuan Zhao, Jiahuan Zhang, Yushuai Wu, Yizhen Luo, and Zaiqing Nie. 2024. LangCell: Language-Cell Pre-training for Cell Identity Understanding. InInterna- tional Conference on Machine Learning (Proceedings of Machine Learning Research, Vol. 235). PMLR, Vienna, Austria, 61159–61185
2024
-
[26]
Yuqi Zhu, Xiaohan Wang, Jing Chen, Shuofei Qiao, Yixin Ou, Yunzhi Yao, Shumin Deng, Huajun Chen, and Ningyu Zhang. 2024. Llms for knowledge graph con- struction and reasoning: Recent capabilities and future opportunities.World Wide Web27, 5 (2024), 58
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.