Recognition: unknown
Patch-Effect Graph Kernels for LLM Interpretability
Pith reviewed 2026-05-08 09:39 UTC · model grok-4.3
The pith
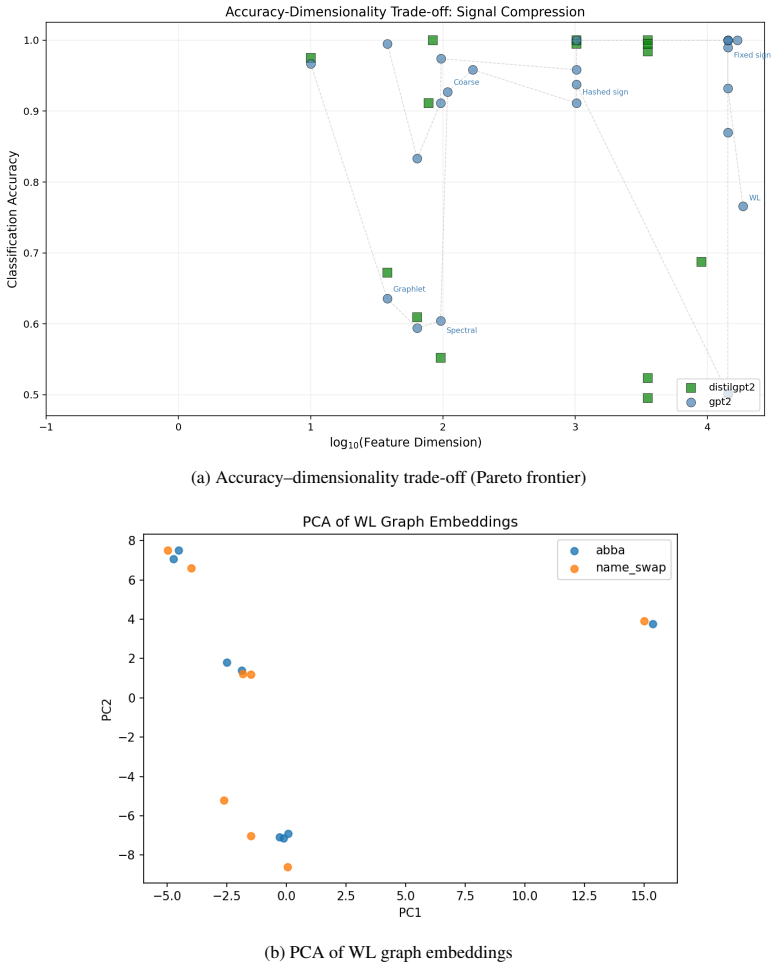
Patch-effect graphs built from activation patching preserve structural signals that graph kernels classify using localized edge features better than global shape descriptors.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Patch-effect graphs represent activation-patching profiles as structures with nodes for model components and edges weighted by influence measures from causal mediation, partial correlation, or co-influence. When graph kernels analyze these graphs, localized features tied to specific edge slots yield higher classification accuracy for task-specific patching patterns than global descriptors of graph shape. A screened paired-patching test confirms that candidate edges from co-influence and partial-correlation constructions correspond to interventions with measurably larger activation-influence effects than random or low-rank selections. The evaluation makes explicit that graph features compress
What carries the argument
Patch-effect graphs over model components with edges from direct-influence, partial-correlation, or co-influence constructions, analyzed by graph kernels to extract discriminative structural features such as localized edge slots.
If this is right
- Graph representations compress high-dimensional patching data into structures that support systematic comparison across prompts and tasks.
- Localized edge features outperform global shape descriptors for identifying task-discriminative patterns in patching results.
- Edges selected via co-influence and partial-correlation methods exhibit stronger activation-influence effects in targeted paired tests.
- Explicit prompt-only and raw patch-effect baselines clarify the scope of evidence for circuit-level claims.
- The pipeline separates robust slice-discriminative signals from stronger task-general causal assertions.
Where Pith is reading between the lines
- The approach could support automated circuit search by treating high-discrimination graphs as targets for optimization.
- Testing on larger models would show whether the advantage of localized edge features scales with model size.
- The baseline controls imply that other interpretability methods should adopt similar explicit comparisons to raw data to strengthen causal claims.
- Graph kernels could be swapped for alternative feature extractors to test whether the structural signal is method-specific.
Load-bearing premise
The three graph construction methods accurately encode the causal structure of activation-patching interventions without introducing artifacts that the kernel analysis then exploits.
What would settle it
If graphs constructed from randomized or non-causal patching data produce the same classification accuracies and validation scores as the actual patching-derived graphs, the claim that the graphs preserve discriminative causal signals would fail.
Figures



read the original abstract
Mechanistic interpretability aims to reverse-engineer transformer computations by identifying causal circuits through activation patching. However, scaling these interventions across diverse prompts and task families produces high-dimensional, unstructured datasets that are difficult to compare systematically. We propose a framework that reframes mechanistic analysis as a graph machine-learning problem by representing activation-patching profiles as patch-effect graphs over model components. We introduce three graph-construction methods: direct-influence via causal mediation, partial-correlation, and co-influence and apply graph kernels to analyze the resulting structures. Evaluating this approach on GPT-2 Small using Indirect Object Identification (IOI) and related tasks, we find that patch-effect graphs preserve discriminative structural signals. Specifically, localized edge-slot features provide higher classification accuracy than global graph-shape descriptors. A screened paired-patching validation suggests that CI and PC selected candidate edges correspond to stronger activation-influence effects than random or low-rank candidates. Crucially, by evaluating these representations against rigorous prompt-only and raw patch-effect controls, we make the evidential scope of the benchmark explicit: graph features compress structured patching signal, while raw tensors and surface cues define strong baselines that any circuit-level claim should address. Ultimately, our framework provides a compression and evaluation pipeline for comparing patching-derived structures under controlled baselines, separating robust slice-discriminative evidence from stronger task-general causal-circuit claims.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes reframing activation-patching results in transformers as patch-effect graphs constructed via three methods (direct-influence through causal mediation, partial-correlation, and co-influence). Graph kernels are then applied to these graphs on GPT-2 Small for IOI and related tasks. The central claims are that patch-effect graphs preserve discriminative structural signals, with localized edge-slot features yielding higher classification accuracy than global graph-shape descriptors, and that a screened paired-patching validation shows CI/PC-selected edges correspond to stronger activation-influence effects than random or low-rank baselines. The work explicitly benchmarks against prompt-only and raw patch-effect controls to bound the evidential scope.
Significance. If the results hold under the stated controls, the framework supplies a systematic compression and comparison pipeline for high-dimensional patching data across prompts and tasks. The explicit prompt-only and raw-tensor baselines are a clear strength, as they prevent overclaiming causal-circuit discovery while still allowing structured-signal analysis. The approach could help mechanistic interpretability move from case-by-case circuit identification toward reproducible, graph-based evaluation of patching-derived structures.
major comments (2)
- [Abstract / Evaluation] Abstract and Evaluation section: the claim that localized edge-slot features provide higher classification accuracy than global descriptors depends on the three graph-construction methods faithfully encoding causal activation-patching structure. Direct-influence is causal by construction, but partial-correlation and co-influence are statistical; the paired-patching validation shows stronger effects for selected edges yet does not isolate whether the accuracy gains arise from causal circuits rather than correlational artifacts that the kernels later exploit.
- [Methods] Methods (graph construction): no explicit test is reported that compares the discriminative power of the three constructions against a purely interventional (causal-mediation-only) baseline while holding the kernel fixed. Without this, it remains possible that the reported advantage of localized features is driven by the statistical methods' sensitivity to non-causal associations rather than by preservation of patching-derived causal structure.
minor comments (3)
- [Methods] Provide the exact definitions and formulas for 'edge-slot features' versus 'global graph-shape descriptors' (including which kernels are used for each) so that the classification comparison can be reproduced.
- [Evaluation] Report raw accuracy numbers, standard errors, and the precise statistical test used for the 'higher classification accuracy' claim rather than qualitative statements.
- [Evaluation] Clarify how the 'screened' paired-patching validation avoids post-hoc selection bias when comparing CI/PC edges against random and low-rank candidates.
Simulated Author's Rebuttal
We thank the referee for their constructive comments and positive assessment of the framework's potential. We address the major comments point by point below, indicating the revisions we will make to clarify the causal aspects of our analysis.
read point-by-point responses
-
Referee: [Abstract / Evaluation] Abstract and Evaluation section: the claim that localized edge-slot features provide higher classification accuracy than global descriptors depends on the three graph-construction methods faithfully encoding causal activation-patching structure. Direct-influence is causal by construction, but partial-correlation and co-influence are statistical; the paired-patching validation shows stronger effects for selected edges yet does not isolate whether the accuracy gains arise from causal circuits rather than correlational artifacts that the kernels later exploit.
Authors: We agree that it is important to distinguish the causal nature of the constructions. The direct-influence method relies on causal mediation analysis, which is interventional by design. In contrast, partial-correlation and co-influence are statistical associations derived from the patching data. Our results show that localized edge-slot features outperform global graph-shape descriptors consistently across all three methods, including the causal direct-influence construction. This suggests that the advantage is not limited to statistical artifacts. The screened paired-patching validation further supports that CI and PC edges align with stronger influence effects. To strengthen the manuscript, we will revise the abstract and evaluation section to explicitly state that the performance advantage holds for the causal construction and discuss the complementary role of the statistical methods. We will also add a sentence noting the evidential scope regarding causality. revision: yes
-
Referee: [Methods] Methods (graph construction): no explicit test is reported that compares the discriminative power of the three constructions against a purely interventional (causal-mediation-only) baseline while holding the kernel fixed. Without this, it remains possible that the reported advantage of localized features is driven by the statistical methods' sensitivity to non-causal associations rather than by preservation of patching-derived causal structure.
Authors: We acknowledge that we did not report a direct comparison isolating the causal-mediation-only graphs against the others with the kernel held fixed. Our current evaluation presents results for each graph construction independently, demonstrating the localized feature advantage in each case. To address this concern rigorously, we will perform and include in the revised manuscript an additional experiment: we will fix the graph kernel and compare classification accuracies using only direct-influence graphs versus the partial-correlation and co-influence graphs. This will help isolate whether the gains stem from causal structure preservation or statistical sensitivities. The results of this analysis will be added to the Evaluation section, along with updated figures if necessary. revision: yes
Circularity Check
No significant circularity; central claims rest on external benchmarks and empirical validation
full rationale
The paper frames activation-patching data as patch-effect graphs via three explicit construction methods (direct-influence, partial-correlation, co-influence), then applies graph kernels and reports classification accuracies plus screened paired-patching results. All load-bearing claims are evaluated against prompt-only and raw patch-effect controls, which are independent of the authors' fitted graph features. No equation or derivation reduces a reported quantity to a parameter defined from the same quantity; no self-citation chain or uniqueness theorem is invoked to force the outcome. The derivation chain therefore remains self-contained against external baselines.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Towards monosemanticity: Decomposing language models with dictionary learning.Transformer Circuits Thread, 2023
Trenton Bricken, Adly Templeton, Joshua Batson, Brian Chen, Adam Jermyn, Tom Conerly, Nick Turner, Cem Anil, Carson Denison, Amanda Askell, et al. Towards monosemanticity: Decomposing language models with dictionary learning.Transformer Circuits Thread, 2023
2023
-
[2]
Towards automated circuit discovery for mechanistic interpretability
Arthur Conmy, Augustine N Mavor-Parker, Aengus Lynch, Stefan Heimersheim, and Adria Garriga- Alonso. Towards automated circuit discovery for mechanistic interpretability. InAdvances in Neural Information Processing Systems, 2023
2023
-
[3]
A mathematical framework for transformer circuits
Nelson Elhage, Neel Nanda, Catherine Olsson, Tom Henighan, Nicholas Joseph, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, Tom Conerly, et al. A mathematical framework for transformer circuits. Transformer Circuits Thread, 2021
2021
-
[4]
Nicholas Goldowsky-Dill, Chris MacLeod, Buck Shlegeris, and Nate Bhatt. Localizing model behavior with path patching.arXiv preprint arXiv:2304.05969, 2023
-
[5]
How does GPT-2 compute greater-than?: Interpret- ing mathematical abilities in a pre-trained language model
Michael Hanna, Ollie Liu, and Alexandre Variengien. How does GPT-2 compute greater-than?: Interpret- ing mathematical abilities in a pre-trained language model. InAdvances in Neural Information Processing Systems, 2023
2023
-
[6]
Diffusion kernels on graphs and other discrete input spaces
Risi Imre Kondor and John Lafferty. Diffusion kernels on graphs and other discrete input spaces. In International Conference on Machine Learning, 2002
2002
-
[7]
A survey on graph kernels.Applied Network Science, 5(1):1–42, 2020
Nils M Kriege, Fredrik D Johansson, and Christopher Morris. A survey on graph kernels.Applied Network Science, 5(1):1–42, 2020
2020
-
[8]
Attribution patching: activation patching at industrial scale
Neel Nanda. Attribution patching: activation patching at industrial scale. Alignment Forum, 2023. URL https://www.neelnanda.io/mechanistic-interpretability/attribution-patching
2023
-
[9]
In-context learning and induction heads.Trans- former Circuits Thread, 2022
Catherine Olsson, Nelson Elhage, Neel Nanda, Nicholas Joseph, Nova DasSarma, Tom Henighan, Ben Mann, Amanda Askell, Yuntao Bai, Anna Chen, et al. In-context learning and induction heads.Trans- former Circuits Thread, 2022
2022
-
[10]
Cambridge University Press, 2009
Judea Pearl.Causality: Models, Reasoning, and Inference. Cambridge University Press, 2009
2009
-
[11]
Language models are unsupervised multitask learners.OpenAI Blog, 1(8):9, 2019
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners.OpenAI Blog, 1(8):9, 2019
2019
-
[12]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Victor Sanh, Lysandre Debut, Julien Chaumond, and Thomas Wolf. DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.arXiv preprint arXiv:1910.01108, 2019
work page internal anchor Pith review arXiv 1910
-
[13]
Effi- cient graphlet kernels for large graph comparison
Nino Shervashidze, SVN Vishwanathan, Tobias Petri, Kurt Mehlhorn, and Karsten M Borgwardt. Effi- cient graphlet kernels for large graph comparison. InArtificial Intelligence and Statistics, pages 488–495, 2009
2009
-
[14]
Weisfeiler-Lehman graph kernels.Journal of Machine Learning Research, 12:2539–2561, 2011
Nino Shervashidze, Pascal Schweitzer, Erik Jan Van Leeuwen, Kurt Mehlhorn, and Karsten M Borgwardt. Weisfeiler-Lehman graph kernels.Journal of Machine Learning Research, 12:2539–2561, 2011
2011
-
[15]
Attention is all you need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N Gomez, Łukasz Kaiser, and Illia Polosukhin. Attention is all you need. InAdvances in Neural Information Processing Systems, volume 30, 2017
2017
-
[16]
Interpretability in the wild: a circuit for indirect object identification in GPT-2 small
Kevin Wang, Alexandre Variengien, Arthur Conmy, Buck Shlegeris, and Jacob Steinhardt. Interpretability in the wild: a circuit for indirect object identification in GPT-2 small. InInternational Conference on Learning Representations, 2023. 10 A Additional Material A.1 Additional Discussion A.1.1 Summary of Evidence for Each Hypothesis Hyp. Claim Status Evi...
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.