Recognition: unknown
Estimate Level Adjustment For Inference With Proxies Under Random Distribution Shifts
Pith reviewed 2026-05-08 07:25 UTC · model grok-4.3
The pith
Proxy-based inferences are calibrated by modeling discrepancies with primary outcomes as random effects estimated from historical domains.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce an estimate-level framework to empirically calibrate proxy-based inference by modeling the proxy-primary metric discrepancy as a random effect at the parameter level. Its distribution is estimated from aggregated historical observations across past domains such as experiments, time periods, or segments. The method requires no retention of individual-level response data and can be layered onto existing proxy-correction procedures to handle residual biases. Both a method-of-moments estimator and a domain bootstrap are supplied to handle limited numbers of historical domains.
What carries the argument
The estimate-level random-effect model for proxy-primary discrepancy, fitted to aggregated historical domain observations.
If this is right
- The adjustment can be applied on top of prediction-powered inference or importance weighting to capture biases those methods leave unaddressed.
- Only aggregate estimates from past domains are needed, so individual data need not be stored or re-accessed.
- Method-of-moments and domain-bootstrap estimators provide practical ways to quantify uncertainty when few historical domains are available.
- The framework applies directly to experimentation, time-series, and segmented data settings where proxies are common.
- Validation on public datasets and real-world experiments supports its use under random distribution shifts.
Where Pith is reading between the lines
- The approach resembles empirical-Bayes shrinkage across domains and could be extended to settings where the random-effect variance itself varies with observable domain features.
- If the random-effect assumption holds, retaining only summary statistics from past experiments becomes sufficient for ongoing calibration, reducing data-storage requirements.
- Practitioners could test the method by withholding the most recent domain and checking whether the adjustment improves inference on that held-out case.
- The same logic might apply to other meta-analytic problems in which historical parameter estimates inform current uncertainty quantification.
Load-bearing premise
The discrepancies between proxy and primary outcomes behave as random effects whose distribution can be reliably estimated from a limited number of historical domains and that these historical observations are representative of the current shift.
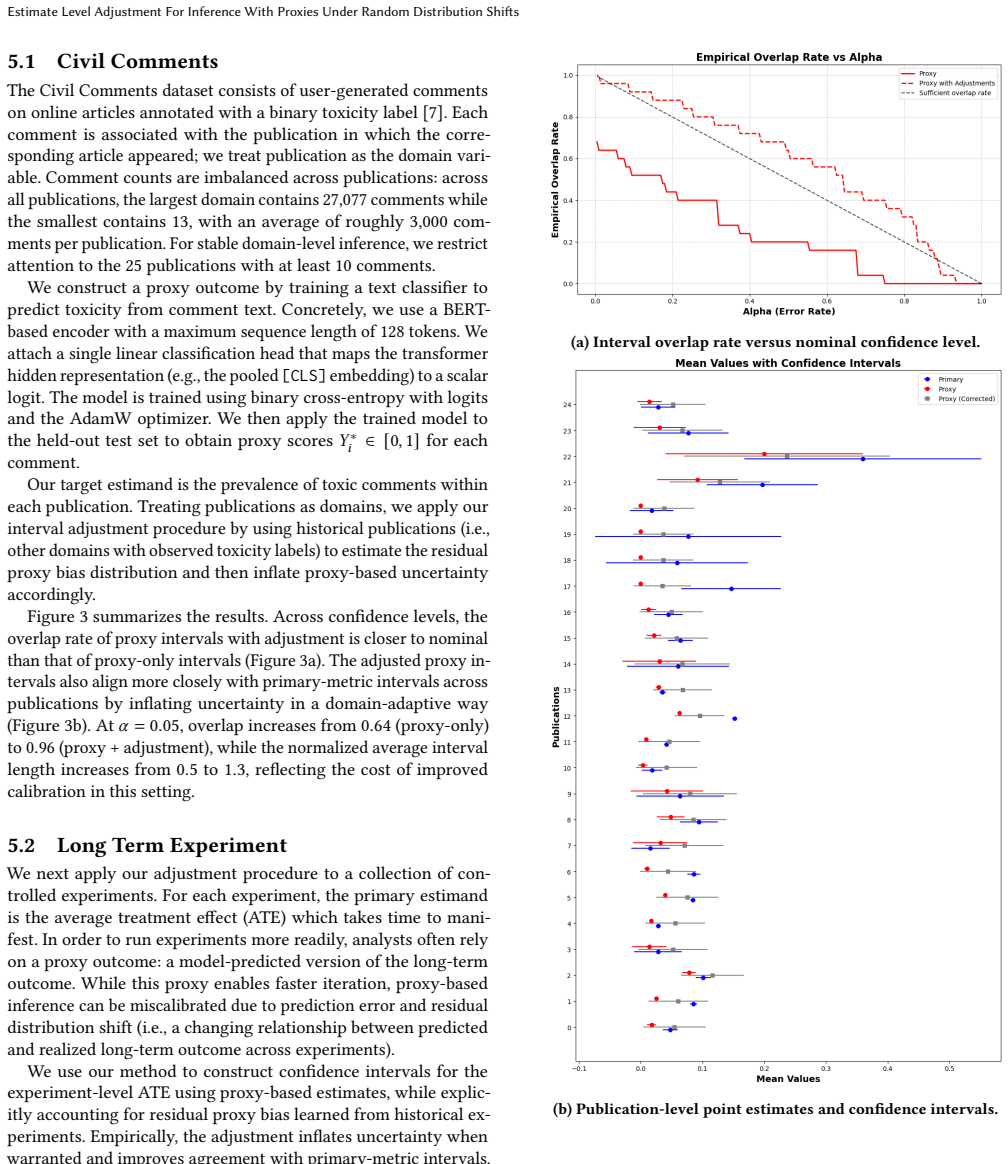
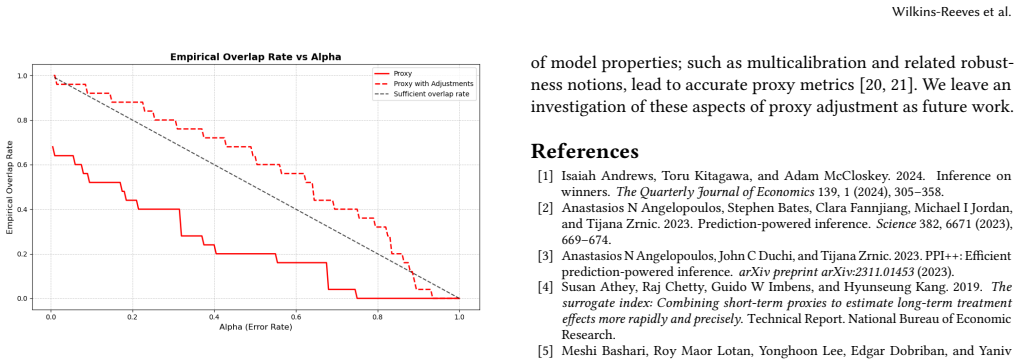
What would settle it
A new domain in which the adjusted estimates show no reduction in bias or no improvement in coverage of the primary parameter relative to the unadjusted proxy estimates, or in which the fitted random-effect distribution systematically fails to match the observed discrepancies.
Figures

read the original abstract
In many scientific domains, including experimentation, researchers rely on measurements of proxy outcomes to achieve faster and more frequent reads, especially when the primary outcome of interest is challenging to measure directly. While proxies offer a more readily accessible observation for inference, the ultimate goal is to draw statistical inferences about the primary outcome parameter and proxy data are typically imperfect in some ways. To correct for these imperfections, current statistical inference methods often depend on strict identifying assumptions (such as surrogacy, covariate/label shift, or missingness assumptions). These assumptions can be difficult to validate and may be violated by various additional sources of distribution shift, potentially leading to biased parameter estimates and miscalibrated uncertainty quantification. We introduce an estimate-level framework, inspired by domain adaptation techniques, to empirically calibrate proxy-based inference. This framework models the proxy-primary metric discrepancy as a random effect at the parameter level, estimating its distribution from aggregated historical observations across past domains (e.g., experiments, time periods, or distinct segments). This method avoids the requirement for retaining individual-level response data. Additionally, this adjustment can be layered on top of existing proxy-correction methods (such as prediction-powered inference or importance weighting) to account for additional biases not addressed by those corrections. To manage uncertainty when the number of historical domains is limited, we provide both a method-of-moments estimator and a domain bootstrap procedure. We further validate this approach using publicly available datasets and real-world experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces an estimate-level framework for calibrating statistical inference when using proxy outcomes under random distribution shifts. It models the discrepancy between proxy-based and primary metric estimates as a random effect at the parameter level, with the distribution of this effect estimated from aggregated historical observations across past domains (e.g., experiments or time periods). The method avoids retaining individual-level data, can be layered atop existing proxy corrections such as prediction-powered inference or importance weighting, and supplies a method-of-moments estimator together with a domain bootstrap procedure to handle uncertainty when the number of historical domains is small. Validation is reported on publicly available datasets and real-world experiments.
Significance. If the exchangeability assumption holds, the work supplies a practical, data-retention-friendly route to improve uncertainty calibration for proxy-based inference in the presence of additional unmodeled shifts. The layering property and the provision of two limited-domain estimators constitute concrete strengths that could be useful in experimentation and observational settings where strict identifying assumptions are hard to verify.
major comments (3)
- [Framework description (modeling the discrepancy as random effect)] The framework treats the current-domain proxy-primary discrepancy as exchangeable with the distribution estimated from historical domains. No formal conditions for this exchangeability, nor sensitivity analyses against systematic violations (time trends, new covariates, or selection effects), are supplied; this assumption is load-bearing for the claim of calibrated intervals after adjustment.
- [Uncertainty quantification section] The domain bootstrap procedure is offered for limited historical domains, yet the manuscript does not detail how the bootstrap is constructed from aggregated estimates alone (without individual-level responses) or how it propagates uncertainty in the estimated random-effect variance.
- [Validation / Experiments] Validation on public datasets and real-world experiments does not include targeted checks (e.g., simulated non-exchangeable shifts) that would demonstrate whether the adjusted intervals remain calibrated when the current shift deviates from the historical distribution.
minor comments (3)
- [Title] The title would read more clearly as 'Estimate-Level Adjustment for Inference with Proxies under Random Distribution Shifts'.
- [Abstract] The abstract introduces the 'estimate-level framework' without a one-sentence definition; a brief gloss would aid readers.
- [Introduction] A short discussion of how the proposed random-effect adjustment relates to existing meta-analytic or domain-adaptation random-effect models would help situate the contribution.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We appreciate the recognition of the framework's practical advantages, including its layering property and data-retention-friendly design. Below we respond point-by-point to the major comments, outlining the revisions we will make to address the concerns raised.
read point-by-point responses
-
Referee: The framework treats the current-domain proxy-primary discrepancy as exchangeable with the distribution estimated from historical domains. No formal conditions for this exchangeability, nor sensitivity analyses against systematic violations (time trends, new covariates, or selection effects), are supplied; this assumption is load-bearing for the claim of calibrated intervals after adjustment.
Authors: We agree that the exchangeability assumption is central to the method. In the revised manuscript we will add a dedicated subsection in the Methods that formally defines the assumption: the target-domain discrepancy is modeled as exchangeable with the historical discrepancies under a common meta-distribution of random shifts. We will also expand the Experiments section with sensitivity analyses that introduce systematic violations (linear time trends in the discrepancy, new unobserved covariates, and selection effects) and report the resulting coverage of the adjusted intervals to illustrate robustness and limitations. revision: yes
-
Referee: The domain bootstrap procedure is offered for limited historical domains, yet the manuscript does not detail how the bootstrap is constructed from aggregated estimates alone (without individual-level responses) or how it propagates uncertainty in the estimated random-effect variance.
Authors: The domain bootstrap operates exclusively on the historical domain-level parameter estimates (the aggregated summaries) by resampling these domain-level discrepancies with replacement; the random-effect variance is then re-estimated in each replicate to propagate its uncertainty. We will insert a detailed algorithmic description together with pseudocode into the Uncertainty Quantification section to make this construction explicit and to confirm that no individual-level data are required. revision: yes
-
Referee: Validation on public datasets and real-world experiments does not include targeted checks (e.g., simulated non-exchangeable shifts) that would demonstrate whether the adjusted intervals remain calibrated when the current shift deviates from the historical distribution.
Authors: We concur that such targeted checks would strengthen the validation. In the revision we will add a new simulation study in which the current-domain shift is deliberately made non-exchangeable (e.g., by superimposing a systematic trend or covariate shift absent from the historical domains) and will report the empirical coverage probabilities of the adjusted intervals under these controlled violations. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's central construction estimates the distribution of proxy-primary discrepancies as a random effect from aggregated historical domain observations and applies this to calibrate inference in a new domain. This relies on an external data source (historical domains) rather than deriving the adjustment from the current estimates alone. No load-bearing step reduces by construction to a self-definition, a fitted parameter renamed as a prediction, or a self-citation chain; the framework is self-contained against external benchmarks and does not invoke uniqueness theorems or ansatzes from prior author work in a circular manner.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Proxy-primary discrepancies can be modeled as random effects whose distribution is estimable from aggregated historical observations across domains.
Reference graph
Works this paper leans on
-
[1]
Isaiah Andrews, Toru Kitagawa, and Adam McCloskey. 2024. Inference on winners.The Quarterly Journal of Economics139, 1 (2024), 305–358
2024
-
[2]
Anastasios N Angelopoulos, Stephen Bates, Clara Fannjiang, Michael I Jordan, and Tijana Zrnic. 2023. Prediction-powered inference.Science382, 6671 (2023), 669–674
2023
- [3]
-
[4]
2019.The surrogate index: Combining short-term proxies to estimate long-term treatment effects more rapidly and precisely
Susan Athey, Raj Chetty, Guido W Imbens, and Hyunseung Kang. 2019.The surrogate index: Combining short-term proxies to estimate long-term treatment effects more rapidly and precisely. Technical Report. National Bureau of Economic Research
2019
- [5]
-
[6]
Aurélien Bibaut, Winston Chou, Simon Ejdemyr, and Nathan Kallus. 2024. Learn- ing the covariance of treatment effects across many weak experiments. InPro- ceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 153–162
2024
-
[7]
Daniel Borkan, Lucas Dixon, Jeffrey Sorensen, Nithum Thain, and Lucy Vasser- man. 2019. Nuanced metrics for measuring unintended bias with real data for text classification. InCompanion Proceedings of The 2019 World Wide Web Conference
2019
-
[8]
Marc Buyse, Geert Molenberghs, Tomasz Burzykowski, Didier Renard, and He- lena Geys. 2000. The validation of surrogate endpoints in meta-analyses of randomized experiments.Biostatistics1, 1 (2000), 49–67
2000
-
[9]
Yee Seng Chan and Hwee Tou Ng. 2005. Word Sense Disambiguation with Distribution Estimation.. InIJCAI, Vol. 5. 1010–5
2005
- [10]
-
[11]
Rebecca DerSimonian and Nan Laird. 1986. Meta-analysis in clinical trials. Controlled clinical trials7, 3 (1986), 177–188
1986
-
[12]
Bradley Efron, Robert Tibshirani, John D Storey, and Virginia Tusher. 2001. Empirical Bayes analysis of a microarray experiment.Journal of the American statistical association96, 456 (2001), 1151–1160
2001
-
[13]
Simon Ejdemyr, Martin Tingley, Yian Shang, and Travis Brooks. 2024. Estimating the returns from an experimentation program. InACIC Conference
2024
-
[14]
Somit Gupta, Ronny Kohavi, Diane Tang, Ya Xu, Reid Andersen, Eytan Bakshy, Niall Cardin, Sumita Chandran, Nanyu Chen, Dominic Coey, et al . 2019. Top challenges from the first practical online controlled experiments summit.ACM SIGKDD Explorations Newsletter21, 1 (2019), 20–35
2019
-
[15]
Ursula Hébert-Johnson, Michael Kim, Omer Reingold, and Guy Rothblum. 2018. Multicalibration: Calibration for the (computationally-identifiable) masses. In International Conference on Machine Learning. PMLR, 1939–1948
2018
-
[16]
James J Heckman, Jora Stixrud, and Sergio Urzua. 2006. The effects of cognitive and noncognitive abilities on labor market outcomes and social behavior.Journal of Labor economics24, 3 (2006), 411–482
2006
-
[17]
Nikos Ignatiadis and Bodhisattva Sen. 2024. Empirical Bayes: From Herbert Robbins to Modern Theory and Applications. (2024). https://nignatiadis.github. io/assets/lecture_notes/Empirical-Bayes.pdf Lecture Notes
2024
-
[18]
Nikolaos Ignatiadis and Stefan Wager. 2022. Confidence intervals for nonparamet- ric empirical Bayes analysis.J. Amer. Statist. Assoc.117, 539 (2022), 1149–1166
2022
- [19]
-
[20]
Michael P Kim, Amirata Ghorbani, and James Zou. 2019. Multiaccuracy: Black-box post-processing for fairness in classification. InProceedings of the 2019 AAAI/ACM Conference on AI, Ethics, and Society. 247–254
2019
-
[21]
Michael P Kim, Christoph Kern, Shafi Goldwasser, Frauke Kreuter, and Omer Reingold. 2022. Universal adaptability: Target-independent inference that com- petes with propensity scoring.Proceedings of the National Academy of Sciences 119, 4 (2022), e2108097119
2022
- [22]
-
[23]
Pang Wei Koh, Shiori Sagawa, Henrik Marklund, Sang Michael Xie, Marvin Zhang, Akshay Balsubramani, Weihua Hu, Michihiro Yasunaga, Richard Lanas Phillips, Irena Gao, et al. 2021. Wilds: A benchmark of in-the-wild distribution shifts. InInternational conference on machine learning. PMLR, 5637–5664
2021
-
[24]
Minyong R Lee and Milan Shen. 2018. Winner’s curse: Bias estimation for total effects of features in online controlled experiments. InProceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 491–499. Estimate Level Adjustment For Inference With Proxies Under Random Distribution Shifts
2018
-
[25]
Zachary Lipton, Yu-Xiang Wang, and Alexander Smola. 2018. Detecting and correcting for label shift with black box predictors. InInternational conference on machine learning. PMLR, 3122–3130
2018
-
[26]
Viet-An Nguyen, Peibei Shi, Jagdish Ramakrishnan, Udi Weinsberg, Henry C Lin, Steve Metz, Neil Chandra, Jane Jing, and Dimitris Kalimeris. 2020. CLARA: confi- dence of labels and raters. InProceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2542–2552
2020
-
[27]
Ross L Prentice. 1989. Surrogate endpoints in clinical trials: definition and operational criteria.Statistics in medicine8, 4 (1989), 431–440
1989
-
[28]
Herbert Robbins. 1964. The empirical Bayes approach to statistical decision problems.The Annals of Mathematical Statistics35, 1 (1964), 1–20
1964
-
[29]
Walter J Rogan and Beth Gladen. 1978. Estimating prevalence from the results of a screening test.American journal of epidemiology107, 1 (1978), 71–76
1978
-
[30]
Tal Sarig, Ido Guy, Ami Tavory, Udi Weinsberg, and Stratis Ioannidis. 2025. Mind the Gap: Delayed Label Bias-Variance Tradeoffs in Predicting Likelihood of Nonpayment. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V. 2. 4784–4795
2025
-
[31]
Bernhard Schölkopf, Dominik Janzing, Jonas Peters, Eleni Sgouritsa, Kun Zhang, and Joris Mooij. 2012. On causal and anticausal learning. InProceedings of the 29th International Conference on International Conference on Machine Learning. 459–466
2012
-
[32]
Hidetoshi Shimodaira. 2000. Improving predictive inference under covariate shift by weighting the log-likelihood function.Journal of statistical planning and inference90, 2 (2000), 227–244
2000
-
[33]
Masashi Sugiyama, Shinichi Nakajima, Hisashi Kashima, Paul Buenau, and Mo- toaki Kawanabe. 2007. Direct importance estimation with model selection and its application to covariate shift adaptation.Advances in neural information processing systems20 (2007)
2007
-
[34]
Richard H Thaler. 1988. Anomalies: The winner’s curse.Journal of economic perspectives2, 1 (1988), 191–202
1988
-
[35]
Allen Tran, Aurélien Bibaut, and Nathan Kallus. 2024. Inferring the long-term causal effects of long-term treatments from short-term experiments. InProceed- ings of the 41st International Conference on Machine Learning. 48565–48577
2024
-
[36]
Nilesh Tripuraneni, Lee Richardson, Alexander D’Amour, Jacopo Soriano, and Steve Yadlowsky. 2024. Choosing a proxy metric from past experiments. In Proceedings of the 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining. 5803–5812
2024
-
[37]
2006.Semiparametric theory and missing data
Anastasios A Tsiatis. 2006.Semiparametric theory and missing data. Vol. 4. Springer
2006
-
[38]
2000.Asymptotic statistics
Aad W Van der Vaart. 2000.Asymptotic statistics. Vol. 3. Cambridge university press
2000
-
[39]
Siruo Wang, Tyler H McCormick, and Jeffrey T Leek. 2020. Methods for correcting inference based on outcomes predicted by machine learning.Proceedings of the National Academy of Sciences117, 48 (2020), 30266–30275
2020
-
[40]
Siqi Wu and Paul Resnick. 2024. Calibrate-extrapolate: Rethinking prevalence estimation with black box classifiers. InProceedings of the International AAAI Conference on Web and Social Media, Vol. 18. 1634–1647. A Simulation parameters and ground-truth prevalence In all simulations we set 𝑃= 4. For 𝑠∈ { 1, . . . , 𝐾− 1}, we draw 𝜇𝑠 uniformly from the Eucl...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.