Recognition: unknown
3D MRI Image Pretraining via Controllable 2D Slice Navigation Task
Pith reviewed 2026-05-08 13:07 UTC · model grok-4.3
The pith
Rendering 3D MRI volumes as controllable 2D slice sequences creates an action-based self-supervision signal for pretraining.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Converting 3D MRI volumes into controllable 2D rendered sequences yields dense video-action data whose trajectories serve as intrinsic supervision; an action-conditioned objective that combines a slice tokenizer with a latent dynamics predictor then learns anatomical and spatial representations from unlabeled collections.
What carries the argument
Action-conditioned pretraining objective that pairs a tokenizer for observed slices with a latent dynamics model predicting feature evolution along action trajectories.
If this is right
- The navigation pretraining improves feature quality for segmentation and registration tasks that rely on anatomical layout.
- It scales to large unlabeled MRI collections without requiring paired labels or reconstructions.
- It serves as a complementary objective that can be combined with existing masked or contrastive losses.
- The learned dynamics model captures spatial transformations useful for downstream navigation or tracking.
Where Pith is reading between the lines
- The same slice-navigation framing could be applied to other 3D modalities such as CT without changing the core objective.
- Continuous control trajectories might support pretraining on video streams from real-time imaging devices.
- Removing action supervision entirely would isolate whether the gain comes from the sequence structure or from the explicit control signal.
Load-bearing premise
Rendering slices at continuous positions, orientations, and scales produces a self-supervision signal that is both different from and stronger than signals from static volumes or masked patches.
What would settle it
No gain on downstream anatomical or spatial tasks when the same architecture is trained without action alignment or with only discrete/static slices instead of continuous navigation trajectories.
Figures


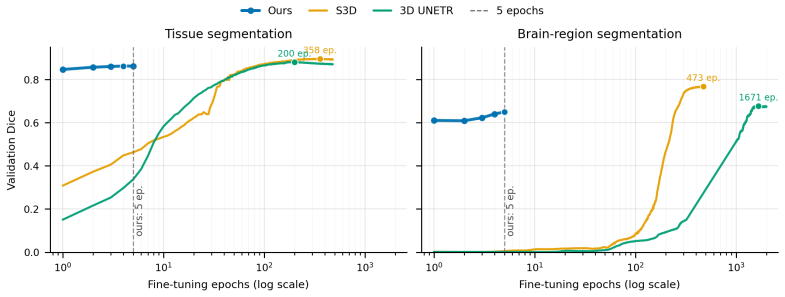


read the original abstract
Self-supervised pretraining has become the mainstream approach for learning MRI representations from unlabeled scans. However, most existing objectives still treat each scan primarily as static aggregations of slices, patches or volumes. We ask whether there exists an intrinsic form of self-supervision signal that is different from reconstructing the masked patches, through transforming the 3D volumes into controllable 2D rendered sequences: by rendering slices at continuous positions, orientations, and scales, a 3D volume can be converted into dense video-action sequences whose controls are the action trajectories. We study this formulation with an action-conditioned pretraining objective, where a tokenizer encodes slice observations and a latent dynamics model predicts the evolution of latent features. Across representative anatomical and spatial downstream tasks, the proposed pretraining is evaluated against standard static-volume baselines, tokenizer-only pretraining, and dynamics variants without aligned actions. These results suggest that controllable MRI slice navigation provides a useful complementary pretraining interface for learning anatomical and spatial representations from large unlabeled MRI collections.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a self-supervised pretraining method for 3D MRI by converting volumes into controllable 2D slice navigation sequences. Slices are rendered at continuous positions, orientations, and scales to form dense video-action pairs. A tokenizer encodes the observed slices while a latent dynamics model predicts the evolution of latent features conditioned on the navigation actions. The approach is evaluated on representative anatomical and spatial downstream tasks against static-volume baselines, tokenizer-only pretraining, and dynamics models trained without aligned actions, with the conclusion that controllable slice navigation supplies a useful complementary pretraining signal for learning from unlabeled MRI collections.
Significance. If the empirical results hold, the work introduces a navigation-based self-supervision signal that explicitly exploits the 3D spatial structure of MRI volumes through action-conditioned dynamics, offering a potential complement to existing reconstruction or masked-prediction objectives. The explicit controls over slice rendering and the comparison to unaligned dynamics variants provide a direct test of whether aligned trajectories add value, which strengthens the internal logic. This framing could encourage further exploration of dynamic, controllable interfaces for medical volume pretraining.
minor comments (2)
- The abstract states that the method is evaluated against baselines and variants but supplies no quantitative metrics, tables, or error bars. Adding at least one key result (e.g., Dice or accuracy delta on a representative downstream task) would make the central claim easier to assess at a glance.
- The description of how continuous action trajectories are sampled and rendered into aligned slice sequences would benefit from a short pseudocode block or diagram in the method section to clarify the data-generation pipeline and support reproducibility.
Simulated Author's Rebuttal
We thank the referee for the positive and accurate summary of our work, as well as for recognizing the potential value of the controllable slice navigation signal as a complement to static reconstruction objectives. The recommendation for minor revision is noted, and we will incorporate improvements to presentation and clarity in the revised manuscript.
Circularity Check
No significant circularity detected in derivation chain
full rationale
The paper formulates a new self-supervised pretraining task by converting 3D MRI volumes into controllable 2D slice navigation sequences with explicit action trajectories, then trains a tokenizer plus latent dynamics model to predict latent evolution under those actions. This objective is defined independently of downstream tasks and is tested via direct comparisons to static-volume baselines, tokenizer-only pretraining, and dynamics models lacking aligned actions. No load-bearing step reduces by construction to its own inputs: the navigation signal is generated from the volume geometry rather than fitted from target labels, and no self-citations or uniqueness theorems are invoked to force the result. The derivation remains self-contained against external empirical controls.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Pablo Acuaviva, Aram Davtyan, Mariam Hassan, Sebastian Stapf, Ahmad Rahimi, Alexandre Alahi, and Paolo Favaro. From generation to generalization: Emergent few-shot learning in video diffusion models.arXiv preprint arXiv:2506.07280, 2025
-
[2]
Computational anatomy with the spm software.Magnetic resonance imaging, 27(8):1163–1174, 2009
John Ashburner. Computational anatomy with the spm software.Magnetic resonance imaging, 27(8):1163–1174, 2009
2009
-
[3]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mahmoud Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Mojtaba Komeili, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, Sergio Arnaud, Abha Gejji, Ada Martin, Francois Robert Hogan, Daniel Dugas, Piotr Bojanowski, Vasil Khalidov, Patrick Labatut, Francisco Massa, Marc Szafraniec, Kapil Krishnakumar, Yong Li, X...
work page internal anchor Pith review arXiv 2025
-
[4]
Petersen, Yike Guo, Paul M
Wenjia Bai, Chen Chen, Giacomo Tarroni, Jinming Duan, Florian Guitton, Steffen E. Petersen, Yike Guo, Paul M. Matthews, and Daniel Rueckert. Self-supervised learning for cardiac mr image segmentation by anatomical position prediction. In Dinggang Shen, Tianming Liu, Terry M. Peters, Lawrence H. Staib, Caroline Essert, Sean Zhou, Pew-Thian Yap, and Ali Kha...
2019
-
[5]
Self-supervised learning for cardiac mr image segmentation by anatomical position prediction
Wenjia Bai, Chen Chen, Giacomo Tarroni, Jinming Duan, Florian Guitton, Steffen E Petersen, Yike Guo, Paul M Matthews, and Daniel Rueckert. Self-supervised learning for cardiac mr image segmentation by anatomical position prediction. InInternational conference on medical image computing and computer-assisted intervention, pages 541–549. Springer, 2019
2019
-
[6]
Simulation as an engine of physical scene understanding.Proceedings of the national academy of sciences, 110(45):18327– 18332, 2013
Peter W Battaglia, Jessica B Hamrick, and Joshua B Tenenbaum. Simulation as an engine of physical scene understanding.Proceedings of the national academy of sciences, 110(45):18327– 18332, 2013
2013
-
[7]
New approaches to the analysis of eye movement behaviour across expertise while viewing brain mris.Cognitive research: principles and implications, 3(1):12, 2018
Emily M Crowe, Iain D Gilchrist, and Christopher Kent. New approaches to the analysis of eye movement behaviour across expertise while viewing brain mris.Cognitive research: principles and implications, 3(1):12, 2018
2018
-
[8]
Freesurfer.Neuroimage, 62(2):774–781, 2012
Bruce Fischl. Freesurfer.Neuroimage, 62(2):774–781, 2012
2012
-
[9]
Mastering diverse control tasks through world models.Nature, pages 1–7, 2025
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse control tasks through world models.Nature, pages 1–7, 2025
2025
-
[10]
Training agents inside of scalable world models, 2025
Danijar Hafner, Wilson Yan, and Timothy Lillicrap. Training agents inside of scalable world models, 2025
2025
-
[11]
Roth, and Daguang Xu
Ali Hatamizadeh, Yucheng Tang, Vishwesh Nath, Dong Yang, Andriy Myronenko, Bennett Landman, Holger R. Roth, and Daguang Xu. Unetr: Transformers for 3d medical image segmentation. In2022 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1748–1758, 2022
2022
-
[12]
Cardiac Copilot: Automatic Probe Guidance for Echocardiography with World Model
Haojun Jiang, Zhenguo Sun, Ning Jia, Meng Li, Yu Sun, Shaqi Luo, Shiji Song, and Gao Huang. Cardiac Copilot: Automatic Probe Guidance for Echocardiography with World Model . In proceedings of Medical Image Computing and Computer Assisted Intervention – MICCAI 2024, volume LNCS 15001. Springer Nature Switzerland, October 2024
2024
-
[13]
Multispectral 3d masked autoencoders for anomaly detection in non-contrast enhanced breast mri
Daniel M Lang, Eli Schwartz, Cosmin I Bercea, Raja Giryes, and Julia A Schnabel. Multispectral 3d masked autoencoders for anomaly detection in non-contrast enhanced breast mri. InMICCAI Workshop on Cancer Prevention through Early Detection, pages 55–67. Springer, 2023
2023
-
[14]
Unityvolumerendering: A volume renderer for unity3d
Matias Lavik. Unityvolumerendering: A volume renderer for unity3d. https://github.com/ mlavik1/UnityVolumeRendering, 2019. Open-source software, MIT License, version 1.8.0
2019
-
[15]
Lowekamp, David T
Bradley C. Lowekamp, David T. Chen, Luis Ibanez, and Daniel Blezek. The design of simpleitk. Frontiers in Neuroinformatics, V olume 7 - 2013, 2013. 10
2013
-
[16]
Duy M. H. Nguyen, Hoang Nguyen, Nghiem Diep, Tan Ngoc Pham, Tri Cao, Binh Nguyen, Paul Swoboda, Nhat Ho, Shadi Albarqouni, Pengtao Xie, Daniel Sonntag, and Mathias Niepert. Lvm- med: Learning large-scale self-supervised vision models for medical imaging via second-order graph matching. In A. Oh, T. Naumann, A. Globerson, K. Saenko, M. Hardt, and S. Levine...
2023
-
[17]
Segment anything in medical images.Nature Communications, 15:654, 2024
Jun Ma, Yuting He, Feifei Li, Lin Han, Chenyu You, and Bo Wang. Segment anything in medical images.Nature Communications, 15:654, 2024
2024
-
[18]
Leworld- model: Stable end-to-end joint-embedding predictive architecture from pixels.arXiv preprint, 2026
Lucas Maes, Quentin Le Lidec, Damien Scieur, Yann LeCun, and Randall Balestriero. Leworld- model: Stable end-to-end joint-embedding predictive architecture from pixels.arXiv preprint, 2026
2026
-
[19]
arXiv preprint arXiv:2603.14482 (2026)
Lorenzo Mur-Labadia, Matthew Muckley, Amir Bar, Mahmoud Assran, Koustuv Sinha, Michael Rabbat, Yann LeCun, Nicolas Ballas, and Adrien Bardes. V-jepa 2.1: Unlocking dense features in video self-supervised learning.arXiv preprint arXiv:2603.14482, 2026
-
[20]
Temporal characteristics of radiologists’ and novices’ lesion detection in viewing medical images presented rapidly and sequentially.Frontiers in Psychology, 7:1553, 2016
Ryoichi Nakashima, Yuya Komori, Eriko Maeda, Takeharu Yoshikawa, and Kazuhiko Yokosawa. Temporal characteristics of radiologists’ and novices’ lesion detection in viewing medical images presented rapidly and sequentially.Frontiers in Psychology, 7:1553, 2016
2016
-
[21]
Van Essen, K
D.C. Van Essen, K. Ugurbil, E. Auerbach, D. Barch, T.E.J. Behrens, R. Bucholz, A. Chang, L. Chen, M. Corbetta, S.W. Curtiss, S. Della Penna, D. Feinberg, M.F. Glasser, N. Harel, A.C. Heath, L. Larson-Prior, D. Marcus, G. Michalareas, S. Moeller, R. Oostenveld, S.E. Petersen, F. Prior, B.L. Schlaggar, S.M. Smith, A.Z. Snyder, J. Xu, and E. Yacoub. The huma...
2012
-
[22]
Revisiting mae pre-training for 3d medical image segmentation
Tassilo Wald, Constantin Ulrich, Stanislav Lukyanenko, Andrei Goncharov, Alberto Paderno, Maximilian Miller, Leander Maerkisch, Paul Jaeger, and Klaus Maier-Hein. Revisiting mae pre-training for 3d medical image segmentation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5186–5196, 2025
2025
-
[23]
A generalizable 3d framework and model for self-supervised learning in medical imaging.npj Digital Medicine, 8(1):639, 2025
Tony Xu, Sepehr Hosseini, Chris Anderson, Anthony Rinaldi, Rahul G Krishnan, Anne L Martel, and Maged Goubran. A generalizable 3d framework and model for self-supervised learning in medical imaging.npj Digital Medicine, 8(1):639, 2025
2025
-
[24]
Medical world model
Yijun Yang, Zhao-Yang Wang, Qiuping Liu, Shuwen Sun, Kang Wang, Rama Chellappa, Zongwei Zhou, Alan Yuille, Lei Zhu, Yu-Dong Zhang, and Jieneng Chen. Medical world model. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 8319–8329, October 2025
2025
-
[25]
Chexworld: Exploring image world modeling for radiograph representation learning
Yang Yue, Yulin Wang, Chenxin Tao, Pan Liu, Shiji Song, and Gao Huang. Chexworld: Exploring image world modeling for radiograph representation learning. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 20778– 20788, June 2025
2025
-
[26]
Self-supervised learning framework application for medical image analysis: a review and summary.BioMedical Engineering OnLine, 23(1):107, 2024
Xiangrui Zeng, Nibras Abdullah, and Putra Sumari. Self-supervised learning framework application for medical image analysis: a review and summary.BioMedical Engineering OnLine, 23(1):107, 2024
2024
-
[27]
On the challenges and perspectives of foundation models for medical image analysis.Medical Image Analysis, 91:102996, 2024
Shaoting Zhang and Dimitris Metaxas. On the challenges and perspectives of foundation models for medical image analysis.Medical Image Analysis, 91:102996, 2024
2024
-
[28]
Self-supervised learning for medical image data with anatomy-oriented imaging planes.Medical Image Analysis, 94:103151, 2024
Tianwei Zhang, Dong Wei, Mengmeng Zhu, Shi Gu, and Yefeng Zheng. Self-supervised learning for medical image data with anatomy-oriented imaging planes.Medical Image Analysis, 94:103151, 2024
2024
-
[29]
Deep reinforcement learning in medical imaging: A literature review.Medical image analysis, 73:102193, 2021
S Kevin Zhou, Hoang Ngan Le, Khoa Luu, Hien V Nguyen, and Nicholas Ayache. Deep reinforcement learning in medical imaging: A literature review.Medical image analysis, 73:102193, 2021. 11
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.