Recognition: unknown
Operator-Guided Invariance Learning for Continuous Reinforcement Learning
Pith reviewed 2026-05-08 12:41 UTC · model grok-4.3
The pith
Value-preserving structures in continuous RL exist exactly when Lie group operators commute with the controlled generator and reward functional.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
A value-preserving structure exists exactly when pulling back the value function and pushing forward actions commute with the controlled generator and reward functional. Approximate value-preserving structures with rigorous guarantees can be found when the Hamilton-Jacobi-Bellman mismatch is small. These structures are discovered by searching associated Lie group operators, fitting differentiable drift, diffusion, and reward models, learning infinitesimal generators via determining-equation residual minimization, exponentiating them with ODE flows to obtain finite transformations, and integrating the results into continuous RL through transition augmentation and transformation-consistency
What carries the argument
Lie-group actions whose pullback on the value function and pushforward on actions commute with the controlled diffusion generator and the reward functional.
If this is right
- When the commutation condition holds exactly, any transformed trajectory preserves the same optimal value function as the original system.
- When the mismatch is small, the deviation in optimal value along approximate orbits remains bounded by a quantity that grows with the effective horizon length.
- The discovered transformations can be inserted into training by augmenting transitions and adding a consistency regularizer without destroying optimality.
- The same search procedure recovers both exact symmetries and more general nonlinear mappings between systems that share isomorphic value functions.
Where Pith is reading between the lines
- The same commutation-based search could be applied to discrete-time RL or model-based planning to discover analogous structures without continuous-time assumptions.
- If the method reliably recovers known physical symmetries in robotic systems, it would provide an unsupervised way to extract domain knowledge that is currently hand-engineered.
- Combining the discovered operators with existing representation-learning objectives might yield richer invariances that further reduce sample complexity.
- Testing the approach on environments with deliberately introduced but unknown shifts would quantify how much robustness is actually gained in practice.
Load-bearing premise
A small mismatch in the learned generator or reward implies that the optimal value function changes only modestly when states and actions are transformed along the approximate orbits generated by the discovered operators, with the size of the change governed by the effective horizon.
What would settle it
A controlled experiment in which the Hamilton-Jacobi-Bellman mismatch is measured to be small yet the value function evaluated along the orbits of the discovered Lie operators deviates from the original optimal value by more than the horizon-dependent bound predicted by the stability result.
Figures



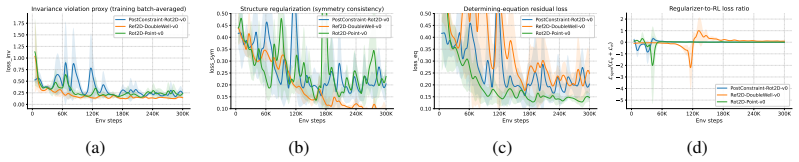
read the original abstract
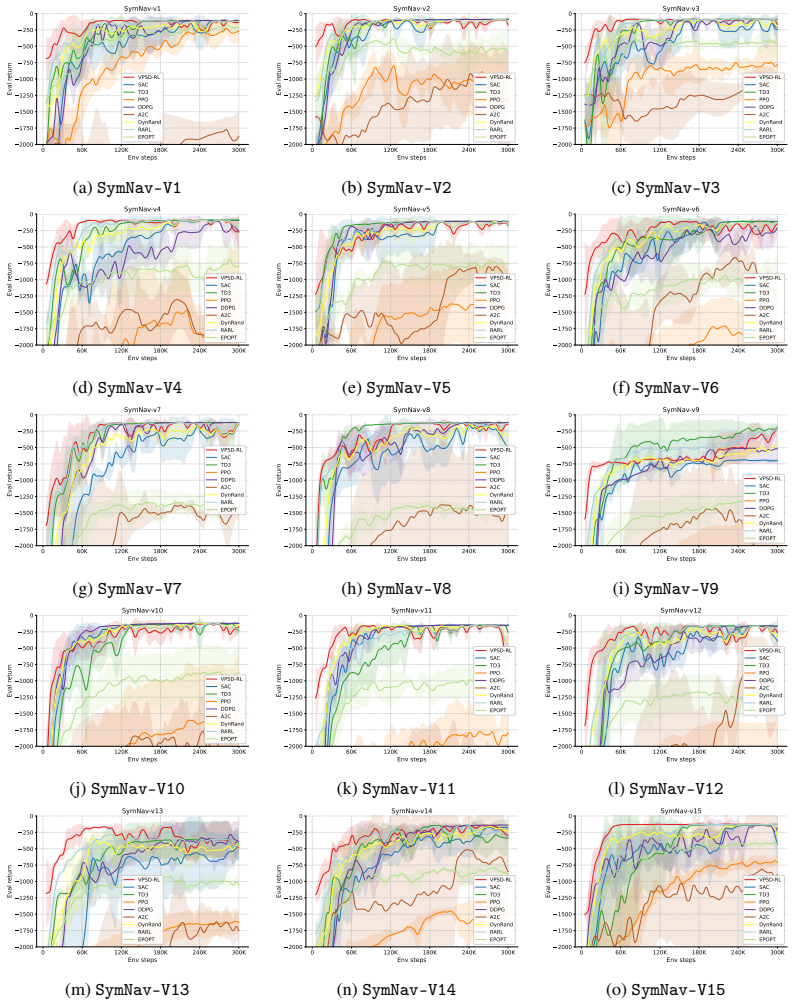
Reinforcement learning (RL) with continuous time and state/action spaces is often data-intensive and brittle under nuisance variability and shift, motivating methods that exploit value-preserving structures to stabilize and improve learning. Most existing approaches focus on special cases, such as prescribed symmetries and exact equivariance, without addressing how to discover more general structures that require nonlinear operators to transform and map between continuous state/action systems with isomorphic value functions. We propose \textbf{VPSD-RL} (Value-Preserving Structure Discovery for Reinforcement Learning). It models continuous RL as a controlled diffusion with value-preserving mappings defined through Lie-group actions and associated pullback operators. We show that a value-preserving structure exists exactly when pulling back the value function and pushing forward actions commute with the controlled generator and reward functional. Further, approximate value-preserving structures with rigorous guarantees can be found when the Hamilton--Jacobi--Bellman mismatch is small. This framework discovers exact and approximate value-preserving structures by searching for the associated Lie group operators. VPSD-RL fits differentiable drift, diffusion, and reward models; learns infinitesimal generators via determining-equation residual minimization; exponentiates them with ODE flows to obtain finite transformations; and integrates them into continuous RL through transition augmentation and transformation-consistency regularization. We show that bounded generator/reward mismatch implies quantitative stability of the optimal value function along approximate orbits, with sensitivity governed by the effective horizon, and observe improved data efficiency and robustness on continuous-control benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VPSD-RL, a framework for discovering value-preserving structures in continuous-time, continuous-space RL via Lie-group operators and pullback/pushforward actions on controlled diffusions. It claims an exact characterization: value-preserving structures exist precisely when the pullback of the value function and pushforward of actions commute with the controlled generator and reward functional. For the approximate case, it asserts that small Hamilton-Jacobi-Bellman mismatch yields structures with rigorous guarantees because bounded generator/reward mismatch implies quantitative stability of the optimal value along approximate orbits, with the constant governed by effective horizon. The method fits differentiable drift/diffusion/reward models, learns infinitesimal generators by residual minimization on determining equations, exponentiates via ODE flows to finite transformations, and incorporates them into RL via transition augmentation and consistency regularization. Experiments reportedly demonstrate improved data efficiency and robustness on continuous-control benchmarks.
Significance. If the exact commutation condition and the approximate stability result hold with practically useful constants, the work would offer a principled, operator-guided route to discovering general (non-prescribed) invariances in continuous RL, potentially reducing data requirements and improving robustness under nuisance variability without relying on hand-crafted symmetries.
major comments (2)
- [abstract (approximate value-preserving structures paragraph) and the stability theorem] The load-bearing claim for approximate structures is that 'bounded generator/reward mismatch implies quantitative stability of the optimal value function along approximate orbits, with sensitivity governed by the effective horizon' (abstract). In continuous-time controlled diffusions this bound is typically obtained via Gronwall or viscosity estimates on the HJB PDE and takes the form O(mismatch × effective horizon). For the discount factors near 1 that are standard in the reported benchmarks, the horizon factor diverges, rendering the guarantee non-informative even for tiny mismatch. The manuscript must supply the explicit constant, the precise statement of the theorem, and a discussion of when the bound remains useful.
- [method description (fitting and generator learning steps)] The method first fits drift, diffusion, and reward models from data and then minimizes residuals of the determining equations on those fitted models to learn the generators. This raises a circularity concern: the discovered 'value-preserving structures' may simply reproduce properties already encoded in the fitted models rather than revealing independent structure of the underlying system. The manuscript should clarify the separation between fitting error and the residual minimization step and provide an ablation isolating the contribution of the Lie-group search.
minor comments (2)
- [abstract] The abstract is dense and introduces several technical terms (VPSD-RL, pullback operators, determining-equation residual minimization, transition augmentation) without brief definitions or forward references; a short glossary or expanded first paragraph would improve accessibility.
- [preliminaries / notation] Notation for the controlled generator, reward functional, and Lie-group actions is used without an early consolidated table or section; readers must hunt through the text to recall definitions when checking the commutation condition.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments identify important areas for clarification and strengthening, particularly around the stability guarantees and methodological separation. We address each major comment below and will incorporate revisions to improve the manuscript.
read point-by-point responses
-
Referee: [abstract (approximate value-preserving structures paragraph) and the stability theorem] The load-bearing claim for approximate structures is that 'bounded generator/reward mismatch implies quantitative stability of the optimal value function along approximate orbits, with sensitivity governed by the effective horizon' (abstract). In continuous-time controlled diffusions this bound is typically obtained via Gronwall or viscosity estimates on the HJB PDE and takes the form O(mismatch × effective horizon). For the discount factors near 1 that are standard in the reported benchmarks, the horizon factor diverges, rendering the guarantee non-informative even for tiny mismatch. The manuscript must supply the explicit constant, the precise statement of the theorem, and a discussion of when the bound remains useful.
Authors: We agree that the stability result requires a more explicit and self-contained presentation. The bound is obtained via Gronwall's inequality on the controlled HJB equation under standard Lipschitz assumptions on the generator and reward, yielding a quantitative stability estimate of the form C · mismatch · (1 − γ)^(−1), where C depends on the Lipschitz constants and the effective horizon is 1/(1 − γ). We acknowledge that the constant becomes large as γ → 1. In the revision we will (i) state the theorem precisely in the main text with the explicit dependence on the constants, (ii) add a short discussion subsection analyzing the regimes in which the bound remains informative (e.g., γ ≤ 0.99 and sufficiently small mismatch), and (iii) report the effective horizons corresponding to the discount factors used in the experiments together with a sensitivity plot showing bound tightness for the observed mismatch levels. revision: yes
-
Referee: [method description (fitting and generator learning steps)] The method first fits drift, diffusion, and reward models from data and then minimizes residuals of the determining equations on those fitted models to learn the generators. This raises a circularity concern: the discovered 'value-preserving structures' may simply reproduce properties already encoded in the fitted models rather than revealing independent structure of the underlying system. The manuscript should clarify the separation between fitting error and the residual minimization step and provide an ablation isolating the contribution of the Lie-group search.
Authors: The referee correctly flags an expository gap. The model-fitting stage learns a parametric approximation of the drift, diffusion, and reward from data; the subsequent residual-minimization stage solves the determining equations (derived from the exact commutation conditions) on this parametric model. These two steps are conceptually distinct: the determining equations encode the value-preservation requirement independently of any particular fitted parameters. Nevertheless, to eliminate ambiguity we will expand the method section with an explicit error-propagation argument separating fitting error from generator residual, and we will add an ablation that compares VPSD-RL against (a) a version using randomly sampled generators and (b) a version that skips the Lie-group search entirely, thereby isolating the contribution of the operator discovery step. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper defines value-preserving structures via Lie-group actions and pullback operators on controlled diffusions, then states an exact existence condition as commutation of pullback/pushforward with the generator and reward. This is a direct definitional equivalence rather than a derived prediction from fitted quantities. The approximate case invokes a general stability implication from bounded HJB mismatch (governed by effective horizon), which is a standard PDE estimate and not constructed from the paper's model-fitting procedure. The algorithmic steps (fitting drift/diffusion/reward, residual minimization for generators, ODE exponentiation) are presented as a practical discovery method separate from the theoretical claims. No self-citations, ansatzes smuggled via prior work, or renamings of known results are present that reduce the central results to inputs by construction. The derivation chain stands on the mathematical setup of continuous-time RL without reduction to fitted parameters.
Axiom & Free-Parameter Ledger
free parameters (1)
- infinitesimal generators
axioms (2)
- domain assumption A value-preserving structure exists exactly when pullback of value function and pushforward of actions commute with the controlled generator and reward functional
- domain assumption Bounded generator/reward mismatch implies quantitative stability of the optimal value function along approximate orbits
invented entities (1)
-
VPSD-RL framework
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Matrix-Space Reinforcement Learning for Reusing Local Transition Geometry
MSRL represents trajectory segments as PSD matrices to prove additive composition properties and bootstrap value functions for better transfer, reaching 0.73 AUC versus 0.57-0.65 baselines.
Reference graph
Works this paper leans on
-
[1]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review arXiv
-
[2]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Sergey Levine, Aviral Kumar, George Tucker, and Justin Fu. Offline reinforcement learning: Tutorial, review, and perspectives on open problems.arXiv preprint arXiv:2005.01643,
work page internal anchor Pith review arXiv 2005
-
[3]
Zuyuan Zhang, Sizhe Tang, and Tian Lan. Cochain perspectives on temporal-difference signals for learning beyond markov dynamics.arXiv preprint arXiv:2602.06939, 2026a. Zuyuan Zhang, Mahdi Imani, and Tian Lan. Geometry of drifting mdps with path-integral stability certificates. arXiv preprint arXiv:2601.21991, 2026b. Zuyuan Zhang, Zeyu Fang, and Tian Lan. ...
-
[4]
arXiv preprint arXiv:2107.09645 , year=
Misha Laskin, Kimin Lee, Adam Stooke, Lerrel Pinto, Pieter Abbeel, and Aravind Srinivas. Reinforcement learning with augmented data.Advances in neural information processing systems, 33:19884–19895, 2020a. 10 Denis Yarats, Rob Fergus, Alessandro Lazaric, and Lerrel Pinto. Mastering visual continuous control: Improved data-augmented reinforcement learning....
-
[5]
Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges
Michael M Bronstein, Joan Bruna, Taco Cohen, and Petar Veliˇckovi´c. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges.arXiv preprint arXiv:2104.13478,
work page internal anchor Pith review arXiv
-
[6]
Invariant and equivariant graph networks.arXiv:1812.09902,
Haggai Maron, Heli Ben-Hamu, Nadav Shamir, and Yaron Lipman. Invariant and equivariant graph networks. arXiv preprint arXiv:1812.09902,
-
[7]
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440,
work page internal anchor Pith review arXiv
-
[8]
Dream to Control: Learning Behaviors by Latent Imagination
Danijar Hafner, Timothy Lillicrap, Jimmy Ba, and Mohammad Norouzi. Dream to control: Learning behaviors by latent imagination.arXiv preprint arXiv:1912.01603,
work page internal anchor Pith review arXiv 1912
-
[9]
arXiv preprint arXiv:1610.01283 , year=
Aravind Rajeswaran, Sarvjeet Ghotra, Balaraman Ravindran, and Sergey Levine. Epopt: Learning robust neural network policies using model ensembles.arXiv preprint arXiv:1610.01283,
-
[10]
Greg Brockman, Vicki Cheung, Ludwig Pettersson, Jonas Schneider, John Schulman, Jie Tang, and Wojciech Zaremba. Openai gym.arXiv preprint arXiv:1606.01540,
work page internal anchor Pith review arXiv
-
[11]
Network diffuser for placing-scheduling service function chains with inverse demonstration
Zuyuan Zhang, Mahdi Imani, and Tian Lan. Modeling other players with bayesian beliefs for games with incomplete information.arXiv preprint arXiv:2405.14122,
-
[12]
Network diffuser for placing-scheduling service function chains with inverse demonstration
Zuyuan Zhang, Vaneet Aggarwal, and Tian Lan. Network diffuser for placing-scheduling service function chains with inverse demonstration. InIEEE INFOCOM 2025-IEEE Conference on Computer Communications, pages 1–10. IEEE, 2025b. Zuyuan Zhang and Tian Lan. Lipschitz lifelong monte carlo tree search for mastering non-stationary tasks. arXiv preprint arXiv:2502.00633,
-
[13]
Tail-risk-safe monte carlo tree search under pac-level guarantees
Zuyuan Zhang, Arnob Ghosh, and Tian Lan. Tail-risk-safe monte carlo tree search under pac-level guarantees. arXiv preprint arXiv:2508.05441, 2025c. Zeyu Fang, Zuyuan Zhang, Mahdi Imani, and Tian Lan. Manifold-constrained energy-based transition models for offline reinforcement learning.arXiv preprint arXiv:2602.02900,
-
[14]
Br-defedrl: Byzantine-robust decentralized federated reinforcement learning with fast convergence and communication efficiency
Jing Qiao, Zuyuan Zhang, Sheng Yue, Yuan Yuan, Zhipeng Cai, Xiao Zhang, Ju Ren, and Dongxiao Yu. Br-defedrl: Byzantine-robust decentralized federated reinforcement learning with fast convergence and communication efficiency. InIEEE infocom 2024-IEEE conference on computer communications, pages 141–150. IEEE,
2024
-
[15]
Zuyuan Zhang, Vaneet Aggarwal, and Tian Lan. Lisfc-search: Lifelong search for network sfc optimization under non-stationary drifts.arXiv preprint arXiv:2602.14360, 2026d. Sizhe Tang, Jiayu Chen, and Tian Lan. Malinzero: Efficient low-dimensional search for mastering complex multi-agent planning.arXiv preprint arXiv:2511.06142,
-
[16]
Sizhe Tang, Rongqian Chen, and Tian Lan. Agent alpha: Tree search unifying generation, exploration and evaluation for computer-use agents.arXiv preprint arXiv:2602.02995,
-
[17]
Yu Li, Sizhe Tang, Rongqian Chen, Fei Xu Yu, Guangyu Jiang, Mahdi Imani, Nathaniel D Bastian, and Tian Lan. Acdzero: Graph-embedding-based tree search for mastering automated cyber defense.arXiv preprint arXiv:2601.02196,
-
[18]
(We optionally include a compact table of map/goal/wind parameters per variant in the released appendix PDF.) Training details.All methods use the same observation preprocessing, episode truncation, and evaluation protocol. Per-method hyperparameters (optimizer, learning rate, batch size, replay set- tings for off-policy methods, etc.) and the exact seed ...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.