Recognition: unknown
Learning to Cut: Reinforcement Learning for Benders Decomposition
Pith reviewed 2026-05-08 08:04 UTC · model grok-4.3
The pith
Reinforcement learning selects effective cuts to accelerate Benders decomposition for stochastic programs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
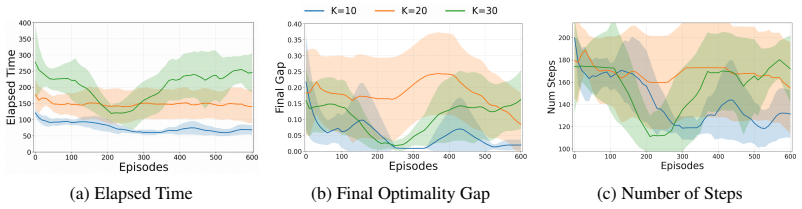
RLBD adapts cut selection in Benders decomposition using a stochastic policy parameterized by a neural network and trained via REINFORCE. Numerical experiments on the two-stage stochastic electric vehicle charging station location problem demonstrate substantial improvements in computational efficiency over vanilla BD and LearnBD. The method also shows strong generalization capabilities to instances with similar structure but different data inputs and decision variable dimensions.
What carries the argument
A neural network that outputs a stochastic policy for selecting cuts, trained by the REINFORCE algorithm to minimize expected solution time in Benders decomposition.
Load-bearing premise
The benefits from faster solving during inference outweigh the upfront cost of training the policy network, and the policy generalizes beyond the electric vehicle test instances used for training.
What would settle it
If the RLBD method requires more total time including training or fails to reduce iterations on a held-out set of problems with different uncertainty distributions, the efficiency claim would not hold.
Figures




read the original abstract
Benders decomposition (BD) is a widely used solution approach for solving two-stage stochastic programs arising in real-world decision-making under uncertainty. However, it often suffers from slow convergence as the master problem grows with an increasing number of cuts. In this paper, we propose Reinforcement Learning for BD (RLBD), a framework that adaptively selects cuts using a neural network-based stochastic policy. The policy is trained using a policy gradient method via the REINFORCE algorithm. We evaluate the proposed approach on a two-stage stochastic electric vehicle charging station location problem and compare it with vanilla BD and LearnBD, a supervised learning approach that classifies cuts using a support vector machine. Numerical results demonstrate that RLBD achieves substantial improvements in computational efficiency and exhibits strong generalization to problems with similar structures but varying data inputs and decision variable dimensions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RLBD, a reinforcement learning framework that trains a neural network policy via REINFORCE to adaptively select cuts during Benders decomposition for two-stage stochastic programs. It is evaluated on a two-stage stochastic electric vehicle charging station location problem, where it is compared to vanilla BD and LearnBD (an SVM-based supervised approach), with claims of substantial computational efficiency gains and strong generalization to instances with similar structure but varying data inputs and decision variable dimensions.
Significance. If the empirical claims hold with proper controls, the work offers a novel RL-based mechanism for improving cut selection in Benders decomposition, which could reduce iteration counts and solve times for large-scale stochastic optimization problems common in energy and logistics applications. The policy-gradient training approach is a reasonable extension of existing learning-for-optimization ideas, though its practical impact depends on whether training overhead is amortized and whether the policy transfers beyond the single test family.
major comments (2)
- [Abstract] Abstract: The central claim of 'strong generalization to problems with similar structures but varying data inputs and decision variable dimensions' is load-bearing for the paper's practical contribution, yet the described experiments are confined to the electric-vehicle charging instance family. No quantitative results, problem sizes, or architecture details (e.g., input feature construction or use of GNN/permutation-invariant layers) are supplied to show that the policy network can be applied to instances with different numbers of decision variables without retraining or ad-hoc padding.
- [Abstract] Abstract and evaluation description: No quantitative metrics, statistical tests, problem dimensions, training hyperparameters, or wall-clock comparisons (including policy training cost) are provided to support the asserted 'substantial improvements in computational efficiency.' This absence prevents verification of whether the RL policy actually outperforms the baselines on the reported instances or merely fits the training distribution.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address the major points below and will revise the manuscript accordingly to strengthen the presentation of our results and claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'strong generalization to problems with similar structures but varying data inputs and decision variable dimensions' is load-bearing for the paper's practical contribution, yet the described experiments are confined to the electric-vehicle charging instance family. No quantitative results, problem sizes, or architecture details (e.g., input feature construction or use of GNN/permutation-invariant layers) are supplied to show that the policy network can be applied to instances with different numbers of decision variables without retraining or ad-hoc padding.
Authors: We agree that the abstract would benefit from additional detail on these aspects. The full manuscript evaluates the policy on the EV charging family across multiple instance sizes, including varying numbers of charging stations (decision variables) and scenarios, without retraining the policy. The network uses a fixed set of aggregated structural features (e.g., statistics over candidate cuts and scenario costs) that are independent of exact dimension, enabling direct transfer. We will revise the abstract to report specific problem dimensions tested, quantitative generalization metrics (e.g., performance on held-out sizes), and a concise description of the feature construction and network architecture. revision: yes
-
Referee: [Abstract] Abstract and evaluation description: No quantitative metrics, statistical tests, problem dimensions, training hyperparameters, or wall-clock comparisons (including policy training cost) are provided to support the asserted 'substantial improvements in computational efficiency.' This absence prevents verification of whether the RL policy actually outperforms the baselines on the reported instances or merely fits the training distribution.
Authors: The full paper reports iteration counts, solve times, and direct comparisons to vanilla BD and LearnBD on the EV instances, with the RL policy showing lower iteration counts and faster overall solution times. We acknowledge that the abstract omits these specifics along with hyperparameters and training overhead. We will revise the abstract to include key quantitative results (e.g., average reductions in iterations and wall-clock time), problem dimensions, a note on multiple random seeds for statistical reliability, and clarification that reported times include amortized training cost, which is offset by repeated use on similar instances. revision: yes
Circularity Check
No circularity: empirical RL training and held-out evaluation are independent of claimed results
full rationale
The paper trains a stochastic policy via REINFORCE on electric-vehicle instances and reports speedups plus generalization on separate test instances with varying inputs and dimensions. No derivation step reduces a 'prediction' to a fitted parameter by construction, no self-definitional equations appear, and no load-bearing claim rests on self-citation. The numerical improvements are direct experimental outcomes on held-out data, satisfying the self-contained benchmark criterion.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network architecture and training hyperparameters
axioms (1)
- standard math REINFORCE policy gradient converges under standard conditions on the MDP formulation of cut selection
Reference graph
Works this paper leans on
-
[1]
Transportation Science , volume=
Benders adaptive-cuts method for two-stage stochastic programs , author=. Transportation Science , volume=. 2023 , publisher=
2023
-
[2]
Transportation Science , volume=
Benders decomposition for the design of a hub and shuttle public transit system , author=. Transportation Science , volume=. 2019 , publisher=
2019
-
[3]
Operations Research , volume=
Benders decomposition for production routing under demand uncertainty , author=. Operations Research , volume=. 2015 , publisher=
2015
-
[4]
SIAM Journal on Applied Mathematics , volume=
L-shaped linear programs with applications to optimal control and stochastic programming , author=. SIAM Journal on Applied Mathematics , volume=. 1969 , publisher=
1969
-
[5]
Reinforcement learning for integer programming:
Tang, Yunhao and Agrawal, Shipra and Faenza, Yuri , booktitle=. Reinforcement learning for integer programming:. 2020 , organization=
2020
-
[6]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Learning to branch in mixed integer programming , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[7]
Advances in Neural Information Processing Systems , volume=
Combinatorial optimization with graph convolutional networks and guided tree search , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
Advances in Neural Information Processing Systems , volume=
Learning combinatorial optimization algorithms over graphs , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
Machine learning for combinatorial optimization:
Bengio, Yoshua and Lodi, Andrea and Prouvost, Antoine , journal=. Machine learning for combinatorial optimization:. 2021 , publisher=
2021
-
[10]
Tabu search and
Easwaran, Gopalakrishnan and. Tabu search and. Transportation Science , volume=. 2009 , publisher=
2009
-
[11]
Management Science , volume=
Multicommodity distribution system design by Benders decomposition , author=. Management Science , volume=. 1974 , publisher=
1974
-
[12]
Improving
Poojari, Chandra A and Beasley, John E , journal=. Improving. 2009 , publisher=
2009
-
[13]
2011 , publisher=
Introduction to Stochastic Programming , author=. 2011 , publisher=
2011
-
[14]
Energy , volume=
Two-stage stochastic programming model for optimal scheduling of the wind-thermal-hydropower-pumped storage system considering the flexibility assessment , author=. Energy , volume=. 2020 , publisher=
2020
-
[15]
IEEE Transactions on Power Systems , volume=
A chance-constrained two-stage stochastic program for unit commitment with uncertain wind power output , author=. IEEE Transactions on Power Systems , volume=. 2011 , publisher=
2011
-
[16]
Management Science , volume=
Mixed-integer rounding enhanced benders decomposition for multiclass service-system staffing and scheduling with arrival rate uncertainty , author=. Management Science , volume=. 2017 , publisher=
2017
-
[17]
Computers & Operations Research , volume=
Time window optimization for attended home service delivery under multiple sources of uncertainties , author=. Computers & Operations Research , volume=. 2023 , publisher=
2023
-
[18]
Service Science , volume=
Integrated vehicle routing and service scheduling under time and cancellation uncertainties with application in nonemergency medical transportation , author=. Service Science , volume=. 2021 , publisher=
2021
-
[19]
Computers & Operations Research , volume=
Resource distribution under spatiotemporal uncertainty of disease spread: Stochastic versus robust approaches , author=. Computers & Operations Research , volume=. 2023 , publisher=
2023
-
[20]
Hybrid robust and stochastic optimization for closed-loop supply chain network design using accelerated
Keyvanshokooh, Esmaeil and Ryan, Sarah M and Kabir, Elnaz , journal=. Hybrid robust and stochastic optimization for closed-loop supply chain network design using accelerated. 2016 , publisher=
2016
-
[21]
Redesigning
Fischetti, Matteo and Ljubi. Redesigning. Management Science , volume=. 2017 , publisher=
2017
-
[22]
European Journal of Operational Research , volume=
Benders decomposition without separability: A computational study for capacitated facility location problems , author=. European Journal of Operational Research , volume=. 2016 , publisher=
2016
-
[23]
A Note on the Selection of
Fischetti, Matteo and Salvagnin, Domenico and Zanette, Andrea , journal=. A Note on the Selection of. 2017 , publisher=
2017
-
[24]
and Wong, Richard T
Magnanti, Thomas L. and Wong, Richard T. , journal=. Accelerating. 1981 , publisher=
1981
-
[25]
Learning to Optimize at Scale:
Choi, Seung Jin and Jozani, Kimiya and Cooper, Joshua F and Buyuktahtakin, I Esra , booktitle=. Learning to Optimize at Scale:
-
[26]
arXiv preprint arXiv:1606.01885 , year=
Learning to Optimize , author=. arXiv preprint arXiv:1606.01885 , year=
-
[27]
International Conference on Learning Representations (ICLR) , year=
Neural Combinatorial Optimization with Reinforcement Learning , author=. International Conference on Learning Representations (ICLR) , year=
-
[28]
OR-Gym: A Reinforcement Learning Library for Operations Research Problems , author=. arXiv preprint arXiv:2008.06319 , year=
-
[29]
Aslani, Babak and Mohebbi, Shima and Ji, Ran , title =. 2025 , month = dec, note =. doi:10.2139/ssrn.5895134 , url =
-
[30]
Advances in Neural Information Processing Systems , year =
A Deep Reinforcement Learning Framework for Column Generation , author =. Advances in Neural Information Processing Systems , year =
-
[31]
Benders, J. F. , title =. Numerische Mathematik , volume =. 1962 , doi =
1962
-
[32]
INFORMS Journal on Optimization , volume =
Benders Cut Classification via Support Vector Machines for Solving Two-Stage Stochastic Programs , author =. INFORMS Journal on Optimization , volume =
-
[33]
and Mitrai, Ilias and Daoutidis, Prodromos , journal =
Li, Zhe and Agyeman, Bernard T. and Mitrai, Ilias and Daoutidis, Prodromos , journal =. Learning to Control Inexact
-
[34]
Accelerating
Mana, Kyle and Mak, Stephen and Zehtabi, Parisa and Cashmore, Michael and Magazzeni, Daniele and Veloso, Manuela , booktitle =. Accelerating
-
[35]
Machine Learning , volume=
Simple Statistical Gradient-Following Algorithms for Connectionist Reinforcement Learning , author=. Machine Learning , volume=
-
[36]
Advances in Neural Information Processing Systems (NeurIPS) , year=
Policy Gradient Methods for Reinforcement Learning with Function Approximation , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[37]
2018 , publisher=
Reinforcement Learning: An Introduction , author=. 2018 , publisher=
2018
-
[38]
and Conejo, A
Alguacil, N. and Conejo, A. J. , title =. IEEE Transactions on Power Systems , year =
-
[39]
A Benders Decomposition Approach for the Charging Station Location Problem with Plug-in Hybrid Electric Vehicles , journal =
Arslan, Okan and Kara. A Benders Decomposition Approach for the Charging Station Location Problem with Plug-in Hybrid Electric Vehicles , journal =. 2016 , volume =
2016
-
[40]
Available at SSRN 5078715 , year=
Contextual stochastic optimization for determining electric vehicle charging station locations with decision-dependent demand learning , author=. Available at SSRN 5078715 , year=
-
[41]
IIE Transactions , volume =
Facility Location Under Uncertainty: A Review , author =. IIE Transactions , volume =. 2006 , publisher =
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.