Recognition: unknown
On the Implicit Reward Overfitting and the Low-rank Dynamics in RLVR
Pith reviewed 2026-05-08 12:35 UTC · model grok-4.3
The pith
RLVR exhibits implicit reward overfitting, enabling strong test performance even when training rewards stay low due to concentration in rank-1 components.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
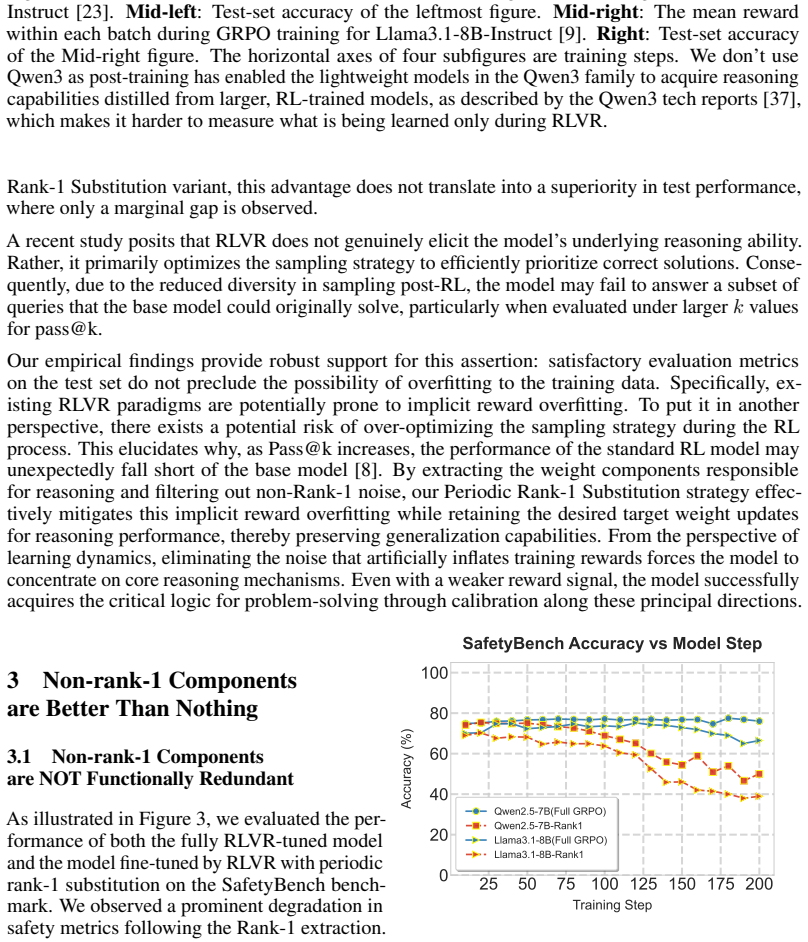
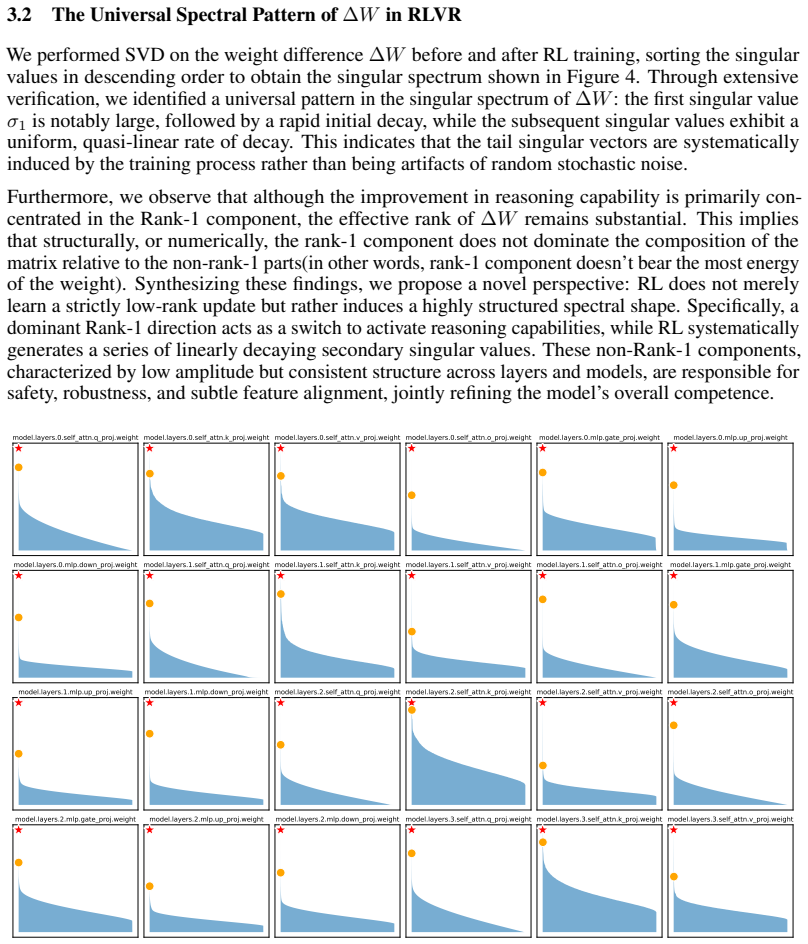
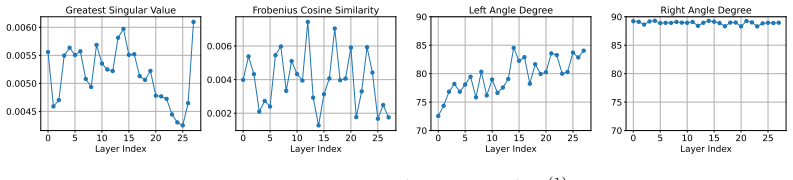
Predicated on the observation that enhanced reasoning capabilities acquired by models through RLVR are primarily concentrated within the rank-1 components, Periodic Rank-1 Substitution reveals that RLVR may exhibit implicit reward overfitting to the training dataset. Specifically, the model can achieve satisfactory performance on the test set even when its rewards remain relatively low during the training process. The effective rank-1 component maintains only mathematical reasoning capability and no other model knowledge. RLVR optimizes a specific singular spectrum such that the distribution of singular values of almost all linear layers behaves like a heavy-tailed distribution. The left-sin
What carries the argument
Periodic Rank-1 Substitution, the operation that periodically replaces higher-rank components with their rank-1 approximations to isolate how low-rank structure drives reward dynamics and test generalization.
If this is right
- The rank-1 component in an RLVR-trained model retains only mathematical reasoning and discards other forms of knowledge.
- RLVR training produces heavy-tailed singular-value distributions across nearly all linear layers.
- Left singular vectors tied to the rank-1 components exhibit stronger alignment as training proceeds.
- These parameter changes supply concrete directions for redesigning RL methods to support continual learning.
Where Pith is reading between the lines
- The same low-rank concentration may appear whenever rewards are computed by an external verifier rather than being dense and human-designed.
- Periodic replacement or diversification of rank-1 components could be tested as a way to preserve broader capabilities while still harvesting reasoning gains.
- Tracking the alignment of left singular vectors might give an early signal of when the model has begun to overfit its reward signal.
Load-bearing premise
That Periodic Rank-1 Substitution isolates the overfitting effect without introducing artifacts that themselves alter the observed reward dynamics or test performance.
What would settle it
If models trained with RLVR under Periodic Rank-1 Substitution display both persistently low training rewards and correspondingly reduced test performance, rather than retaining high test accuracy, the implicit-overfitting claim would be falsified.
Figures










read the original abstract
Recent extensive research has demonstrated that the enhanced reasoning capabilities acquired by models through Reinforcement Learning with Verifiable Rewards (RLVR) are primarily concentrated within the rank-1 components. Predicated on this observation, we employed Periodic Rank-1 Substitution and identified a counterintuitive phenomenon: RLVR may exhibit implicit reward overfitting to the training dataset. Specifically, the model can achieve satisfactory performance on the test set even when its rewards remain relatively low during the training process. Furthermore, we characterize three distinct properties of RL training: (1) The effective rank-1 component in RLVR don't maintain other model knowledge except mathematical reasoning capability. (2) RLVR fundamentally functions by optimizing a specific singular spectrum. The distribution of singular values of almost all linear layers in RLVR-trained model behaves like heavy-tailed distribution. (3) the left singular vectors associated with rank-1 components demonstrate a stronger alignment tendency during training, which echoes the discovery that RLVR is optimizing sampling efficiency in essence. Taken together, our findings and analysis further reveal how RLVR shapes model parameters and offer potential insights for improving existing RL paradigms or other training paradigms to implement continual learning.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that RLVR exhibits implicit reward overfitting to the training dataset, as models achieve satisfactory test-set performance despite relatively low training rewards; this is observed via Periodic Rank-1 Substitution. It further characterizes three properties of RL training: (1) the effective rank-1 component preserves only mathematical reasoning capability, (2) RLVR optimizes a heavy-tailed singular spectrum across linear layers, and (3) left singular vectors of rank-1 components exhibit stronger alignment during training, interpreted as optimization of sampling efficiency.
Significance. If the observations are shown to be robust to controls and not artifacts of the substitution procedure, the work could provide useful empirical insights into the low-rank mechanisms underlying RLVR's reasoning gains and suggest directions for designing RL methods that reduce overfitting while supporting continual learning.
major comments (2)
- [Abstract] Abstract: The central claim of implicit reward overfitting and the three listed properties rest entirely on observations obtained under Periodic Rank-1 Substitution, yet the abstract supplies no experimental details, controls, baselines, statistical tests, or ablation results that would demonstrate the substitution isolates overfitting without independently altering reward dynamics or test performance.
- [Abstract] The weakest assumption is that Periodic Rank-1 Substitution preserves the original RLVR reward dynamics and generalization behavior; without explicit controls (e.g., standard RLVR runs or ablation of the substitution schedule) showing that the intervention does not itself suppress measured rewards or inflate test scores, the reported mismatch between training rewards and test performance cannot be attributed to RLVR rather than the experimental procedure.
minor comments (1)
- [Abstract] The abstract would benefit from a concise definition or reference for 'Periodic Rank-1 Substitution' on first use.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our manuscript. The comments highlight important points about the presentation of our central claims in the abstract and the assumptions underlying Periodic Rank-1 Substitution. We address each major comment below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of implicit reward overfitting and the three listed properties rest entirely on observations obtained under Periodic Rank-1 Substitution, yet the abstract supplies no experimental details, controls, baselines, statistical tests, or ablation results that would demonstrate the substitution isolates overfitting without independently altering reward dynamics or test performance.
Authors: We agree that the abstract, constrained by length, does not detail the experimental controls or ablations. The full manuscript describes the Periodic Rank-1 Substitution procedure in detail (Section 3), including comparisons to standard RLVR runs and ablations of the substitution schedule that confirm it does not independently suppress training rewards or inflate test performance. To address the concern, we will revise the abstract to briefly reference the substitution method and note that its validity is supported by the controls and statistical comparisons reported in the experimental sections. revision: yes
-
Referee: [Abstract] The weakest assumption is that Periodic Rank-1 Substitution preserves the original RLVR reward dynamics and generalization behavior; without explicit controls (e.g., standard RLVR runs or ablation of the substitution schedule) showing that the intervention does not itself suppress measured rewards or inflate test scores, the reported mismatch between training rewards and test performance cannot be attributed to RLVR rather than the experimental procedure.
Authors: This concern is well-taken. The manuscript already includes explicit controls via direct comparisons between standard RLVR training and the Periodic Rank-1 Substitution variant, along with ablations of the substitution schedule (see Figures 4-6 and associated text). These demonstrate that the intervention preserves reward dynamics and does not artifactually create the observed reward-test mismatch. We will revise the abstract to summarize these controls concisely, ensuring readers can immediately appreciate that the mismatch is attributable to RLVR rather than the procedure. revision: yes
Circularity Check
No circularity: empirical substitution experiments with no self-referential derivations or fitted predictions
full rationale
The paper's core claims rest on observations from Periodic Rank-1 Substitution applied to RLVR training runs. No equations, derivations, or parameter-fitting steps are described that reduce by construction to the inputs (e.g., no self-definitional scaling, no 'prediction' of a quantity that was itself fitted). The three listed properties are direct empirical characterizations of the resulting models rather than outputs of a closed mathematical chain. No self-citations are invoked as load-bearing uniqueness theorems or ansatzes. The analysis is therefore self-contained against external benchmarks and receives the default non-finding.
Axiom & Free-Parameter Ledger
axioms (1)
- standard math Singular value decomposition can be applied to weight matrices of linear layers to isolate rank-1 components.
Reference graph
Works this paper leans on
-
[1]
Adam: A Method for Stochastic Optimization
Kingma DP Ba J Adam et al. A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 1412(6), 2014
work page internal anchor Pith review arXiv 2014
-
[2]
Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting reinforce style optimization for learning from human feedback in llms.arXiv preprint arXiv:2402.14740, 2024
work page internal anchor Pith review arXiv 2024
-
[3]
arXiv preprint arXiv:2510.00553 , year=
Yuchen Cai, Ding Cao, Xin Xu, Zijun Yao, Yuqing Huang, Zhenyu Tan, Benyi Zhang, Guiquan Liu, and Junfeng Fang. On predictability of reinforcement learning dynamics for large language models.arXiv preprint arXiv:2510.00553, 2025
-
[4]
MiniMax-M1: Scaling Test-Time Compute Efficiently with Lightning Attention
Aili Chen, Aonian Li, Bangwei Gong, Binyang Jiang, Bo Fei, Bo Yang, Boji Shan, Changqing Yu, Chao Wang, Cheng Zhu, et al. Minimax-m1: Scaling test-time compute efficiently with lightning attention.arXiv preprint arXiv:2506.13585, 2025
work page internal anchor Pith review arXiv 2025
-
[5]
Zhipeng Chen, Xiaobo Qin, Youbin Wu, Yue Ling, Qinghao Ye, Wayne Xin Zhao, and Guang Shi. Pass@ k training for adaptively balancing exploration and exploitation of large reasoning models.arXiv preprint arXiv:2508.10751, 2025
-
[6]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, et al. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review arXiv 2021
-
[7]
The Entropy Mechanism of Reinforcement Learning for Reasoning Language Models
Ganqu Cui, Yuchen Zhang, Jiacheng Chen, Lifan Yuan, Zhi Wang, Yuxin Zuo, Haozhan Li, Yuchen Fan, Huayu Chen, Weize Chen, Zhiyuan Liu, Hao Peng, Lei Bai, Wanli Ouyang, Yu Cheng, Bowen Zhou, and Ning Ding. The entropy mechanism of reinforcement learning for reasoning language models, 2025. URLhttps://arxiv.org/abs/2505.22617
work page internal anchor Pith review arXiv 2025
-
[8]
Assessing diversity collapse in reasoning
Xingyu Dang, Christina Baek, J Zico Kolter, and Aditi Raghunathan. Assessing diversity collapse in reasoning. InScaling Self-Improving Foundation Models without Human Supervision, 2025
2025
-
[9]
The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, Abhishek Kadian, Ahmad Al-Dahle, Aiesha Letman, Akhil Mathur, Alan Schelten, Amy Yang, Angela Fan, et al. The llama 3 herd of models.arXiv e-prints, pages arXiv–2407, 2024
2024
-
[10]
OpenThoughts: Data Recipes for Reasoning Models
Etash Guha, Ryan Marten, Sedrick Keh, Negin Raoof, Georgios Smyrnis, Hritik Bansal, Marianna Nezhurina, Jean Mercat, Trung Vu, Zayne Sprague, et al. Openthoughts: Data recipes for reasoning models.arXiv preprint arXiv:2506.04178, 2025
work page internal anchor Pith review arXiv 2025
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review arXiv 2025
-
[12]
arXiv preprint arXiv:2504.11456 , year=
Zhiwei He, Tian Liang, Jiahao Xu, Qiuzhi Liu, Xingyu Chen, Yue Wang, Linfeng Song, Dian Yu, Zhenwen Liang, Wenxuan Wang, et al. Deepmath-103k: A large-scale, challenging, decontaminated, and verifiable mathematical dataset for advancing reasoning.arXiv preprint arXiv:2504.11456, 2025
-
[13]
Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding.Proceedings of the International Conference on Learning Representations (ICLR), 2021
2021
-
[14]
Alexandre Heuillet, Fabien Couthouis, and Natalia Díaz-Rodríguez. Collective explainable ai: Explaining cooperative strategies and agent contribution in multiagent reinforcement learning with shapley values.IEEE Computational Intelligence Magazine, 17(1):59–71, 2022
2022
-
[15]
Open-Reasoner-Zero: An Open Source Approach to Scaling Up Reinforcement Learning on the Base Model
Jingcheng Hu, Yinmin Zhang, Qi Han, Daxin Jiang, Xiangyu Zhang, and Heung-Yeung Shum. Open-reasoner-zero: An open source approach to scaling up reinforcement learning on the base model.arXiv preprint arXiv:2503.24290, 2025. 10
work page internal anchor Pith review arXiv 2025
-
[16]
Llama3.1-8B-Thinking-R1
Jackrong. Llama3.1-8B-Thinking-R1. https://huggingface.co/Jackrong/Llama3. 1-8B-Thinking-R1, 2025. Accessed: 2026-05-07
2025
-
[17]
arXiv preprint arXiv:2512.05117 (2025)
Prakhar Kaushik, Shravan Chaudhari, Ankit Vaidya, Rama Chellappa, and Alan Yuille. The universal weight subspace hypothesis.arXiv preprint arXiv:2512.05117, 2025
-
[18]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023
2023
-
[19]
Understanding R1-Zero-Like Training: A Critical Perspective
Zichen Liu, Changyu Chen, Wenjun Li, Penghui Qi, Tianyu Pang, Chao Du, Wee Sun Lee, and Min Lin. Understanding r1-zero-like training: A critical perspective.arXiv preprint arXiv:2503.20783, 2025
work page internal anchor Pith review arXiv 2025
-
[20]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review arXiv 2017
-
[21]
Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
2022
-
[22]
Tinyzero
Jiayi Pan, Junjie Zhang, Xingyao Wang, Lifan Yuan, Hao Peng, and Alane Suhr. Tinyzero. https://github.com/Jiayi-Pan/TinyZero, 2025. Accessed: 2025-01-24
2025
-
[23]
Qwen, :, An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, Huan Lin, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jingren Zhou, Junyang Lin, Kai Dang, Keming Lu, Keqin Bao, Kexin Yang, Le Yu, Mei Li, Mingfeng Xue, Pei Zhang, Qin Zhu, Rui Men, Runji Lin, Tianhao Li,...
work page internal anchor Pith review arXiv 2025
-
[24]
Direct preference optimization: Your language model is secretly a reward model
Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, and Chelsea Finn. Direct preference optimization: Your language model is secretly a reward model. Advances in neural information processing systems, 36:53728–53741, 2023
2023
-
[25]
Learning dynamics of llm finetuning
Yi Ren and Danica J Sutherland. Learning dynamics of llm finetuning. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[26]
John Schulman and Thinking Machines Lab. Lora without regret.Thinking Machines Lab: Connectionism, 2025. doi: 10.64434/tml.20250929. https://thinkingmachines.ai/blog/lora/
-
[27]
Trust region policy optimization
John Schulman, Sergey Levine, Pieter Abbeel, Michael Jordan, and Philipp Moritz. Trust region policy optimization. InInternational conference on machine learning, pages 1889–1897. PMLR, 2015
2015
-
[28]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347, 2017
work page internal anchor Pith review arXiv 2017
-
[29]
Interestingness elements for explainable reinforcement learning: Understanding agents’ capabilities and limitations.Artificial Intelligence, 288:103367, 2020
Pedro Sequeira and Melinda Gervasio. Interestingness elements for explainable reinforcement learning: Understanding agents’ capabilities and limitations.Artificial Intelligence, 288:103367, 2020
2020
-
[30]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, YK Li, Yang Wu, et al. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review arXiv 2024
-
[31]
Rl’s razor: Why online reinforcement learning forgets less, 2025
Idan Shenfeld, Jyothish Pari, and Pulkit Agrawal. Rl’s razor: Why online reinforcement learning forgets less, 2025. URLhttps://arxiv.org/abs/2509.04259. 11
-
[32]
Hybridflow: A flexible and efficient rlhf framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. Hybridflow: A flexible and efficient rlhf framework. In Proceedings of the Twentieth European Conference on Computer Systems, pages 1279–1297, 2025
2025
-
[33]
Sample more to think less: Group filtered policy optimization for concise reasoning
Vaishnavi Shrivastava, Ahmed Awadallah, Vidhisha Balachandran, Shivam Garg, Harkirat Behl, and Dimitris Papailiopoulos. Sample more to think less: Group filtered policy optimization for concise reasoning.arXiv preprint arXiv:2508.09726, 2025
-
[34]
Kimi Team, Yifan Bai, Yiping Bao, Guanduo Chen, Jiahao Chen, Ningxin Chen, Ruijue Chen, Yanru Chen, Yuankun Chen, Yutian Chen, Zhuofu Chen, Jialei Cui, Hao Ding, Mengnan Dong, Angang Du, Chenzhuang Du, Dikang Du, Yulun Du, Yu Fan, Yichen Feng, Kelin Fu, Bofei Gao, Hongcheng Gao, Peizhong Gao, Tong Gao, Xinran Gu, Longyu Guan, Haiqing Guo, Jianhang Guo, Ha...
work page internal anchor Pith review arXiv 2025
-
[35]
Qwen Team et al. Qwen2 technical report.arXiv preprint arXiv:2407.10671, 2(3), 2024
work page internal anchor Pith review arXiv 2024
-
[36]
Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290, 2024
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290, 2024
2024
-
[37]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review arXiv 2025
-
[38]
DAPO: An Open-Source LLM Reinforcement Learning System at Scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, et al. Dapo: An open-source llm reinforcement learning system at scale, 2025.URL https://arxiv. org/abs/2503.14476, 2025
work page internal anchor Pith review arXiv 2025
-
[39]
Does Reinforcement Learning Really Incentivize Reasoning Capacity in LLMs Beyond the Base Model?
Yang Yue, Zhiqi Chen, Rui Lu, Andrew Zhao, Zhaokai Wang, Yang Yue, Shiji Song, and Gao Huang. Does reinforcement learning really incentivize reasoning capacity in llms beyond the base model?arXiv preprint arXiv:2504.13837, 2025. 12
work page internal anchor Pith review arXiv 2025
-
[40]
Lolcats: On low-rank linearizing of large language models
Michael Zhang, Simran Arora, Rahul Chalamala, Alan Wu, Benjamin Spector, Aaryan Singhal, Krithik Ramesh, and Christopher Ré. Lolcats: On low-rank linearizing of large language models. arXiv preprint arXiv:2410.10254, 2024
-
[41]
Safetybench: Evaluating the safety of large language models
Zhexin Zhang, Leqi Lei, Lindong Wu, Rui Sun, Yongkang Huang, Chong Long, Xiao Liu, Xuanyu Lei, Jie Tang, and Minlie Huang. Safetybench: Evaluating the safety of large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 15537–15553, 2024
2024
-
[42]
arXiv preprint arXiv:2507.20673 , year=
Yuzhong Zhao, Yue Liu, Junpeng Liu, Jingye Chen, Xun Wu, Yaru Hao, Tengchao Lv, Shaohan Huang, Lei Cui, Qixiang Ye, et al. Geometric-mean policy optimization.arXiv preprint arXiv:2507.20673, 2025
-
[43]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, et al. Group sequence policy optimization.arXiv preprint arXiv:2507.18071, 2025
work page internal anchor Pith review arXiv 2025
-
[44]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models, 2023. URL https://arxiv.org/abs/2311.07911. 13 A Why RLVR Algorithms Are the Same in Essence Let ˆAi = Ri −µ R σR , µ R = 1 G GX j=1 Rj. GRPO objective: JGRPO(θ) =E " 1 G GX i=1 1 |yi| |yi|X...
work page internal anchor Pith review arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.