Recognition: unknown
Ex Ante Evaluation of AI-Induced Idea Diversity Collapse
Pith reviewed 2026-05-08 09:46 UTC · model grok-4.3
The pith
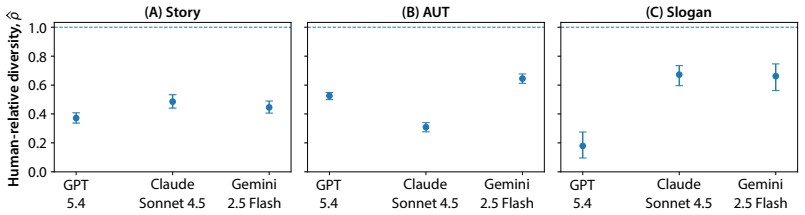
Three frontier LLMs fall below idea diversity parity across creative tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce a human-relative framework for benchmarking AI-induced human diversity collapse without requiring human-AI interaction data. By modeling ideas as congestible resources, source-level crowding is identifiable from within-distribution comparisons of model-only generations and matched unaided human baselines, yielding an excess-crowding coefficient Δ and a human-relative diversity ratio ρ with ρ≥1 as the no-excess-crowding parity condition. Across short stories, marketing slogans, and alternative-uses tasks, three frontier LLMs fall below parity across crowding kernels, with estimates stabilizing with feasible model-only sample sizes. Generation-protocol variants show crowding can
What carries the argument
The excess-crowding coefficient Δ and human-relative diversity ratio ρ, which quantify source-level crowding via within-distribution comparisons between model-only and human baseline idea generations.
Load-bearing premise
That within-distribution comparisons between model-only generations and matched unaided human baselines can reliably identify source-level crowding without human-AI interaction data.
What would settle it
A real-world study comparing the actual spread and adoption success of ideas in populations using the AI versus those not using it, to check if the predicted excess crowding matches observed redundancy.
Figures













read the original abstract
Creative AI systems are typically evaluated at the level of individual utility, yet creative outputs are consumed in populations: an idea loses value when many others produce similar ones. This creates an evaluation blind spot, as AI can improve individual outputs while increasing population-level crowding. We introduce a human-relative framework for benchmarking AI-induced human diversity collapse without requiring human-AI interaction data, providing an ex ante protocol to estimate crowding risk from model-only generations and matched unaided human baselines. By modeling ideas as congestible resources, we show that source-level crowding is identifiable from within-distribution comparisons, yielding an excess-crowding coefficient $\Delta$ and a human-relative diversity ratio $\rho$. We show that $\rho\ge1$ is the no-excess-crowding parity condition and connect $\Delta$ to an adoption game with exposure-dependent redundancy costs. Across short stories, marketing slogans, and alternative-uses tasks, three frontier LLMs fall below parity across crowding kernels. Estimates stabilize with feasible model-only sample sizes. Importantly, generation-protocol variants show that crowding can be reduced through targeted design, making diversity collapse an actionable, development-time evaluation target for population-aware creative AI.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a human-relative ex ante framework for assessing AI-induced idea diversity collapse. It models ideas as congestible resources and extracts an excess-crowding coefficient Δ and human-relative diversity ratio ρ from within-distribution comparisons of model-only LLM generations versus matched unaided human baselines, without requiring human-AI interaction data. The paper claims that ρ ≥ 1 is the no-excess-crowding parity condition, connects Δ to an adoption game with exposure-dependent redundancy costs, and reports that three frontier LLMs fall below parity across short stories, marketing slogans, and alternative-uses tasks. It further shows that estimates stabilize with feasible sample sizes and that targeted generation-protocol variants can reduce crowding.
Significance. If the identification from within-distribution comparisons holds, the framework supplies a practical, interaction-free protocol for population-level evaluation of creative AI, addressing the blind spot between individual utility and collective crowding. The empirical demonstration that crowding is measurable and mitigable at development time is a concrete strength, as is the stabilization of estimates with model-only samples; these elements make diversity collapse an actionable design target rather than a purely theoretical concern.
major comments (3)
- [Abstract / central construction] Abstract and central construction: the claim that source-level crowding is identifiable from within-distribution comparisons (yielding Δ and ρ) rests on an un-derived equivalence between the chosen crowding kernels and the redundancy-cost function in the adoption game. No steps are shown establishing that kernel statistics alone determine exposure-dependent payoffs once human choice, selection, or context-dependent valuation are admitted; this assumption is load-bearing for the ex ante protocol.
- [Abstract] Abstract: the assertion that ρ ≥ 1 constitutes the no-excess-crowding parity condition and that Δ maps directly to the adoption game is presented without the intermediate equations or kernel definitions needed to verify independence from the same within-distribution statistics used to compute ρ, raising a circularity risk for the redundancy-cost parameterization.
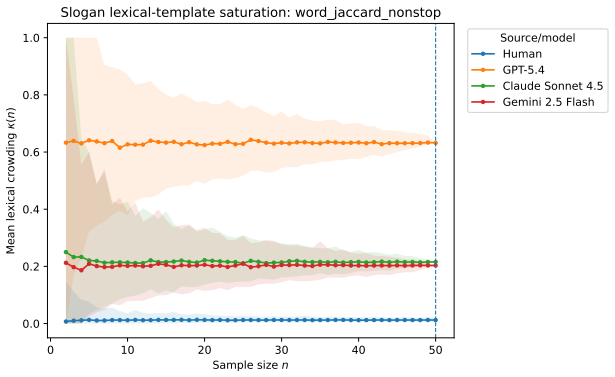
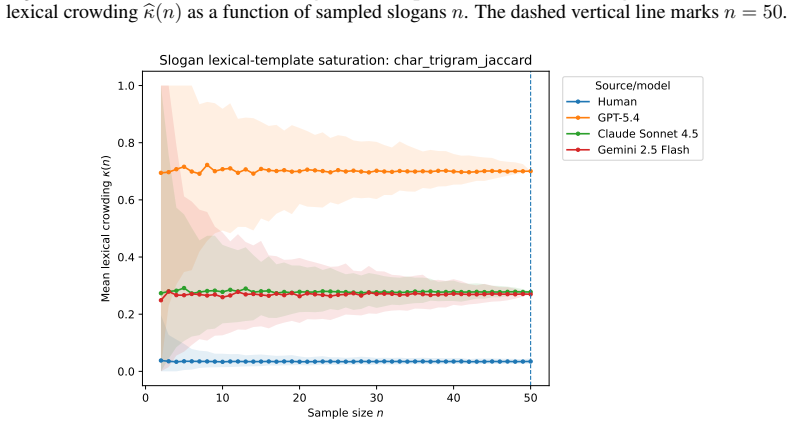
- [Empirical results] Empirical results (across tasks): the report that three LLMs fall below parity and that estimates stabilize with feasible model-only sample sizes is given without error bars, sample-size justification, or robustness checks against kernel choice, which weakens the claim that the protocol yields reliable ex ante signals.
minor comments (2)
- Notation for Δ and ρ is introduced in the abstract but would benefit from an explicit early section defining the crowding kernels and their application to the two distributions.
- The manuscript would be strengthened by a brief discussion of how the framework relates to existing measures of semantic diversity or novelty in computational creativity literature.
Simulated Author's Rebuttal
We thank the referee for the constructive report and for recognizing the practical value of an interaction-free ex ante protocol. We address each major comment below. Where the manuscript requires additional derivation or empirical safeguards, we have revised accordingly.
read point-by-point responses
-
Referee: [Abstract / central construction] Abstract and central construction: the claim that source-level crowding is identifiable from within-distribution comparisons (yielding Δ and ρ) rests on an un-derived equivalence between the chosen crowding kernels and the redundancy-cost function in the adoption game. No steps are shown establishing that kernel statistics alone determine exposure-dependent payoffs once human choice, selection, or context-dependent valuation are admitted; this assumption is load-bearing for the ex ante protocol.
Authors: We agree that the mapping from kernel statistics to exposure-dependent payoffs must be derived explicitly rather than asserted. The revised manuscript adds a dedicated subsection that starts from a standard random-utility adoption model in which an agent’s payoff declines linearly with the expected number of near-duplicates encountered. We then show that the first two moments of the within-distribution similarity kernel are sufficient statistics for this expectation under the maintained assumption that agents observe only pairwise similarities (not full context-dependent valuations). The derivation is now presented before the definitions of Δ and ρ, making the identifiability claim traceable to the kernel rather than circular. revision: yes
-
Referee: [Abstract] Abstract: the assertion that ρ ≥ 1 constitutes the no-excess-crowding parity condition and that Δ maps directly to the adoption game is presented without the intermediate equations or kernel definitions needed to verify independence from the same within-distribution statistics used to compute ρ, raising a circularity risk for the redundancy-cost parameterization.
Authors: The revised text inserts the missing intermediate equations immediately after the kernel definitions. ρ is defined solely as the ratio of average pairwise distances in the human versus model-only distributions; Δ is obtained by substituting the same kernel into the closed-form redundancy-cost term of the adoption game and solving for the excess-crowding multiplier that equates expected payoffs. Because the parity condition ρ ≥ 1 is obtained by setting Δ = 0 in the game, the two quantities are algebraically linked but computed from distinct operations on the kernel; we now display both the algebraic link and the separate computational paths to eliminate any appearance of circularity. revision: yes
-
Referee: [Empirical results] Empirical results (across tasks): the report that three LLMs fall below parity and that estimates stabilize with feasible model-only sample sizes is given without error bars, sample-size justification, or robustness checks against kernel choice, which weakens the claim that the protocol yields reliable ex ante signals.
Authors: We accept the criticism. The revised empirical section now reports bootstrap standard errors for both Δ and ρ, includes convergence plots that justify the chosen sample sizes (n = 200 per condition), and adds a robustness table repeating the main results under three alternative kernels (cosine on sentence embeddings, Jaccard on n-grams, and edit-distance on tokenized ideas). All three LLMs remain below parity and the stabilization result is unchanged, but the added diagnostics directly address the concern about reliability. revision: yes
Circularity Check
Central metrics Δ and ρ extracted by construction from within-distribution comparisons; mapping to adoption game assumed without independent derivation
specific steps
-
self definitional
[Abstract]
"By modeling ideas as congestible resources, we show that source-level crowding is identifiable from within-distribution comparisons, yielding an excess-crowding coefficient Δ and a human-relative diversity ratio ρ. We show that ρ≥1 is the no-excess-crowding parity condition and connect Δ to an adoption game with exposure-dependent redundancy costs."
Δ and ρ are defined directly as outputs of applying crowding kernels to the model-only and human baseline distributions; the 'identifiability' claim, the parity condition ρ≥1, and the connection of Δ to the adoption game's redundancy costs are then asserted as shown results. No separate equation or external mapping is supplied demonstrating that the kernel statistics determine the game's exposure-dependent costs independently of the same distributional inputs, rendering the central construction equivalent to its modeling assumptions by definition.
full rationale
The paper's core claim is that source-level crowding is identifiable from within-distribution comparisons of model-only generations versus human baselines, directly yielding Δ and ρ, with ρ ≥ 1 declared the parity condition and Δ connected to an adoption game. This identification and connection rest on the modeling choice of ideas as congestible resources and the selected kernels as sufficient statistics, without a separate derivation showing that distributional overlap alone determines exposure-dependent redundancy costs once human choice and context are admitted. The empirical results across tasks add non-circular content, but the load-bearing identification step reduces to the input definitions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Ideas function as congestible resources whose value decreases with population-level similarity
Reference graph
Works this paper leans on
-
[1]
Assessing associative distance among ideas elicited by tests of divergent thinking.Creativity Research Journal, 26(2):229–238, 2014
Selcuk Acar and Mark A Runco. Assessing associative distance among ideas elicited by tests of divergent thinking.Creativity Research Journal, 26(2):229–238, 2014
2014
-
[2]
From semantic memory to collective creativity: A generative cognitive foundation for social creativity models
Mirza Nayeem Ahmed and Raiyan Abdul Baten. From semantic memory to collective creativity: A generative cognitive foundation for social creativity models. InProceedings of the Annual Meeting of the Cognitive Science Society, volume 48, 2026
2026
-
[3]
Social psychology of creativity: A consensual assessment technique
Teresa M Amabile. Social psychology of creativity: A consensual assessment technique. Journal of Personality and Social Psychology, 43(5):997, 1982
1982
-
[4]
Homogenization effects of Large Language Models on human creative ideation
Barrett R Anderson, Jash Hemant Shah, and Max Kreminski. Homogenization effects of Large Language Models on human creative ideation. InProceedings of the 16th Conference on Creativity & Cognition, pages 413–425, 2024
2024
-
[5]
How AI ideas affect the creativity, diversity, and evolution of human ideas: evidence from a large, dynamic experiment
Joshua Ashkinaze, Julia Mendelsohn, Li Qiwei, Ceren Budak, and Eric Gilbert. How AI ideas affect the creativity, diversity, and evolution of human ideas: evidence from a large, dynamic experiment. InProceedings of the ACM Collective Intelligence Conference, pages 198–213, 2025
2025
-
[6]
MuseScorer: Idea originality scoring at scale
Ali Sarosh Bangash, Krish Veera, Ishfat Abrar Islam, and Raiyan Abdul Baten. MuseScorer: Idea originality scoring at scale. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 19947–19965, 2025
2025
-
[7]
Cues to gender and racial identity reduce creativity in diverse social networks.Scientific Reports, 11(1):10261, 2021
Raiyan Abdul Baten, Richard N Aslin, Gourab Ghoshal, and Ehsan Hoque. Cues to gender and racial identity reduce creativity in diverse social networks.Scientific Reports, 11(1):10261, 2021
2021
-
[8]
Goldilocks
Raiyan Abdul Baten, Richard N Aslin, Gourab Ghoshal, and Ehsan Hoque. Novel idea generation in social networks is optimized by exposure to a “Goldilocks” level of idea-variability. PNAS Nexus, 1(5):pgac255, 2022
2022
-
[9]
Creativity in temporal social networks: How divergent thinking is impacted by one’s choice of peers.Journal of the Royal Society Interface, 17(171):20200667, 2020
Raiyan Abdul Baten, Daryl Bagley, Ashely Tenesaca, Famous Clark, James P Bagrow, Gourab Ghoshal, and Ehsan Hoque. Creativity in temporal social networks: How divergent thinking is impacted by one’s choice of peers.Journal of the Royal Society Interface, 17(171):20200667, 2020
2020
-
[10]
AI can enhance creativity in social networks.arXiv preprint arXiv:2410.15264, 2024
Raiyan Abdul Baten, Ali Sarosh Bangash, Krish Veera, Gourab Ghoshal, and Ehsan Hoque. AI can enhance creativity in social networks.arXiv preprint arXiv:2410.15264, 2024
-
[11]
Automating creativity assessment with SemDis: An open platform for computing semantic distance.Behavior Research Methods, 53(2):757–780, 2021
Roger E Beaty and Dan R Johnson. Automating creativity assessment with SemDis: An open platform for computing semantic distance.Behavior Research Methods, 53(2):757–780, 2021
2021
-
[12]
Scoring divergent thinking tests by computer with a semantics-based algorithm.Europe’s Journal of Psychology, 12(2):210, 2016
Kenes Beketayev and Mark A Runco. Scoring divergent thinking tests by computer with a semantics-based algorithm.Europe’s Journal of Psychology, 12(2):210, 2016
2016
-
[13]
A semantic network approach to the Creativity Quotient (CQ).Creativity Research Journal, 21(1):64–71, 2009
Terry Bossomaier, Mike Harré, Anthony Knittel, and Allan Snyder. A semantic network approach to the Creativity Quotient (CQ).Creativity Research Journal, 21(1):64–71, 2009
2009
-
[14]
The machines take over: A comparison of various supervised learning approaches for automated scoring of divergent thinking tasks.The Journal of Creative Behavior, 57(1):17–36, 2023
Philip Buczak, He Huang, Boris Forthmann, and Philipp Doebler. The machines take over: A comparison of various supervised learning approaches for automated scoring of divergent thinking tasks.The Journal of Creative Behavior, 57(1):17–36, 2023
2023
-
[15]
Can good writing be generative? expert-level AI writing emerges through fine-tuning on high quality books
Tuhin Chakrabarty and Paramveer S Dhillon. Can good writing be generative? expert-level AI writing emerges through fine-tuning on high quality books. InProceedings of the 2026 CHI Conference on Human Factors in Computing Systems, pages 1–27, 2026
2026
-
[16]
Art or artifice? Large Language Models and the false promise of creativity
Tuhin Chakrabarty, Philippe Laban, Divyansh Agarwal, Smaranda Muresan, and Chien-Sheng Wu. Art or artifice? Large Language Models and the false promise of creativity. InProceedings of the 2024 CHI Conference on Human Factors in Computing Systems, pages 1–34, 2024
2024
-
[17]
Cognitive abilities involved in insight problem solving: An individual differences model.Creativity Research Journal, 20(3):278–290, 2008
Colin G DeYoung, Joseph L Flanders, and Jordan B Peterson. Cognitive abilities involved in insight problem solving: An individual differences model.Creativity Research Journal, 20(3):278–290, 2008. 26
2008
-
[18]
Generative AI enhances individual creativity but reduces the collective diversity of novel content.Science Advances, 10(28):eadn5290, 2024
Anil R Doshi and Oliver P Hauser. Generative AI enhances individual creativity but reduces the collective diversity of novel content.Science Advances, 10(28):eadn5290, 2024
2024
-
[19]
Understanding fluency and originality: A latent variable perspective.Thinking Skills and Creativity, 14:56–67, 2014
Denis Dumas and Kevin N Dunbar. Understanding fluency and originality: A latent variable perspective.Thinking Skills and Creativity, 14:56–67, 2014
2014
-
[20]
Denis Dumas, Peter Organisciak, and Michael Doherty. Measuring divergent thinking originality with human raters and text-mining models: A psychometric comparison of methods.Psychology of Aesthetics, Creativity, and the Arts, 15(4):645, 2021
2021
-
[21]
Hierarchical neural story generation
Angela Fan, Mike Lewis, and Yann Dauphin. Hierarchical neural story generation. InProceed- ings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 889–898, 2018
2018
-
[22]
Boris Forthmann, Sue Hyeon Paek, Denis Dumas, Baptiste Barbot, and Heinz Holling. Scru- tinizing the basis of originality in divergent thinking tests: On the measurement precision of response propensity estimates.British Journal of Educational Psychology, 90(3):683–699, 2020
2020
-
[23]
McGraw-Hill, 1967
Joy Paul Guilford.The Nature of Human Intelligence. McGraw-Hill, 1967
1967
-
[24]
The Curious Case of Neural Text Degeneration
Ari Holtzman, Jan Buys, Li Du, Maxwell Forbes, and Yejin Choi. The curious case of neural text degeneration.arXiv preprint arXiv:1904.09751, 2019
work page internal anchor Pith review arXiv 1904
-
[25]
Zhaoyi Joey Hou, Bowei Alvin Zhang, Yining Lu, Bhiman Kumar Baghel, Anneliese Brei, Ximing Lu, Meng Jiang, Faeze Brahman, Snigdha Chaturvedi, Haw-Shiuan Chang, Daniel Khashabi, and Xiang Lorraine Li. CreativityPrism: A holistic benchmark for Large Language Model creativity.arXiv preprint arXiv:2510.20091, 2025
-
[26]
arXiv preprint arXiv:2411.02316 , year =
Mete Ismayilzada, Claire Stevenson, and Lonneke van der Plas. Evaluating creative short story generation in humans and Large Language Models.arXiv preprint arXiv:2411.02316, 2024
-
[27]
The innovation trade-off: how following superstars shapes academic novelty
Sean Kelty, Raiyan Abdul Baten, Adiba Mahbub Proma, Ehsan Hoque, Johan Bollen, and Gourab Ghoshal. The innovation trade-off: how following superstars shapes academic novelty. Humanities and Social Sciences Communications, 12(1):1–13, 2025
2025
-
[28]
Robert Kirk, Ishita Mediratta, Christoforos Nalmpantis, Jelena Luketina, Eric Hambro, Edward Grefenstette, and Roberta Raileanu. Understanding the effects of RLHF on LLM generalisation and diversity.arXiv preprint arXiv:2310.06452, 2023
-
[29]
Human creativity in the age of LLMs: Randomized experiments on divergent and convergent thinking
Harsh Kumar, Jonathan Vincentius, Ewan Jordan, and Ashton Anderson. Human creativity in the age of LLMs: Randomized experiments on divergent and convergent thinking. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, pages 1–18, 2025
2025
-
[30]
Tianjian Li, Yiming Zhang, Ping Yu, Swarnadeep Saha, Daniel Khashabi, Jason Weston, Jack Lanchantin, and Tianlu Wang. Jointly reinforcing diversity and quality in language model generations.arXiv preprint arXiv:2509.02534, 2025
-
[31]
LLM-Eval: Unified multi-dimensional automatic evaluation for open-domain conversations with Large Language Models
Yen-Ting Lin and Yun-Nung Chen. LLM-Eval: Unified multi-dimensional automatic evaluation for open-domain conversations with Large Language Models. InProceedings of the 5th Workshop on NLP for Conversational AI (NLP4ConvAI 2023), pages 47–58, 2023
2023
-
[32]
Creativity in LLM-based multi-agent systems: A survey
Yi-Cheng Lin, Kang-Chieh Chen, Zhe-Yan Li, Tzu-Heng Wu, Tzu-Hsuan Wu, Kuan-Yu Chen, Hung-yi Lee, and Yun-Nung Chen. Creativity in LLM-based multi-agent systems: A survey. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 27572–27595, 2025
2025
-
[33]
Evaluating text-to-visual generation with image-to-text generation
Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Deva Ramanan. Evaluating text-to-visual generation with image-to-text generation. In European Conference on Computer Vision, pages 366–384. Springer, 2024
2024
-
[34]
Ximing Lu, Melanie Sclar, Skyler Hallinan, Niloofar Mireshghallah, Jiacheng Liu, Seungju Han, Allyson Ettinger, Liwei Jiang, Khyathi Chandu, Nouha Dziri, et al. AI as humanity’s Salieri: Quantifying linguistic creativity of language models via systematic attribution of machine text against web text.arXiv preprint arXiv:2410.04265, 2024. 27
-
[35]
Minh Nhat Nguyen, Andrew Baker, Clement Neo, Allen Roush, Andreas Kirsch, and Ravid Shwartz-Ziv. Turning up the heat: Min-p sampling for creative and coherent LLM outputs. arXiv preprint arXiv:2407.01082, 2024
-
[36]
Naming unrelated words predicts creativity.Proceedings of the National Academy of Sciences, 118(25):e2022340118, 2021
Jay A Olson, Johnny Nahas, Denis Chmoulevitch, Simon J Cropper, and Margaret E Webb. Naming unrelated words predicts creativity.Proceedings of the National Academy of Sciences, 118(25):e2022340118, 2021
2021
-
[37]
Beyond semantic distance: Automated scoring of divergent thinking greatly improves with Large Language Models.Thinking Skills and Creativity, 49:101356, 2023
Peter Organisciak, Selcuk Acar, Denis Dumas, and Kelly Berthiaume. Beyond semantic distance: Automated scoring of divergent thinking greatly improves with Large Language Models.Thinking Skills and Creativity, 49:101356, 2023
2023
-
[38]
Open creativity scoring
Peter Organisciak and Denis Dumas. Open creativity scoring. https://openscoring.du. edu, 2020. [Computer software]
2020
-
[39]
Deep associations, high creativity: A simple yet effective metric for evaluating Large Language Models
Ziliang Qiu and Renfen Hu. Deep associations, high creativity: A simple yet effective metric for evaluating Large Language Models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 10870–10883, 2025
2025
-
[40]
Scoring divergent thinking tests: A review and systematic framework.Psychology of Aesthetics, Creativity, and the Arts, 13(2):144, 2019
Roni Reiter-Palmon, Boris Forthmann, and Baptiste Barbot. Scoring divergent thinking tests: A review and systematic framework.Psychology of Aesthetics, Creativity, and the Arts, 13(2):144, 2019
2019
-
[41]
The standard definition of creativity.Creativity Research Journal, 24(1):92–96, 2012
Mark A Runco and Garrett J Jaeger. The standard definition of creativity.Creativity Research Journal, 24(1):92–96, 2012
2012
-
[42]
Scoring divergent thinking tests using total ideational output and a creativity index.Educational and Psychological Measurement, 52(1):213–221, 1992
Mark A Runco and Wayne Mraz. Scoring divergent thinking tests using total ideational output and a creativity index.Educational and Psychological Measurement, 52(1):213–221, 1992
1992
-
[43]
Evaluating the diversity and quality of LLM generated content.CoRR, abs/2504.12522, 2025
Alexander Shypula, Shuo Li, Botong Zhang, Vishakh Padmakumar, Kayo Yin, and Osbert Bastani. Evaluating the diversity and quality of LLM generated content.arXiv preprint arXiv:2504.12522, 2025
-
[44]
Brandon Smith, Mohamed Reda Bouadjenek, Tahsin Alamgir Kheya, Phillip Dawson, and Sunil Aryal. A comprehensive analysis of Large Language Model outputs: Similarity, diversity, and bias.arXiv preprint arXiv:2505.09056, 2025
-
[45]
The Creativity Quotient: An objective scoring of ideational fluency.Creativity Research Journal, 16(4):415–419, 2004
Allan Snyder, John Mitchell, Terry Bossomaier, and Gerry Pallier. The Creativity Quotient: An objective scoring of ideational fluency.Creativity Research Journal, 16(4):415–419, 2004
2004
-
[46]
Short and extra-short forms of the Big Five Inventory–2: The BFI-2-S and BFI-2-XS.Journal of Research in Personality, 68:69–81, 2017
Christopher J Soto and Oliver P John. Short and extra-short forms of the Big Five Inventory–2: The BFI-2-S and BFI-2-XS.Journal of Research in Personality, 68:69–81, 2017
2017
-
[47]
The homogenizing effect of Large Language Models on human expression and thought.Trends in Cognitive Sciences, 2026
Zhivar Sourati, Alireza S Ziabari, and Morteza Dehghani. The homogenizing effect of Large Language Models on human expression and thought.Trends in Cognitive Sciences, 2026
2026
-
[48]
Stevenson, I
C. Stevenson, I. Smal, M. Baas, M. Dahrendorf, R. Grasman, C. Tanis, E. Scheurs, D. Sleiffer, and H. van der Maas. Automated AUT scoring using a big data variant of the consensual assessment technique. Report Final Technical Report, Modeling Creativity Project, Universiteit van Amsterdam, Amsterdam, July 2020. Faculty of Social and Behavioural Sciences (F...
2020
-
[49]
Nurture of creative talents.Theory Into Practice, 5(4):167–173, 1966
E Paul Torrance. Nurture of creative talents.Theory Into Practice, 5(4):167–173, 1966
1966
-
[50]
Diverse AI personas can mitigate the homogenization effect in human-AI collaborative ideation.Computers in Human Behavior: Artificial Humans, page 100289, 2026
Yun Wan and Yoram M Kalman. Diverse AI personas can mitigate the homogenization effect in human-AI collaborative ideation.Computers in Human Behavior: Artificial Humans, page 100289, 2026
2026
-
[51]
We’re different, we’re the same: Creative homogeneity across llms.arXiv preprint arXiv:2501.19361,
Emily Wenger and Yoed Kenett. We’re different, we’re the same: Creative homogeneity across LLMs.arXiv preprint arXiv:2501.19361, 2025
-
[52]
Echoes in AI: Quantifying lack of plot diversity in LLM outputs.Proceedings of the National Academy of Sciences, 122(35):e2504966122, 2025
Weijia Xu, Nebojsa Jojic, Sudha Rao, Chris Brockett, and Bill Dolan. Echoes in AI: Quantifying lack of plot diversity in LLM outputs.Proceedings of the National Academy of Sciences, 122(35):e2504966122, 2025. 28
2025
-
[53]
The price of format: Diversity collapse in llms, 2025
Longfei Yun, Chenyang An, Zilong Wang, Letian Peng, and Jingbo Shang. The price of format: Diversity collapse in LLMs.arXiv preprint arXiv:2505.18949, 2025
-
[54]
Noveltybench: Evaluating language models for humanlike diversity.arXiv preprint arXiv:2504.05228,
Yiming Zhang, Harshita Diddee, Susan Holm, Hanchen Liu, Xinyue Liu, Vinay Samuel, Barry Wang, and Daphne Ippolito. NoveltyBench: Evaluating language models for humanlike diversity. arXiv preprint arXiv:2504.05228, 2025. 29
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.