Recognition: unknown
CCL-Bench 1.0: A Trace-Based Benchmark for LLM Infrastructure
Pith reviewed 2026-05-08 05:04 UTC · model grok-4.3
The pith
Trace-based benchmarking for LLM infrastructure reveals that higher compute-communication overlap can produce longer training steps and that framework choices can create up to 3x gaps on identical hardware.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
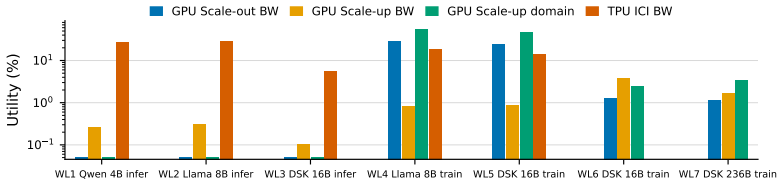
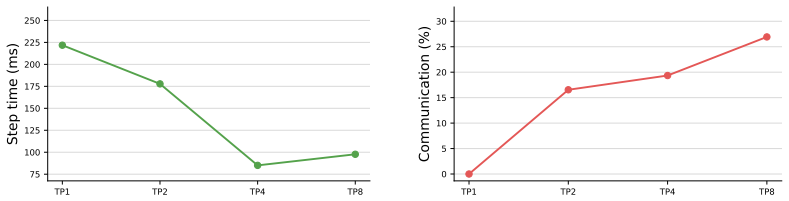
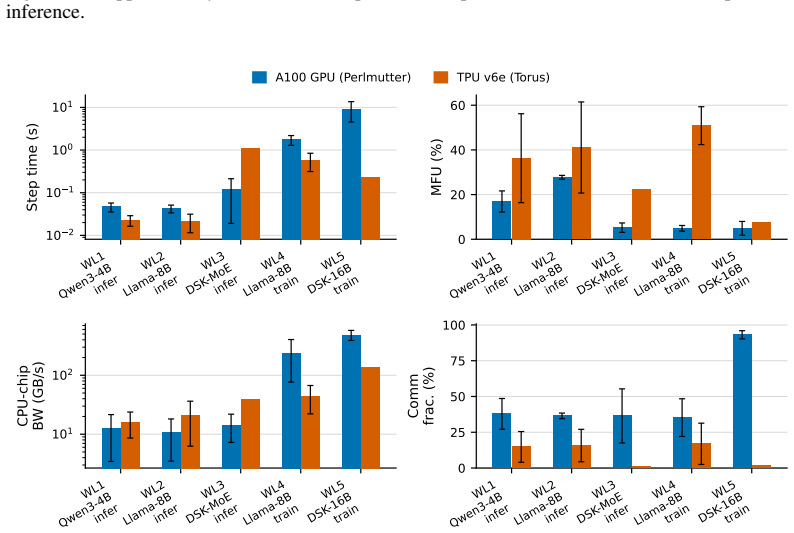
CCL-Bench records an execution trace, a YAML workload card, and launch scripts for each contributed data point, then applies a community-extensible toolkit to compute fine-grained compute, memory, and communication efficiency metrics from the trace. This evidence shows that higher compute-communication overlap can coincide with longer training step time and reveal inefficient parallelization choices, that doubling TPU interconnect bandwidth yields substantially higher end-to-end step-time improvement than doubling GPU interconnect bandwidth on small and medium workloads, and that the best-tuned configuration on one training framework can run up to 3x slower than the best-tuned configuration
What carries the argument
The toolkit that processes execution traces to compute fine-grained compute, memory, and communication efficiency metrics from reusable trace packages.
If this is right
- Higher compute-communication overlap can indicate inefficient parallelization when it coincides with longer step times.
- Doubling interconnect bandwidth produces larger step-time gains on TPUs than on GPUs for small and medium workloads.
- Training frameworks can differ by up to 3x in end-to-end performance even after best tuning on identical hardware.
Where Pith is reading between the lines
- Infrastructure teams could adopt trace collection as a standard practice to diagnose parallelization issues before scaling to larger workloads.
- Comparisons across hardware generations might become more reliable if benchmarks always ship the underlying traces rather than derived numbers alone.
- Automated tools that suggest parallelism plans from trace patterns could reduce reliance on manual tuning.
Load-bearing premise
The collected execution traces and the toolkit's metric computations faithfully represent true performance characteristics without bias from tracing overhead or workload selection.
What would settle it
A replication on the same workloads using an independent tracing method that finds the three reported performance relationships do not hold or reverse.
Figures











read the original abstract
Evaluative claims about LLM infrastructure -- ``workload X is fastest on hardware Y with software Z'' -- depend on a complex configuration space spanning hardware accelerators, interconnect bandwidth, software frameworks, parallelism plans, and communication libraries. Current infrastructure evaluation benchmarks publish a small set of end-to-end numbers that do not explain why one configuration outperforms another. We present CCL-Bench, a trace-based benchmark that addresses the limitations of existing benchmarks by recording reusable evidence for every ML workload. Each contributed data point in CCL-Bench packages an execution trace, a YAML workload card, and the launch scripts. We have developed a community-extensible toolkit to compute fine-grained compute, memory, and communication efficiency metrics from this evidence. Using CCL-Bench, we surface three claims that summary-statistic benchmarks cannot support: (i) higher compute-communication overlap can coincide with longer training step time and reveal inefficient parallelization choices, (ii) doubling TPU interconnect bandwidth yields a much higher end-to-end improvement in step time than doubling GPU interconnect bandwidth on small and medium workloads, and (iii) the best-tuned configuration on one training framework can run up to 3$\times$ slower than the best-tuned configuration on a peer framework on identical hardware.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CCL-Bench 1.0, a trace-based benchmark for LLM infrastructure evaluation. Each data point consists of an execution trace, a YAML workload card, and launch scripts. A community-extensible toolkit computes fine-grained compute, memory, and communication efficiency metrics from these traces. The authors use the benchmark to surface three claims not supportable by summary-statistic benchmarks: (i) higher compute-communication overlap can coincide with longer training step time and indicate inefficient parallelization, (ii) doubling TPU interconnect bandwidth yields substantially higher step-time improvement than doubling GPU interconnect bandwidth on small and medium workloads, and (iii) the best-tuned configuration on one training framework can be up to 3× slower than the best-tuned configuration on a peer framework on identical hardware.
Significance. If the traces are made publicly available, the toolkit is shown to be extensible, and the metrics are validated, CCL-Bench could meaningfully advance reproducible evaluation of distributed LLM training by exposing why one configuration outperforms another rather than reporting only end-to-end numbers. The packaging of reusable evidence (trace + card + script) directly addresses a documented limitation of existing infrastructure benchmarks.
major comments (2)
- [Abstract] Abstract: the three claims are presented as observations enabled by CCL-Bench, yet no workloads, configurations, quantitative results, or error bars are supplied to support them. This absence prevents assessment of whether the evidence actually sustains the claims, especially claim (iii) on the 3× slowdown.
- [Benchmark Design] Benchmark design and toolkit description: the manuscript provides no details on how the fine-grained metrics are computed from traces, no validation against ground-truth performance counters, and no analysis of tracing overhead or workload-selection bias. These omissions directly affect the weakest assumption that the collected traces faithfully represent true performance characteristics.
minor comments (1)
- [Abstract] Abstract: the LaTeX fragment “3$×$” should be rendered consistently as “3×” in the final PDF; check for similar formatting issues in any tables or figures that report speedups.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below and describe the revisions planned for the next version of the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the three claims are presented as observations enabled by CCL-Bench, yet no workloads, configurations, quantitative results, or error bars are supplied to support them. This absence prevents assessment of whether the evidence actually sustains the claims, especially claim (iii) on the 3× slowdown.
Authors: We agree that the abstract, in its current form, presents the three claims at a high level without the supporting quantitative details. The revised manuscript will incorporate concise quantitative summaries directly into the abstract (e.g., the specific workloads, hardware configurations, measured step-time deltas with error bars for claim (ii), and the exact frameworks, hardware, and workload yielding the 3× difference for claim (iii)). The full supporting data, including all workloads, configurations, and error bars, will also be expanded and clearly cross-referenced in the evaluation section. revision: yes
-
Referee: [Benchmark Design] Benchmark design and toolkit description: the manuscript provides no details on how the fine-grained metrics are computed from traces, no validation against ground-truth performance counters, and no analysis of tracing overhead or workload-selection bias. These omissions directly affect the weakest assumption that the collected traces faithfully represent true performance characteristics.
Authors: We acknowledge that the current manuscript lacks these details. The revised version will add a dedicated subsection describing the exact formulas, algorithms, and trace-parsing logic used to compute each fine-grained metric (compute, memory, and communication efficiency). We will also include a validation subsection that compares toolkit-derived metrics against ground-truth hardware performance counters, report measured tracing overhead as a percentage of step time on representative workloads, and add an analysis of workload-selection criteria together with a discussion of potential biases and how they were mitigated. revision: yes
Circularity Check
No significant circularity: empirical benchmark with no derivations or self-referential predictions
full rationale
The paper introduces CCL-Bench as a trace-collection and metric-computation toolkit for LLM infrastructure evaluation. Its central claims are direct observations computed from collected execution traces on specific workloads and hardware configurations; no equations, fitted parameters, or predictions are derived from prior results within the paper. The three surfaced claims (overlap vs. step time, TPU vs. GPU bandwidth scaling, framework tuning differences) are presented as empirical findings enabled by the benchmark rather than as universally quantified theorems. No self-citation chains, ansatzes, or uniqueness theorems are invoked to justify the methodology or results. The work is self-contained as a reusable artifact whose validity rests on external reproducibility of the traces and scripts, not on internal reduction to its own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Execution traces accurately record all relevant compute, memory, and communication events without significant overhead or omission.
Reference graph
Works this paper leans on
-
[1]
Fathom: Reference workloads for modern deep learning methods
Robert Adolf, Saketh Rama, Brandon Reagen, Gu-Yeon Wei, and David Brooks. Fathom: Reference workloads for modern deep learning methods. In2016 IEEE International Symposium on Workload Characterization (IISWC), pages 1–10. IEEE, 2016
2016
-
[2]
Vidur: A large-scale simulation framework for llm inference.Proceedings of Machine Learning and Systems, 6:351–366, 2024
Amey Agrawal, Nitin Kedia, Jayashree Mohan, Ashish Panwar, Nipun Kwatra, Bhargav S Gulavani, Ramachandran Ramjee, and Alexey Tumanov. Vidur: A large-scale simulation framework for llm inference.Proceedings of Machine Learning and Systems, 6:351–366, 2024
2024
-
[3]
MaxText: A Simple, Performant and Scalable JAX LLM
AI Hypercomputer. MaxText: A Simple, Performant and Scalable JAX LLM. https://github.com/ AI-Hypercomputer/maxtext, 2026. Accessed: 2026-05-05
2026
-
[4]
Amazon web services (aws)
Amazon Web Services. Amazon web services (aws). https://aws.amazon.com/, 2026. Accessed: 2026-05-06
2026
-
[5]
Accelerating generative AI: How AMD Instinct GPUs delivered breakthrough effi- ciency and scalability in MLPerf Inference v5.1
AMD. Accelerating generative AI: How AMD Instinct GPUs delivered breakthrough effi- ciency and scalability in MLPerf Inference v5.1. https://www.amd.com/en/blogs/2025/ accelerating-generative-ai-how-instinct-gpus-delivered.html , 2025. Accessed 2026-04- 26
2025
-
[6]
Accelerating AI training: How AMD Instinct MI350 Series GPUs delivered breakthrough performance and efficiency in MLPerf Training v5.1
AMD. Accelerating AI training: How AMD Instinct MI350 Series GPUs delivered breakthrough performance and efficiency in MLPerf Training v5.1. https://www.amd.com/en/blogs/2025/ accelerating-ai-training.html, 2025. Accessed 2026-04-26
2025
-
[7]
Jason Ansel, Edward Yang, Horace He, Natalia Gimelshein, Animesh Jain, Michael V oznesensky, Bin Bao, Peter Bell, David Berard, Evgeni Burovski, Geeta Chauhan, Anjali Chourdia, Will Constable, Alban Desmaison, Zachary DeVito, Elias Ellison, Will Feng, Jiong Gong, Michael Gschwind, Brian Hirsh, Sherlock Huang, Kshiteej Kalambarkar, Laurent Kirsch, Michael ...
-
[8]
doi: 10.1145/3620665.3640366
-
[9]
LLM Leaderboard: Comparison of over 100 AI Models
Artificial Analysis. LLM Leaderboard: Comparison of over 100 AI Models. https:// artificialanalysis.ai/leaderboards/models, 2026. Accessed: 2026-05-05
2026
-
[10]
MINT: Securely Mitigating Rowhammer with a Minimalist in-DRAM Tracker ,
Jehyeon Bang, Yujeong Choi, Myeongwoo Kim, Yongdeok Kim, and Minsoo Rhu. vTrain: A simulation framework for evaluating cost-effective and compute-optimal large language model training. In2024 57th IEEE/ACM International Symposium on Microarchitecture (MICRO), pages 153–167. IEEE, 2024. doi: 10.1109/MICRO61859.2024.00021
-
[11]
Jahs-bench-201: A foundation for research on joint architecture and hyperparameter search.Advances in Neural Information Processing Systems, 35:38788–38802, 2022
Archit Bansal, Danny Stoll, Maciej Janowski, Arber Zela, and Frank Hutter. Jahs-bench-201: A foundation for research on joint architecture and hyperparameter search.Advances in Neural Information Processing Systems, 35:38788–38802, 2022
2022
-
[12]
Barbarians at the gate: How AI is upending systems research
Audrey Cheng, Shu Liu, Melissa Pan, Zhifei Li, Bowen Wang, Alex Krentsel, Tian Xia, Mert Cemri, Jongseok Park, Shuo Yang, et al. Barbarians at the gate: How ai is upending systems research.arXiv preprint arXiv:2510.06189, 2025
-
[13]
Llmservingsim: A hw/sw co-simulation infrastructure for llm inference serving at scale
Jaehong Cho, Minsu Kim, Hyunmin Choi, Guseul Heo, and Jongse Park. Llmservingsim: A hw/sw co-simulation infrastructure for llm inference serving at scale. In2024 IEEE International Symposium on Workload Characterization (IISWC), pages 15–29. IEEE, 2024. 10
2024
-
[14]
Palm: Scaling language modeling with pathways.Journal of machine learning research, 24(240):1–113, 2023
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin, Maarten Bosma, Gaurav Mishra, Adam Roberts, Paul Barham, Hyung Won Chung, Charles Sutton, Sebastian Gehrmann, et al. Palm: Scaling language modeling with pathways.Journal of machine learning research, 24(240):1–113, 2023
2023
- [15]
-
[16]
DAWNBench: An end-to-end deep learning benchmark and competition
Cody Coleman, Deepak Narayanan, Daniel Kang, Tian Zhao, Jian Zhang, Luigi Nardi, Peter Bailis, Kunle Olukotun, Christopher Ré, and Matei Zaharia. DAWNBench: An end-to-end deep learning benchmark and competition. InNIPS ML Systems Workshop, 2017
2017
-
[17]
Efficient allreduce with stragglers, 2025
Arjun Devraj, Eric Ding, Abhishek Vijaya Kumar, Robert Kleinberg, and Rachee Singh. Efficient allreduce with stragglers, 2025. URLhttps://arxiv.org/abs/2505.23523
-
[18]
Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
William Fedus, Barret Zoph, and Noam Shazeer. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity.Journal of Machine Learning Research, 23(120):1–39, 2022
2022
-
[19]
Distributed training of large language models on aws trainium
Xinwei Fu, Zhen Zhang, Haozheng Fan, Guangtai Huang, Mohammad El-Shabani, Randy Huang, Rahul Solanki, Fei Wu, Ron Diamant, and Yida Wang. Distributed training of large language models on aws trainium. InProceedings of the 2024 ACM Symposium on Cloud Computing, pages 961–976, 2024
2024
-
[20]
Introducing Cloud TPU v5p and AI Hypercom- puter
Google Cloud. Introducing Cloud TPU v5p and AI Hypercom- puter. https://cloud.google.com/blog/products/ai-machine-learning/ introducing-cloud-tpu-v5p-and-ai-hypercomputer, 2023. Accessed 2026-04-26
2023
-
[21]
From LLMs to image generation: Accelerate inference workloads with AI Hypercomputer
Google Cloud. From LLMs to image generation: Accelerate inference workloads with AI Hypercomputer. https://cloud.google.com/blog/products/compute/ ai-hypercomputer-inference-updates-for-google-cloud-tpu-and-gpu , 2025. Accessed 2026-04-26
2025
-
[22]
Tensor processing units (tpus)
Google Cloud. Tensor processing units (tpus). https://cloud.google.com/tpu?hl=en, 2026. Ac- cessed: 2026-05-06
2026
-
[23]
Cloud TPU v6e
Google Cloud. Cloud TPU v6e. https://cloud.google.com/tpu/docs/v6e, 2026. Accessed: 2026- 05-06
2026
- [24]
-
[25]
LLM-Perf Leaderboard
Hugging Face Optimum Team. LLM-Perf Leaderboard. https://huggingface.co/spaces/optimum/ llm-perf-leaderboard, 2024. Accessed: 2026-05-05
2024
-
[26]
MSCCL++: Rethinking GPU communication abstractions for AI inference
Changho Hwang, Peng Cheng, Roshan Dathathri, Abhinav Jangda, Saeed Maleki, Madan Musuvathi, Olli Saarikivi, Aashaka Shah, Ziyue Yang, Binyang Li, Caio Rocha, Qinghua Zhou, Mahdieh Ghazimirsaeed, Sreevatsa Anantharamu, and Jithin Jose. MSCCL++: Rethinking GPU communication abstractions for AI inference. InACM International Conference on Architectural Suppo...
2026
-
[27]
Beyond data and model parallelism for deep neural networks
Zhihao Jia, Matei Zaharia, and Alex Aiken. Beyond data and model parallelism for deep neural networks. InMLSys, 2019
2019
-
[28]
Yinsicheng Jiang, Yao Fu, Yeqi Huang, Ping Nie, Zhan Lu, Leyang Xue, Congjie He, Man-Kit Sit, Jilong Xue, Li Dong, et al. Moe-cap: Benchmarking cost, accuracy and performance of sparse mixture-of-experts systems.arXiv preprint arXiv:2412.07067, 2024
-
[29]
Norman P. Jouppi, George Kurian, Sheng Li, Peter Ma, Rahul Nagarajan, Lifeng Nai, Nishant Patil, Suvinay Subramanian, Andy Swing, Brian Towles, Cliff Young, Xiang Zhou, Zongwei Zhou, and David Patterson. TPU v4: An optically reconfigurable supercomputer for machine learning with hardware support for embeddings. InProceedings of the 50th Annual Internation...
-
[30]
doi: 10.1145/3579371.3589350
-
[31]
Technology-driven, highly-scalable dragonfly topology.ACM SIGARCH Computer Architecture News, 36(3):77–88, 2008
John Kim, Wiliam J Dally, Steve Scott, and Dennis Abts. Technology-driven, highly-scalable dragonfly topology.ACM SIGARCH Computer Architecture News, 36(3):77–88, 2008
2008
-
[32]
Efficient memory management for large language model serving with pagedattention
Woosuk Kwon, Zhuohan Li, Siyuan Zhuang, Ying Sheng, Lianmin Zheng, Cody Hao Yu, Joseph Gonzalez, Hao Zhang, and Ion Stoica. Efficient memory management for large language model serving with pagedattention. InProceedings of the 29th symposium on operating systems principles, pages 611–626, 2023. 11
2023
-
[33]
XSP: Across- stack profiling and analysis of machine learning models on GPUs
Cheng Li, Abdul Dakkak, Jinjun Xiong, Wei Wei, Lingjie Xu, and Wen-Mei Hwu. XSP: Across- stack profiling and analysis of machine learning models on GPUs. InProceedings of the 34th IEEE International Parallel and Distributed Processing Symposium (IPDPS), pages 326–327. IEEE, 2020. doi: 10.1109/IPDPS47924.2020.00042
-
[34]
Lumos: Efficient performance modeling and estimation for large-scale llm training.Proceedings of Machine Learning and Systems, 7, 2025
Mingyu Liang, Hiwot T Kassa, Wenyin Fu, Brian Coutinho, Louis Feng, and Christina Delimitrou. Lumos: Efficient performance modeling and estimation for large-scale llm training.Proceedings of Machine Learning and Systems, 7, 2025
2025
-
[35]
Wanchao Liang, Tianyu Liu, Less Wright, Will Constable, Andrew Gu, Chien-Chin Huang, Iris Zhang, Wei Feng, Howard Huang, Junjie Wang, et al. Torchtitan: One-stop pytorch native solution for production ready llm pre-training.arXiv preprint arXiv:2410.06511, 2024
-
[36]
Mlperf training benchmark.Proceedings of Machine Learning and Systems, 2:336–349, 2020
Peter Mattson, Christine Cheng, Gregory Diamos, Cody Coleman, Paulius Micikevicius, David Patterson, Hanlin Tang, Gu-Yeon Wei, Peter Bailis, Victor Bittorf, et al. Mlperf training benchmark.Proceedings of Machine Learning and Systems, 2:336–349, 2020
2020
-
[37]
MTIA v1: Meta’s first-generation AI inference accelerator
Meta. MTIA v1: Meta’s first-generation AI inference accelerator. https://ai.meta.com/blog/ meta-training-inference-accelerator-AI-MTIA/, 2023. Accessed: 2026-05-04
2023
-
[38]
Holistic trace analysis
Meta Platforms, Inc. Holistic trace analysis. https://hta.readthedocs.io/en/latest/, 2024. Accessed 2026-04-22
2024
-
[39]
Galvatron: Efficient transformer training over multiple GPUs using automatic parallelism
Xupeng Miao, Yujie Wang, Youhe Jiang, Chunan Shi, Xiaonan Nie, Hailin Zhang, and Bin Cui. Galvatron: Efficient transformer training over multiple GPUs using automatic parallelism. InVLDB, 2023
2023
-
[40]
MSCCL++: A GPU-driven communication stack for scalable AI applications
Microsoft. MSCCL++: A GPU-driven communication stack for scalable AI applications. https: //github.com/microsoft/mscclpp, 2026. Accessed 2026-04-26
2026
-
[41]
Microsoft azure.https://azure.microsoft.com/en-us, 2026
Microsoft. Microsoft azure.https://azure.microsoft.com/en-us, 2026. Accessed: 2026-05-06
2026
-
[42]
MLCommons. Chakra. https://mlcommons.org/working-groups/research/chakra/, 2026. Ac- cessed 2026-04-22
2026
-
[43]
Efficient large-scale language model training on gpu clusters using megatron-lm
Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGresley, Mostofa Patwary, Vijay Anand Korthikanti, Dmitri Vainbrand, Prethvi Kashinkunti, Julie Bernauer, Bryan Catanzaro, Amar Phanishayee, and Matei Zaharia. Efficient large-scale language model training on gpu clusters using megatron-lm. In Proceedings of the International Conference for High ...
-
[44]
Perlmutter architecture
National Energy Research Scientific Computing Center. Perlmutter architecture. https://docs.nersc. gov/systems/perlmutter/architecture/, 2026. Accessed: 2026-05-06
2026
-
[45]
H100 GPUs Set Standard for Gen AI in Debut MLPerf Benchmark
NVIDIA. H100 GPUs Set Standard for Gen AI in Debut MLPerf Benchmark. https://blogs.nvidia. com/blog/generative-ai-debut-mlperf/, 2023. Accessed 2026-04-26
2023
-
[46]
NVIDIA Blackwell takes pole position in latest MLPerf inference results
NVIDIA. NVIDIA Blackwell takes pole position in latest MLPerf inference results. https://blogs. nvidia.com/blog/blackwell-mlperf-inference/, 2025. Accessed 2026-04-26
2025
-
[47]
NVIDIA Blackwell Ultra sets the bar in new MLPerf inference benchmark
NVIDIA. NVIDIA Blackwell Ultra sets the bar in new MLPerf inference benchmark. https://blogs. nvidia.com/blog/mlperf-inference-blackwell-ultra/, 2025. Accessed 2026-04-26
2025
-
[48]
Understanding NCCL tuning to accelerate GPU-to- GPU communication
NVIDIA. Understanding NCCL tuning to accelerate GPU-to- GPU communication. https://developer.nvidia.com/blog/ understanding-nccl-tuning-to-accelerate-gpu-to-gpu-communication/ , 2025. Accessed 2026-04-26
2025
-
[49]
NVIDIA wins every MLPerf Training v5.1 benchmark
NVIDIA. NVIDIA wins every MLPerf Training v5.1 benchmark. https://blogs.nvidia.com/blog/ mlperf-training-benchmark-blackwell-ultra/, 2025. Accessed 2026-04-26
2025
-
[50]
Nvidia collective communication library (NCCL) documentation
NVIDIA. Nvidia collective communication library (NCCL) documentation. https://docs.nvidia. com/deeplearning/nccl/user-guide/docs/, 2026. Accessed: 2026-05-04
2026
-
[51]
NCCL Tests.https://github.com/NVIDIA/nccl-tests, 2026
NVIDIA. NCCL Tests.https://github.com/NVIDIA/nccl-tests, 2026. Accessed 2026-04-26
2026
-
[52]
NVIDIA Nsight Systems
NVIDIA. NVIDIA Nsight Systems. https://docs.nvidia.com/nsight-systems/, 2026. Accessed: 2026-05-06
2026
-
[53]
NVIDIA NVLink and NVLink Switch
NVIDIA. NVIDIA NVLink and NVLink Switch. https://www.nvidia.com/en-us/data-center/ nvlink/, 2026. Accessed: 2026-05-06. 12
2026
-
[54]
XLA Operation Semantics
OpenXLA Project. XLA Operation Semantics. https://openxla.org/xla/operation_semantics,
-
[55]
Accessed: 2026-05-06
2026
-
[56]
Profiling jax computations with xprof
OpenXLA Project. Profiling jax computations with xprof. https://openxla.org/xprof/jax_ profiling, 2026. Accessed: 2026-05-05
2026
-
[57]
Splitwise: Efficient generative llm inference using phase splitting
Pratyush Patel, Esha Choukse, Chaojie Zhang, Aashaka Shah, Íñigo Goiri, Saeed Maleki, and Ricardo Bianchini. Splitwise: Efficient generative llm inference using phase splitting. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), pages 118–132. IEEE, 2024
2024
-
[58]
Accelerating PyTorch with CUDA Graphs
PyTorch. Accelerating PyTorch with CUDA Graphs. https://pytorch.org/blog/ accelerating-pytorch-with-cuda-graphs/, 2021. Accessed: 2026-05-05
2021
-
[59]
Libkineto readme
PyTorch Foundation. Libkineto readme. https://github.com/pytorch/kineto/blob/main/ libkineto/README.md, 2026. Accessed 2026-04-23
2026
-
[60]
Alibaba hpn: A data center network for large language model training
Kun Qian, Yongqing Xi, Jiamin Cao, Jiaqi Gao, Yichi Xu, Yu Guan, Binzhang Fu, Xuemei Shi, Fangbo Zhu, Rui Miao, et al. Alibaba hpn: A data center network for large language model training. InProceedings of the ACM SIGCOMM 2024 Conference, pages 691–706, 2024
2024
-
[61]
Zero: Memory optimizations toward training trillion parameter models
Samyam Rajbhandari, Jeff Rasley, Olatunji Ruwase, and Yuxiong He. Zero: Memory optimizations toward training trillion parameter models. InSC20: international conference for high performance computing, networking, storage and analysis, pages 1–16. IEEE, 2020
2020
-
[62]
Zero-infinity: Breaking the gpu memory wall for extreme scale deep learning
Samyam Rajbhandari, Olatunji Ruwase, Jeff Rasley, Shaden Smith, and Yuxiong He. Zero-infinity: Breaking the gpu memory wall for extreme scale deep learning. InProceedings of the international conference for high performance computing, networking, storage and analysis, pages 1–14, 2021
2021
-
[63]
MLPerf inference benchmark
Vijay Janapa Reddi, Christine Cheng, David Kanter, Peter Mattson, Guenther Schmuelling, Carole-Jean Wu, Brian Anderson, Maximilien Breez, et al. MLPerf inference benchmark. InISCA, 2020
2020
-
[64]
ZeRO-Offload: Democratizing Billion-Scale model training
Jie Ren, Samyam Rajbhandari, Reza Yazdani Aminabadi, Olatunji Ruwase, Shuangyan Yang, Minjia Zhang, Dong Li, and Yuxiong He. ZeRO-Offload: Democratizing Billion-Scale model training. In2021 USENIX Annual Technical Conference (USENIX ATC 21), pages 551–564. USENIX Association, July 2021. ISBN 978-1-939133-23-6. URL https://www.usenix.org/conference/atc21/p...
2021
-
[65]
Xla: Compiling machine learning for peak performance
Amit Sabne. Xla: Compiling machine learning for peak performance. 2020
2020
-
[66]
InferenceX: Inference benchmarking
SemiAnalysis. InferenceX: Inference benchmarking. https://inferencex.semianalysis.com/ inference, 2026. Accessed 2026-04-26
2026
-
[67]
SGLang bench serving guide
SGLang Team. SGLang bench serving guide. https://github.com/sgl-project/sglang/blob/ main/docs/developer_guide/bench_serving.md, 2026. Accessed 2026-04-26
2026
-
[68]
SGLang documentation.https://docs.sglang.io/, 2026
SGLang Team. SGLang documentation.https://docs.sglang.io/, 2026. Accessed 2026-04-26
2026
-
[69]
Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism
Mohammad Shoeybi, Mostofa Patwary, Raul Puri, Patrick LeGresley, Jared Casper, and Bryan Catanzaro. Megatron-lm: Training multi-billion parameter language models using model parallelism.arXiv preprint arXiv:1909.08053, 2019
work page internal anchor Pith review arXiv 1909
-
[70]
Dynamollm: Designing llm inference clusters for performance and energy efficiency
Jovan Stojkovic, Chaojie Zhang, Íñigo Goiri, Josep Torrellas, and Esha Choukse. Dynamollm: Designing llm inference clusters for performance and energy efficiency. In2025 IEEE International Symposium on High Performance Computer Architecture (HPCA), pages 1348–1362. IEEE, 2025
2025
-
[71]
Triton: an intermediate language and compiler for tiled neural network computations
Philippe Tillet, Hsiang-Tsung Kung, and David Cox. Triton: an intermediate language and compiler for tiled neural network computations. InProceedings of the 3rd ACM SIGPLAN International Workshop on Machine Learning and Programming Languages, pages 10–19, 2019
2019
-
[72]
Ultra Accelerator Link (UALink) 200G 1.0 Specification
UALink Consortium. Ultra Accelerator Link (UALink) 200G 1.0 Specification. https:// ualinkconsortium.org/specification/, 2026. Accessed: 2026-05-06
2026
-
[73]
vLLM Bench Latency
vLLM Project. vLLM Bench Latency. https://docs.vllm.ai/en/stable/cli/bench/latency/. Accessed: 2026-05-05
2026
-
[74]
vLLM v0.6.0: 2.7x throughput improvement and 5x latency reduction
vLLM Team. vLLM v0.6.0: 2.7x throughput improvement and 5x latency reduction. https://vllm.ai/ blog/perf-update, 2024. Accessed 2026-04-26. 13
2024
-
[75]
vLLM benchmarks
vLLM Team. vLLM benchmarks. https://docs.vllm.ai/en/v0.14.1/api/vllm/benchmarks/,
-
[76]
SimAI: Unifying architecture design and performance tuning for large-scale large language model training with scalability and precision.NSDI, 2025
Xizheng Wang et al. SimAI: Unifying architecture design and performance tuning for large-scale large language model training with scalability and precision.NSDI, 2025
2025
-
[77]
A systematic methodology for analysis of deep learning hardware and software platforms.Proceedings of Machine Learning and Systems, 2:30–43, 2020
Yu Wang, Gu-Yeon Wei, and David Brooks. A systematic methodology for analysis of deep learning hardware and software platforms.Proceedings of Machine Learning and Systems, 2:30–43, 2020
2020
-
[78]
Burstgpt: A real-world workload dataset to optimize llm serving systems
Yuxin Wang, Yuhan Chen, Zeyu Li, Xueze Kang, Yuchu Fang, Yeju Zhou, Yang Zheng, Zhenheng Tang, Xin He, Rui Guo, et al. Burstgpt: A real-world workload dataset to optimize llm serving systems. In Proceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, pages 5831–5841, 2025
2025
-
[79]
William Won, Taekyung Shi, Dhruvit Ajith, Saeed Sudarshan, Adarsh Ravichandran, and Tushar Krishna. ASTRA-sim2.0: Modeling hierarchical networks and disaggregated systems for large-model training at scale.arXiv preprint arXiv:2303.14006, 2023
-
[80]
LLMCompass: Enabling efficient hardware design for large language model inference
Hengrui Zhang, August Ning, Rohan Baskar Prabhakar, and David Wentzlaff. LLMCompass: Enabling efficient hardware design for large language model inference. In2024 ACM/IEEE 51st Annual International Symposium on Computer Architecture (ISCA), pages 1080–1096. IEEE, 2024. doi: 10.1109/ISCA59077. 2024.00082
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.