Recognition: unknown
Long Context Pre-Training with Lighthouse Attention
Pith reviewed 2026-05-08 10:05 UTC · model grok-4.3
The pith
Lighthouse Attention enables faster pre-training of long-context transformers by using hierarchical compression for most training before a short full-attention recovery phase.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Lighthouse Attention is a training-only symmetrical selection-based hierarchical attention algorithm that wraps ordinary scaled dot-product attention. It introduces a subquadratic pre- and post-processing step for adaptive compression and decompression of the sequence, using symmetrical pooling of queries, keys, and values that maintains causality. A two-stage training process pre-trains for the bulk of steps with Lighthouse Attention and concludes with a short full-attention recovery phase, producing a deployable full-attention model. Preliminary small-scale LLM pre-training runs demonstrate faster overall training time and lower final loss than matched full-attention baselines.
What carries the argument
Lighthouse Attention, a gradient-free symmetrical selection-based hierarchical wrapper around scaled dot-product attention that performs adaptive sequence compression and decompression while preserving causality.
Load-bearing premise
The information lost during hierarchical compression can be reliably recovered in a short full-attention phase without introducing lasting biases or needing extensive extra training.
What would settle it
A controlled larger-scale experiment in which the final loss after the recovery phase is equal to or higher than that of a full-attention baseline trained for the same total steps.
Figures



read the original abstract
Training causal transformers at extreme sequence lengths is bottlenecked by the quadratic time and memory of scaled dot-product attention (SDPA). In this work, we propose Lighthouse Attention, a training-only symmetrical selection-based hierarchical attention algorithm that wraps around ordinary SDPA and can be easily removed towards the end of the training. Our hierarchical selection is also gradient-free, which exempts us from dealing with a complicated and potentially inefficient backward pass kernel. Our contribution is three-fold: (i) A subquadratic hierarchical pre- and post-processing step that does adaptive compression and decompression of the sequence. (ii) A symmetrical compression strategy that pools queries, keys and values at the same time, while preserving left-to-right causality, which greatly improves parallelism. (iii) A two stage training approach which we pre-train for the majority of the time with Lighthouse Attention and recover a full attention model at the end with a short training. We run preliminary small scale LLM pre-training experiments that show the effectiveness of our method compared to full attention training with all other settings matched, where we achieve a faster total training time and lower final loss after the recovery phase. Full code is available at: https://github.com/ighoshsubho/lighthouse-attention
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Lighthouse Attention, a training-only symmetrical selection-based hierarchical attention algorithm that wraps around standard scaled dot-product attention (SDPA). It introduces subquadratic hierarchical pre- and post-processing for adaptive compression and decompression of the sequence, a gradient-free symmetrical pooling strategy for queries, keys, and values that preserves left-to-right causality, and a two-stage training procedure in which the majority of pre-training uses Lighthouse Attention followed by a short full-attention recovery phase. Preliminary small-scale LLM pre-training experiments are claimed to show faster total training time and lower final loss relative to matched full-attention baselines, with open-source code provided.
Significance. If the approach proves robust at larger scales, it could meaningfully reduce the computational burden of long-context pre-training by allowing most steps to avoid quadratic attention costs while recovering a deployable full-attention model. The explicit release of code is a clear strength that enables direct verification and extension.
major comments (3)
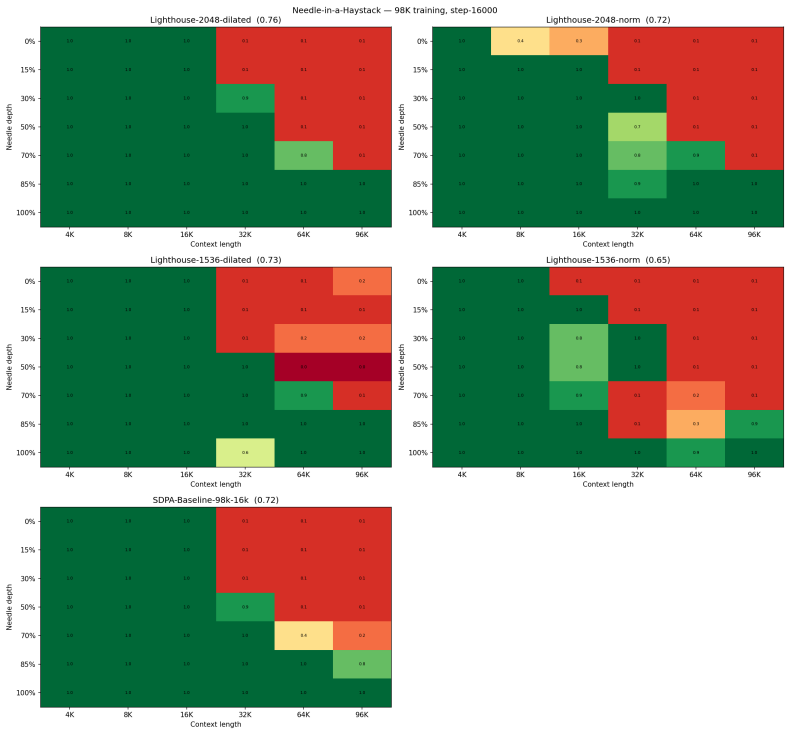
- [Abstract] Abstract: the claim that the method achieves 'faster total training time and lower final loss after the recovery phase' provides no quantitative values for model size, sequence length, total steps, recovery-phase length, speedup factor, or loss numbers, nor any loss curves or statistical details; this absence makes it impossible to assess whether the reported gains are load-bearing or artifacts of the small-scale setting.
- [Two-stage training approach] The two-stage training description: no analysis or ablation is given showing that the information discarded by the gradient-free symmetrical hierarchical pooling is reliably recoverable in a short full-attention phase without introducing persistent bias; the central efficiency claim rests on this unverified assumption.
- [Experimental results] Experimental validation: the manuscript reports only that results are 'preliminary' and 'small scale' with 'all other settings matched,' but supplies neither the exact experimental protocol, number of runs, nor any scaling behavior, leaving open whether the observed advantages hold beyond the tested regime.
minor comments (2)
- The description of the hierarchical selection mechanism would benefit from explicit pseudocode or a small diagram illustrating the simultaneous Q/K/V pooling and causality preservation.
- Notation for the compression levels and decompression step is introduced without a clear reference table or equation numbering, which reduces readability.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments identify areas where greater specificity and analysis would strengthen the manuscript. We address each major comment below and describe the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the method achieves 'faster total training time and lower final loss after the recovery phase' provides no quantitative values for model size, sequence length, total steps, recovery-phase length, speedup factor, or loss numbers, nor any loss curves or statistical details; this absence makes it impossible to assess whether the reported gains are load-bearing or artifacts of the small-scale setting.
Authors: We agree that the abstract would be more informative with concrete numbers. The full manuscript reports preliminary small-scale results, and we will revise the abstract to include specific values drawn from those experiments (model size, sequence length, total steps, recovery-phase length, observed speedup, and loss comparisons). We will also ensure loss curves and basic statistical details are referenced in the abstract and prominently displayed in the main text. revision: yes
-
Referee: [Two-stage training approach] The two-stage training description: no analysis or ablation is given showing that the information discarded by the gradient-free symmetrical hierarchical pooling is reliably recoverable in a short full-attention phase without introducing persistent bias; the central efficiency claim rests on this unverified assumption.
Authors: This observation is correct; we currently rely on the empirical outcome that the recovered model reaches lower loss than a matched full-attention baseline rather than on explicit ablations of recoverability. In the revision we will add an analysis subsection with ablations that vary recovery-phase length and track loss trajectories, to demonstrate that the information loss is not persistent and that convergence occurs within a short full-attention phase. revision: yes
-
Referee: [Experimental results] Experimental validation: the manuscript reports only that results are 'preliminary' and 'small scale' with 'all other settings matched,' but supplies neither the exact experimental protocol, number of runs, nor any scaling behavior, leaving open whether the observed advantages hold beyond the tested regime.
Authors: We will expand the experimental section to supply the complete protocol, all hyperparameters, data details, and the precise matching conditions used with the baseline. We performed multiple runs with different seeds and will report means with standard deviations. Regarding scaling, our current results are limited to the small-scale regime; we will add a discussion of observed limitations and expected scaling behavior, while acknowledging that large-scale validation lies outside the scope of this preliminary study. revision: partial
- Empirical demonstration that the observed advantages persist at larger model scales and longer sequences, which would require substantial additional compute beyond the resources available for this preliminary work.
Circularity Check
No circularity in algorithmic proposal or empirical validation
full rationale
The paper introduces Lighthouse Attention as a new training-only hierarchical attention wrapper around standard SDPA, with a symmetrical gradient-free compression step and a two-stage pre-train-then-recover procedure. No equations or first-principles derivations are presented that reduce claimed performance (faster training time, lower final loss) to quantities defined by the method's own fitted parameters or by construction. The experimental results are reported as independent small-scale validation runs with matched settings, not as outputs of any self-referential fitting or renaming process. No load-bearing self-citations, uniqueness theorems, or ansatzes imported from prior author work are invoked to justify the core claims. The derivation chain is therefore self-contained as an algorithmic contribution plus separate empirical check.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The Claude 3 model family, 2024
Anthropic. The Claude 3 model family, 2024. URLhttps://www.anthropic.com/news/ claude-3-family
2024
-
[2]
Zoology: Measuring and improving recall in efficient language models, 2024
S. Arora, S. Eyuboglu, A. Timalsina, I. Johnson, M. Poli, J. Zou, A. Rudra, and C. R ´e. Zoology: Measuring and improving recall in efficient language models. InICLR, 2024. arXiv:2312.04927
-
[3]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Y . Bengio, N. L´eonard, and A. Courville. Estimating or propagating gradients through stochas- tic neurons for conditional computation.arXiv preprint arXiv:1308.3432, 2013
work page internal anchor Pith review arXiv 2013
-
[4]
Choromanski, V
K. Choromanski, V . Likhosherstov, D. Dohan, X. Song, A. Gane, T. Sarlos, P. Hawkins, J. Davis, A. Mohiuddin, L. Kaiser, D. Belanger, L. Colwell, and A. Weller. Rethinking at- tention with Performers. InICLR, 2021
2021
-
[5]
T. Dao. FlashAttention-2: Faster attention with better parallelism and work partitioning. In ICLR, 2024. arXiv:2307.08691
work page internal anchor Pith review arXiv 2024
-
[6]
Dao and A
T. Dao and A. Gu. Transformers are SSMs: Generalized models and efficient algorithms through structured state space duality. InICML, 2024
2024
-
[7]
T. Dao, D. Y . Fu, S. Ermon, A. Rudra, and C. R´e. FlashAttention: Fast and memory-efficient exact attention with IO-awareness. InNeurIPS, 2022
2022
-
[8]
DeepSeek-AI. DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review arXiv 2024
-
[9]
DeepSeek-V3.2-Exp: Boosting long-context efficiency with DeepSeek sparse attention.arXiv preprint, 2025
DeepSeek-AI. DeepSeek-V3.2-Exp: Boosting long-context efficiency with DeepSeek sparse attention.arXiv preprint, 2025
2025
- [10]
-
[11]
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Gemini Team, Google DeepMind. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.arXiv preprint arXiv:2403.05530, 2024
work page internal anchor Pith review arXiv 2024
-
[12]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
A. Gu and T. Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023
work page internal anchor Pith review arXiv 2023
-
[13]
Guo et al
H. Guo et al. Log-linear attention.arXiv preprint, 2025
2025
-
[14]
E. Jang, S. Gu, and B. Poole. Categorical reparameterization with Gumbel-softmax. InInter- national Conference on Learning Representations (ICLR), 2017
2017
-
[15]
Minference 1.0: Ac- celerating pre-filling for long-context llms via dynamic sparse attention
H. Jiang, Y . Li, C. Zhang, Q. Wu, X. Luo, S. Ahn, Z. Han, A. H. Abdi, D. Li, C.-Y . Lin, Y . Yang, and L. Qiu. MInference 1.0: Accelerating pre-filling for long-context LLMs via dynamic sparse attention.arXiv preprint arXiv:2407.02490, 2024
-
[16]
Lai et al
X. Lai et al. FlexPrefill: A context-aware sparse attention mechanism for efficient long- sequence inference.arXiv preprint, 2025
2025
-
[17]
Y . Li, Y . Huang, B. Yang, B. Venkitesh, A. Locatelli, H. Ye, T. Cai, P. Lewis, and D. Chen. SnapKV: LLM knows what you are looking for before generation.arXiv preprint arXiv:2404.14469, 2024
work page internal anchor Pith review arXiv 2024
-
[18]
Lin et al
C. Lin et al. Twilight: Adaptive attention sparsity with hierarchical top-ppruning.arXiv preprint, 2025
2025
-
[19]
H. Liu, M. Zaharia, and P. Abbeel. Ring attention with blockwise transformers for near-infinite context.arXiv preprint arXiv:2310.01889, 2023
work page internal anchor Pith review arXiv 2023
- [20]
-
[21]
C. J. Maddison, A. Mnih, and Y . W. Teh. The concrete distribution: A continuous relaxation of discrete random variables. InInternational Conference on Learning Representations (ICLR), 2017
2017
-
[22]
Meta AI. The Llama 3 herd of models.arXiv preprint arXiv:2407.21783, 2024
work page internal anchor Pith review arXiv 2024
-
[23]
Kimi k1.5: Scaling Reinforcement Learning with LLMs
Moonshot AI. Kimi K1.5: Scaling reinforcement learning with llms.arXiv preprint arXiv:2501.12599, 2025
work page internal anchor Pith review arXiv 2025
-
[24]
Ni et al
Y . Ni et al. DoubleP: Hierarchical cluster-and-refine attention with centroid approximation. arXiv preprint, 2026
2026
-
[25]
OpenAI. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2024
work page internal anchor Pith review arXiv 2024
- [26]
-
[27]
Qwen Team. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2025
work page internal anchor Pith review arXiv 2025
-
[28]
Ribar, I
L. Ribar, I. Chelombiev, L. Hudlass-Galley, C. Blake, C. Luschi, and D. Orr. SparQ atten- tion: Bandwidth-efficient LLM inference. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[29]
J. Shah, G. Bikshandi, Y . Zhang, V . Thakkar, P. Ramani, and T. Dao. FlashAttention-3: Fast and accurate attention with asynchrony and low-precision. InAdvances in Neural Information Processing Systems (NeurIPS), 2024
2024
-
[30]
Y . Sun, L. Dong, S. Huang, S. Ma, Y . Xia, J. Xue, J. Wang, and F. Wei. Retentive network: A successor to transformer for large language models.arXiv preprint arXiv:2307.08621, 2023
work page internal anchor Pith review arXiv 2023
-
[31]
J. Tang, Y . Zhao, K. Zhu, G. Xiao, B. Kasikci, and S. Han. Quest: Query-aware sparsity for efficient long-context LLM inference. InInternational Conference on Machine Learning (ICML), 2024
2024
-
[32]
G. Xiao, Y . Tian, B. Chen, S. Han, and M. Lewis. Efficient streaming language models with attention sinks. InInternational Conference on Learning Representations (ICLR), 2024
2024
-
[33]
Xu et al
R. Xu et al. XAttention: Block sparse attention with antidiagonal scoring.arXiv preprint, 2025
2025
- [34]
-
[35]
Z. Yang, D. Yang, C. Dyer, X. He, A. Smola, and E. Hovy. Hierarchical attention networks for document classification. InNAACL, 2016
2016
- [36]
-
[37]
Zhang et al
J. Zhang et al. SpargeAttention: Accurate and training-free sparse attention accelerating any model inference.arXiv preprint, 2025
2025
-
[38]
Zhang, Y
Z. Zhang, Y . Sheng, T. Zhou, T. Chen, L. Zheng, R. Cai, Z. Song, Y . Tian, C. R´e, C. Barrett, Z. Wang, and B. Chen. H 2O: Heavy-hitter oracle for efficient generative inference of large language models. InAdvances in Neural Information Processing Systems (NeurIPS), 2023
2023
-
[39]
arXiv preprint arXiv:2306.14048 , year=
Z. Zhang, Y . Sheng, T. Zhou, T. Chen, L. Zheng, R. Cai, Z. Song, Y . Tian, C. R´e, C. Barrett, Z. Wang, and B. Chen. H2O: Heavy-hitter oracle for efficient generative inference of large language models. InNeurIPS, 2024. arXiv:2306.14048
-
[40]
HISA: Efficient Hierarchical Indexing for Fine-Grained Sparse Attention
L. Zhao et al. HISA: Efficient hierarchical indexing for fine-grained sparse attention.arXiv preprint arXiv:2603.28458, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[41]
what would softmax do,
L. Zhao et al. InfLLM-V2: Dense–sparse switchable attention for seamless short-to-long adaptation.arXiv preprint, 2026. 11 A Ablations Configuration Scorer Params LH Total Total B200-Hrs Tok/s (k) Final Loss Steps Steps Tokens (↓) (↑) (↓) SDPA Baseline (ctx= 98k) — 530M — 16k 50.3B 303.2 45.6 0.7237 SDPA recoverability (L=3, p=2, k=6144, ctx= 98k) LH→SDPA...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.