Recognition: 2 theorem links
· Lean TheoremHISA: Efficient Hierarchical Indexing for Fine-Grained Sparse Attention
Pith reviewed 2026-05-14 21:36 UTC · model grok-4.3
The pith
HISA replaces flat token scanning in sparse attention with a two-stage hierarchical procedure that keeps the exact same tokens selected while cutting computation at long contexts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
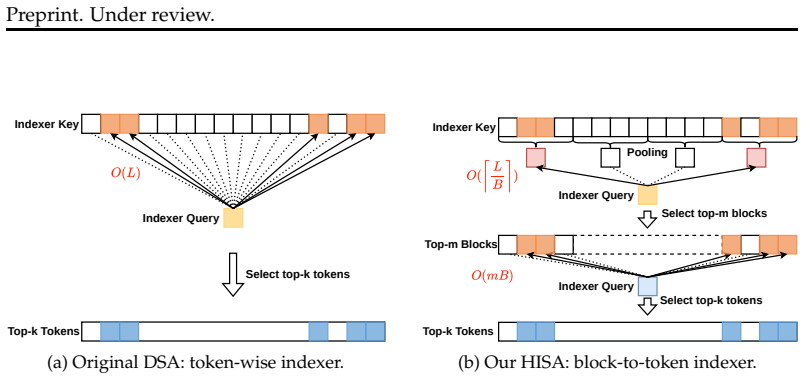
HISA rewrites the search path from a flat token scan into a two-stage hierarchical procedure: a block-level coarse filtering stage that scores pooled block representations to discard irrelevant regions, followed by a token-level refinement stage that applies the original indexer exclusively within the retained candidate blocks. It preserves the identical token-level top-sparse pattern consumed by the downstream Sparse MLA operator and requires no additional training.
What carries the argument
Two-stage hierarchical indexing that first filters at block level using pooled representations and then refines at token level only inside retained blocks.
If this is right
- Up to large speedup at 64K context on kernel-level benchmarks.
- Direct plug-in replacement in DeepSeek-V3.2 and GLM-5 matches original DSA quality on Needle-in-a-Haystack and LongBench with no finetuning.
- Substantially outperforms block-sparse baselines while retaining fine-grained token selection.
- Preserves identical token-level top-sparse patterns for any downstream Sparse MLA operator.
Where Pith is reading between the lines
- The same block-then-token pattern could be stacked into deeper hierarchies to push context lengths beyond current tested ranges.
- Any other token-level sparse indexer could be wrapped the same way, extending the speedup to additional attention variants.
- If the pooling step were made differentiable, the approach could be folded into training to learn better block representations.
Load-bearing premise
Block-level pooled representations are sufficient to discard irrelevant regions without excluding any blocks that contain tokens the original flat indexer would have selected.
What would settle it
A side-by-side run on a long-context benchmark where HISA and the original flat indexer produce different top-k token sets for the same queries and the quality gap becomes measurable.
Figures



read the original abstract
Token-level sparse attention mechanisms, exemplified by DeepSeek Sparse Attention (DSA), achieve fine-grained key selection by scoring every historical key for each query through a lightweight indexer, then computing attention only on the selected subset. While the downstream sparse attention itself scales favorably, the indexer must still scan the entire prefix for every query, introducing an per-layer bottleneck that grows prohibitively with context length. We propose HISA (Hierarchical Indexed Sparse Attention), a plug-and-play replacement for the indexer that rewrites the search path from a flat token scan into a two-stage hierarchical procedure: (1) a block-level coarse filtering stage that scores pooled block representations to discard irrelevant regions, followed by (2) a token-level refinement stage that applies the original indexer exclusively within the retained candidate blocks. HISA preserves the identical token-level top-sparse pattern consumed by the downstream Sparse MLA operator and requires no additional training. On kernel-level benchmarks, HISA achieves up to speedup at 64K context. On Needle-in-a-Haystack and LongBench, we directly replace the indexer in DeepSeek-V3.2 and GLM-5 with our HISA indexer, without any finetuning. HISA closely matches the original DSA in quality, while substantially outperforming block-sparse baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents HISA, an efficient hierarchical indexing method for fine-grained sparse attention. It replaces the flat scan of the original indexer (as in DeepSeek Sparse Attention) with a two-stage process consisting of block-level coarse filtering using pooled representations to prune irrelevant regions, followed by token-level refinement within the retained blocks. The key claims are that this preserves the exact same token-level top-sparse pattern as the original method without any additional training or parameters, achieves substantial kernel speedups at long contexts such as 64K, and maintains matching quality on tasks like Needle-in-a-Haystack and LongBench when substituted into models such as DeepSeek-V3.2 and GLM-5.
Significance. Should the preservation of the identical top-k token set be rigorously established, HISA would provide a valuable optimization for scaling sparse attention mechanisms to longer sequences by reducing the indexer's computational cost from linear in context length to sublinear, without compromising the downstream attention quality or requiring model retraining. This is particularly relevant for efficient inference in large language models handling extended contexts. The parameter-free nature and plug-and-play integration are notable strengths.
major comments (3)
- [Abstract] Abstract: The central claim that HISA 'preserves the identical token-level top-sparse pattern consumed by the downstream Sparse MLA operator' is load-bearing for the quality results yet unsupported by any proof, bound, or verification that block-level pooled scoring (max/mean over keys) never discards a block containing a token the flat indexer would have selected. Pooled block scores can be low despite a single high-scoring token inside the block.
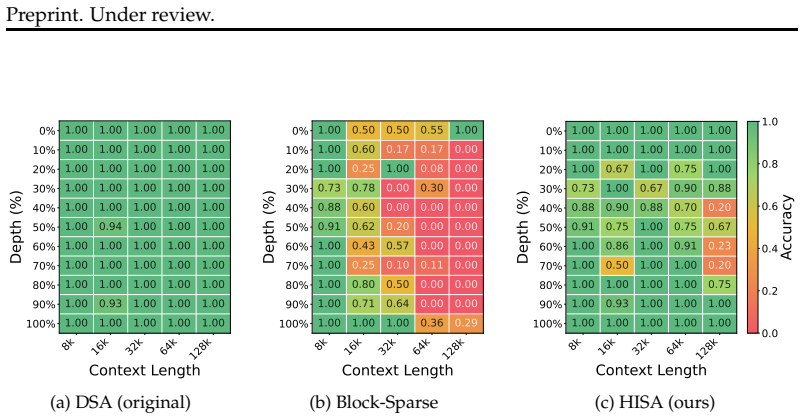
- [Experimental Evaluation] Experimental Evaluation: The manuscript supplies no explicit check or statistic confirming that the output token-level top-k set is identical to the original DSA indexer on the Needle-in-a-Haystack or LongBench runs; without this, the 'closely matches' quality claim cannot be assessed as exact preservation rather than approximate.
- [Kernel Benchmarks] Kernel Benchmarks: Exact numerical speedup factors at 64K context, block size definition, pooling operator, and retention threshold are not reported, preventing quantitative evaluation of the claimed efficiency gains or reproduction of the hierarchical procedure.
minor comments (1)
- [Abstract] The abstract contains the placeholder phrase 'up to speedup' that should be replaced with the concrete factor achieved.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which helps clarify the presentation of our claims and implementation details. We address each major comment below and will revise the manuscript to incorporate additional verification, statistics, and specifications as outlined.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that HISA 'preserves the identical token-level top-sparse pattern consumed by the downstream Sparse MLA operator' is load-bearing for the quality results yet unsupported by any proof, bound, or verification that block-level pooled scoring (max/mean over keys) never discards a block containing a token the flat indexer would have selected. Pooled block scores can be low despite a single high-scoring token inside the block.
Authors: We acknowledge that the current manuscript does not include a formal proof or explicit verification of exact top-k preservation. The design uses max-pooling over block keys precisely to ensure that any block containing a high-scoring token receives an elevated block score and is retained for the token-level stage, preventing the scenario described. In the revision we will add both a brief argument for this property and empirical verification that the final token sets match the flat indexer on the reported benchmarks. revision: yes
-
Referee: [Experimental Evaluation] Experimental Evaluation: The manuscript supplies no explicit check or statistic confirming that the output token-level top-k set is identical to the original DSA indexer on the Needle-in-a-Haystack or LongBench runs; without this, the 'closely matches' quality claim cannot be assessed as exact preservation rather than approximate.
Authors: We will add explicit statistics (e.g., exact match rate of the top-k token sets) in the experimental evaluation section for both Needle-in-a-Haystack and LongBench runs, confirming identity with the original DSA indexer. This will allow readers to assess exact preservation directly. revision: yes
-
Referee: [Kernel Benchmarks] Kernel Benchmarks: Exact numerical speedup factors at 64K context, block size definition, pooling operator, and retention threshold are not reported, preventing quantitative evaluation of the claimed efficiency gains or reproduction of the hierarchical procedure.
Authors: We will report the precise numerical speedup factors at 64K context, along with the block size, pooling operator (max-pooling), and retention threshold used in the kernel benchmarks section to enable full reproduction and quantitative assessment of the efficiency claims. revision: yes
Circularity Check
No significant circularity; HISA is a direct algorithmic redesign evaluated on external benchmarks
full rationale
The paper proposes a two-stage hierarchical indexer (block-level coarse filtering followed by token-level refinement using the original indexer) as a plug-and-play replacement. The claim that HISA preserves the identical token-level top-sparse pattern is presented as a property of this explicit design choice rather than a derived prediction or fitted result. No equations, self-citations, or uniqueness theorems are invoked in a load-bearing way; the method requires no additional training and is validated directly on Needle-in-a-Haystack and LongBench by replacing the indexer in existing models. The derivation chain is self-contained against external benchmarks with no reductions to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pooled block representations suffice for accurate coarse relevance scoring that does not discard needed tokens
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
HISA replaces the flat prefix scan with a two-stage coarse-to-fine search... block-level coarse filtering... token-level refinement... preserves the identical token-level top-k sparse pattern
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
per-query indexing cost drops from O(L) to O(L/B + mB)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Forward citations
Cited by 3 Pith papers
-
MISA: Mixture of Indexer Sparse Attention for Long-Context LLM Inference
MISA routes to a small subset of indexer heads via block statistics, matching full DSA performance on LongBench with 4-8x fewer heads and 3.82x speedup while recovering over 92% of selected tokens.
-
Long Context Pre-Training with Lighthouse Attention
Lighthouse Attention enables faster long-context pre-training via gradient-free symmetrical hierarchical compression of QKV while preserving causality, followed by a short full-attention recovery that yields lower los...
-
Guess-Verify-Refine: Data-Aware Top-K for Sparse-Attention Decoding on Blackwell via Temporal Correlation
GVR uses previous-step Top-K predictions, pre-indexed stats, secant counting, and shared-memory verification to deliver 1.88x average speedup over radix-select while preserving bit-exact Top-K on DeepSeek-V3.2 workloads.
Reference graph
Works this paper leans on
-
[1]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding
URL https://www.anthropic.com/news/ claude-sonnet-4-6. Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding.arXiv preprint arXiv:2308.14508,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Yushi Bai, Qian Dong, Ting Jiang, Xin Lv, Zhengxiao Du, Aohan Zeng, Jie Tang, and Juanzi Li. Indexcache: Accelerating sparse attention via cross-layer index reuse.arXiv preprint arXiv:2603.12201,
-
[3]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning
Tri Dao. Flashattention-2: Faster attention with better parallelism and work partitioning. arXiv preprint arXiv:2307.08691,
work page internal anchor Pith review Pith/arXiv arXiv
-
[4]
DeepSeek-AI. DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
DeepSeek-AI. Deepseek-v3.2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Qichen Fu, Minsik Cho, Thomas Merth, Sachin Mehta, Mohammad Rastegari, and Mahyar Najibi. Lazyllm: Dynamic token pruning for efficient long context LLM inference.arXiv preprint arXiv:2407.14057,
-
[7]
GLM-5: from Vibe Coding to Agentic Engineering
GLM-5-Team. Glm-5: from vibe coding to agentic engineering.arXiv preprint arXiv:2602.15763,
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
URLhttps://www.arxiv.org/abs/2407.02490. Greg Kamradt. Needle in a haystack — pressure testing llms
-
[10]
Moba: Mixture of block attention for long-context llms.arXiv preprint arXiv:2502.13189,
Enzhe Lu, Zhejun Jiang, Jingyuan Liu, Yulun Du, Tao Jiang, Chao Hong, Shaowei Liu, Weiran He, Enming Yuan, Yuzhi Wang, et al. Moba: Mixture of block attention for long-context llms.arXiv preprint arXiv:2502.13189,
-
[11]
MiniMax, Aonian Li, Bangwei Gong, Bo Yang, Boji Shan, Chang Liu, et al
URL https://ai.meta.com/blog/ llama-4-multimodal-intelligence/. MiniMax, Aonian Li, Bangwei Gong, Bo Yang, Boji Shan, Chang Liu, et al. MiniMax-01: Scaling foundation models with lightning attention.arXiv preprint arXiv:2501.08313,
-
[12]
Kimi K2: Open Agentic Intelligence
Moonshot AI. Kimi K2: Open agentic intelligence.arXiv preprint arXiv:2507.20534,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
10 Preprint. Under review. Wentao Ni, Kangqi Zhang, Zhongming Yu, Oren Nelson, Mingu Lee, Hong Cai, Fatih Porikli, Jongryool Kim, Zhijian Liu, and Jishen Zhao. Double-p: Hierarchical top-p sparse attention for long-context LLMs.arXiv preprint arXiv:2602.05191,
-
[14]
Matanel Oren, Michael Hassid, Nir Rosenfeld, Yossi Adi, and Roy Schwartz
URL https://openai.com/index/ gpt-5-4-thinking-system-card. Matanel Oren, Michael Hassid, Nir Rosenfeld, Yossi Adi, and Roy Schwartz. Transformers are multi-state RNNs. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing,
work page 2024
-
[15]
URL https://qwenlm.github. io/blog/qwen3.5. Lei Wang, Yu Cheng, Yining Shi, Zhengju Tang, Zhiwen Mo, Wenhao Xie, Lingxiao Ma, Yuqing Xia, Jilong Xue, Fan Yang, and Zhi Yang. Tilelang: A composable tile-based programming model for ai systems.arXiv preprint arXiv:2504.17577,
-
[16]
Hierarchi- cal attention networks for document classification
Zichao Yang, Diyi Yang, Chris Dyer, Xiaodong He, Alex Smola, and Eduard Hovy. Hierarchi- cal attention networks for document classification. InProceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pp. 1480–1489,
work page 2016
-
[18]
SnapKV: LLM Knows What You are Looking for Before Generation
URL https://www.arxiv. org/abs/2404.14469. Jintao Zhang, Chendong Xiang, Haofeng Huang, Jia Wei, Haocheng Xi, Jun Zhu, and Jianfei Chen. Spargeattention: Accurate and training-free sparse attention accelerating any model inference. InProceedings of the 42nd International Conference on Machine Learning,
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.