Recognition: unknown
Coordination Matters: Evaluation of Cooperative Multi-Agent Reinforcement Learning
Pith reviewed 2026-05-08 03:30 UTC · model grok-4.3
The pith
Similar returns in cooperative multi-agent reinforcement learning often mask distinct coordination mechanisms among agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
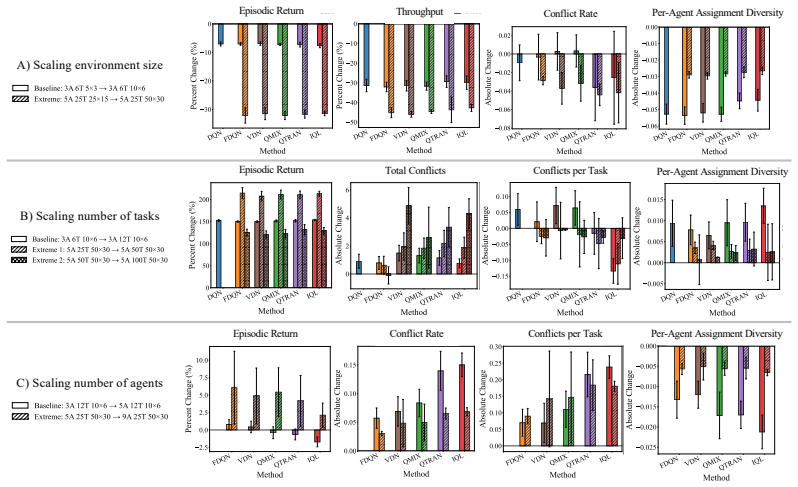
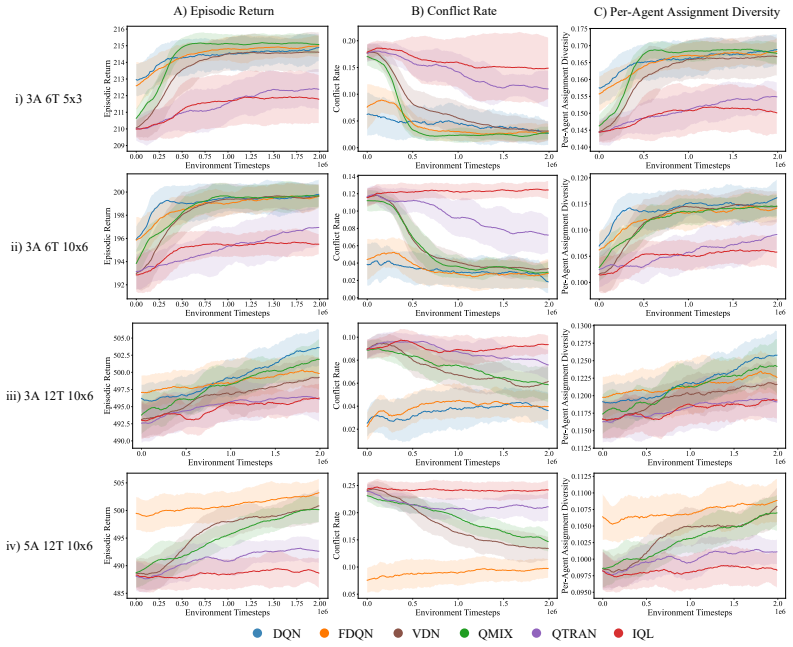
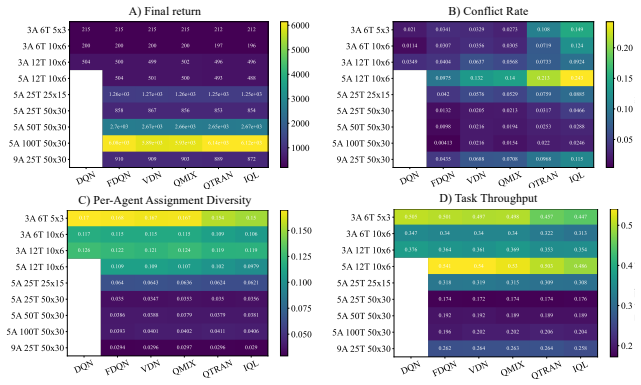
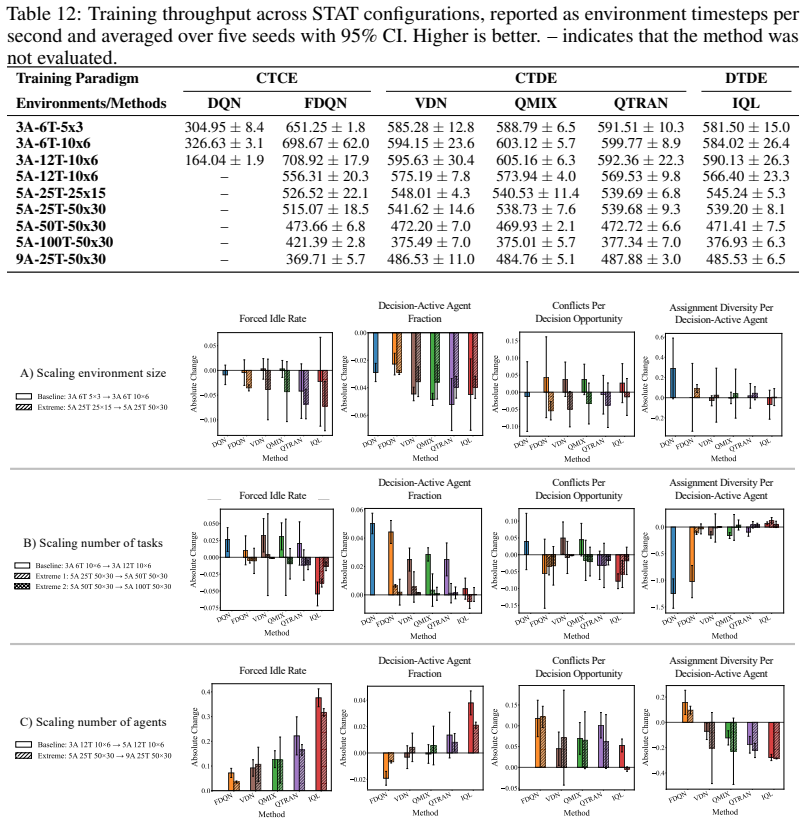
Similar return trends can reflect distinct coordination mechanisms, including differences in redundant assignment, assignment diversity, and task-completion efficiency. In commitment-constrained task allocation, performance under scale is shaped not only by nominal action-space size, but also by assignment pressure, sparse decision opportunities, and redundant choices among interdependent agents.
What carries the argument
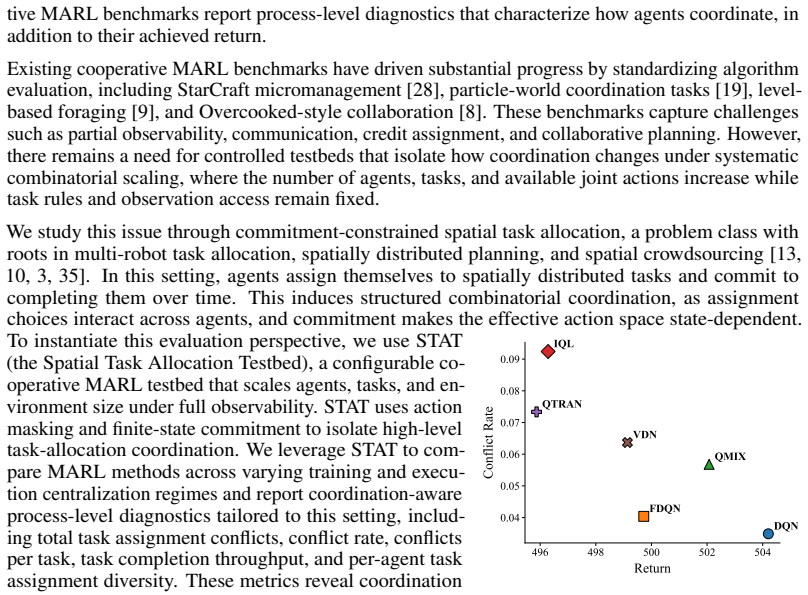
The STAT testbed, a controlled commitment-constrained spatial task-allocation environment that varies the number of agents, tasks, and environment size while holding observation access and task rules fixed, paired with process-level diagnostics that measure redundant assignment, assignment diversity, and task-completion efficiency.
If this is right
- Return-only evaluation can fail to distinguish coordination quality among value-based MARL methods even when aggregate scores look the same.
- Scaling performance in task allocation depends on assignment pressure and the presence of redundant choices, not solely on the size of the action space.
- Different centralization levels in MARL produce measurable variations in how often agents duplicate tasks or complete them efficiently.
- Process diagnostics provide a practical way to compare methods beyond what success rate or total return alone can show.
Where Pith is reading between the lines
- The same diagnostic approach could be adapted to other cooperative domains such as multi-robot navigation to detect hidden coordination failures.
- Training procedures might improve by adding explicit penalties for redundant assignments during learning.
- Benchmark suites for MARL could incorporate these process checks as standard reporting requirements to support fairer comparisons at larger scales.
Load-bearing premise
The selected process-level diagnostics and the controlled scale variations in the testbed capture the essential features of coordination in cooperative multi-agent settings.
What would settle it
A follow-up experiment in which two methods with different diagnostic profiles produce identical real-world coordination outcomes, such as the same rate of successful joint task completions without overlap, would challenge the claim that the diagnostics reveal meaningful differences.
Figures





read the original abstract
Cooperative multi-agent reinforcement learning (MARL) benchmarks commonly emphasize aggregate outcomes such as return, success rate, or completion time. While essential, these metrics often fail to reveal how agents coordinate, particularly in settings where agents, tasks, and joint assignment choices scale combinatorially. We propose a coordination-aware evaluation perspective that supplements return with process-level diagnostics. We instantiate this perspective using STAT, a controlled commitment-constrained spatial task-allocation testbed that systematically varies agents, tasks, and environment size while holding observation access and task rules fixed. We evaluate six representative value-based MARL methods across varying levels of centralization. Our results show that similar return trends can reflect distinct coordination mechanisms, including differences in redundant assignment, assignment diversity, and task-completion efficiency. We find that in commitment-constrained task allocation, performance under scale is shaped not only by nominal action-space size, but also by assignment pressure, sparse decision opportunities, and redundant choices among interdependent agents. Our findings motivate coordination-aware evaluation as a necessary complement to return-based benchmarking for cooperative MARL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that aggregate metrics such as return are insufficient to reveal coordination mechanisms in cooperative MARL, particularly under combinatorial scaling of agents and tasks. It introduces the STAT testbed—a commitment-constrained spatial task-allocation environment that varies agent count, task count, and environment size while fixing observation access and task rules—and evaluates six value-based MARL methods across centralization levels. The central empirical finding is that similar return trends can mask distinct coordination mechanisms (differences in redundant assignment, assignment diversity, and task-completion efficiency), and that performance under scale is shaped by assignment pressure, sparse decision opportunities, and redundant choices among interdependent agents.
Significance. If the empirical distinctions hold, the work is significant for motivating process-level diagnostics as a necessary complement to return-based benchmarking in cooperative MARL. The controlled STAT testbed enables systematic isolation of scaling factors, which is a methodological strength, and the focus on commitment-constrained allocation addresses a practically relevant setting. This could encourage more nuanced algorithm evaluation and design, especially for interdependent agent settings.
major comments (2)
- [Experiments section] Experiments section: the claims that similar return trends reflect distinct coordination mechanisms rest on observed differences in the process-level diagnostics, yet no statistical significance tests, error bars, number of independent runs, or data-exclusion rules are reported. Without these, it is impossible to determine whether the reported differences in redundant assignment or task-completion efficiency exceed experimental variance.
- [STAT testbed section] STAT testbed section: the central claim that the diagnostics isolate coordination mechanisms (assignment pressure, sparse decisions, redundant choices) independent of other factors is load-bearing for the generalizability argument. Because observation access and task rules are held fixed by construction, an ablation that perturbs the observation model or relaxes commitment constraints while holding nominal action-space size constant is needed to confirm the differences are not artifacts of the specific spatial layout or joint-action enumeration.
minor comments (2)
- [Abstract] Abstract: the six methods are referred to only as 'representative value-based MARL methods'; naming them (e.g., QMIX, VDN, etc.) would improve immediate clarity for readers.
- [Figures] Figures: legends and axis labels for the process-level diagnostic plots should explicitly define 'redundant assignment' and 'assignment diversity' to ensure the metrics are interpretable without returning to the text.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point by point below, indicating where revisions have been made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments section] Experiments section: the claims that similar return trends reflect distinct coordination mechanisms rest on observed differences in the process-level diagnostics, yet no statistical significance tests, error bars, number of independent runs, or data-exclusion rules are reported. Without these, it is impossible to determine whether the reported differences in redundant assignment or task-completion efficiency exceed experimental variance.
Authors: We agree that the original submission lacked sufficient statistical reporting to rigorously support the observed differences in process-level diagnostics. In the revised manuscript, we now report all results as means over 5 independent runs with distinct random seeds, include error bars denoting one standard deviation, explicitly state that no data points were excluded beyond standard convergence checks, and add paired statistical significance tests (t-tests with p < 0.05 threshold) on the differences in redundant assignment rates and task-completion efficiency. These additions confirm that the reported distinctions between methods exceed experimental variance. revision: yes
-
Referee: [STAT testbed section] STAT testbed section: the central claim that the diagnostics isolate coordination mechanisms (assignment pressure, sparse decisions, redundant choices) independent of other factors is load-bearing for the generalizability argument. Because observation access and task rules are held fixed by construction, an ablation that perturbs the observation model or relaxes commitment constraints while holding nominal action-space size constant is needed to confirm the differences are not artifacts of the specific spatial layout or joint-action enumeration.
Authors: We appreciate the referee's concern regarding potential artifacts. However, the STAT testbed is deliberately designed to hold observation access and task rules fixed precisely to isolate the effects of combinatorial scaling on coordination under commitment constraints. Introducing ablations that perturb the observation model or relax commitments would change the fundamental problem class, confounding the very scaling factors under study. Our generalizability claims are scoped to commitment-constrained spatial allocation with fixed rules; we have added a clarifying paragraph in the revised STAT testbed section explaining why the current controlled variations suffice to attribute differences to assignment pressure and inter-agent redundancy rather than layout or enumeration artifacts. revision: partial
Circularity Check
No circularity: purely empirical evaluation of existing methods on new testbed
full rationale
The paper introduces the STAT testbed and applies process-level diagnostics (redundant assignment, assignment diversity, task-completion efficiency) to evaluate six existing value-based MARL algorithms under controlled variations in agents, tasks, and environment size. No derivations, equations, fitted parameters, or predictions are claimed; results are direct experimental outcomes. No self-citations are load-bearing for the central claims, and the evaluation does not reduce any quantity to its own inputs by construction. The work is self-contained as an empirical benchmarking study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Value-based MARL methods are representative of the broader class of cooperative algorithms for the purpose of this evaluation.
invented entities (1)
-
STAT testbed
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Aakriti Agrawal, Amrit Singh Bedi, and Dinesh Manocha. Rtaw: An attention inspired reinforcement learning method for multi-robot task allocation in warehouse environments. arXiv preprint arXiv:2209.05738, 2022
-
[2]
Dc-mrta: Decen- tralized multi-robot task allocation and navigation in complex environments
Aakriti Agrawal, Senthil Hariharan, Amrit Singh Bedi, and Dinesh Manocha. Dc-mrta: Decen- tralized multi-robot task allocation and navigation in complex environments. In2022 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022
2022
-
[3]
Dynamic multi-agent task allocation with spatial and temporal constraints
Sofia Amador, Steven Okamoto, and Roie Zivan. Dynamic multi-agent task allocation with spatial and temporal constraints. InProceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, pages 1384–1390, 2014
2014
-
[4]
Who is helping whom? analyzing inter-dependencies to evaluate cooperation in human-ai teaming
Upasana Biswas, Vardhan Palod, Siddhant Bhambri, and Subbarao Kambhampati. Who is helping whom? analyzing inter-dependencies to evaluate cooperation in human-ai teaming. Proceedings of the AAAI Conference on Artificial Intelligence, 40(21):17347–17356, 2026
2026
-
[5]
Multi-agent reinforcement learning: A review of challenges and applications.Applied Sciences, 11(11):4948, 2021
Lorenzo Canese, Gian Carlo Cardarilli, Luca Di Nunzio, Rocco Fazzolari, Daniele Giardino, Marco Re, and Sergio Spanò. Multi-agent reinforcement learning: A review of challenges and applications.Applied Sciences, 11(11):4948, 2021
2021
-
[6]
Practical heuristics for victim tagging during a mass casualty incident emergency medical response
Maria Ana Cardei and Afsaneh Doryab. Practical heuristics for victim tagging during a mass casualty incident emergency medical response. In2024 IEEE 20th International Conference on Automation Science and Engineering (CASE), pages 165–172, 2024
2024
-
[7]
Factorized deep q-network for cooperative multi-agent reinforcement learning in victim tagging.IEEE Transactions on Automation Science and Engineering, 23:3109–3120, 2026
Maria Ana Cardei and Afsaneh Doryab. Factorized deep q-network for cooperative multi-agent reinforcement learning in victim tagging.IEEE Transactions on Automation Science and Engineering, 23:3109–3120, 2026
2026
-
[8]
Ho, Thomas L
Micah Carroll, Rohin Shah, Mark K. Ho, Thomas L. Griffiths, Sanjit A. Seshia, Pieter Abbeel, and Anca Dragan.On the utility of learning about humans for human-AI coordination. Curran Associates Inc., Red Hook, NY , USA, 2019
2019
-
[9]
Shared experience actor-critic for multi-agent reinforcement learning
Filippos Christianos, Lukas Schäfer, and Stefano V Albrecht. Shared experience actor-critic for multi-agent reinforcement learning. InAdvances in Neural Information Processing Systems (NeurIPS), 2020
2020
-
[10]
Oliehoek, Karl Tuyls, Daniel Hennes, and Wiebe van der Hoek
Daniel Claes, Philipp Robbel, Frans A. Oliehoek, Karl Tuyls, Daniel Hennes, and Wiebe van der Hoek. Effective approximations for multi-robot coordination in spatially distributed tasks. InProceedings of the 2015 International Conference on Autonomous Agents and Multiagent Systems, pages 881–890, Richland, SC, 2015. International Foundation for Autonomous ...
2015
-
[11]
Zhenhui Feng, Renbin Xiao, and Mingzhi Xiao. Spatial crowdsourcing task allocation for heterogeneous multi-task hybrid scenarios: A model-embedded role division approach.Frontiers of Information Technology & Electronic Engineering, 26:1144–1163, 2025
2025
-
[12]
Counterfactual multi-agent policy gradients
Jakob Foerster, Gregory Farquhar, Triantafyllos Afouras, Nantas Nardelli, and Shimon Whiteson. Counterfactual multi-agent policy gradients. InProceedings of the AAAI conference on artificial intelligence, volume 32, 2018
2018
-
[13]
A formal analysis and taxonomy of task allocation in multi-robot systems.The International journal of robotics research, 23(9):939–954, 2004
Brian P Gerkey and Maja J Matari ´c. A formal analysis and taxonomy of task allocation in multi-robot systems.The International journal of robotics research, 23(9):939–954, 2004
2004
-
[14]
A survey and critique of multiagent deep reinforcement learning.Autonomous Agents and Multi-Agent Systems, 33(6):750–797, 2019
Pablo Hernandez-Leal, Bilal Kartal, and Matthew E Taylor. A survey and critique of multiagent deep reinforcement learning.Autonomous Agents and Multi-Agent Systems, 33(6):750–797, 2019
2019
-
[15]
Policy diagnosis via measuring role diversity in cooperative multi-agent reinforcement learning
Siyi Hu, Fengda Zhu, Xiaojun Chang, and Xiaodan Liang. Policy diagnosis via measuring role diversity in cooperative multi-agent reinforcement learning. InProceedings of the 39th Inter- national Conference on Machine Learning, volume 162 ofProceedings of Machine Learning Research, pages 9041–9071. PMLR, 2022. 10
2022
-
[16]
Steleac, Jonathan D
Aleksandar Krnjaic, Raul D. Steleac, Jonathan D. Thomas, Georgios Papoudakis, Lukas Schäfer, Andrew Wing Keung To, Kuan-Ho Lao, Murat Cubuktepe, Matthew Haley, Peter Börsting, and Stefano V . Albrecht. Scalable multi-agent reinforcement learning for warehouse logistics with robotic and human co-workers. In2024 IEEE/RSJ International Conference on Intellig...
2024
-
[17]
Kun Li, Shengling Wang, Hongwei Shi, Xiuzhen Cheng, and Minghui Xu. Spatial crowd- sourcing task allocation scheme for massive data with spatial heterogeneity.arXiv preprint arXiv:2310.12433, 2023
-
[18]
Michael L. Littman. Markov games as a framework for multi-agent reinforcement learning. In Proceedings of the Eleventh International Conference on Machine Learning, pages 157–163, 1994
1994
-
[19]
Multi-agent actor- critic for mixed cooperative-competitive environments
Ryan Lowe, Yi Wu, Aviv Tamar, Jean Harb, Pieter Abbeel, and Igor Mordatch. Multi-agent actor- critic for mixed cooperative-competitive environments. InProceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, page 6382–6393, Red Hook, NY , USA, 2017. Curran Associates Inc
2017
-
[20]
Maven: Multi-agent variational exploration
Anuj Mahajan, Tabish Rashid, Mikayel Samvelyan, and Shimon Whiteson. Maven: Multi-agent variational exploration. InAdvances in Neural Information Processing Systems, volume 32, 2019
2019
-
[21]
Maheswaran, Pedro A
Rajiv T. Maheswaran, Pedro A. Szekely, Marcel Becker, Stephen Fitzpatrick, Gergely Gati, Jing Jin, Robert Neches, Narges Noori, Craig Milo Rogers, Romeo Sanchez, Kevin Smyth, and Chris VanBuskirk. Predictability and criticality metrics for coordination in complex environments. In Proceedings of the 7th International Joint Conference on Autonomous Agents a...
2008
-
[22]
Human-level control through deep reinforcement learning.Nature, 518(7540):529–533, 2015
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, Stig Pe- tersen, Charles Beattie, Amir Sadik, Ioannis Antonoglou, Helen King, Dharshan Kumaran, Daan Wierstra, Shane Legg, and Demis Hassabis. Human-level control through deep reinforcement l...
2015
-
[23]
Springer, 2016
Frans A Oliehoek, Christopher Amato, et al.A concise introduction to decentralized POMDPs, volume 1. Springer, 2016
2016
-
[24]
A review of cooperative multi-agent deep reinforce- ment learning.Applied Intelligence, 53:13677–13722, 2023
Afshin Oroojlooy and Davood Hajinezhad. A review of cooperative multi-agent deep reinforce- ment learning.Applied Intelligence, 53:13677–13722, 2023
2023
-
[25]
An extended benchmarking of multi-agent reinforcement learning algorithms in complex fully cooperative tasks
George Papadopoulos, Andreas Kontogiannis, Foteini Papadopoulou, Chaido Poulianou, Ioannis Koumentis, and George V ouros. An extended benchmarking of multi-agent reinforcement learning algorithms in complex fully cooperative tasks. InProceedings of the 24th International Conference on Autonomous Agents and Multiagent Systems, AAMAS ’25, page 1613–1622, Ri...
2025
-
[26]
Albrecht
Georgios Papoudakis, Filippos Christianos, Lukas Schäfer, and Stefano V . Albrecht. Benchmark- ing multi-agent deep reinforcement learning algorithms in cooperative tasks. InProceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks (NeurIPS), 2021
2021
-
[27]
Qmix: Monotonic value function factorisation for deep multi-agent reinforcement learning
Tabish Rashid, Mikayel Samvelyan, Christopher de Witt, Gregory Farquhar, Jakob N Foerster, and Shimon Whiteson. Qmix: Monotonic value function factorisation for deep multi-agent reinforcement learning. InProceedings of the 35th International Conference on Machine Learning (ICML), volume 80, pages 4295–4304. PMLR, 2018
2018
-
[28]
The starcraft multi-agent challenge
Mikayel Samvelyan, Tabish Rashid, Christian Schroeder de Witt, Gregory Farquhar, Nantas Nardelli, Tim G J Rudner, Philip H S Torr, Jakob Foerster, and Shimon Whiteson. The starcraft multi-agent challenge. InProceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems (AAMAS), pages 2186–2188, 2019. 11
2019
-
[29]
Qtran: Learning to factorize with transformation for cooperative multi-agent reinforcement learning
Kyunghwan Son, Daewoo Kim, Wan Ju Kang, David Hostallero, and Yung Yi. Qtran: Learning to factorize with transformation for cooperative multi-agent reinforcement learning. InPro- ceedings of the 36th International Conference on Machine Learning (ICML), pages 5887–5896. PMLR, 2019
2019
-
[30]
When collaboration beats ability: Mixed- ability teams can outperform high-ability teams under coordination demands
Younes Strittmatter, Rachael Skye, Samuel Lozano Iglesias, Samuel Liebana, Andrew Saxe, Miguel Ruiz-Garcia, Erin Teich, and Markus Spitzer. When collaboration beats ability: Mixed- ability teams can outperform high-ability teams under coordination demands. InProceedings of the Annual Meeting of the Cognitive Science Society, 2026
2026
-
[31]
Value-Decomposition Networks For Cooperative Multi-Agent Learning
Peter Sunehag, Guy Lever, Audrunas Gruslys, Wojciech M. Czarnecki, Vinícius Flores Zambaldi, Max Jaderberg, Marc Lanctot, Nicolas Sonnerat, Joel Z. Leibo, Karl Tuyls, and Thore Graepel. Value-decomposition networks for cooperative multi-agent learning.ArXiv, abs/1706.05296, 2017
work page Pith review arXiv 2017
-
[32]
Multi-agent reinforcement learning: Independent vs
Ming Tan. Multi-agent reinforcement learning: Independent vs. cooperative agents. InProceed- ings of the Tenth International Conference on Machine Learning (ICML 1993), pages 330–337, San Francisco, CA, USA, 1993. Morgan Kaufmann
1993
-
[33]
QPLEX: Duplex dueling multi-agent q-learning
Jianhao Wang, Zhizhou Ren, Terry Liu, Yang Yu, and Chongjie Zhang. QPLEX: Duplex dueling multi-agent q-learning. InInternational Conference on Learning Representations (ICLR), 2021
2021
-
[34]
B. L. Welch. The generalization of Student’s problem when several different population variances are involved.Biometrika, 34(1/2):28–35, 1947
1947
-
[35]
Task allocation with geographic partition in spatial crowdsourcing
Guanyu Ye, Yan Zhao, Xuanhao Chen, and Kai Zheng. Task allocation with geographic partition in spatial crowdsourcing. InProceedings of the 30th ACM International Conference on Information & Knowledge Management, pages 2404–2413, 2021
2021
-
[36]
The surprising effectiveness of ppo in cooperative multi-agent games
Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and Yi Wu. The surprising effectiveness of ppo in cooperative multi-agent games. InAdvances in Neural Information Processing Systems, volume 35, pages 24611–24624, 2022
2022
-
[37]
Coordination between individual agents in multi-agent reinforcement learning
Yongchao Zhang, Qingyu Yang, Dou An, and Weidong Chen. Coordination between individual agents in multi-agent reinforcement learning. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 11387–11394, 2021
2021
-
[38]
Task alloca- tion in spatial crowdsourcing: An efficient geographic partition framework.IEEE Transactions on Knowledge and Data Engineering, 36(9):4943–4955, 2024
Yan Zhao, Xuanlei Chen, Guanyu Ye, Fangda Guo, Kai Zheng, and Xiaofang Zhou. Task alloca- tion in spatial crowdsourcing: An efficient geographic partition framework.IEEE Transactions on Knowledge and Data Engineering, 36(9):4943–4955, 2024
2024
-
[39]
Ofcourse: A multi-agent reinforcement learning environment for order fulfillment.Advances in Neural Information Processing Systems, 36:34765–34777, 2023
Yiheng Zhu, Yang Zhan, Xuankun Huang, Yuwei Chen, Jiangwen Wei, Wei Feng, Yinzhi Zhou, Haoyuan Hu, Jieping Ye, et al. Ofcourse: A multi-agent reinforcement learning environment for order fulfillment.Advances in Neural Information Processing Systems, 36:34765–34777, 2023. 12 A Code Release We release the STAT environment together with executable training a...
2023
-
[40]
results are reported in Appendix C.1. Centralized Training and Centralized ExecutionIn the CTCE paradigm, both learning and action selection are performed centrally over the full multi-agent system. We employ a DQN and FDQN. 16 DQN.We extend Deep Q-Networks (DQN) [ 22], originally proposed for single-agent reinforcement learning, to a fully centralized mu...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.