Recognition: unknown
Improved techniques for fine-tuning flow models via adjoint matching: a deterministic control pipeline
Pith reviewed 2026-05-08 09:41 UTC · model grok-4.3
The pith
A new adjoint matching framework formulates flow model alignment as optimal control, enabling direct regression training and terminal-trajectory truncation for efficiency gains on models like SiT-XL and FLUX.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose a deterministic adjoint matching framework that formulates human preference alignment for flow-based generative models as an optimal control problem over velocity fields. One can directly regress the control toward a value-gradient-induced target under the current policy, leading to a simple and stable training objective.
Load-bearing premise
The assumption that reward-relevant signals concentrate in the terminal portion of the trajectory, justifying the truncated adjoint scheme without degrading alignment quality.
Figures

















read the original abstract
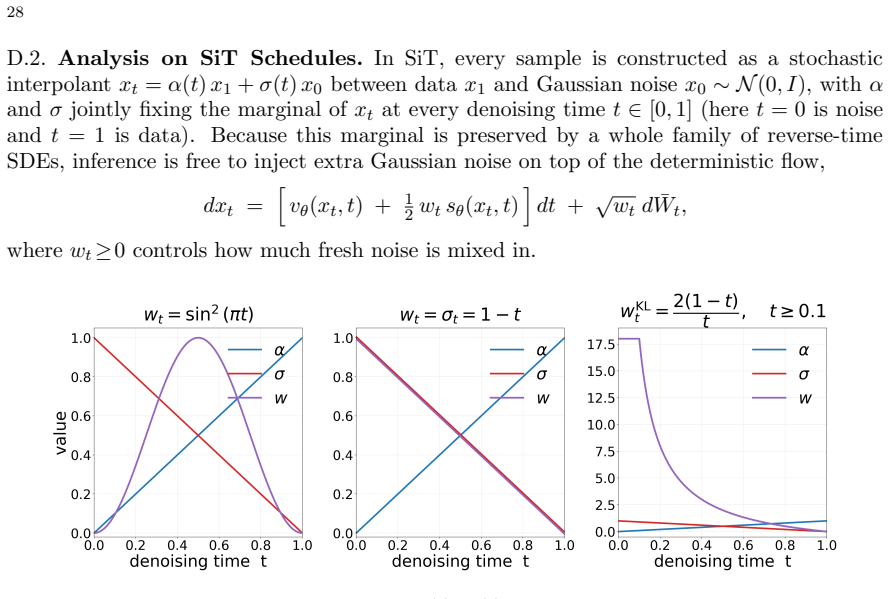
We propose a deterministic adjoint matching framework that formulates human preference alignment for flow-based generative models as an optimal control problem over velocity fields. One can directly regress the control toward a value-gradient-induced target under the current policy, leading to a simple and stable training objective. Building on this perspective, we introduce a truncated adjoint scheme that focuses computation on the terminal portion of the trajectory, where reward-relevant signals concentrate, which yields substantial computational savings while preserving alignment quality. We further generalize the framework beyond standard KL-based regularization, allowing more flexible trade-offs between alignment strength and distributional preservation. Experiments on SiT-XL/2 and FLUX.2-Klein-4B demonstrate consistent gains across multiple alignment metrics, along with substantially improved diversity and mode preservation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a deterministic adjoint matching framework that formulates human preference alignment for flow-based generative models as an optimal control problem over velocity fields. It enables direct regression of the control toward a value-gradient-induced target under the current policy, yielding a simple training objective. Building on this, the paper introduces a truncated adjoint scheme that focuses computation on the terminal trajectory portion (where reward-relevant signals are claimed to concentrate) for computational savings while preserving alignment quality, and generalizes the approach beyond standard KL regularization. Experiments on SiT-XL/2 and FLUX.2-Klein-4B report consistent gains across alignment metrics along with improved diversity and mode preservation.
Significance. If the central claims hold, particularly the stability of the direct regression objective and the effectiveness of the truncated adjoint without degrading alignment, this could provide a more efficient and deterministic alternative to existing fine-tuning methods for flow models, with better trade-offs in distributional preservation. The derivation from optimal control principles and the explicit focus on velocity fields represent a coherent technical contribution.
major comments (2)
- [Abstract] Abstract: the claim that 'reward-relevant signals concentrate' in the terminal portion of the trajectory, which justifies the truncated adjoint scheme and its computational savings while 'preserving alignment quality,' is asserted without a supporting lemma, ablation study, or sensitivity analysis on the truncation horizon. This assumption is load-bearing for the efficiency claim; if reward signals depend on path properties earlier in the flow, truncation introduces bias in the regressed control.
- [Experiments] Experiments section (SiT-XL/2 and FLUX.2-Klein-4B results): the reported 'consistent gains across multiple alignment metrics' and 'substantially improved diversity and mode preservation' provide no details on experimental controls, error bars, data selection criteria, or isolation of the truncated adjoint's contribution versus other factors. This undermines verification of whether the gains survive changes to the truncation point.
minor comments (1)
- The generalization beyond KL-based regularization is mentioned in the abstract but lacks explicit specification of the alternative regularization forms or their impact on the control objective.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive feedback. We address each major comment below and commit to revisions that strengthen the empirical and methodological support for our claims without overstating the current manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that 'reward-relevant signals concentrate' in the terminal portion of the trajectory, which justifies the truncated adjoint scheme and its computational savings while 'preserving alignment quality,' is asserted without a supporting lemma, ablation study, or sensitivity analysis on the truncation horizon. This assumption is load-bearing for the efficiency claim; if reward signals depend on path properties earlier in the flow, truncation introduces bias in the regressed control.
Authors: We agree that the concentration assumption is central to the efficiency argument and currently lacks direct empirical validation in the manuscript. The motivation stems from the optimal-control derivation (value function evaluated at terminal state) and the observation that human-preference rewards are typically terminal-state functions, but we do not claim a general lemma. In the revision we will add a dedicated sensitivity analysis subsection that varies the truncation horizon across a range of values, reports alignment metrics, diversity scores, and wall-clock savings for each, and includes an ablation comparing truncated vs. full adjoint matching on the same seeds. This will quantify any bias introduced by early truncation and identify the practical horizon that preserves quality. revision: yes
-
Referee: [Experiments] Experiments section (SiT-XL/2 and FLUX.2-Klein-4B results): the reported 'consistent gains across multiple alignment metrics' and 'substantially improved diversity and mode preservation' provide no details on experimental controls, error bars, data selection criteria, or isolation of the truncated adjoint's contribution versus other factors. This undermines verification of whether the gains survive changes to the truncation point.
Authors: We acknowledge the lack of reproducibility details and isolation experiments. The current manuscript reports point estimates without variance or controls. In the revised version we will expand the Experiments section to include: (i) complete hyperparameter tables and training protocols, (ii) mean and standard deviation over at least three independent runs with different random seeds, (iii) explicit data-selection and prompt-filtering criteria, and (iv) a new ablation table that isolates the truncated-adjoint component by comparing full-adjoint matching, truncated matching at multiple horizons, and a non-adjoint baseline, all under identical reward models and data. These additions will allow direct verification that the reported gains are attributable to the proposed method and remain stable under truncation changes. revision: yes
Circularity Check
No significant circularity; derivation applies optimal control to velocity fields independently
full rationale
The paper's central construction formulates preference alignment as an optimal control problem over flow velocity fields and regresses controls to a value-gradient target, which follows directly from the stated optimal control setup without reducing to fitted inputs or self-definitions. The truncated adjoint is presented as a computational choice justified by the explicit claim that reward signals concentrate terminally, rather than being forced by prior equations or self-citations. No load-bearing self-citation chains, uniqueness theorems from the same authors, or ansatzes smuggled via citation appear in the derivation; the framework retains independent content from first-principles control theory applied to the flow model.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Reward-relevant signals concentrate in the terminal portion of the trajectory
Reference graph
Works this paper leans on
-
[1]
M. S. Albergo, N. M. Boffi, and E. Vanden-Eijnden. Stochastic interpolants: a unifying framework for flows and diffusions.J. Mach. Learn. Res., 26:Paper No. [209], 80, 2025
2025
-
[2]
Bellman.Dynamic Programming
R. Bellman.Dynamic Programming. Princeton Landmarks in Mathematics. Princeton University Press, Princeton, NJ, 1957. Reprinted in 2010 by Princeton University Press
1957
-
[3]
Berner, L
J. Berner, L. Richter, and K. Ullrich. An optimal control perspective on diffusion-based generative mod- eling.Transactions on Machine Learning Research, 2024
2024
-
[4]
Black, M
K. Black, M. Janner, Y. Du, I. Kostrikov, and S. Levine. Training diffusion models with reinforcement learning. InICLR, 2024
2024
-
[5]
FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
Black Forest Labs. FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025. 12
2025
-
[6]
Directly fine-tuning diffusion models on differentiable rewards.arXiv preprint arXiv:2309.17400,
K. Clark, P. Vicol, K. Swersky, and D. J. Fleet. Directly fine-tuning diffusion models on differentiable rewards. 2023. arXiv:2309.17400
-
[7]
Domingo-Enrich, M
C. Domingo-Enrich, M. Drozdzal, B. Karrer, and R. T. Chen. Adjoint matching: Fine-tuning flow and diffusion generative models with memoryless stochastic optimal control. InICLR, 2025
2025
-
[8]
Dosovitskiy, L
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Min- derer, G. Heigold, S. Gelly, J. Uszkoreit, and N. Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. InICLR, 2021
2021
-
[9]
Esser, S
P. Esser, S. Kulal, A. Blattmann, R. Entezari, J. M¨ uller, H. Saini, Y. Levi, D. Lorenz, A. Sauer, and F. Boesel. Scaling rectified flow transformers for high-resolution image synthesis. InICML, pages 12606– 12633, 2024
2024
-
[10]
Optimizing ddpm sampling with shortcut fine-tuning.arXiv preprint arXiv:2301.13362,
Y. Fan and K. Lee. Optimizing DDPM sampling with shortcut fine-tuning. 2023. arXiv:2301.13362
-
[11]
Y. Fan, O. Watkins, Y. Du, H. Liu, M. Ryu, C. Boutilier, P. Abbeel, M. Ghavamzadeh, K. Lee, and K. Lee. DPOK: Reinforcement learning for fine-tuning text-to-image diffusion models. InNeurips, 2023
2023
-
[12]
R. Gao, E. Hoogeboom, J. Heek, V. De Bortoli, K. P. Murphy, and T. Salimans. Diffusion meets flow matching: Two sides of the same coin. 2024.https://diffusionflow.github.io
2024
-
[13]
Y. Han, M. Razaviyayn, and R. Xu. Stochastic control for fine-tuning diffusion models: Optimality, regularity, and convergence. InICML, pages 21844 – 21870, 2025
2025
-
[14]
Adjoint sampling: Highly scalable diffusion samplers via adjoint matching
A. Havens, B. K. Miller, B. Yan, C. Domingo-Enrich, A. Sriram, B. Wood, D. Levine, B. Hu, B. Amos, B. Karrer, X. Fu, G.-H. Liu, and R. T. Q. Chen. Adjoint sampling: Highly scalable diffusion samplers via adjoint matching. 2025. arXiv:2504.11713
-
[15]
Ho and T
J. Ho and T. Salimans. Classifier-free diffusion guidance. InNeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021
2021
-
[16]
Pick-a-pic: An open dataset of user preferences for text-to-image generation, 2023
Y. Kirstain, A. Polyak, U. Singer, S. Matiana, J. Penna, and O. Levy. Pick-a-Pic: An open dataset of user preferences for text-to-image generation. 2023. arXiv:2305.01569
- [17]
-
[18]
Laidlaw, S
C. Laidlaw, S. Singhal, and A. Dragan. Correlated proxies: A new definition and improved mitigation for reward hacking. InICLR, 2025
2025
-
[19]
J. Lee, J. Chang, J. Kim, and J. C. Ye. Reward score matching: Unifying reward-based fine-tuning for flow and diffusion models. 2026. arXiv:2604.17415
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
J. Li, Y. Cui, T. Huang, Y. Ma, C. Fan, Y. Cheng, M. Yang, Z. Zhong, and L. Bo. MixGRPO: Unlocking flow-based GRPO efficiency with mixed ODE-SDE. 2025. arXiv:2507.21802
work page internal anchor Pith review arXiv 2025
-
[21]
Lipman, R
Y. Lipman, R. T. Chen, H. Ben-Hamu, M. Nickel, and M. Le. Flow matching for generative modeling. InICLR, 2023
2023
-
[22]
G.-H. Liu, J. Choi, Y. Chen, B. K. Miller, and R. T. Chen. Adjoint Schr¨ odinger bridge sampler. In Neurips, 2025
2025
-
[23]
J. Liu, G. Liu, J. Liang, Y. Li, J. Liu, X. Wang, P. Wan, D. Zhang, and W. Ouyang. Flow-GRPO: Training flow matching models via online RL. 2025. arXiv:2505.05470
work page internal anchor Pith review arXiv 2025
-
[24]
Liu and C
X. Liu and C. Gong. Flow straight and fast: Learning to generate and transfer data with rectified flow. InICLR, 2023
2023
-
[25]
Z. Liu, T. Z. Xiao, C. Domingo-Enrich, W. Liu, and D. Zhang. Value gradient guidance for flow matching alignment. InNeurips, 2025
2025
-
[26]
N. Ma, M. Goldstein, M. S. Albergo, N. M. Boffi, E. Vanden-Eijnden, and S. Xie. SiT: Exploring flow and diffusion-based generative models with scalable interpolant transformers. InECCV. Springer, 2024
2024
-
[27]
Ouyang, J
L. Ouyang, J. Wu, X. Jiang, D. Almeida, C. Wainwright, P. Mishkin, C. Zhang, S. Agarwal, K. Slama, and A. Ray. Training language models to follow instructions with human feedback. InNeurips, volume 35, pages 27730–27744, 2022
2022
-
[28]
Peebles and S
W. Peebles and S. Xie. Scalable diffusion models with transformers. InICCV, 2023
2023
-
[29]
L. S. Pontryagin, V. G. Boltyanskii, R. V. Gamkrelidze, and E. F. Mishchenko.The Mathematical Theory of Optimal Processes. Interscience Publishers John Wiley & Sons, Inc., New York-London, 1962
1962
-
[30]
Radford, J
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clark, G. Krueger, and I. Sutskever. Learning transferable visual models from natural language super- vision. InICML, pages 8748–8763, 2021. 13
2021
-
[31]
Rombach, A
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer. High-resolution image synthesis with latent diffusion models. InCVPR, pages 10684–10695, June
-
[32]
Ronneberger, P
O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmen- tation. InMICCAI, volume 9351 ofLecture Notes in Computer Science, pages 234–241, 2015
2015
-
[33]
LAION-5B: An open large-scale dataset for training next generation image-text models
C. Schuhmann, R. Beaumont, R. Vencu, C. Gordon, R. Wightman, M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsman, P. Schramowski, S. Kundurthy, K. Crowson, L. Schmidt, R. Kaczmarczyk, and J. Jitsev. Laion-5b: An open large-scale dataset for training next generation image-text models. 2022. arXiv:2210.08402
work page internal anchor Pith review arXiv 2022
- [34]
-
[35]
W. Tang, H. V. Tran, and Y. P. Zhang. Policy iteration for the deterministic control problems: a viscosity approach.SIAM J. Control. Optim., 63, 2025
2025
-
[36]
Tang and H
W. Tang and H. Zhao. Score-based diffusion models via stochastic differential equations.Stat. Surv., 19:28–64, 2025
2025
-
[37]
Tang and F
W. Tang and F. Zhou. Fine-tuning of diffusion models via stochastic control: entropy regularization and beyond. 2026. To appear in ACC
2026
-
[38]
Wan: Open and Advanced Large-Scale Video Generative Models
Team WAN. WAN: Open and advanced large-scale video generative models. 2025. arXiv:2503.20314
work page internal anchor Pith review arXiv 2025
-
[39]
M. Uehara, Y. Zhao, T. Biancalani, and S. Levine. Understanding reinforcement learning-based fine- tuning of diffusion models: A tutorial and review. 2024. arXiv:2407.13734
-
[41]
M. Uehara, Y. Zhao, K. Black, E. Hajiramezanali, G. Scalia, N. L. Diamant, A. M. Tseng, T. Biancalani, and S. Levine. Fine-tuning of continuous-time diffusion models as entropy-regularized control. 2024. arXiv:2402.15194
-
[42]
Wallace, M
B. Wallace, M. Dang, R. Rafailov, L. Zhou, A. Lou, S. Purushwalkam, S. Ermon, C. Xiong, S. Joty, and N. Naik. Diffusion model alignment using direct preference optimization. InCVPR, pages 8228–8238, 2024
2024
-
[43]
C. Wang, Y. Jiang, C. Yang, H. Liu, and Y. Chen. Beyond reverse KL: Generalizing direct preference optimization with diverse divergence constraints. InICLR, 2024
2024
-
[44]
Z. Wang, E. P. Simoncelli, and A. C. Bovik. Multi-scale structural similarity for image quality assessment. InConf. Rec. Asilomar Conf. Signals Syst. Comput., 2003
2003
-
[45]
G. I. Winata, H. Zhao, A. Das, W. Tang, D. D. Yao, S.-X. Zhang, and S. Sahu. Preference tuning with human feedback on language, speech, and vision tasks: a survey.J. Artificial Intelligence Res., 82:2595–2661, 2025
2025
-
[46]
X. Wu, Y. Hao, K. Sun, Y. Chen, F. Zhu, R. Zhao, and H. Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis. InICCV, 2023
2023
-
[47]
J. Xu, X. Liu, Y. Wu, Y. Tong, Q. Li, M. Ding, J. Tang, and Y. Dong. ImageReward: Learning and evaluating human preferences for text-to-image generation. InNeurips, volume 36, pages 15903–15935, 2023
2023
-
[48]
Z. Xue, J. Wu, Y. Gao, F. Kong, L. Zhu, M. Chen, Z. Liu, W. Liu, Q. Guo, W. Huang, and P. Luo. DanceGRPO: Unleashing GRPO on visual generation. 2025. arXiv:2505.07818
work page internal anchor Pith review arXiv 2025
-
[49]
Yong and X
J. Yong and X. Y. Zhou.Stochastic controls: Hamiltonian systems and HJB equations, volume 43 of Applications of Mathematics (New York). Springer-Verlag, New York, 1999
1999
- [50]
-
[51]
Zhang, M
Q. Zhang, M. Tao, and Y. Chen. gDDIM: generalized denoising diffusion implicit models. InICLR, 2023
2023
-
[52]
Zhang, P
R. Zhang, P. Isola, A. A. Efros, E. Shechtman, and O. Wang. The unreasonable effectiveness of deep features as a perceptual metric. InCVPR, 2018
2018
- [53]
-
[54]
H. Zhao, H. Chen, J. Zhang, D. D. Yao, and W. Tang. Scores as Actions: fine tuning diffusion generative models by continuous-time reinforcement learning. InICML, pages 77371 – 77389, 2025. 14 Appendix Contents Appendix Contents 14 Appendix A. Proof of Deterministic Optimal Control 15 A.1. HJB equation of Deterministic Optimal Control 15 A.2. Pontryagin Ma...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.