Recognition: unknown
DARTS: Targeting Prognostic Covariates in Budget-Constrained Sequential Experiments
Pith reviewed 2026-05-08 04:35 UTC · model grok-4.3
The pith
DARTS decouples adaptive covariate selection from randomization validity in budget-limited sequential experiments.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Adaptive covariate selection based on past batches preserves batch-level randomization validity, and the cumulative inverse-variance weighted estimator achieves at least nominal asymptotic coverage. The acquisition layer satisfies a Bayes risk bound that matches the minimax lower bound up to logarithmic factors.
What carries the argument
The decoupling result between adaptive covariate selection via Thompson sampling on past batches and the design-based validity of current-batch randomization.
If this is right
- The method systematically concentrates the measurement budget on the most informative covariates.
- It closes a substantial fraction of the efficiency gap to an oracle design that knows the prognostic covariates in advance.
- The overall estimator retains at least nominal asymptotic coverage for the average treatment effect.
- Batch-level randomization remains valid at every step despite the adaptive policy.
Where Pith is reading between the lines
- The same decoupling idea might allow adaptive covariate policies inside other design-based procedures such as stratified randomization or rerandomization with different balance metrics.
- Empirical checks could compare DARTS against fixed-budget designs on data sets with known cost structures to measure realized variance reduction.
- Tighter analysis could remove the logarithmic factors in the risk bound or replace Thompson sampling with a different acquisition rule while preserving the validity guarantee.
Load-bearing premise
The prognostic value of covariates can be learned reliably from past batches using Thompson sampling without introducing bias into the current batch's randomization or the overall estimator.
What would settle it
A simulation in which the coverage probability of the treatment-effect confidence interval falls below the nominal level when selection is made adaptive across batches, or in which the Bayes risk of the acquisition policy exceeds the minimax lower bound by more than logarithmic factors.
Figures
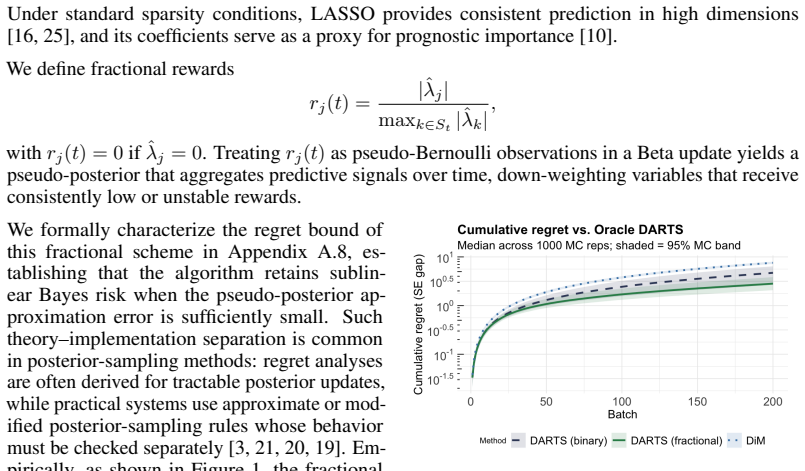

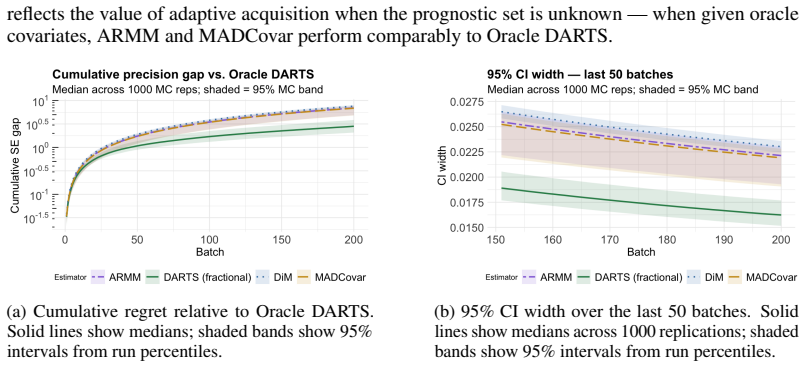
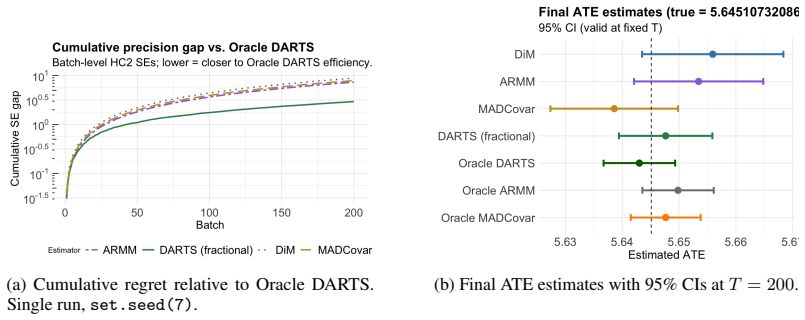


read the original abstract
Randomized controlled trials typically assume that prognostic covariates are known and available at no cost. In practice, obtaining high-dimensional pretreatment data is costly, forcing a trade-off between covariate-adaptive precision and a measurement budget. We introduce Dynamic Adaptive Rerandomization via Thompson Sampling (DARTS), which treats covariate acquisition as a sequential optimization problem embedded within a design-based causal inference task. A budgeted combinatorial Thompson sampler learns which covariates are most prognostic across successive batches; selected covariates then drive rerandomization and regression adjustment to reduce batch-level average treatment effect variance. Our primary theoretical contribution is a decoupling result: adaptive covariate selection based on past batches preserves batch-level randomization validity, and the cumulative inverse-variance weighted estimator achieves at least nominal asymptotic coverage. We further derive a Bayes risk bound for the acquisition layer that matches the minimax lower bound up to logarithmic factors. Empirically, DARTS systematically concentrates the budget on informative features, significantly closing the efficiency gap to oracle designs while maintaining strict inferential validity.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes DARTS, a sequential experimental design that embeds budgeted covariate acquisition as a combinatorial Thompson sampling problem within batch-wise RCTs. Covariates selected from prior batches drive rerandomization and regression adjustment to reduce ATE variance; the central claims are a decoupling result ensuring that past-batch adaptive selection preserves within-batch randomization validity and that the inverse-variance-weighted cumulative estimator attains at least nominal asymptotic coverage, plus a Bayes risk bound for the acquisition layer that matches the minimax lower bound up to logarithmic factors. Empirical results indicate that the method concentrates the budget on prognostic features and narrows the efficiency gap to oracle designs while retaining strict design-based validity.
Significance. If the decoupling and coverage results hold under the stated conditions, the work provides a principled way to trade off measurement cost against precision in high-dimensional covariate settings, which is directly relevant to budget-limited trials. The explicit separation of selection from randomization is a clean contribution to adaptive design theory, and the near-minimax Bayes bound for the acquisition policy is a notable theoretical strength. The empirical demonstration of budget concentration without validity loss further supports practical utility.
major comments (2)
- [Abstract / §3] Abstract and §3 (theoretical results): the decoupling claim that 'adaptive covariate selection based on past batches preserves batch-level randomization validity' is asserted by construction, yet the manuscript does not list the precise measurability or independence conditions (e.g., on the Thompson sampling posterior or batch-size growth) required for the argument; without these, it is impossible to verify whether the result extends beyond the finite-batch case or survives model misspecification in the outcome regression.
- [Abstract / §4] Abstract and §4 (Bayes risk bound): the statement that the acquisition-layer bound 'matches the minimax lower bound up to logarithmic factors' is given without an explicit statement of the outcome model class, the prior on covariate prognostic values, or the precise logarithmic term; this makes it difficult to assess whether the bound is tight only under strong parametric assumptions or holds more generally.
minor comments (2)
- [Empirical evaluation] The empirical section describes results qualitatively ('significantly closing the efficiency gap'); quantitative tables or figures reporting variance reduction ratios, coverage rates, and budget allocation fractions across simulation settings would strengthen the claims.
- [Notation / §2] Notation for the cumulative inverse-variance-weighted estimator is introduced without an explicit recursive formula or variance estimator; adding this would improve readability for readers focused on implementation.
Simulated Author's Rebuttal
We thank the referee for the positive evaluation and recommendation for minor revision. The comments correctly identify places where explicit statements of assumptions will improve clarity and verifiability. We address both points below and will incorporate the requested details in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract / §3] Abstract and §3 (theoretical results): the decoupling claim that 'adaptive covariate selection based on past batches preserves batch-level randomization validity' is asserted by construction, yet the manuscript does not list the precise measurability or independence conditions (e.g., on the Thompson sampling posterior or batch-size growth) required for the argument; without these, it is impossible to verify whether the result extends beyond the finite-batch case or survives model misspecification in the outcome regression.
Authors: We agree that the measurability and independence conditions should be stated explicitly rather than left implicit. In the revision we will add a dedicated paragraph in §3 that lists the required conditions: (i) the Thompson sampling posterior at the start of batch t is a measurable function of the data from batches 1 through t-1 only, hence independent of the current-batch potential outcomes; (ii) batch sizes n_t are non-decreasing and satisfy n_t / N → 0 with N = sum n_t → ∞; (iii) the covariate-selection policy is adapted to the filtration generated by previous batches. Under these conditions the within-batch randomization remains valid by construction, the inverse-variance-weighted estimator is asymptotically normal, and the coverage result holds in the design-based sense without requiring correct specification of the outcome regression. The argument therefore extends to the sequential (infinite-batch) limit under the stated growth condition. revision: yes
-
Referee: [Abstract / §4] Abstract and §4 (Bayes risk bound): the statement that the acquisition-layer bound 'matches the minimax lower bound up to logarithmic factors' is given without an explicit statement of the outcome model class, the prior on covariate prognostic values, or the precise logarithmic term; this makes it difficult to assess whether the bound is tight only under strong parametric assumptions or holds more generally.
Authors: We will make the modeling assumptions explicit in the revised §4. The Bayes-risk upper bound is derived for a linear outcome model Y = Xβ + τW + ε with ε ~ N(0,σ²) and a Gaussian prior on the prognostic vector β. The minimax lower bound is taken with respect to the same parametric class. The logarithmic factor is O(log T) where T denotes the number of batches; it arises from the posterior concentration rate of the combinatorial Thompson sampler. We will add these statements together with a short remark that extensions to nonparametric or misspecified outcome models are left for future work. revision: yes
Circularity Check
No significant circularity; decoupling and risk bound are independent of fitted inputs
full rationale
The paper's central claims rest on a decoupling argument (past-batch Thompson sampling for covariate selection leaves within-batch randomization and the inverse-variance weighted ATE estimator design-valid) and a separate Bayes-risk bound for the acquisition policy that matches minimax rates up to logs. Neither step reduces to a fitted quantity renamed as a prediction, nor to a self-citation that itself assumes the target result. The decoupling follows directly from the sequential batch structure (selection uses only prior data), and the risk bound is stated under an explicit outcome model without circular dependence on the estimator itself. No equations or self-citations are shown that would force the claimed coverage or rate by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Batch-level randomization remains valid when covariate selection depends only on prior batches
- domain assumption Outcome model permits a Bayes risk bound matching minimax up to logs
Reference graph
Works this paper leans on
-
[1]
Bandits with knap- sacks.Journal of the ACM (JACM), 65(3):1–55, 2018
Ashwinkumar Badanidiyuru, Robert Kleinberg, and Aleksandrs Slivkins. Bandits with knap- sacks.Journal of the ACM (JACM), 65(3):1–55, 2018
2018
-
[2]
Bugni, Ivan A
Federico A. Bugni, Ivan A. Canay, and Azeem M. Shaikh. Inference under covariate-adaptive randomization.Journal of the American Statistical Association, 113(524):1784–1796, 2018
2018
-
[3]
An empirical evaluation of thompson sam- pling
Olivier Chapelle and Lihong Li. An empirical evaluation of thompson sam- pling. InAdvances in Neural Information Processing Systems, volume 24, pages 2249–2257, 2011. URL https://proceedings.neurips.cc/paper/2011/hash/ e53a0a2978c28872a4505bdb51db06dc-Abstract.html
2011
-
[4]
Learning to maximize mutual information for dynamic feature selection
Ian Connick Covert, Wei Qiu, Mingyu Lu, Na Yoon Kim, Nathan J White, and Su-In Lee. Learning to maximize mutual information for dynamic feature selection. InInternational Conference on Machine Learning, pages 6424–6447. PMLR, 2023
2023
-
[5]
Budgeted combinatorial multi-armed bandits.arXiv preprint arXiv:2202.03704, 2022
Debojit Das, Shweta Jain, and Sujit Gujar. Budgeted combinatorial multi-armed bandits.arXiv preprint arXiv:2202.03704, 2022
-
[6]
Correlated combinatorial bandits for online resource allocation
Samarth Gupta, Jinhang Zuo, Carlee Joe-Wong, Gauri Joshi, and Osman Ya˘gan. Correlated combinatorial bandits for online resource allocation. InProceedings of the Twenty-Third International Symposium on Theory, Algorithmic Foundations, and Protocol Design for Mobile Networks and Mobile Computing, pages 91–100, 2022
2022
-
[7]
Academic press, 2014
Peter Hall and Christopher C Heyde.Martingale limit theory and its application. Academic press, 2014
2014
-
[8]
Classification with costly features using deep reinforcement learning
Jaromír Janisch, Tomáš Pevn `y, and Viliam Lis `y. Classification with costly features using deep reinforcement learning. InProceedings of the AAAI conference on artificial intelligence, volume 33, pages 3959–3966, 2019
2019
-
[9]
Tight regret bounds for stochastic combinatorial semi-bandits
Branislav Kveton, Zheng Wen, Azin Ashkan, and Csaba Szepesvari. Tight regret bounds for stochastic combinatorial semi-bandits. InArtificial Intelligence and Statistics, pages 535–543. PMLR, 2015
2015
-
[10]
Variable importance matching for causal inference
Quinn Lanners, Harsh Parikh, Alexander V olfovsky, Cynthia Rudin, and David Page. Variable importance matching for causal inference. InUncertainty in Artificial Intelligence, pages 1174–1184. PMLR, 2023
2023
-
[11]
Rerandomization and regression adjustment.Journal of the Royal Statistical Society: Series B (Statistical Methodology), 82(1):241–268, 2020
Xinran Li and Peng Ding. Rerandomization and regression adjustment.Journal of the Royal Statistical Society: Series B (Statistical Methodology), 82(1):241–268, 2020
2020
-
[12]
Design-based theory for causal inference from adaptive experiments
Xinran Li and Anqi Zhao. Design-based theory for causal inference from adaptive experiments. arXiv preprint arXiv:2602.21998, 2026
-
[13]
Active feature acquisition with generative surrogate models
Yang Li and Junier Oliva. Active feature acquisition with generative surrogate models. In International conference on machine learning, pages 6450–6459. PMLR, 2021
2021
-
[14]
Bayesian neural networks for selection of drug sensitive genes.Journal of the American Statistical Association, 113(523):955–972, 2018
Faming Liang, Qizhai Li, and Lei Zhou. Bayesian neural networks for selection of drug sensitive genes.Journal of the American Statistical Association, 113(523):955–972, 2018
2018
-
[15]
Variable selection via thompson sampling.Journal of the American Statistical Association, 118(541):287–304, 2023
Yi Liu and Veronika Ro ˇcková. Variable selection via thompson sampling.Journal of the American Statistical Association, 118(541):287–304, 2023
2023
-
[16]
Lasso-type recovery of sparse representations for high- dimensional data.The Annals of Statistics, 37(1):246–270, 2009
Nicolai Meinshausen and Bin Yu. Lasso-type recovery of sparse representations for high- dimensional data.The Annals of Statistics, 37(1):246–270, 2009
2009
-
[17]
Daniel Molitor and Samantha Gold. Anytime-valid inference in adaptive experiments: Covariate adjustment and balanced power.arXiv preprint arXiv:2506.20523, 2025
-
[18]
Kari Lock Morgan and Donald B Rubin. Rerandomization to improve covariate balance in experiments.The Annals of Statistics, 40(2):1263–1282, April 2012. doi: 10.1214/12-AOS1008. 10
-
[19]
Thompson sampling and approx- imate inference
My Phan, Yasin Abbasi-Yadkori, and Justin Domke. Thompson sampling and approx- imate inference. InAdvances in Neural Information Processing Systems, volume 32, pages 8801–8811, 2019. URL https://proceedings.neurips.cc/paper/2019/hash/ f3507289cfdc8c9ae93f4098111a13f9-Abstract.html
2019
-
[20]
An analysis of en- semble sampling
Chao Qin, Zheng Wen, Xiuyuan Lu, and Benjamin Van Roy. An analysis of en- semble sampling. InAdvances in Neural Information Processing Systems, volume 35,
-
[21]
URL https://proceedings.neurips.cc/paper_files/paper/2022/hash/ 874f5e53d7ce44f65fbf27a7b9406983-Abstract-Conference.html
2022
-
[22]
Deep bayesian bandits showdown: An empirical comparison of bayesian deep networks for thompson sampling
Carlos Riquelme, George Tucker, and Jasper Snoek. Deep bayesian bandits showdown: An empirical comparison of bayesian deep networks for thompson sampling. InInternational Conference on Learning Representations, 2018. URL https://openreview.net/forum? id=SyYe6k-CW
2018
-
[23]
Learning to optimize via posterior sampling.Mathematics of Operations Research, 39(4):1221–1243, 2014
Daniel Russo and Benjamin Van Roy. Learning to optimize via posterior sampling.Mathematics of Operations Research, 39(4):1221–1243, 2014
2014
-
[24]
Joint active feature acquisition and classification with variable-size set encoding.Advances in neural information processing systems, 31, 2018
Hajin Shim, Sung Ju Hwang, and Eunho Yang. Joint active feature acquisition and classification with variable-size set encoding.Advances in neural information processing systems, 31, 2018
2018
-
[25]
Types of cost in inductive concept learning.arXiv preprint cs/0212034, 2002
Peter D Turney. Types of cost in inductive concept learning.arXiv preprint cs/0212034, 2002
work page internal anchor Pith review arXiv 2002
-
[26]
High dimensional variable selection.Annals of statistics, 37(5A):2178, 2009
Larry Wasserman and Kathryn Roeder. High dimensional variable selection.Annals of statistics, 37(5A):2178, 2009
2009
-
[27]
Balancing covariates in multi- arm trials via adaptive randomization.Computational Statistics & Data Analysis, 179:107642, 2023
Haoyu Yang, Yichen Qin, Fan Wang, Yang Li, and Feifang Hu. Balancing covariates in multi- arm trials via adaptive randomization.Computational Statistics & Data Analysis, 179:107642, 2023
2023
-
[28]
Sequential covariate-adjusted randomization via hierarchically minimizing mahalanobis distance and marginal imbalance.Biometrics, 80(2): ujae047, 2024
Haoyu Yang, Yichen Qin, Yang Li, and Feifang Hu. Sequential covariate-adjusted randomization via hierarchically minimizing mahalanobis distance and marginal imbalance.Biometrics, 80(2): ujae047, 2024
2024
-
[29]
Response-adaptive rerandomization.Journal of the Royal Statistical Society: Series C (Applied Statistics), 70(5):1281–1298, 2021
Hengtao Zhang and Guosheng Yin. Response-adaptive rerandomization.Journal of the Royal Statistical Society: Series C (Applied Statistics), 70(5):1281–1298, 2021
2021
-
[30]
Ernst, Kari Lock Morgan, Donald B
Quan Zhou, Philip A. Ernst, Kari Lock Morgan, Donald B. Rubin, and Anru Zhang. Sequential rerandomization.Biometrika, 105(3):745–752, 2018. A Technical appendices and supplementary material A.1 Proof of theorem 1 Fix batch t and condition on Ft−1. Since St is chosen using only previous batches, the selected covariate set is fixed under this conditioning. ...
2018
-
[31]
(A5) imports this conclusion into the superpopulation framework as a primitive assumption on the joint conditional distribution ofˆτgivenG t
show that such schemes reduce or preserve variance relative to simple random assignment. (A5) imports this conclusion into the superpopulation framework as a primitive assumption on the joint conditional distribution ofˆτgivenG t. 13 A.4 Proof of theorem 2 By relative weight consistency, PT t=1 wtPT t=1 ¯wt p − →1. By the estimated-weight remainder condit...
-
[32]
at mostKarms per found forTrounds, soQ(T)≤KT
-
[33]
Since both must hold,Q(T)≤min KT, B cmin
each pull of arm j costs at least cmin, and the total budget is B, so cmin ·Q(T)≤B , giving Q(T)≤B/c min. Since both must hold,Q(T)≤min KT, B cmin . We get E TX t=1 [Ut(St)−r θ∗(St)]≤2 p 2 log(pT2)· r p·min KT, B cmin . Combining this with the vanishing terms for event E C t and term II, we get the bound in the theorem. A.7 Planning gap Let B′ = min(B, T)...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.