Recognition: unknown
Verifier-Backed Hard Problem Generation for Mathematical Reasoning
Pith reviewed 2026-05-08 11:57 UTC · model grok-4.3
The pith
Adding an independent verifier to setter-solver self-play produces harder and more valid mathematical problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
VHG integrates an independent verifier into the conventional setter-solver self-play so that the setter's reward depends jointly on the verifier's assessment of problem validity and the solver's assessment of difficulty, yielding substantially more valid and challenging problems on mathematical tasks.
What carries the argument
Verifier-backed three-party self-play in which problem validity (from the verifier) and difficulty (from the solver) together determine the setter's reward.
Load-bearing premise
The verifier can judge problem validity and difficulty accurately and independently without bias or being manipulated by the setter.
What would settle it
Human experts or a stronger independent judge rating VHG-generated problems as no more valid or difficult than baseline problems, or training a new model on VHG problems showing no performance gain over baseline-generated data.
Figures

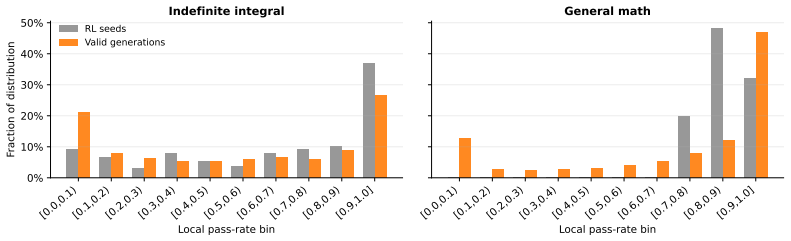




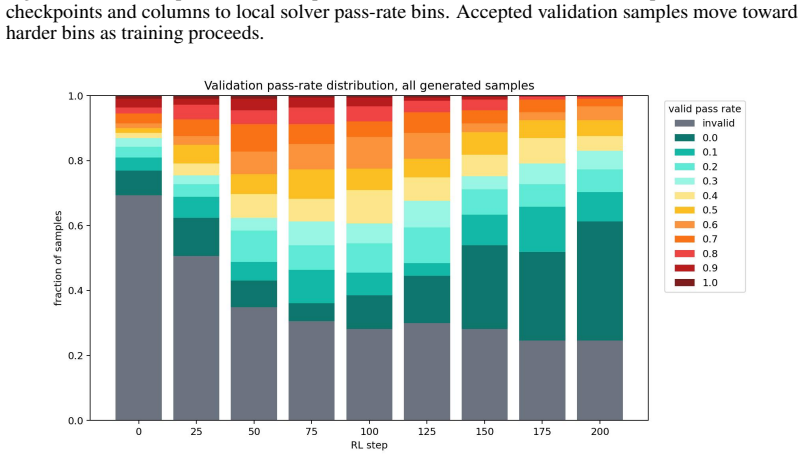


read the original abstract
Large Language Models (LLMs) demonstrate strong capabilities for solving scientific and mathematical problems, yet they struggle to produce valid, challenging, and novel problems - an essential component for advancing LLM training and enabling autonomous scientific research. Existing problem generation approaches either depend on expensive human expert involvement or adopt naive self-play paradigms, which frequently yield invalid problems due to reward hacking. This work introduces VHG, a verifier-enhanced hard problem generation framework built upon three-party self-play. By integrating an independent verifier into the conventional setter-solver duality, our design constrains the setter's reward to be jointly determined by problem validity (evaluated by the verifier) and difficulty (assessed by the solver). We instantiate two verifier variants: a Hard symbolic verifier and a Soft LLM-based verifier, with evaluations conducted on indefinite integral tasks and general mathematical reasoning tasks. Experimental results show that VHG substantially outperforms all baseline methods by a clear margin.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VHG, a three-party self-play framework for generating valid and challenging mathematical problems for LLMs. It augments the conventional setter-solver setup with an independent verifier that jointly scores problem validity and difficulty, instantiated via a hard symbolic verifier (for indefinite integrals) and a soft LLM-based verifier (for general math reasoning). The central claim is that this design mitigates reward hacking and yields substantially better problems than baseline methods, as shown in experiments on the two task domains.
Significance. If the experimental results and verifier independence hold, the work offers a concrete mechanism to improve automated generation of training data for mathematical reasoning, addressing a key bottleneck in scaling LLM capabilities without heavy human curation. The explicit separation of validity and difficulty signals is a useful conceptual advance over naive self-play.
major comments (3)
- [Method / Verifier instantiation] The abstract and method description assert that the verifier is 'independent' and constrains the setter's reward, but no concrete mechanism (frozen weights, separate training corpus, cross-model verification, or human audit) is specified to prevent the soft LLM verifier from sharing inductive biases or training data with the solver, which would allow the gaming scenario the paper criticizes in naive self-play.
- [Experiments] The experimental results claim 'substantial outperformance by a clear margin,' yet the provided abstract supplies no information on baseline definitions, exact evaluation metrics (e.g., validity rate, difficulty distribution, novelty), statistical tests, number of runs, or controls for confounds such as model size or prompt engineering; without these, the central performance claim cannot be verified.
- [Evaluation domains] The hard symbolic verifier is restricted to indefinite integrals and therefore cannot support the 'general mathematical reasoning tasks' mentioned in the abstract; the paper must clarify how the framework generalizes beyond this narrow domain or restrict its claims accordingly.
minor comments (2)
- [Framework definition] Notation for the joint reward (validity × difficulty) should be defined explicitly with an equation rather than described in prose.
- [Results] The paper should include a table comparing VHG variants against each baseline on the same metrics with standard deviations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on VHG. We address each major comment below with point-by-point responses and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [Method / Verifier instantiation] The abstract and method description assert that the verifier is 'independent' and constrains the setter's reward, but no concrete mechanism (frozen weights, separate training corpus, cross-model verification, or human audit) is specified to prevent the soft LLM verifier from sharing inductive biases or training data with the solver, which would allow the gaming scenario the paper criticizes in naive self-play.
Authors: We agree that concrete mechanisms are essential to support the independence claim and prevent potential reward hacking. The manuscript positions the verifier as a distinct third party in the self-play loop, but does not elaborate on implementation details such as model separation. In the revision, we will add a new subsection in the method that specifies the soft verifier uses a separately initialized LLM with no shared parameters or training data overlap with the solver, plus a protocol for periodic human auditing of a sample of verifier outputs. This directly mitigates the gaming concern raised. revision: yes
-
Referee: [Experiments] The experimental results claim 'substantial outperformance by a clear margin,' yet the provided abstract supplies no information on baseline definitions, exact evaluation metrics (e.g., validity rate, difficulty distribution, novelty), statistical tests, number of runs, or controls for confounds such as model size or prompt engineering; without these, the central performance claim cannot be verified.
Authors: The full manuscript (Section 4 and Appendix) defines the baselines (naive setter-solver self-play, random generation, and human-curated sets), reports exact metrics including validity rate, difficulty distribution via solver success rates, and novelty via semantic embedding distances, and includes results from 5 independent runs with t-tests for significance while controlling for model size and prompt templates. However, we acknowledge the abstract is overly brief on these points. We will revise the abstract to summarize the key metrics, baselines, and statistical controls, and add a table in the main text for quick reference. revision: partial
-
Referee: [Evaluation domains] The hard symbolic verifier is restricted to indefinite integrals and therefore cannot support the 'general mathematical reasoning tasks' mentioned in the abstract; the paper must clarify how the framework generalizes beyond this narrow domain or restrict its claims accordingly.
Authors: The hard symbolic verifier is indeed specialized for indefinite integrals as a proof-of-concept for verifiable validity. The framework itself is verifier-agnostic: the three-party structure (setter, solver, verifier) applies to any domain where a validity signal can be obtained. For general mathematical reasoning, we instantiate the soft LLM-based verifier, which scores both validity and difficulty without requiring symbolic rules. We will revise the abstract, introduction, and method sections to explicitly distinguish the two instantiations and state that generalization occurs through the choice of verifier, with the soft variant enabling broader tasks. revision: yes
Circularity Check
No significant circularity; framework and experimental claims are self-contained
full rationale
The paper introduces VHG as a three-party self-play framework with an independent verifier constraining setter rewards via validity and difficulty. No equations, derivations, or first-principles results are presented that reduce by construction to fitted inputs, self-citations, or renamed quantities. The abstract describes external components (hard symbolic verifier, soft LLM verifier) and reports empirical outperformance without any load-bearing step that equates predictions to the method's own parameters or prior self-referential results. This is the common case of an applied framework paper whose central claims rest on experimental comparison rather than internal definitional closure.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption An independent verifier can accurately assess problem validity and difficulty
invented entities (1)
-
VHG framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Self-play fine-tuning converts weak language models to strong language models
Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. Self-play fine-tuning converts weak language models to strong language models. In Ruslan Salakhutdinov, Zico 9 Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st International Conference on Machine Learning, volu...
2024
-
[2]
Training Verifiers to Solve Math Word Problems
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, Christopher Hesse, and John Schulman. Training verifiers to solve math word problems.arXiv preprint arXiv:2110.14168, 2021
work page internal anchor Pith review arXiv 2021
-
[3]
Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025
DeepSeek-AI, Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning, 2025. URL https://arxiv.org/abs/2501. 12948
2025
-
[4]
Prompt curriculum learning for efficient LLM post-training
Zhaolin Gao, Joongwon Kim, Wen Sun, Thorsten Joachims, Sid Wang, Richard Yuanzhe Pang, and Liang Tan. Prompt curriculum learning for efficient LLM post-training. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview. net/forum?id=zqOCacBD3P
2026
-
[5]
ToRA: A tool-integrated reasoning agent for mathematical problem solving
Zhibin Gou, Zhihong Shao, Yeyun Gong, Yelong Shen, Yujiu Yang, Minlie Huang, Nan Duan, and Weizhu Chen. ToRA: A tool-integrated reasoning agent for mathematical problem solving. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview.net/forum?id=Ep0TtjVoap
2024
-
[6]
LLMs Gaming Verifiers: RLVR can Lead to Reward Hacking
Lukas Helff, Quentin Delfosse, David Steinmann, Ruben Härle, Hikaru Shindo, Patrick Schramowski, Wolfgang Stammer, Kristian Kersting, and Felix Friedrich. LLMs gaming verifiers: RLVR can lead to reward hacking.arXiv preprint arXiv:2604.15149, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. In Joaquin Vanschoren and Sai-Kit Yeung, editors,Proceedings of the Neu- ral Information Processing Systems Track on Datasets and Benchmarks, volume 1, 2021. URL https://datasets...
2021
-
[8]
R-Zero: Self-evolving reasoning LLM from zero data
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu. R-Zero: Self-evolving reasoning LLM from zero data. InThe Fourteenth International Conference on Learning Representations, 2026. URL https://openreview.net/forum?id=96apU6YzSO
2026
-
[9]
Key-point-driven data synthesis with its enhancement on mathematical reasoning
Yiming Huang, Xiao Liu, Yeyun Gong, Zhibin Gou, Yelong Shen, Nan Duan, and Weizhu Chen. Key-point-driven data synthesis with its enhancement on mathematical reasoning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 24176–24184,
-
[10]
URL https://ojs.aaai.org/index.php/AAAI/ article/view/34593
doi: 10.1609/aaai.v39i23.34593. URL https://ojs.aaai.org/index.php/AAAI/ article/view/34593
-
[11]
Olympiad-level formal mathemati- cal reasoning with reinforcement learning.Nature, 651:607–613, 2026
Thomas Hubert, Rishi Mehta, Laurent Sartran, et al. Olympiad-level formal mathemati- cal reasoning with reinforcement learning.Nature, 651:607–613, 2026. doi: 10.1038/ s41586-025-09833-y
2026
-
[12]
Inference-time reward hacking in large language models
Hadi Khalaf, Claudio Mayrink Verdun, Alex Oesterling, Himabindu Lakkaraju, and Flavio du Pin Calmon. Inference-time reward hacking in large language models. InAdvances in Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id= hSX7Dd8dxy. Spotlight
2025
-
[13]
Synthesizing verified mathematical problems
Xuefeng Li, Yanheng He, and Pengfei Liu. Synthesizing verified mathematical problems. InThe 4th Workshop on Mathematical Reasoning and AI at NeurIPS 2024, 2024. URL https://openreview.net/forum?id=L5US093OwO
2024
-
[14]
Sws: Self-aware weakness-driven problem synthesis in reinforcement learning for llm reasoning
Xiao Liang, Zhong-Zhi Li, Yeyun Gong, Yang Wang, Hengyuan Zhang, Yelong Shen, Ying Nian Wu, and Weizhu Chen. Sws: Self-aware weakness-driven problem synthesis in reinforcement learning for llm reasoning. InAdvances in Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=0jQUNQsZra. 10
2025
-
[15]
Beyond pass@1: Self-play with variational problem synthesis sustains rlvr
Xiao Liang, Zhongzhi Li, Yeyun Gong, Yelong Shen, Ying Nian Wu, Zhijiang Guo, and Weizhu Chen. Beyond pass@1: Self-play with variational problem synthesis sustains rlvr. In The Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=Wjf3OMJxpn
2026
-
[16]
Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct
Haipeng Luo, Qingfeng Sun, Can Xu, Pu Zhao, Jian-Guang Lou, Chongyang Tao, Xiubo Geng, Qingwei Lin, Shifeng Chen, Yansong Tang, and Dongmei Zhang. Wizardmath: Empowering mathematical reasoning for large language models via reinforced evol-instruct. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview. net/for...
2025
-
[17]
Chaitanya Manem, Pratik Prabhanjan Brahma, Prakamya Mishra, Zicheng Liu, and Emad Barsoum. Sand-math: Using llms to generate novel, difficult and useful mathematics questions and answers, 2025. URLhttps://arxiv.org/abs/2507.20527
-
[18]
Ivan Moshkov, Darragh Hanley, Ivan Sorokin, Shubham Toshniwal, Christof Henkel, Benedikt Schifferer, Wei Du, and Igor Gitman. Aimo-2 winning solution: Building state-of-the-art mathematical reasoning models with openmathreasoning dataset, 2025. URL https://arxiv. org/abs/2504.16891
-
[19]
Learning to reason with LLMs
OpenAI. Learning to reason with LLMs. https://openai.com/index/ learning-to-reason-with-llms/, 2024. Accessed: 2026-05-07
2024
-
[20]
How to get your LLM to generate challenging problems for evaluation
Arkil Patel, Siva Reddy, and Dzmitry Bahdanau. How to get your LLM to generate challenging problems for evaluation. InNeurIPS 2025 Workshop on LLM Evaluation, 2025. URL https: //openreview.net/forum?id=AQm9quyPHU
2025
-
[21]
MathFusion: Enhancing mathematical problem-solving of LLM through instruction fusion
Qizhi Pei, Lijun Wu, Zhuoshi Pan, Yu Li, Honglin Lin, Chenlin Ming, Xin Gao, Conghui He, and Rui Yan. MathFusion: Enhancing mathematical problem-solving of LLM through instruction fusion. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Moham- mad Taher Pilehvar, editors,Proceedings of the 63rd Annual Meeting of the Association for Computational Lin...
-
[22]
doi: 10.18653/v1/2025.acl-long.367
Association for Computational Linguistics. doi: 10.18653/v1/2025.acl-long.367. URL https://aclanthology.org/2025.acl-long.367/
-
[23]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google- proof q&a benchmark. InFirst Conference on Language Modeling, 2024. URL https: //openreview.net/forum?id=Ti67584b98
2024
-
[24]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models.arXiv preprint arXiv:2402.03300, 2024
work page internal anchor Pith review arXiv 2024
-
[25]
MathScale: Scaling instruction tuning for mathematical reasoning
Zhengyang Tang, Xingxing Zhang, Benyou Wang, and Furu Wei. MathScale: Scaling instruction tuning for mathematical reasoning. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of ...
2024
-
[26]
Openmathinstruct-2: Accelerating ai for math with massive open-source instruction data
Shubham Toshniwal, Wei Du, Ivan Moshkov, Branislav Kisacanin, Alexan Ayrapetyan, and Igor Gitman. Openmathinstruct-2: Accelerating ai for math with massive open-source instruction data. InThe Thirteenth International Conference on Learning Representations, 2025. URL https://openreview.net/forum?id=mTCbq2QssD
2025
-
[27]
Trinh, Yuhuai Wu, Quoc V
Trieu H. Trinh, Yuhuai Wu, Quoc V . Le, He He, and Thang Luong. Solving olympiad ge- ometry without human demonstrations.Nature, 625(7995):476–482, 2024. doi: 10.1038/ s41586-023-06747-5
2024
-
[28]
Xiong Jun Wu, Zhenduo Zhang, Zujie Wen, Zhiqiang Zhang, Wang Ren, Lei Shi, Cai Chen, Deng Zhao, Qing Wang, Xudong Han, Chengfu Tang, Dingnan Jin, Qing Cui, and Jun Zhou. Sharp: Synthesizing high-quality aligned reasoning problems for large reasoning models reinforcement learning, 2025. URLhttps://arxiv.org/abs/2505.14147. 11
-
[29]
Metamath: Bootstrap your own mathematical questions for large language models
Longhui Yu, Weisen Jiang, Han Shi, Jincheng YU, Zhengying Liu, Yu Zhang, James Kwok, Zhenguo Li, Adrian Weller, and Weiyang Liu. Metamath: Bootstrap your own mathematical questions for large language models. InThe Twelfth International Conference on Learning Representations, 2024. URLhttps://openreview.net/forum?id=N8N0hgNDRt
2024
-
[30]
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason E. Weston. Self-rewarding language models. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceedings of the 41st International Conference on Machine Learning, volume 235...
2024
-
[31]
Shaoxiong Zhan, Yanlin Lai, Ziyu Lu, Dahua Lin, Ziqing Yang, and Fei Tan. Mathsmith: Towards extremely hard mathematical reasoning by forging synthetic problems with a reinforced policy, 2025. URLhttps://arxiv.org/abs/2508.05592
-
[32]
Absolute zero: Reinforced self-play reasoning with zero data
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Yang Yue, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute zero: Reinforced self-play reasoning with zero data. InAdvances in Neural Information Processing Systems, 2025. URL https://openreview.net/forum?id=neZSGqhxDa. Spotlight
2025
-
[33]
Xueliang Zhao, Wei Wu, Jian Guan, and Lingpeng Kong. PromptCoT: Synthesizing olympiad- level problems for mathematical reasoning in large language models. In Wanxiang Che, Joyce Nabende, Ekaterina Shutova, and Mohammad Taher Pilehvar, editors,Findings of the Association for Computational Linguistics: ACL 2025, pages 18167–18188, Vienna, Austria, July 2025...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.