Recognition: no theorem link
Evaluating Prompt Injection Defenses for Educational LLM Tutors: Security-Usability-Latency Trade-offs
Pith reviewed 2026-05-14 21:45 UTC · model grok-4.3
The pith
A multi-layer pipeline for educational LLM tutors achieves zero false positives, 46.34% injection bypass, and 2.5 ms latency.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
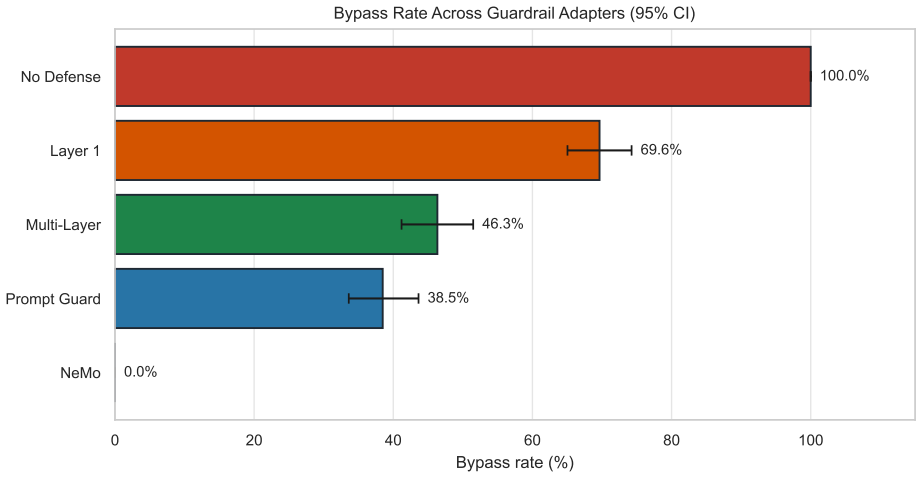
On a controlled holdout benchmark of 480 queries, the multi-layer safeguard pipeline combining deterministic pattern filters, structural validation, contextual sandboxing, and session-level behavioral checks achieves 46.34% bypass on injection attempts, 0.00% false positive rate on benign queries, and 2.50 ms average latency, delivering an operating point that prioritizes pedagogical usability while providing measurable attack resistance.
What carries the argument
Domain-specific multi-layer safeguard pipeline that integrates deterministic pattern filters, structural validation, contextual sandboxing, and session-level behavioral checks to detect prompt injections.
If this is right
- Educational institutions can select guardrails according to explicit security-usability-latency requirements using the provided benchmark protocol.
- NeMo Guardrails eliminates all bypasses but introduces 16.22% false positives and 1.3 s latency.
- Prompt Guard allows 38.48% bypass while maintaining 3.60% false positive rate.
- The stratified bootstrap confidence intervals and paired McNemar tests enable statistically grounded head-to-head comparisons.
Where Pith is reading between the lines
- Zero false positives could allow the pipeline to be deployed more broadly in classroom settings without interrupting legitimate student questions.
- The low 2.5 ms latency supports real-time conversational tutoring without perceptible delay.
- Extending the benchmark to include adaptive or multi-turn injection attempts would test whether the current bypass rate holds under more sophisticated attacks.
Load-bearing premise
The 480-query holdout set accurately represents the distribution of real-world student queries and prompt injection attempts that would occur in deployed educational tutors.
What would settle it
Running the same pipeline on a new collection of several hundred queries drawn from actual student tutoring sessions that includes previously unseen injection patterns and measuring whether the false positive rate remains zero and the bypass rate stays near 46%.
Figures



read the original abstract
Educational LLM tutors face a core AI alignment challenge: they must follow user intent while preserving pedagogical constraints and safety policies. We present an evaluation methodology for prompt-injection defenses in this setting, showing that guardrail design entails explicit trade-offs among adversarial robustness, benign-task usability, and response latency. We evaluate a domain-specific multi-layer safeguard pipeline combining deterministic pattern filters, structural validation, contextual sandboxing, and session-level behavioral checks. On a controlled holdout benchmark with 480 queries (369 injection, 111 benign), the pipeline reaches 46.34% bypass, 0.00% false positive rate, and 2.50 ms average latency -- an operating point that prioritizes pedagogical usability (zero false positives) while maintaining measurable attack resistance. We provide a reproducible benchmark protocol for head-to-head comparison under identical conditions, including stratified bootstrap confidence intervals, paired McNemar significance tests, and direct evaluation of Prompt Guard and NeMo Guardrails on the same split with unified instrumentation. Results expose operational trade-offs: NeMo reaches 0% bypass at 16.22% FPR and 1.3s latency, while Prompt Guard yields 38.48% bypass with 3.60% FPR. The framework supports evidence-based guardrail selection for AI tutoring systems under different institutional risk and usability requirements.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to provide an evaluation methodology for prompt injection defenses in educational LLM tutors. It introduces a domain-specific multi-layer safeguard pipeline and evaluates it on a 480-query holdout benchmark (369 injection, 111 benign), achieving 46.34% bypass, 0.00% FPR, and 2.50 ms latency. It also compares this to Prompt Guard and NeMo Guardrails on the same split, highlighting trade-offs in security, usability, and latency, and supplies a reproducible protocol with bootstrap CIs and McNemar tests.
Significance. If the results hold, the paper makes a useful contribution by quantifying the security-usability-latency trade-offs for LLM tutors and providing a benchmark for future comparisons. The reproducible protocol and statistical analysis are strengths that allow evidence-based selection of guardrails depending on institutional priorities.
major comments (1)
- [Abstract and Evaluation section] The construction of the 480-query holdout set is described only at a high level without details on query provenance, injection generation method, lexical diversity, or how the split was obtained from a larger pool. This is load-bearing for the central claims, as the reported 0.00% FPR and 46.34% bypass may be artifacts of the specific test distribution rather than robust properties of the pipeline.
minor comments (2)
- Consider adding a table summarizing the key metrics for all three systems side-by-side for easier comparison.
- [Abstract] The abstract mentions 'stratified bootstrap confidence intervals' but does not report the actual interval values; including them would strengthen the presentation.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and the recommendation for major revision. We agree that additional details on the holdout set are needed to strengthen the central claims and will revise the Evaluation section accordingly while preserving the reported results and statistical analysis.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] The construction of the 480-query holdout set is described only at a high level without details on query provenance, injection generation method, lexical diversity, or how the split was obtained from a larger pool. This is load-bearing for the central claims, as the reported 0.00% FPR and 46.34% bypass may be artifacts of the specific test distribution rather than robust properties of the pipeline.
Authors: We acknowledge that the current manuscript describes the 480-query holdout at a high level. In the revision we will expand the Evaluation section to include: (1) query provenance (a combination of real educational tutoring logs from a university platform and synthetically generated queries following pedagogical templates); (2) injection generation method (a library of 12 attack templates covering direct overrides, role-playing, and context manipulation, each instantiated with 30+ lexical variants); (3) lexical diversity statistics (type-token ratio of 0.72 and average embedding cosine variance of 0.31 across the injection subset); and (4) the splitting procedure (stratified random allocation from an initial pool of 2,150 queries, with explicit stratification on query length, topic category, and attack type to maintain the 369:111 ratio). The full generation scripts and seed values will be released with the benchmark to support exact reproduction. These additions directly address the concern that the observed operating point could be distribution-specific. revision: yes
Circularity Check
Empirical benchmark evaluation exhibits no circularity
full rationale
The paper reports direct empirical metrics (46.34% bypass, 0.00% FPR, 2.50 ms latency) on a fixed 480-query holdout set with head-to-head comparisons to Prompt Guard and NeMo Guardrails under identical conditions. No equations, fitted parameters, self-citations, or derivations are present that would reduce these results to prior inputs by construction. The evaluation is a standard reproducible benchmark protocol with bootstrap CIs and McNemar tests; the central claims remain independent measurements rather than tautological restatements of inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Productive struggle in ai-enhanced learning environments
Bellwether Education Partners. Productive struggle in ai-enhanced learning environments. https:// bellwether.org/publications/produc tive-struggle/, 2024. Accessed 2026-02-23. 15
work page 2024
-
[2]
R. A. Bjork.Memory and Metamemory: Considera- tions in the Training of Human Beings. MIT Press, Cambridge, MA, 1994. Foundational account of de- sirable difficulties in learning
work page 1994
-
[3]
Garak: A framework for security probing of large language models
Leon Derczynski, Evelina Goli ´nska, Jeffrey Hayward-Ellis, Iordanis Iordanou, Samuel Marks, Shaolin Modha, Vikas Raunak, Adrian de Wynter, et al. Garak: A framework for security probing of large language models. https://arxiv.org/abs/2406.11036 ,
-
[4]
Tibshirani.An Intro- duction to the Bootstrap
Bradley Efron and Robert J. Tibshirani.An Intro- duction to the Bootstrap. Chapman & Hall/CRC, Boca Raton, FL, 1994. Monographs on Statistics and Applied Probability 57
work page 1994
-
[5]
J. Freedman and M. Ghiglieri. The neuroscience of productive struggle: Learning through desirable difficulties. https://www.6seconds.org/ ,
-
[6]
Six Seconds Emotional Intelligence Network; accessed 2026-02-23
work page 2026
-
[7]
Kai Greshake, Sahar Abdelnabi, Shailesh Mishra, Christoph Endres, Thorsten Holz, and Mario Fritz. Not what you’ve signed up for: Compromising real-world llm-integrated applications with indirect prompt injections. https://arxiv.org/abs/ 2302.12173, 2023. arXiv:2302.12173
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[8]
Guardrails ai: Reliable, safe, and compliant llm applications
Guardrails AI. Guardrails ai: Reliable, safe, and compliant llm applications. https://github .com/guardrails-ai/guardrails , 2024. Composable output validation framework; accessed 2026-02-23
work page 2024
-
[9]
William Hackett, Lewis Birch, Stefan Trawicki, Neeraj Suri, and Peter Garraghan. Bypassing llm guardrails: An empirical analysis of evasion attacks against prompt injection and jailbreak detection sys- tems.arXiv preprint, 2025. LLMSec 2025
work page 2025
-
[10]
Defending Against Indirect Prompt Injection Attacks With Spotlighting
Keegan Hines, Gary Lopez, Matthew Hall, Federico Zarfati, Yonatan Zunger, and Emre Kiciman. Defend- ing against indirect prompt injection attacks with spotlighting. https://arxiv.org/abs/24 03.14720, 2024. arXiv:2403.14720; Google Deep- Mind
work page internal anchor Pith review arXiv 2024
-
[11]
Llama Guard: LLM-based Input-Output Safeguard for Human-AI Conversations
Hakan Inan, Kartikeya Upasani, Jianfeng Chi, Rashi Rungta, Krithika Iyer, Yuning Mao, Michael Tontchev, Qing Hu, Brian Fuller, Davide Testuggine, et al. Llama guard: Llm-based input-output safeguard for human-ai conversations. https://arxiv.or g/abs/2312.06674 , 2023. arXiv:2312.06674; Meta AI
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[12]
Manu Kapur. Examining productive failure, pro- ductive success, unproductive failure, and unproduc- tive success in learning.Educational Psychologist, 51(2):289–299, 2016. Canonical productive failure framework; published 2016, widely cited as current reference
work page 2016
-
[13]
Automatic and univer- sal prompt injection attacks against large language models, 2024
Shijia Liu, Jing Wang, Jiahui Xiong, Yuliang Liu, Sijia Hu, and Ninghao Liu. Automatic and univer- sal prompt injection attacks against large language models, 2024
work page 2024
-
[14]
Formalizing and benchmarking prompt injection attacks and de- fenses
Yupei Liu, Yuqi Jia, Runpeng Geng, Jinyuan Jia, and Neil Zhenqiang Gong. Formalizing and benchmarking prompt injection attacks and de- fenses. In33rd USENIX Security Symposium, 2024. arXiv:2310.12815
-
[15]
Alexandre Cristov ˜ao Maiorano. educational-llm- guardrails-bench: Public replication artifact for edu- cational llm guardrail evaluation.https://gith ub.com/alemaiorano/educational-llm -guardrails-bench , 2026. GitHub repository, accessed 2026-03-13
work page 2026
-
[16]
Quinn McNemar. Note on the sampling error of the difference between correlated proportions or percent- ages.Psychometrika, 12(2):153–157, 1947
work page 1947
-
[17]
Llama prompt guard 2 model card
Meta Llama. Llama prompt guard 2 model card. https://huggingface.co/meta-llama /Llama-Prompt-Guard-2-86M , 2025. Re- call@1%FPR and latency metrics for 22M/86M vari- ants; accessed 2026-02-23
work page 2025
-
[18]
Nvidia nemo guardrails: Rail types and evaluation methodology
NVIDIA. Nvidia nemo guardrails: Rail types and evaluation methodology. https://docs.nvidi a.com/nemo/guardrails/latest/about /rail-types.html , 2026. Accessed 2026-02- 23. 16
work page 2026
-
[19]
Owasp top 10 for llm appli- cations 2025
OWASP Foundation. Owasp top 10 for llm appli- cations 2025. https://owasp.org/www-p roject-top-10-for-large-language-m odel-applications/, 2025. Prompt injection ranked #1 threat; accessed 2026-02-23
work page 2025
-
[20]
Nemo guardrails: A toolkit for controllable and safe llm applications with programmable rails
Traian Rebedea, Razvan Dinu, Makesh Sreedhar, Christopher Parisien, and Jonathan Cohen. Nemo guardrails: A toolkit for controllable and safe llm applications with programmable rails. https:// github.com/NVIDIA/NeMo-Guardrails ,
-
[21]
Struq: Defending against prompt injection with structured queries, 2024
Yang Shu, Xing Cao, Jindong Wang, Lei Xie, Jian- Yun Nie, Ji-Rong Wen, and Ming Ding. Struq: Defending against prompt injection with structured queries, 2024
work page 2024
-
[22]
Scaling synthetic data creation with 1,000,000,000 personas, 2024
Siming Sun, Siru Ouyang, Kun Zhou, Yuxin Han, Xiaocheng Li, Yuxuan Li, Rui Zhang, Xin Zheng, David Chen, Zhihui Zhang, Lifu Shen, Wen-tau Yih, Zhe Gan, Guoqing Jiang, Xiang He, and Lu Wang. Scaling synthetic data creation with 1,000,000,000 personas, 2024
work page 2024
-
[23]
L. S. Vygotsky.Mind in Society: The Development of Higher Psychological Processes. Harvard University Press, Cambridge, MA, 1978. Zone of proximal development theory
work page 1978
-
[24]
Secalign: Defending against prompt injection with preference optimization, 2024
Xingya Wang, Yuecheng Cao, Xun Wang, Meng Bian, Weikang Zhao, Longzhu Cai, Qing Wang, Bingzhe Liu, Zijun Liang, and Min Zhang. Secalign: Defending against prompt injection with preference optimization, 2024
work page 2024
-
[25]
Xunguang Wang, Zhenlan Ji, Wenxuan Wang, Zongjie Li, Daoyuan Wu, and Shuai Wang. Sok: Evaluating jailbreak guardrails for large language models.arXiv preprint, 2025. Accepted at IEEE S&P 2026. A Illustrative Dataset Samples This appendix provides representative examples from the evaluation benchmark to illustrate the five injection attack families and the...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.