Recognition: 2 theorem links
· Lean TheoremMore Thinking, More Bias: Length-Driven Position Bias in Reasoning Models
Pith reviewed 2026-05-11 01:20 UTC · model grok-4.3
The pith
Longer reasoning trajectories increase position bias in multiple-choice questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
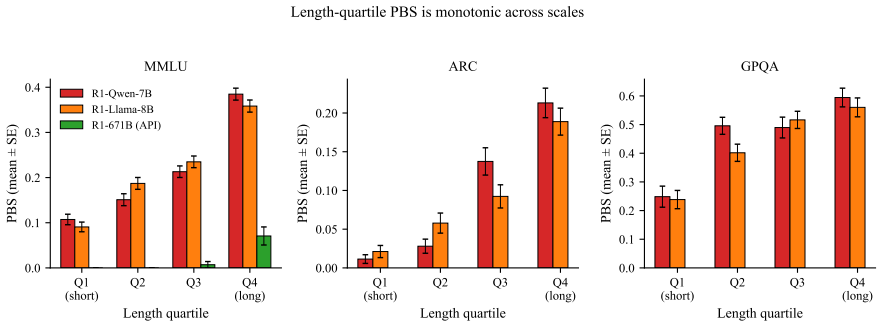
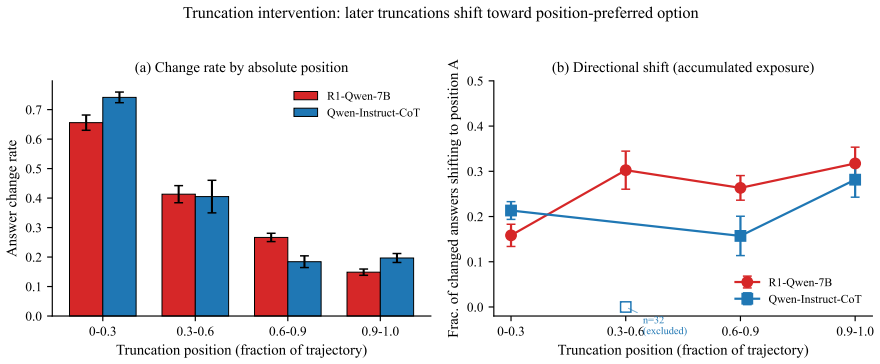
Within any reasoning-capable model, per-question position bias scales with the length of the reasoning trajectory. Twelve of thirteen tested configurations exhibit positive partial correlation between trajectory length and Position Bias Score after accuracy controls. Truncation interventions provide causal evidence that continuations from later points shift toward position-preferred options. At the largest scale, aggregate bias is low but the length effect persists in the longest quartile.
What carries the argument
Position Bias Score (PBS), which isolates position preference while controlling for accuracy, analyzed via partial correlations with trajectory length and truncation probes that resume reasoning from intermediate points.
If this is right
- Reasoning models cannot be treated as order-robust by default when evaluating multiple-choice questions.
- Chain-of-thought replaces baseline direct-answer bias with a distinct length-accumulated bias.
- High overall accuracy can mask length-driven bias, but the mechanism remains active in the longest trajectories.
- Diagnostic tools such as PBS, commitment change points, and truncation probes can audit position bias in reasoning systems.
Where Pith is reading between the lines
- Applications that rely on long reasoning chains may need explicit length controls or post-hoc bias checks to maintain fairness.
- The length-bias relationship could be tested in non-MCQ tasks where sequential ordering influences decisions.
- Model training objectives might incorporate penalties on length-correlated biases to reduce the effect at the source.
Load-bearing premise
The Position Bias Score and partial correlation controls fully isolate length-driven bias from accuracy, model-specific effects, and other confounds.
What would settle it
A truncation experiment in which resuming from later points in the trajectory produces no increase in shifts toward position-preferred options would falsify the causal claim.
Figures


read the original abstract
Chain-of-thought (CoT) reasoning and reasoning-tuned models such as DeepSeek-R1 are commonly assumed to reduce shallow heuristic biases by thinking carefully. We test this on position bias in multiple-choice QA and find a different story: within any reasoning-capable model, per-question position bias scales with the length of the reasoning trajectory. Across thirteen reasoning-mode configurations (two R1-distilled 7-8B models, two base models prompted with CoT, and DeepSeek-R1 at 671B) on MMLU, ARC-Challenge, and GPQA, twelve show a positive partial correlation between trajectory length and Position Bias Score (PBS) after controlling for accuracy, ranging from 0.11 to 0.41 (all p < 0.05). All twelve open-weight reasoning-mode configurations show monotonically increasing PBS across length quartiles. A truncation intervention provides causal evidence: continuations resumed from later points in the trajectory are increasingly likely to shift toward position-preferred options (16% to 32% for R1-Qwen-7B across absolute-position buckets). At 671B, aggregate PBS collapses to 0.019, but the length effect still manifests in the longest quartile (PBS = 0.071), suggesting that accuracy gates the expression of length-driven bias rather than eliminating the underlying mechanism. We additionally find that direct-answer position bias is a distinct phenomenon with a different footprint (strong in Llama-Instruct-direct, weak in Qwen-Instruct-direct, and uncorrelated with trajectory length): CoT reasoning replaces this baseline bias with length-accumulated bias. Our results argue that reasoning-capable models should not be treated as order-robust by default in MCQ evaluation pipelines, and offer a diagnostic toolkit (PBS, commitment change point, effective switching, truncation probes) for auditing position bias in reasoning models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that within reasoning-capable models, per-question position bias in multiple-choice QA scales with the length of the reasoning trajectory. Across thirteen configurations (R1-distilled models, base models with CoT, and DeepSeek-R1) on MMLU, ARC-Challenge, and GPQA, twelve exhibit positive partial correlations (0.11–0.41, p<0.05) between trajectory length and Position Bias Score (PBS) after controlling for accuracy; all twelve open-weight setups show monotonic PBS increases across length quartiles. A truncation intervention supplies causal evidence via increased shifts toward position-preferred options (16–32%) when resuming from later trajectory points. The work distinguishes this length-driven effect from direct-answer position bias and notes that at 671B scale the aggregate PBS is low but the length effect persists in the longest quartile.
Significance. If the central claim holds, the results are significant for MCQ evaluation pipelines, as they indicate that CoT reasoning can replace baseline position bias with a length-accumulated form rather than eliminating bias. The multi-model, multi-dataset design, accuracy controls via partial correlation, and proposed diagnostics (PBS, commitment change point, truncation probes) constitute clear strengths. The empirical measurement approach with falsifiable patterns across 13 setups adds value, though the causal isolation of length from other trajectory properties remains the key point requiring further support.
major comments (1)
- [Truncation intervention (results)] The truncation intervention (results describing the probe) is presented as causal evidence that longer trajectories drive position bias, with reported shifts of 16–32% toward position-preferred options. However, resumption from later points necessarily includes greater accumulated tokens, prior commitments, and semantic context; any bias increase could therefore arise from these state differences rather than token count alone. The manuscript should add controls that match resumption points on equivalent reasoning depth or content type to isolate length per se.
minor comments (2)
- [Abstract] The abstract reports that twelve of thirteen configurations show the positive partial correlation but does not identify the single exception; stating which configuration fails to show the effect would improve interpretability.
- [Methods / PBS definition] The exact operational definition of the Position Bias Score (PBS) and the precise covariates used in the partial-correlation analysis should be stated explicitly in the main text (or a dedicated methods subsection) rather than assumed from the abstract.
Simulated Author's Rebuttal
Thank you for your thorough review and constructive feedback on our manuscript. We appreciate the referee's careful reading of the truncation intervention and the opportunity to address concerns about causal isolation. We respond to the major comment below.
read point-by-point responses
-
Referee: The truncation intervention (results describing the probe) is presented as causal evidence that longer trajectories drive position bias, with reported shifts of 16–32% toward position-preferred options. However, resumption from later points necessarily includes greater accumulated tokens, prior commitments, and semantic context; any bias increase could therefore arise from these state differences rather than token count alone. The manuscript should add controls that match resumption points on equivalent reasoning depth or content type to isolate length per se.
Authors: We thank the referee for this insightful observation. The truncation probe was designed to test whether bias increases when generation resumes after more prior reasoning has occurred, producing the reported 16–32% shifts. However, we fully agree that resumption from later points confounds additional token count with accumulated semantic context, prior commitments, and reasoning depth, so the design does not isolate length per se. Adding controls that match resumption points on equivalent reasoning depth or content type would require new experiments (e.g., generating matched-length but semantically varied trajectories), which we did not conduct. We will therefore make a partial revision: (1) change phrasing in the abstract and results from “causal evidence” to “supporting evidence” or “suggestive of a length-driven mechanism”; (2) add an explicit Limitations paragraph acknowledging the confounding factors and the difficulty of cleanly separating length from content; and (3) highlight that the partial-correlation and quartile results provide independent, non-interventional support for the overall claim. This revision clarifies the strength of the evidence without overstating causality. revision: partial
Circularity Check
No significant circularity: purely empirical measurement study
full rationale
The paper defines Position Bias Score (PBS) as a metric, computes partial correlations between reasoning trajectory length and PBS (controlling for accuracy), and reports results from a truncation intervention across models and datasets. No derivation chain, first-principles predictions, or equations are present that could reduce to inputs by construction. There are no self-definitional steps, fitted inputs renamed as predictions, or load-bearing self-citations that justify the central claims. The analysis relies on direct empirical measurements and interventions, which are self-contained and falsifiable against external data. Minor self-citations, if any, are not load-bearing for the reported correlations or intervention results.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Position Bias Score (PBS) validly quantifies order preference after accuracy controls
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquationwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
within any reasoning-capable model, per-question position bias scales with the length of the reasoning trajectory... partial correlation ρ(length,PBS|accuracy)
-
IndisputableMonolith/Foundation/ArithmeticFromLogicLogicNat.induction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A truncation intervention provides causal evidence: continuations resumed from later points...
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Peter Clark, Isaac Cowhey, Oren Etzioni, Tushar Khot, Ashish Sabharwal, Carissa Schoenick, and Oyvind Tafjord. Think you have solved question answering? Try ARC , the AI2 reasoning challenge. arXiv preprint arXiv:1803.05457, 2018. URL https://arxiv.org/abs/1803.05457
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
DeepSeek-AI , Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, et al. DeepSeek-R1 : Incentivizing reasoning capability in LLMs via reinforcement learning. Nature, 645: 0 633--638, 2025. doi:10.1038/s41586-025-09422-z. URL https://arxiv.org/abs/2501.12948. arXiv:2501.12948
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1038/s41586-025-09422-z 2025
-
[3]
Measuring massive multitask language understanding
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. Measuring massive multitask language understanding. In International Conference on Learning Representations (ICLR), 2021. URL https://openreview.net/forum?id=d7KBjmI3GmQ
work page 2021
-
[6]
QwQ : Reflect deeply on the boundaries of the unknown
Qwen Team . QwQ : Reflect deeply on the boundaries of the unknown. https://qwenlm.github.io/blog/qwq-32b-preview/, 2024. Blog post
work page 2024
-
[7]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA : A graduate-level Google-Proof Q&A benchmark. In Conference on Language Modeling (COLM), 2024. URL https://arxiv.org/abs/2311.12022
work page internal anchor Pith review arXiv 2024
-
[10]
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena
Lianmin Zheng, Wei-Lin Chiang, Ying Sheng, Siyuan Zhuang, Zhanghao Wu, Yonghao Zhuang, Zi Lin, Zhuohan Li, Dacheng Li, Eric P. Xing, Hao Zhang, Joseph E. Gonzalez, and Ion Stoica. Judging LLM -as-a-judge with MT-Bench and chatbot arena. In Advances in Neural Information Processing Systems (NeurIPS), Datasets and Benchmarks Track, 2023. URL https://arxiv.o...
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [11]
-
[12]
Does Reasoning Introduce Bias?
Wu, Xuyang and Nian, Jinming and Wei, Ting-Ruen and Tao, Zhiqiang and Wu, Hsin-Tai and Fang, Yi , booktitle =. Does Reasoning Introduce Bias?. 2025 , address =. doi:10.18653/v1/2025.findings-emnlp.1006 , url =
-
[13]
arXiv preprint arXiv:2510.17062 , year =
Investigating Thinking Behaviours of Reasoning-Based Language Models for Social Bias Mitigation , author =. arXiv preprint arXiv:2510.17062 , year =
work page internal anchor Pith review arXiv
-
[14]
and Zhang, Hao and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Li, Dacheng and Xing, Eric P. and Zhang, Hao and Gonzalez, Joseph E. and Stoica, Ion , booktitle =. Judging. 2023 , url =
work page 2023
-
[15]
Large Language Models are not Fair Evaluators
Large Language Models are not Fair Evaluators , author =. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages =. 2024 , address =. doi:10.18653/v1/2024.acl-long.511 , url =
-
[16]
Findings of the Association for Computational Linguistics: NAACL 2024 , pages =
Large Language Models Sensitivity to The Order of Options in Multiple-Choice Questions , author =. Findings of the Association for Computational Linguistics: NAACL 2024 , pages =. 2024 , address =. doi:10.18653/v1/2024.findings-naacl.130 , url =
-
[17]
International Conference on Learning Representations (ICLR) , year =
Measuring Massive Multitask Language Understanding , author =. International Conference on Learning Representations (ICLR) , year =
-
[18]
Think you have Solved Question Answering?
Clark, Peter and Cowhey, Isaac and Etzioni, Oren and Khot, Tushar and Sabharwal, Ashish and Schoenick, Carissa and Tafjord, Oyvind , journal =. Think you have Solved Question Answering?. 2018 , url =
work page 2018
-
[19]
Rein, David and Hou, Betty Li and Stickland, Asa Cooper and Petty, Jackson and Pang, Richard Yuanzhe and Dirani, Julien and Michael, Julian and Bowman, Samuel R. , booktitle =. 2024 , url =
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.