Recognition: no theorem link
The Single-File Test: A Longitudinal Public-Interface Evaluation of First-Output LLM Web Generation with Social Reach Tracking
Pith reviewed 2026-05-11 01:19 UTC · model grok-4.3
The pith
Claude leads in quality for single-file HTML web generation under fixed public interfaces
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
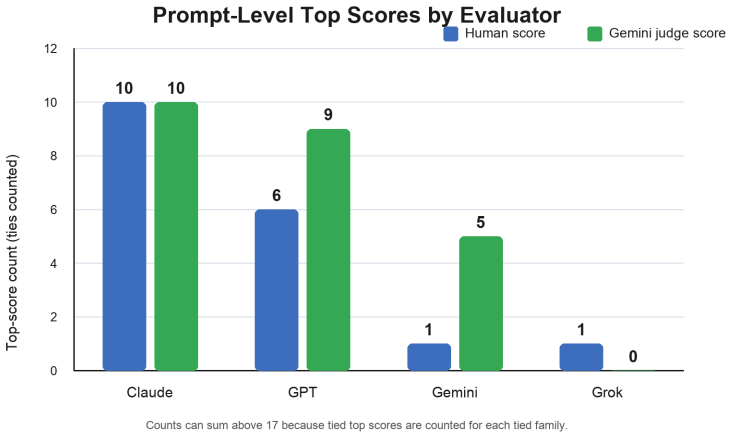
Under this fixed public-interface protocol with no custom instructions or repair prompts, Claude was the strongest and most consistent family, leading mean performance and winning 9/17 prompts under the primary human weighted score. Longer measured reasoning time was not associated with higher quality overall. Gemini as a judge was significantly more lenient than the human evaluator on functional correctness and overall performance, while the exploratory X-impressions model remained weak under cross-validation whereas the HTML-lines model performed better with a model-family-only baseline outperforming prompt-aware alternatives. Code verbosity was driven much more by model family than by the
What carries the argument
The Single-File Test: a standardized observational protocol that collects first-output LLM generations of complete HTML pages through public interfaces, evaluates them via human review of rendered videos plus LLM-as-judge metrics for adherence and UI quality, and packages results for social-media tracking.
If this is right
- Claude family outputs score higher on human-weighted quality than GPT, Gemini, or Grok families under identical first-output conditions.
- HTML code length depends more on model family than on the wording of the generation prompt.
- Technical and audio variables collected before publication do not reliably predict 24-hour X impressions.
- LLM-as-judge scores using Gemini diverge from human scores on functional correctness and overall performance.
Where Pith is reading between the lines
- Developers needing reliable single-file prototypes might select Claude to reduce iteration time without extra prompting.
- Repeating the protocol with private API access could isolate whether interface drift or access differences explain the observed gaps.
- Social reach models may need to incorporate posting time, thumbnail appeal, or audience demographics beyond the HTML itself.
- Longer-term tracking could reveal whether model updates shift the relative rankings seen in this eight-week window.
Load-bearing premise
The fixed public-interface protocol with no custom instructions or repair prompts allows fair, stable comparisons across model families despite acknowledged public-interface drift and access-path differences.
What would settle it
Re-running the exact 17 prompts on the same day via private APIs for all four families and obtaining a different winner or ranking than the public-interface results.
Figures


read the original abstract
This paper presents an eight-week observational comparison of 68 single-file HTML generations collected across 17 public experiments in the "HTML AI Battle" project between December 10, 2025 and February 4, 2026. Four reasoning model families, GPT, Gemini, Grok, and Claude, were compared under a fixed public-interface protocol with no custom instructions, no personality tuning, and no repair prompts. Each output was evaluated from a rendered browser video using human scores and a Gemini LLM-as-a-judge layer for prompt adherence, functional correctness, and UI quality, then packaged into a standardized social-media protocol spanning X (Twitter), TikTok, and YouTube. The tracker was also used for two supervised predictive analyses: an experiment-level model for 24-hour X impressions and a generation-level model for HTML verbosity. Under this protocol, Claude was the strongest and most consistent family, leading mean performance and winning 9/17 prompts under the primary human weighted score. Longer measured reasoning time was not associated with higher quality overall. Gemini as a judge was significantly more lenient than the human evaluator on functional correctness and overall performance, while stable self-favoring bias remained unresolved. The exploratory X-impressions model remained weak under post-screen cross-validation (MAE = 46,874, R^2 = -0.377), whereas the HTML-lines model performed better, with a model-family-only baseline outperforming prompt-aware alternatives (MAE = 135.2, R^2 = 0.576). Overall, selected pre-publication technical/audio variables were not sufficient to predict 24-hour X reach, while code verbosity was driven much more by model family than by prompt wording. The comparisons remain observational and are limited by public-interface drift, access-path differences, and one primary human scorer.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper reports an eight-week observational study of 68 single-file HTML generations from 17 public prompts across four LLM families (GPT, Gemini, Grok, Claude) under a fixed public-interface protocol with no custom instructions or repairs. Outputs were evaluated via human scoring and Gemini LLM-as-judge on prompt adherence, functional correctness, and UI quality, then tracked for social-media reach on X, TikTok, and YouTube. Two supervised models were fit: one for 24-hour X impressions and one for HTML verbosity. The central finding is that Claude led mean performance and won 9/17 prompts under the primary human-weighted score; longer reasoning time was not linked to higher quality; Gemini judge was more lenient than human; the impressions model was weak (negative R² under cross-validation) while the verbosity model was driven primarily by model family (R²=0.576). All comparisons are presented as observational with explicit limits from public-interface drift, access-path differences, and single human scorer.
Significance. If the observational rankings prove robust to the acknowledged confounds, the work supplies rare longitudinal public-interface data on LLM web-generation consistency and documents the practical difficulty of predicting social reach from pre-publication technical features. The dual human/LLM-judge protocol and social-reach tracker add applied value for practitioners, though the negative cross-validated R² on impressions and the family-only baseline outperforming prompt-aware models on verbosity indicate that the predictive components add limited new insight beyond the descriptive rankings.
major comments (2)
- [Abstract; Methods (protocol description); Results (family rankings)] The claim that Claude leads mean performance and wins 9/17 prompts under the human-weighted score (abstract and results) rests on the assumption that the 17 prompts were evaluated under sufficiently equivalent conditions. The eight-week span (Dec 2025–Feb 2026) and explicit mention of public-interface drift plus access-path differences introduce uncontrolled temporal and path confounds (e.g., version updates, rate limits, regional serving) that could systematically bias outputs and rankings; no version tracking, access standardization, or sensitivity checks are reported to quantify or mitigate this risk.
- [Predictive analyses (impressions model)] The supervised X-impressions model reports MAE = 46,874 and R² = -0.377 under post-screen cross-validation (abstract and predictive-analysis section). A negative R² indicates the model performs worse than a simple mean predictor, undermining any claim that the collected technical/audio variables are useful for reach prediction and rendering the exploratory analysis largely descriptive rather than predictive.
minor comments (3)
- [Methods] The 17 prompts are not reproduced or characterized in sufficient detail (e.g., topic distribution, complexity metrics), which limits reproducibility and makes it hard to assess whether prompt wording truly had negligible effect on verbosity relative to model family.
- [Evaluation protocol] The single primary human scorer is acknowledged as a limitation, yet no inter-rater reliability statistics or secondary scorer results are provided to bound subjectivity in the weighted score that drives the main ranking claim.
- [Predictive analyses (verbosity model)] The HTML verbosity model shows a model-family-only baseline outperforming prompt-aware alternatives (R²=0.576); this should be stated more prominently as evidence that prompt wording adds little explanatory power beyond family identity.
Simulated Author's Rebuttal
We thank the referee for the constructive review of our observational study. We address each major comment below, preserving the manuscript's explicit framing as observational while incorporating clarifications and revisions to better highlight limitations.
read point-by-point responses
-
Referee: [Abstract; Methods (protocol description); Results (family rankings)] The claim that Claude leads mean performance and wins 9/17 prompts under the human-weighted score (abstract and results) rests on the assumption that the 17 prompts were evaluated under sufficiently equivalent conditions. The eight-week span (Dec 2025–Feb 2026) and explicit mention of public-interface drift plus access-path differences introduce uncontrolled temporal and path confounds (e.g., version updates, rate limits, regional serving) that could systematically bias outputs and rankings; no version tracking, access standardization, or sensitivity checks are reported to quantify or mitigate this risk.
Authors: We agree that the eight-week public-interface collection period introduces uncontrolled temporal and access-path confounds that could affect output consistency and rankings. The manuscript already states that all comparisons are observational and limited by public-interface drift and access-path differences. To address the referee's point, we will revise the Methods and Limitations sections to explicitly note the absence of version tracking or sensitivity analyses and to caution that rankings should be interpreted as descriptive under the specific collection conditions rather than robust to all interface changes. Retrospective standardization is not possible given the public protocol used. revision: partial
-
Referee: [Predictive analyses (impressions model)] The supervised X-impressions model reports MAE = 46,874 and R² = -0.377 under post-screen cross-validation (abstract and predictive-analysis section). A negative R² indicates the model performs worse than a simple mean predictor, undermining any claim that the collected technical/audio variables are useful for reach prediction and rendering the exploratory analysis largely descriptive rather than predictive.
Authors: We concur that the negative cross-validated R² demonstrates the model performs worse than a mean baseline, indicating the collected variables lack useful predictive power for 24-hour impressions. The manuscript already reports these exact metrics and concludes that the variables are not sufficient to predict reach. We have revised the predictive-analysis section to state explicitly that the analysis is descriptive only and that no predictive utility is claimed, aligning with the referee's assessment and our overall finding that technical features do not reliably forecast social reach. revision: yes
- Absence of version tracking, access standardization, or sensitivity checks for public-interface drift, as these data were not collected during the original eight-week observational period.
Circularity Check
No significant circularity detected in observational comparisons or exploratory regressions.
full rationale
The paper is an eight-week observational study comparing four LLM families on 68 single-file HTML outputs using fixed public-interface prompts, human scoring, and an LLM judge. The central claims (Claude leading mean performance and winning 9/17 prompts under the human-weighted score) rest directly on the collected scores rather than any derived equation or model. The two supervised predictive analyses (experiment-level X-impressions model and generation-level HTML verbosity model) are explicitly labeled exploratory; the impressions model is reported as weak (negative cross-validated R² = -0.377), while the verbosity model simply shows that a model-family-only baseline yields R² = 0.576 and outperforms prompt-aware alternatives. This is a straightforward variance decomposition within the observed data, not a fitted input renamed as an independent prediction, nor a self-definitional loop. No self-citations, uniqueness theorems, ansatzes, or renamings of known results are used in a load-bearing capacity for the main results. The derivation chain (data collection under stated protocol → scoring → regression fitting) remains self-contained against external benchmarks and does not reduce any claimed result to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Chen, M., Tworek, J., Jun, H., et al. (2021). Evaluating Large Language Models Trained on Code . arXiv:2107.03374
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[2]
Zheng, L., Chiang, W.-L., Sheng, Y., et al. (2023). Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena. arXiv:2306.05685
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Bubeck, S., Chandrasekaran, V., Eldan, R., et al. (2023). Sparks of Artificial General Intelligence: Early Experiments with GPT-4 . arXiv:2303.12712
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Chang, Y., Wang, X., Wang, J., et al. (2024). A Survey on Evaluation of Large Language Models . ACM Transactions on Intelligent Systems and Technology , 15(3)
work page 2024
-
[5]
Cabezas Palacios, D. (2026). HTML AI Battle: Dataset, Notebook, and Paper Materials . GitHub repository: https://github.com/diegocp01/html_ai_battle
work page 2026
-
[6]
Hoerl, A. E., and Kennard, R. W. (1970). Ridge Regression: Biased Estimation for Nonorthogonal Problems. Technometrics, 12(1), 55-67
work page 1970
-
[7]
Tibshirani, R. (1996). Regression Shrinkage and Selection via the Lasso . Journal of the Royal Statistical Society: Series B , 58(1), 267-288
work page 1996
-
[8]
Pedregosa, F., Varoquaux, G., Gramfort, A., et al. (2011). Scikit-learn: Machine Learning in Python . Journal of Machine Learning Research , 12, 2825-2830
work page 2011
-
[9]
Salton, G., and Buckley, C. (1988). Term-Weighting Approaches in Automatic Text Retrieval. Information Processing and Management , 24(5), 513-523
work page 1988
-
[10]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Zhou, S., Xu, F. F., Zhu, H., et al. (2023). WebArena: A Realistic Web Environment for Building Autonomous Agents. arXiv:2307.13854
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[11]
arXiv preprint arXiv:2401.13649 , year=
Koh, J. Y., Lo, R., Jang, L., et al. (2024). VisualWebArena: Evaluating Multimodal Agents on Realistic Visual Web Tasks . arXiv:2401.13649. 15 Appendix A.1 Notebook Data-Exploration Question Summary The notebook’s 1.3 - Data Exploration (EDA) section contains additional descriptive checks that in- formed the paper. The main text uses the strongest of thes...
-
[12]
**Naming Convention:** Do NOT use the exact commercial names of the models. Instead, write their names **phonetically** or use nicknames that fit the flow and rhyme scheme of the song (e.g., "Gem-in-eye," "Gee-P-Tee," "Grok," "Claw-d"). ↪ ↪ 19
-
[13]
**Content:** The lyrics must reflect the specific observations provided and the exact behaviour/output of the model (e.g., if one failed the HTML structure, mock it; if one was perfect, praise it). ↪ ↪
-
[14]
[PROMPT used for the experiment]
**Structure:** Verse-Chorus structure. # Input Data (Observations & Scores) **Model 1: [Model name] GPT-5.1 Extended Thinking** * Observations: [observations] * Score: [score]/10 **Model 2: [Model name] Gemini 3 Pro** * Observations: [observations] * Score: [score]/10 **Model 3: [Model name] Grok 4.1 Thinking** * Observations: [observations] * Score: [sco...
-
[15]
Prompt Adherence Score (PA) Definition: Measures how completely the output implements the specified behavior and constraints found in "The Goal."↪ 21 Scoring Guide: 10: Every requested feature (e.g., specific buttons, specific colors, specific mechanics) is present and accurate.↪ 5: Main features are present, but specific constraints (like color or layout...
-
[16]
broken" states.↪ 5: The app functions but feels
Functional Correctness Score (FC) Definition: Evaluates the stability, physics, and logic of the application based on visual evidence.↪ Scoring Guide: 10: Physics mimic reality (if applicable), controls are responsive, logic flows correctly, and there are no visible glitches or "broken" states.↪ 5: The app functions but feels "janky" or has minor logic er...
-
[17]
UI Quality Score (UI) Definition: Assesses visual design, layout, readability, color hierarchy, and clarity of controls. Scoring Guide: 10: Professional, modern, accessible design. Good use of whitespace, consistent color palette, and clear typography.↪ 22 5: "Engineer Art." It works, but uses raw default HTML styles, clashing colors, or poor spacing. 1: ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.