Recognition: no theorem link
Medical Imaging Classification with Cold-Atom Reservoir Computing using Auto-Encoders and Surrogate-Driven Training
Pith reviewed 2026-05-11 00:44 UTC · model grok-4.3
The pith
A guided autoencoder paired with a differentiable surrogate lets neutral-atom reservoir computing classify polyps more accurately than PCA or unguided encoders.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By replacing direct differentiation through quantum measurements with a trainable surrogate that emulates Rydberg dynamics, the pipeline achieves end-to-end gradient descent that simultaneously learns discriminative image encodings and reservoir parameters, producing classification performance superior to classical dimensionality-reduction baselines on binary polyp-detection tasks.
What carries the argument
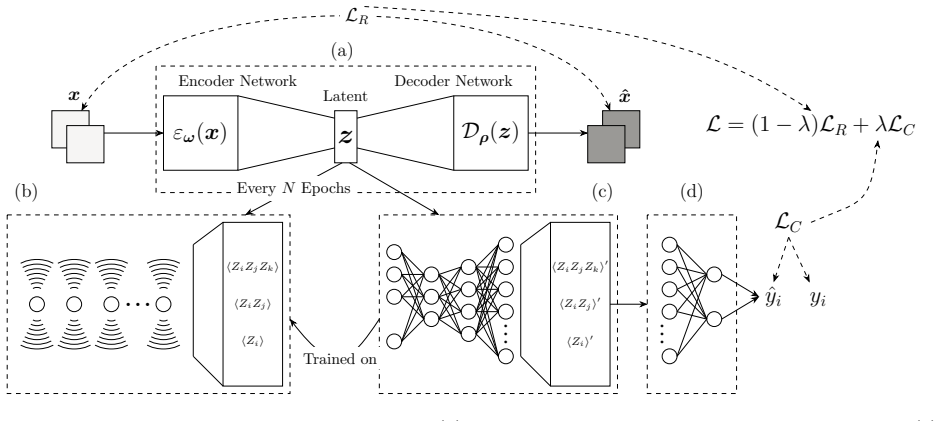
The differentiable surrogate model that emulates non-differentiable quantum measurements and Rydberg Hamiltonian evolution, thereby removing the gradient barrier and permitting joint optimization of the autoencoder and reservoir.
If this is right
- End-to-end training becomes feasible for quantum reservoir systems whose measurements are otherwise non-differentiable.
- The learned latent codes serve as both faithful image reconstructions and suitable inputs for Rydberg-based embedding.
- Performance remains stable under variation of reservoir size, detuning range, and training hyperparameters.
- The approach stays applicable to current noisy intermediate-scale quantum devices for real medical-image tasks.
Where Pith is reading between the lines
- The same surrogate technique could be reused for other reservoir-computing pipelines that face non-differentiable readouts.
- Replacing the linear classifier with a small neural network might further improve accuracy without breaking the gradient flow.
- Testing the trained parameters on real Rydberg hardware would reveal how closely the surrogate must match physical noise to preserve gains.
Load-bearing premise
The surrogate model reproduces the quantum layer's input-output behavior with enough fidelity that any bias it introduces does not erase the reported classification advantage over PCA and unguided autoencoders.
What would settle it
Training the pipeline with the surrogate, then executing the identical parameters on actual cold-atom hardware and finding that classification accuracy falls below the PCA or unguided-autoencoder baselines would falsify the claim that the surrogate enables reliable performance gains.
Figures




read the original abstract
We introduce a hybrid quantum-classical pipeline, based on neutral-atom reservoir computing, for medical image classification, focusing on the binary classification task of polyp detection. To deal effectively with the high dimensionality, we integrate a guided auto-encoder. This pipeline learns compact and discriminative representations of image data that are also well-suited for quantum reservoir computing. A key challenge in such systems is the non-differentiable nature of quantum measurements, which creates a 'gradient barrier' for standard training. We overcome this barrier by incorporating a differentiable surrogate model that emulates the quantum layer, enabling end-to-end backpropagation through the entire system. This guided training process is jointly optimized for classification accuracy and for faithful image recovery from the auto-encoder. The learned latent representations are encoded as pulse detuning parameters within a Rydberg Hamiltonian, and quantum embeddings are subsequently obtained through expectation values. These embeddings are then passed to a linear classifier. Our simulations show that this method outperforms some traditional approaches that use PCA or unguided autoencoders. We also conduct ablation studies to assess the impact of various quantum and training parameters, demonstrating the robustness and flexibility of our proposed pipeline for real-world medical imaging applications, even in the current NISQ era.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a hybrid quantum-classical pipeline for binary classification of medical images (polyp detection) using neutral-atom reservoir computing. It combines a guided auto-encoder to learn compact representations suitable for quantum processing with a differentiable surrogate model to enable end-to-end backpropagation through the non-differentiable quantum measurement layer. Latent representations are encoded as pulse detuning in a Rydberg Hamiltonian, from which expectation-value embeddings are extracted and fed to a linear classifier. The authors report that simulations of this method outperform traditional approaches using PCA or unguided autoencoders, and include ablation studies on quantum and training parameters to demonstrate robustness in the NISQ era.
Significance. Should the quantitative performance improvements be substantiated and the surrogate model's fidelity to the actual Rydberg dynamics be validated, this approach could offer a viable method for leveraging quantum reservoirs in high-dimensional classification tasks like medical imaging. The surrogate-driven training addresses a key technical challenge in hybrid quantum-classical systems, potentially enabling better optimization of quantum embeddings. However, the current lack of detailed metrics limits the ability to gauge its practical impact or novelty relative to existing quantum ML methods.
major comments (2)
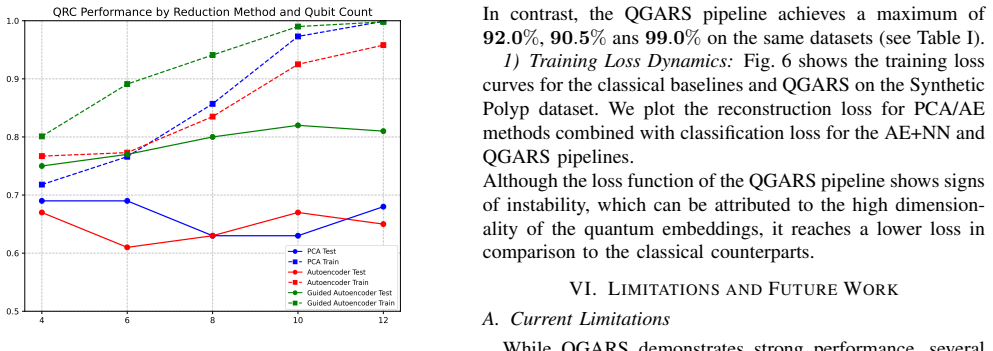
- Abstract: The claim that 'our simulations show that this method outperforms some traditional approaches that use PCA or unguided autoencoders' is presented without any quantitative metrics, such as classification accuracy, precision, recall, or AUC scores, nor error bars or statistical significance tests. This makes it impossible to assess the magnitude or reliability of the reported gains, which is central to the paper's contribution.
- Surrogate model and training procedure: The differentiable surrogate is described as emulating the quantum layer to overcome the gradient barrier, but no validation is provided comparing the surrogate outputs to exact simulations of the Rydberg Hamiltonian evolution or measurements (e.g., no error metrics or plots for the chosen parameters). This is load-bearing for the end-to-end training claim, as bias in the surrogate could mean the optimized embeddings do not translate to the actual quantum system, potentially explaining gains over baselines without true quantum benefit.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which help clarify the presentation of our results. We address each major point below and will incorporate revisions to provide the requested quantitative details and validations.
read point-by-point responses
-
Referee: Abstract: The claim that 'our simulations show that this method outperforms some traditional approaches that use PCA or unguided autoencoders' is presented without any quantitative metrics, such as classification accuracy, precision, recall, or AUC scores, nor error bars or statistical significance tests. This makes it impossible to assess the magnitude or reliability of the reported gains, which is central to the paper's contribution.
Authors: We agree that the abstract would be strengthened by including specific quantitative metrics. The main text already reports detailed classification accuracies, AUC scores, precision, recall, and ablation results with comparisons to PCA and unguided autoencoders (including error bars from multiple runs). In the revision, we will update the abstract to explicitly state key performance numbers (e.g., accuracy gains and AUC values) and note the statistical robustness shown in the experiments. revision: yes
-
Referee: Surrogate model and training procedure: The differentiable surrogate is described as emulating the quantum layer to overcome the gradient barrier, but no validation is provided comparing the surrogate outputs to exact simulations of the Rydberg Hamiltonian evolution or measurements (e.g., no error metrics or plots for the chosen parameters). This is load-bearing for the end-to-end training claim, as bias in the surrogate could mean the optimized embeddings do not translate to the actual quantum system, potentially explaining gains over baselines without true quantum benefit.
Authors: We acknowledge the importance of explicit surrogate validation. The surrogate was designed and trained to approximate the Rydberg dynamics for the specific parameter ranges used in our experiments. In the revised manuscript, we will add a dedicated validation subsection (with plots and metrics such as mean absolute error between surrogate predictions and exact Hamiltonian simulations) to demonstrate fidelity and confirm that the learned embeddings transfer effectively to the true quantum system. revision: yes
Circularity Check
No circularity: pipeline and performance claims are independent of inputs
full rationale
The paper describes a hybrid pipeline that combines a guided auto-encoder with a differentiable surrogate to enable backpropagation through a non-differentiable Rydberg reservoir layer, followed by linear classification on expectation-value embeddings. Performance is reported via direct simulation comparisons against PCA and unguided auto-encoder baselines plus parameter ablations; none of these steps reduce the claimed accuracy gains to a fitted parameter, self-defined quantity, or self-citation chain by construction. The surrogate is presented strictly as an optimization tool rather than a redefinition of the target quantum dynamics, leaving the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
A guide to deep learning in healthcare,
A. Esteva, A. Robicquet, B. Ramsundar, V . Kuleshov, M. DePristo, K. Chou, C. Cui, G. Corrado, S. Thrun, and J. Dean, “A guide to deep learning in healthcare,”Nature Medicine, vol. 25, no. 1, pp. 24–29, Jan. 2019
work page 2019
- [2]
-
[3]
P. Mei and F. Zhang, “A framework for processing large-scale health data in medical higher-order correlation mining by quantum computing in smart healthcare,”Frontiers in Digital Health, vol. 6, p. 1502745, Nov. 2024
work page 2024
-
[4]
Recent advances in physical reservoir computing: A review,
G. Tanaka, T. Yamane, J. B. H ´eroux, R. Nakane, N. Kanazawa, S. Takeda, H. Numata, D. Nakano, and A. Hirose, “Recent advances in physical reservoir computing: A review,”Neural Networks, vol. 115, pp. 100–123, Jul. 2019
work page 2019
-
[5]
Harnessing disordered quantum dynamics for machine learning,
K. Fujii and K. Nakajima, “Harnessing disordered quantum dynamics for machine learning,”Physical Review Applied, vol. 8, no. 2, p. 024030, Aug. 2017
work page 2017
-
[6]
Optimal quantum reservoir computing for the NISQ era,
L. Domingo, G. Carlo, and F. Borondo, “Optimal quantum reservoir computing for the NISQ era,” May 2022
work page 2022
-
[7]
Large-scale quantum reservoir learning with an analog quantum computer,
M. Kornjavcaet al., “Large-scale quantum reservoir learning with an analog quantum computer,” Jul. 2024
work page 2024
-
[8]
Barren plateaus in quantum neural network training landscapes,
J. R. McClean, S. Boixo, V . N. Smelyanskiy, R. Babbush, and H. Neven, “Barren plateaus in quantum neural network training landscapes,”Nature Communications, vol. 9, no. 1, p. 4812, Nov. 2018
work page 2018
-
[9]
A Tutorial on Principal Component Analysis,
J. Shlens, “A Tutorial on Principal Component Analysis,” Apr. 2014
work page 2014
-
[10]
Principal component analysis: A review and recent developments,
I. T. Jolliffe and J. Cadima, “Principal component analysis: A review and recent developments,”Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences, vol. 374, no. 2065, p. 20150202, Apr. 2016
work page 2065
-
[11]
Guided Quantum Compression for High Dimensional Data Classifi- cation,
V . Belis, P. Odagiu, M. Grossi, F. Reiter, G. Dissertori, and S. Vallecorsa, “Guided Quantum Compression for High Dimensional Data Classifi- cation,”Machine Learning: Science and Technology, vol. 5, no. 3, p. 035010, Sep. 2024
work page 2024
-
[12]
Reducing the Dimensionality of Data with Neural Networks,
G. E. Hinton and R. R. Salakhutdinov, “Reducing the Dimensionality of Data with Neural Networks,”Science, vol. 313, no. 5786, pp. 504–507, Jul. 2006
work page 2006
-
[13]
Quantum Surrogate-Driven Image Classifier: A Gradient-Free Approach to Avoid Barren Plateaus,
Y . Xie, “Quantum Surrogate-Driven Image Classifier: A Gradient-Free Approach to Avoid Barren Plateaus,” May 2025
work page 2025
-
[14]
Harnessing Quantum Extreme Learning Machines for image classification,
A. D. Lorenzis, M. P. Casado, M. P. Estarellas, N. L. Gullo, T. Lux, F. Plastina, A. Riera, and J. Settino, “Harnessing Quantum Extreme Learning Machines for image classification,”Physical Review Applied, vol. 23, no. 4, Apr. 2025
work page 2025
-
[15]
Convolutional autoencoders for spatially- informed ensemble post-processing,
S. Lerch and K. L. Polsterer, “Convolutional autoencoders for spatially- informed ensemble post-processing,” Apr. 2022
work page 2022
-
[16]
M. Raissi, P. Perdikaris, and G. E. Karniadakis, “Physics Informed Deep Learning (Part I): Data-driven Solutions of Nonlinear Partial Differential Equations,” Nov. 2017
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.