Recognition: no theorem link
Semantic State Abstraction Interfaces for LLM-Augmented Portfolio Decisions: Multi-Axis News Decomposition and RL Diagnostics
Pith reviewed 2026-05-11 00:54 UTC · model grok-4.3
The pith
Semantic State Abstraction Interfaces turn sparse news into four named coordinates to isolate representation quality from optimization variance in sequential portfolio decisions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We introduce Semantic State Abstraction Interfaces (SSAI): a methodological template for mapping sparse unstructured text into K auditable, named coordinates with neutral defaults on no-news days, designed to separate representation hypotheses from optimisation variance in sequential decision systems. Our contribution is the framework and its evaluation protocol, not a claim that SSAI outperforms denser alternatives. We instantiate SSAI with K=4 axes on a US-equity panel and evaluate it across direct factor portfolios, supervised ridge forecasters, and RL agents that share the same fixed mapping; apparent gains fail coverage-stratified controls, reverse at modest transaction costs, and are 1
What carries the argument
Semantic State Abstraction Interfaces (SSAI), which decompose news into K named axes with neutral defaults to produce a fixed state vector for downstream decision systems.
If this is right
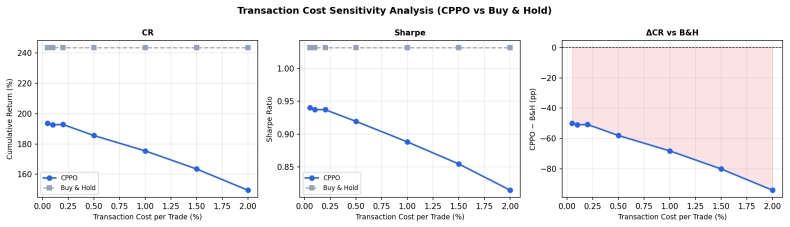
- The four-axis factor portfolio reaches 307.2 percent cumulative return yet fails coverage-stratified controls and reverses at 0.2 percent or higher transaction costs.
- PC1 composite and FinBERT baselines produce stronger ranking signals than the four-axis decomposition in this panel.
- Ridge and RL blocks using the fixed SSAI state allow direct comparison of representation versus optimiser contributions.
- SSAI functions as an interpretability-performance diagnostic and reusable protocol for any sparse-text sequential decision task.
Where Pith is reading between the lines
- The same neutral-default mapping could be tested in non-finance sequential settings such as energy dispatch or inventory control whenever text arrives irregularly.
- If the protocol is adopted, future work could vary the number of axes or the choice of named coordinates while holding the RL optimizer fixed to measure marginal diagnostic value.
- The approach supplies a concrete audit trail for LLM-augmented agents by forcing every news item into a small set of human-readable coordinates rather than opaque embeddings.
Load-bearing premise
The specific choice of four axes together with the coverage-stratified controls is sufficient to isolate representation quality from optimization effects.
What would settle it
Running the identical RL agents on the same data but with a denser text embedding in place of the four-axis SSAI state, then observing that performance gaps disappear after applying the same coverage controls and cost thresholds.
Figures


read the original abstract
We introduce Semantic State Abstraction Interfaces (SSAI): a methodological template for mapping sparse unstructured text into $K$ auditable, named coordinates with neutral defaults on no-news days, designed to separate representation hypotheses from optimisation variance in sequential decision systems. Our contribution is the framework and its evaluation protocol, not a claim that SSAI outperforms denser alternatives. We instantiate SSAI with $K=4$ axes (sentiment, risk, confidence, volatility forecast) on a US-equity panel (30 NASDAQ-100 names, FNSPID news, 2019--2023 test), and evaluate it across direct factor portfolios, supervised ridge forecasters, and RL agents (DP-PPO, SAC) that share the same fixed $\phi$. The four-factor factor portfolio reaches 307.2% cumulative return and Sharpe 1.067, but apparent gains versus buy-and-hold (243.6%) fail coverage-stratified controls, reverse at $\geq 0.2$% costs, and are statistically fragile versus a sentiment-only baseline; a PC1 composite and a FinBERT portfolio baseline are stronger ranking signals in this setting. Ridge and RL blocks diagnose representation versus optimiser effects. We position SSAI as an interpretability-performance diagnostic and reusable protocol for sparse-text decision systems.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Semantic State Abstraction Interfaces (SSAI) as a methodological template for mapping sparse unstructured text into K auditable, named coordinates with neutral defaults on no-news days, designed to separate representation hypotheses from optimisation variance in sequential decision systems. The authors instantiate SSAI with K=4 axes (sentiment, risk, confidence, volatility forecast) on a US-equity panel (30 NASDAQ-100 names, FNSPID news, 2019-2023), evaluating across direct factor portfolios (reaching 307.2% cumulative return, Sharpe 1.067), supervised ridge forecasters, and RL agents (DP-PPO, SAC) that share a fixed φ. The paper reports that apparent gains versus buy-and-hold fail coverage-stratified controls, reverse at ≥0.2% transaction costs, and are statistically fragile versus sentiment-only or PC1 baselines, positioning SSAI as an interpretability-performance diagnostic and reusable protocol rather than a performance claim.
Significance. If the SSAI template holds, it would supply a reusable protocol for creating interpretable, low-dimensional state representations from sparse text in LLM-augmented RL and forecasting systems, with an evaluation design that uses fixed representations across optimizers and cross-representation baselines to isolate effects. The transparent reporting of negative results (failure under controls and vs simpler baselines) is a strength that supports the diagnostic framing and could help the field move beyond opaque performance claims in text-based decision systems. The approach has moderate significance for cs.LG work on hybrid LLM-RL agents in finance, provided the extraction methods are made reproducible.
major comments (2)
- [Instantiation of SSAI] Instantiation section (details of axis extraction): The manuscript does not specify the exact procedure for deriving the four axes from FNSPID news text (e.g., LLM prompts, fine-tuned models, or heuristics for sentiment, risk, confidence, and volatility forecast). This detail is load-bearing for the claimed auditability, neutral defaults, and reusability of the SSAI template as a methodological contribution.
- [Evaluation protocol] Evaluation and results section: The coverage-stratified controls and the statistical tests establishing 'statistical fragility' versus the sentiment-only baseline are described at a high level but lack the precise stratification criteria, test statistics, or p-value thresholds. Without these, it is difficult to verify that the controls adequately separate representation quality from optimization effects as asserted.
minor comments (3)
- [Abstract and Method] The abstract and method sections should explicitly define how the neutral default values are assigned on no-news days and confirm that φ is constructed identically from the four axes in all blocks.
- [RL and ridge blocks] Add a table or appendix listing the exact hyperparameters for DP-PPO and SAC, as well as the ridge regularization details, to support reproducibility of the optimizer-effect diagnostics.
- [Introduction/Related work] The related-work discussion would benefit from citations to prior state-abstraction methods in RL and text-feature extraction in quantitative finance to better situate the SSAI template.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and for recognizing the diagnostic intent and transparent reporting of negative results. We address the two major comments below and will incorporate the requested details in the revision to improve reproducibility and verifiability.
read point-by-point responses
-
Referee: [Instantiation of SSAI] The manuscript does not specify the exact procedure for deriving the four axes from FNSPID news text (e.g., LLM prompts, fine-tuned models, or heuristics for sentiment, risk, confidence, and volatility forecast). This detail is load-bearing for the claimed auditability, neutral defaults, and reusability of the SSAI template as a methodological contribution.
Authors: We agree that the precise extraction procedure must be documented for auditability and reusability. The current text describes the axes conceptually but does not include the implementation steps. In the revised manuscript we will add a subsection detailing the exact LLM prompts employed for each axis, the neutral-default assignment logic on no-news days, and any post-processing or aggregation rules. This addition will directly support the methodological template claims without altering the reported results. revision: yes
-
Referee: [Evaluation protocol] The coverage-stratified controls and the statistical tests establishing 'statistical fragility' versus the sentiment-only baseline are described at a high level but lack the precise stratification criteria, test statistics, or p-value thresholds. Without these, it is difficult to verify that the controls adequately separate representation quality from optimization effects as asserted.
Authors: We acknowledge the need for greater specificity to enable independent verification. In the revision we will expand the Evaluation section to state the exact coverage stratification criteria (including bin definitions based on news-item counts), the statistical tests performed (e.g., paired comparisons of Sharpe ratios or returns with any bootstrap or multiple-testing adjustments), the p-value thresholds used to classify fragility, and the numerical test statistics and p-values for the key contrasts against the sentiment-only and PC1 baselines. These additions will clarify the separation of representation and optimization effects. revision: yes
Circularity Check
No significant circularity identified
full rationale
The paper presents SSAI as an explicit methodological template and evaluation protocol rather than deriving a performance result from fitted parameters. The abstract and evaluation sections report that the four-axis instantiation fails coverage-stratified controls, reverses at modest costs, and is fragile versus baselines, positioning negative outcomes as diagnostic evidence. No equation or claim reduces by construction to its own inputs; cross-representation comparisons (PC1, FinBERT, sentiment-only) and fixed-φ RL/ridge blocks supply independent contrasts. The framework is self-contained against external benchmarks with no load-bearing self-citation or ansatz smuggling.
Axiom & Free-Parameter Ledger
free parameters (2)
- K=4 and axis names
- Neutral default values
axioms (2)
- domain assumption The four chosen axes capture the relevant semantic content of news for portfolio decisions.
- domain assumption Coverage-stratified controls and cost analysis isolate representation effects from optimization variance.
Reference graph
Works this paper leans on
-
[1]
Mostapha Benhenda. FinRL-DeepSeek: LLM-infused risk-sensitive reinforcement learning for trading agents.arXiv preprint arXiv:2502.07393,
-
[2]
Language models are few-shot learners.Advances in Neural Information Processing Systems, 33:1877–1901,
Tom Brown, Benjamin Mann, Nick Ryder, et al. Language models are few-shot learners.Advances in Neural Information Processing Systems, 33:1877–1901,
1901
-
[3]
FNSPID: A comprehensive financial news dataset in time series.arXiv preprint arXiv:2402.06698,
Zihan Dong, Xinyu Fan, and Zhiyuan Peng. FNSPID: A comprehensive financial news dataset in time series.arXiv preprint arXiv:2402.06698,
-
[4]
Finrl: A deep reinforcement learning library for automated stock trading in quantitative finance
Xiao-Yang Liu, Hongyang Yang, Qian Chen, Runjia Zhang, Liuqing Yang, Bowen Xiao, and Christina Dan Wang. FinRL: A deep reinforcement learning library for automated stock trading in quantitative finance.arXiv preprint arXiv:2011.09607,
-
[5]
Xiao-Yang Liu, Jingyang Rui, Jiechao Gao, Liuqing Yang, Hongyang Yang, Zhaoran Wang, Christina Dan Wang, and Jian Guo. FinRL-Meta: Market environments and benchmarks for data-driven financial reinforcement learning.arXiv preprint arXiv:2211.03107,
-
[6]
FinGPT: Open-source financial large language models,
Xiao-Yang Liu, Guoxuan Wang, and Daochen Zha. FinGPT: Open-source financial large language models.arXiv preprint arXiv:2306.06031,
-
[7]
Alejandro Lopez-Lira and Yuehua Tang. Can ChatGPT forecast stock price movements? Return predictability and large language models.arXiv preprint arXiv:2304.07619,
-
[8]
Benchmarking safe exploration in deep reinforcement learning,
Alex Ray, Joshua Achiam, and Dario Amodei. Benchmarking safe exploration in deep reinforcement learning.arXiv preprint arXiv:1910.01708,
-
[9]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms.arXiv preprint arXiv:1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
BloombergGPT: A Large Language Model for Finance
Shijie Wu, Ozan Irsoy, Steven Lu, et al. BloombergGPT: A large language model for finance.arXiv preprint arXiv:2303.17564,
work page internal anchor Pith review arXiv
-
[11]
sparse- signal replay
Hongyang Yang, Xiao-Yang Liu, Shan Zhong, and Anwar Walid. FinRL: A deep reinforcement learning library for automated stock trading in quantitative finance.NeurIPS Workshop on Deep RL, 2020a. Hongyang Yang, Xiao-Yang Liu, Shan Zhong, and Anwar Walid. Deep reinforcement learning for automated stock trading: An ensemble strategy.Proceedings of the First ACM...
2013
-
[12]
is not specific to portfolio tradingas a definition. Any sequential system that occasionally observes sparse unstructured textcoulduse a fixed-axis LLM interface as an auditable, sparse-by-design augmentation.The present submission does not run experiments in these domains;the following areillustrativesketches only: clinical triage (patient notes → urgenc...
2019
-
[13]
43 -9.80 2.45 -12.25 -1.145 Recovery Bull (May 2020–Dec
2020
-
[14]
Buy-and-hold has no ongoing rebalance cost in this sweep; DP-PPO remains below the passive sleeve across tested cost levels
422 144.86 110.56 34.30 2.159 Rate Hike Bear (2022) 251 -38.91 -28.99 -9.92 -1.194 2023 Rally (2023) 250 54.91 55.44 -0.53 2.163 Table 10: Transaction-cost sensitivity for the released DP-PPO checkpoint. Buy-and-hold has no ongoing rebalance cost in this sweep; DP-PPO remains below the passive sleeve across tested cost levels. Cost (%) DP-PPO CR B&H CR∆CR...
2022
-
[15]
Table 12: SFP transaction-cost sensitivity (2019–2023)
coincides with the AI-investment-cycle rally that disproportionately benefited NVDA, GOOGL, and A VGO—the high-coverage NASDAQ names that dominate the SFP basket (see SRF/SCW coincidence discussion in Section 5.2).Caveat:it is not possible to rule out that SFP’s 2023 excess return is a disguised factor exposure to the AI-driven index rally rather than a s...
2023
-
[16]
E.8 Coverage-Stratified SFP Analysis Table 3 (presented in Section 5.2) addresses the coverage confound directly. We split the 30-ticker universe into terciles by non-neutral coverage fraction and evaluate SFP within each tercile, comparing against an equal-weight B&H sleeve of thesame tickers.Key result: SFP does not outperform equal-weight B&H within an...
2013
-
[17]
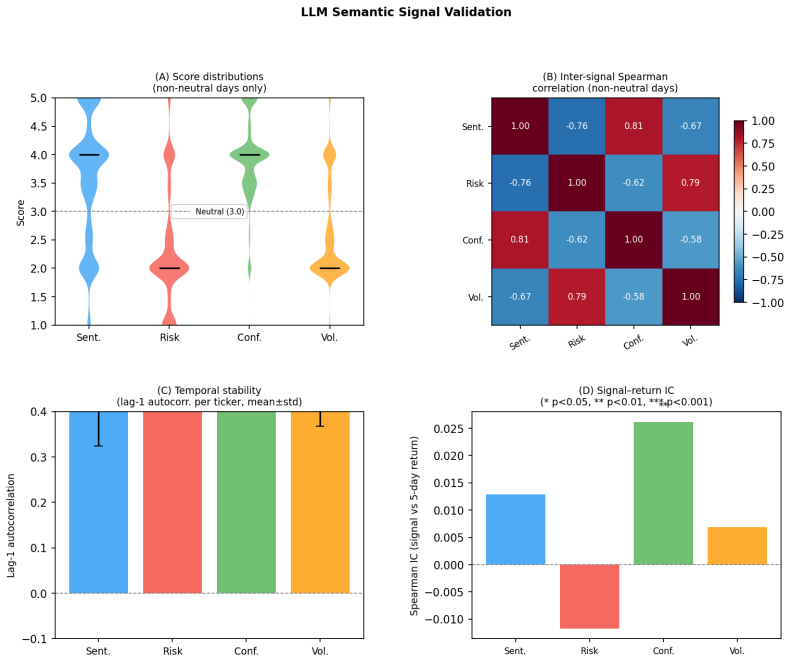
confirms: within any fixed coverage tercile, SFP does not outperform equal-weight B&H. The LLM scores are a necessary ingredient (without them there is no ranking), but the performance originates from which names areselected, not from the direction of the scores on selected names. F LLM Signal Validation Table 14: Descriptive statistics of LLM-generated s...
2013
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.