Recognition: 2 theorem links
· Lean TheoremA Statistical Framework for Algorithmic Collective Action with Multiple Collectives
Pith reviewed 2026-05-11 00:44 UTC · model grok-4.3
The pith
Multiple collectives can jointly steer a shared classifier with statistical success bounds each group computes from partial knowledge of the others.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose the first comprehensive statistical framework for algorithmic collective action with multiple collectives acting on the same system. We provide quantitative statistical bounds on the success of the collectives, considering the role and the interplay of the collectives' sizes and the alignment of their goals. We make such bounds computable by each collective with only partial knowledge of other collectives' sizes and strategies.
What carries the argument
A family of statistical bounds on collective success probability that incorporate group sizes and goal-alignment parameters while remaining computable under partial observability of other groups.
If this is right
- Success probability rises when collectives are larger or when their goals align more closely.
- Each collective can obtain usable numerical bounds without full knowledge of the others' sizes or chosen strategies.
- The same bounding technique applies to any classification task in which data alterations can influence model decisions.
- Simulations confirm that the bounds track observed success rates across different size and alignment regimes in smart-city planning scenarios.
Where Pith is reading between the lines
- Fragmented advocacy groups could use the bounds to decide the minimum scale needed to reach a target influence level.
- The partial-information structure may extend to non-classification settings such as regression or ranking systems.
- Operators of public models could monitor aggregate data patterns for early signs that multiple collectives are approaching a success threshold.
Load-bearing premise
Coordinated changes to data by user collectives produce measurable, statistically predictable shifts in a classifier's output behavior.
What would settle it
Run a controlled test in which collectives of known sizes apply specified data perturbations to a classifier and measure the resulting change rate; check whether the observed rate lies inside the framework's predicted interval for the given sizes and alignments.
Figures
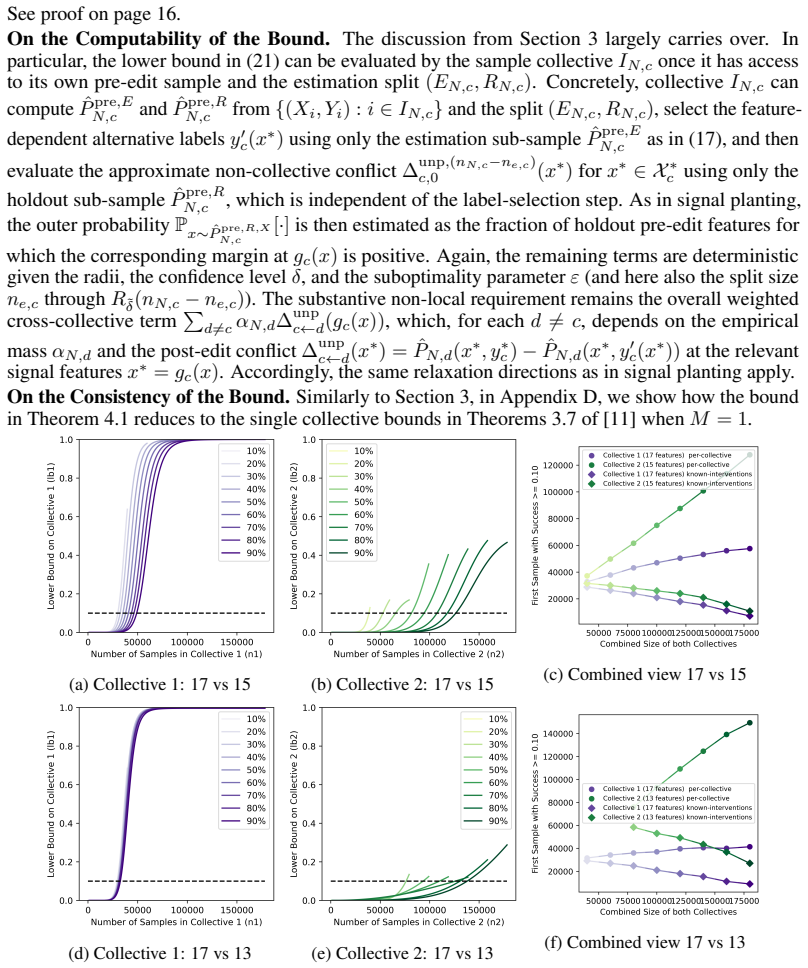

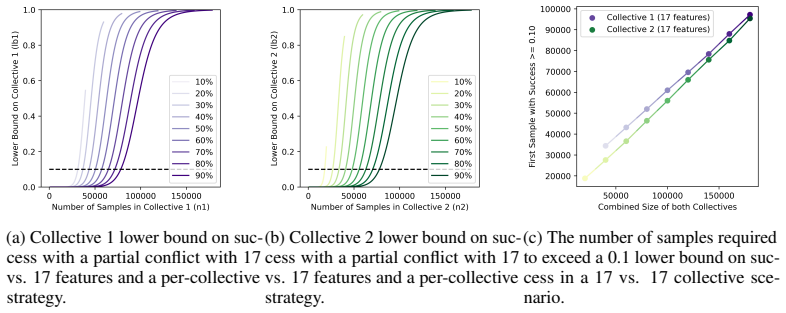
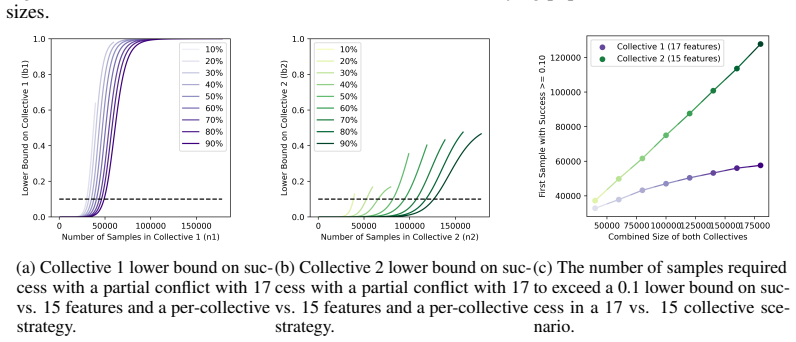
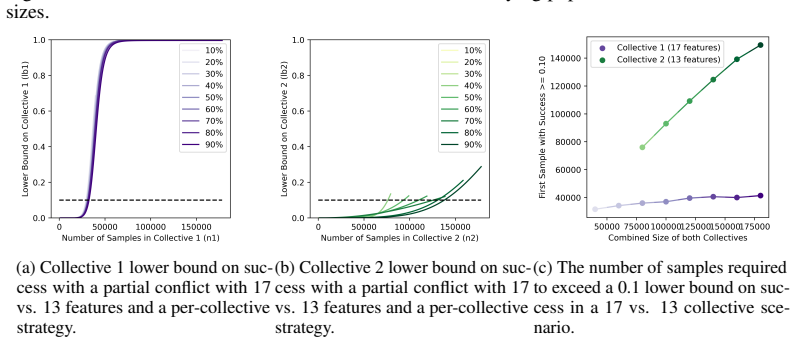
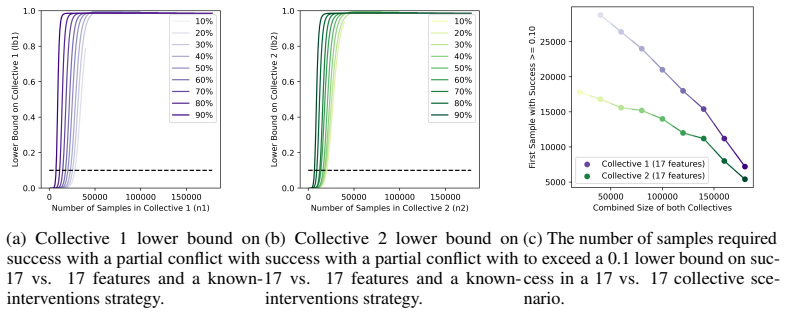
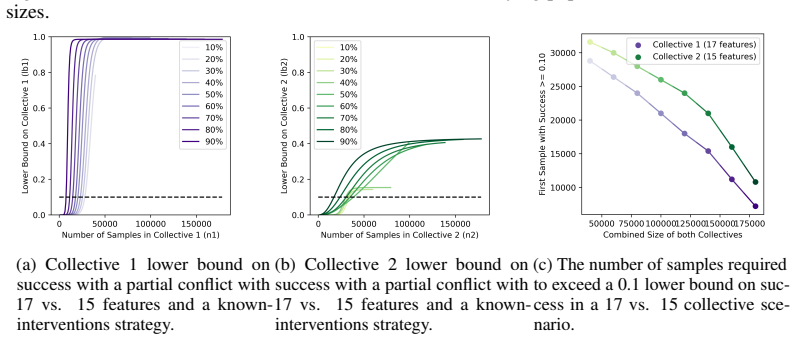
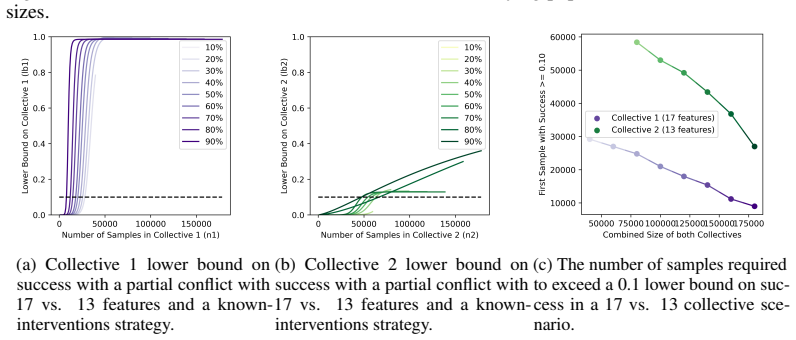
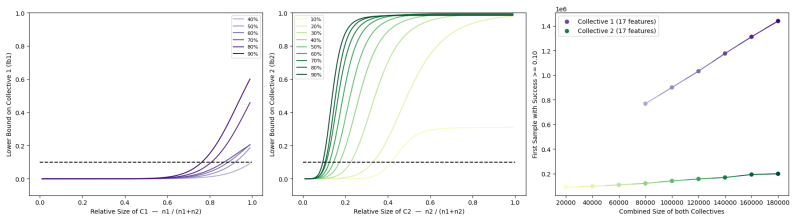
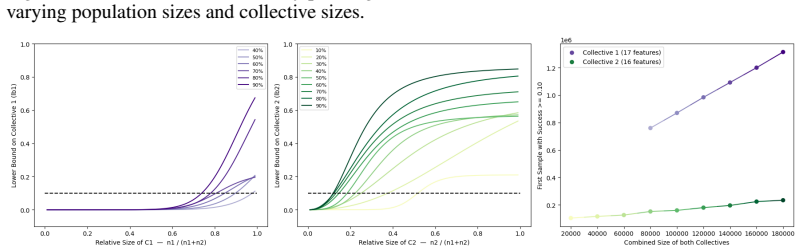
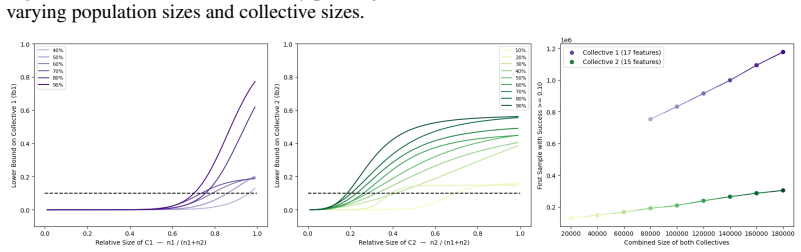
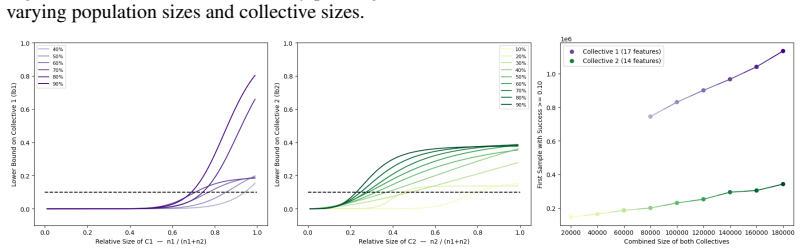
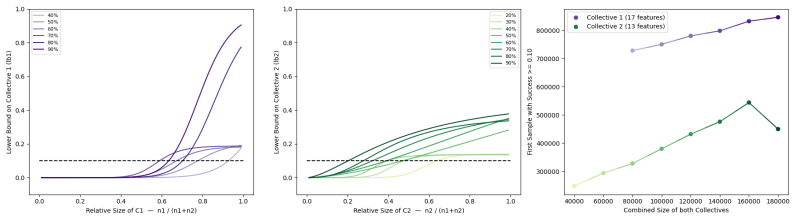
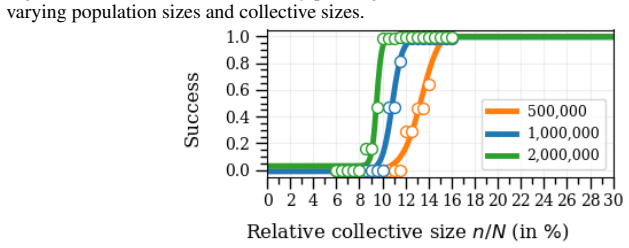

read the original abstract
As learning systems increasingly shape everyday decisions, Algorithmic Collective Action (ACA), i.e., users coordinating changes to shared data to steer model behavior, offers a complement to regulator-side policy and corporate model design. Real-world collective actions have traditionally been decentralized and fragmented into multiple collectives, despite sharing overarching objectives, with each collective differing in size, strategy, and actionable goals. However, most of the ACA literature focuses on single collective settings. To address this, we propose the first comprehensive statistical framework for ACA with multiple collectives acting on the same system. In particular, we focus on collective action in classification, studying how multiple collectives can influence a classifier's behavior. We provide quantitative statistical bounds on the success of the collectives, considering the role and the interplay of the collectives' sizes and the alignment of their goals. We make such bounds computable by each collective with only partial knowledge of other collectives' sizes and strategies. Finally, we numerically illustrate our framework on simulations inspired by interventions for climate adaptation in smart cities, demonstrating the usefulness of our bounds.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes the first statistical framework for algorithmic collective action (ACA) involving multiple collectives that coordinate data changes to influence a shared classifier. It derives quantitative bounds on the joint success probability of the collectives, incorporating their sizes, goal alignments, and partial information about others, and illustrates the framework through simulations inspired by climate-adaptation interventions in smart cities.
Significance. If the bounds are rigorously derived and hold under the framework's assumptions, the work would fill a notable gap in the ACA literature by moving beyond single-collective settings to realistic decentralized scenarios. The emphasis on partial-information computability could make the results actionable for collectives, and the simulation study provides relevant empirical grounding. Strengths include the focus on interplay between collectives and the attempt to ground bounds in statistical principles.
major comments (2)
- [Abstract and framework description] The central claim (abstract) that the success bounds are computable by each collective using only its own size, goal alignment, and partial knowledge of others requires an explicit model of how collectives modify features/labels, a stated loss function or training procedure, and a derivation method (concentration inequality, influence function, or minimax). Without these, it is impossible to verify that the partial-information expressions remain valid rather than depending on the full joint data distribution or exact optimization details.
- [§3] §3 (bounds derivation): the quantitative statistical bounds on collective success must be shown to be independent of unspecified distributional assumptions; if the expressions reduce to fitted parameters or require full knowledge of other collectives' strategies, the partial-information guarantee does not hold.
minor comments (1)
- [Simulation section] The simulation section would benefit from clearer reporting of the exact classifier training procedure and data-generation process used to generate the numerical results.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback, which identifies key areas where the presentation of our statistical framework can be strengthened. We respond to each major comment below and commit to revisions that enhance clarity without altering the core contributions.
read point-by-point responses
-
Referee: [Abstract and framework description] The central claim (abstract) that the success bounds are computable by each collective using only its own size, goal alignment, and partial knowledge of others requires an explicit model of how collectives modify features/labels, a stated loss function or training procedure, and a derivation method (concentration inequality, influence function, or minimax). Without these, it is impossible to verify that the partial-information expressions remain valid rather than depending on the full joint data distribution or exact optimization details.
Authors: We agree that the modeling choices and derivation method should be stated more explicitly to allow verification of the partial-information property. Section 2 defines collective actions as coordinated modifications (label flips or targeted feature shifts) on subsets of the training data. The classifier is obtained by empirical risk minimization under the logistic loss. The success bounds are obtained via McDiarmid's bounded-differences inequality applied to the indicator of correct classification after the modifications; this yields expressions that depend only on collective sizes, an alignment parameter, and an uncertainty set over the unknown actions of other collectives. The resulting bounds are therefore computable from local information alone. We will insert a dedicated paragraph in Section 2 that enumerates these modeling choices and the concentration inequality used, together with a short proof sketch confirming that the expressions do not require the full joint distribution. revision: yes
-
Referee: [§3] §3 (bounds derivation): the quantitative statistical bounds on collective success must be shown to be independent of unspecified distributional assumptions; if the expressions reduce to fitted parameters or require full knowledge of other collectives' strategies, the partial-information guarantee does not hold.
Authors: The bounds in §3 are distribution-free in the sense that McDiarmid's inequality requires only that the loss is bounded (a mild assumption satisfied by 0-1 classification error) and does not depend on any further properties of the data-generating distribution. The alignment parameter is treated as a known or estimable scalar that each collective can set using its own data and a conservative range for the others' strategies; no fitted parameters from the joint distribution or exact optimization details of other collectives enter the final expressions. We will add a remark immediately after the main theorem in §3 that explicitly states these independence properties and shows how the partial-information uncertainty set is constructed, thereby confirming that the computability claim holds under the stated assumptions. revision: yes
Circularity Check
No circularity: bounds derived from statistical principles without reduction to inputs
full rationale
The paper proposes a statistical framework deriving quantitative bounds on collective success probabilities from sizes, goal alignments, and partial information on other collectives. No equations or sections in the provided text reduce the claimed bounds to fitted parameters, self-definitions, or self-citation chains by construction. The derivation relies on external classification theory and concentration inequalities rather than tautological renaming or ansatz smuggling. Partial-knowledge computability is presented as a modeling feature, not a re-expression of full-information results. This is a standard non-circular outcome for a framework paper.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Coordinated changes to shared data can influence a classifier's behavior in a quantifiable way.
- domain assumption Collectives possess partial knowledge of others' sizes and strategies sufficient to compute success bounds.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.lean; IndisputableMonolith/Cost/FunctionalEquation.leanreality_from_one_distinction; washburn_uniqueness_aczel unclearWe provide quantitative statistical bounds on the success of the collectives... using Hoeffding’s concentration inequality... ε-contamination-suboptimal classifier... Theorems 3.1 and 4.1 derive lower bounds involving αN,c ˆpX_c, Δc→d, and Rγ(k) radii.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery; embed_injective unclearThe framework assumes... coordinated data changes... statistical model allows derivation of bounds computable under partial information, without detailing the precise data distributions or classifier training assumptions.
Reference graph
Works this paper leans on
-
[1]
MIT press, 2023
Solon Barocas, Moritz Hardt, and Arvind Narayanan.Fairness and machine learning: Limita- tions and opportunities. MIT press, 2023
2023
-
[2]
Algorithmic collective action with multiple collectives
Claudio Battiloro, Pietro Greiner, Bret Nestor, Oumaima Amezgar, and Francesca Dominici. Algorithmic collective action with multiple collectives. InNeurIPS 2025 (Non-archival) Workshop on Algorithmic Collective Action, 2025
2025
-
[3]
Algorithmic collective action in recom- mender systems: promoting songs by reordering playlists.Advances in Neural Information Processing Systems, 37:119123–119149, 2024
Joachim Baumann and Celestine Mendler-Dünner. Algorithmic collective action in recom- mender systems: promoting songs by reordering playlists.Advances in Neural Information Processing Systems, 37:119123–119149, 2024
2024
-
[4]
The role of learning algorithms in collective action
Omri Ben-Dov, Jake Fawkes, Samira Samadi, and Amartya Sanyal. The role of learning algorithms in collective action. InInternational Conference on Machine Learning (ICML), volume 235, pages 3443–3461. PMLR, 2024
2024
-
[5]
Fairness for the people, by the people: Minority collective action
Omri Ben-Dov, Samira Samadi, Amartya Sanyal, and Alexandru Tifrea. Fairness for the people, by the people: Minority collective action. InNeurIPS 2025 (Non-archival) Workshop on Algorithmic Collective Action (ACA), 2025
2025
-
[6]
Heat mapping – heat watch, 2025
CAPA Strategies, LLC. Heat mapping – heat watch, 2025
2025
-
[7]
Rotterdam in transformation: Vision on the digital city 1.0, 2024
City of Rotterdam, CIO Office. Rotterdam in transformation: Vision on the digital city 1.0, 2024
2024
-
[8]
Building, shifting, & employing power: A taxonomy of responses from below to algorithmic harm
Alicia DeVrio, Motahhare Eslami, and Kenneth Holstein. Building, shifting, & employing power: A taxonomy of responses from below to algorithmic harm. InProceedings of the 2024 ACM Conference on Fairness, Accountability, and Transparency, pages 1093–1106, 2024
2024
-
[9]
European Parliament and Council of the European Union. Regulation (eu) 2016/679 of the european parliament and of the council of 27 april 2016 on the protection of natural persons with regard to the processing of personal data and on the free movement of such data, and repealing directive 95/46/ec (general data protection regulation).Official Journal of t...
2016
-
[10]
Altruistic collective action in recommender systems
Ekaterina Fedorova, Madeline Celi Kitch, and Chara Podimata. Altruistic collective action in recommender systems. InNeurIPS 2025 (Non-archival) Workshop on Algorithmic Collective Action (ACA), 2025
2025
-
[11]
Etienne Gauthier, Francis Bach, and Michael I. Jordan. Statistical collusion by collectives on learning platforms. InForty-second International Conference on Machine Learning (ICML), 2025
2025
-
[12]
Personal information protection and electronic documents act, 2000
Government of Canada. Personal information protection and electronic documents act, 2000. S.C. 2000, c. 5
2000
-
[13]
A cyborg manifesto: Science, technology, and socialist-feminism in the late twentieth century
Donna Haraway. A cyborg manifesto: Science, technology, and socialist-feminism in the late twentieth century. InThe transgender studies reader, pages 103–118. Routledge, 2013
2013
-
[14]
Algorithmic collective action in machine learning
Moritz Hardt, Eric Mazumdar, Celestine Mendler-Dünner, and Tijana Zrnic. Algorithmic collective action in machine learning. InInternational Conference on Machine Learning (ICML), volume 202, pages 12570–12586. PMLR, 2023
2023
-
[15]
Empowering users together: Connecting algorithmic collective action and explainable ai
Ayana Hussain, Cole Michael Thacker, Patrick Zhao, Aditya Karan, and Nicholas Vincent. Empowering users together: Connecting algorithmic collective action and explainable ai. In NeurIPS 2025 (Non-archival) Workshop on Algorithmic Collective Action (ACA), 2025
2025
-
[16]
Sync or sink: Bounds on algorithmic collective action with noise and multiple groups
Aditya Karan, Prabhat Kalle, Nicholas Vincent, and Hari Sundaram. Sync or sink: Bounds on algorithmic collective action with noise and multiple groups. InNeurIPS 2025 (Non-archival) Workshop on Algorithmic Collective Action (ACA), 2025
2025
-
[17]
Algorithmic collec- tive action with two collectives
Aditya Karan, Nicholas Vincent, Karrie Karahalios, and Hari Sundaram. Algorithmic collec- tive action with two collectives. InProceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency, pages 1468–1483, 2025. 10
2025
-
[18]
Oxford University Press, Oxford, 2005
Bruno Latour.Reassembling the Social: An Introduction to Actor-Network-Theory. Oxford University Press, Oxford, 2005. ISBN 9780199256044
2005
-
[19]
Workers vs
Kristina Lewandowska. Workers vs. the algorithm: Simulating collective action in gig-economy platforms. InNeurIPS 2025 (Non-archival) Workshop on Algorithmic Collective Action (ACA), 2025
2025
-
[20]
Pii- scope: A comprehensive study on training data privacy leakage in pretrained llms
Krishna Kanth Nakka, Ahmed Frikha, Ricardo Mendes, Xue Jiang, and Xuebing Zhou. Pii- scope: A comprehensive study on training data privacy leakage in pretrained llms. InProceed- ings of the 14th International Joint Conference on Natural Language Processing and the 4th Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics,...
2025
-
[21]
Mapping campaigns
National Oceanic and Atmospheric Administration (NOAA). Mapping campaigns. HEAT.gov, 2025
2025
-
[22]
Artificial intelligence risk management framework: Generative artificial intelligence profile.NIST Trustworthy and Responsible AI Gaithersburg, MD, USA, 2024
NIST. Artificial intelligence risk management framework: Generative artificial intelligence profile.NIST Trustworthy and Responsible AI Gaithersburg, MD, USA, 2024
2024
-
[23]
Android ai app exposes nearly 2m user images and videos: anyone can watch your videos
Paulina Okunyt˙e. Android ai app exposes nearly 2m user images and videos: anyone can watch your videos. Cybernews, February 2026. Published: 19 Feb 2026; last updated: 20 Feb 2026. Accessed: 24 Feb 2026
2026
-
[24]
Exclusive: Openai used kenyan workers on less than $2 per hour to make chatgpt less toxic.TIME, January 2023
Billy Perrigo. Exclusive: Openai used kenyan workers on less than $2 per hour to make chatgpt less toxic.TIME, January 2023. Published Jan 18, 2023. Accessed Feb 24, 2026
2023
-
[25]
Transfusion: Understand- ing transfer learning for medical imaging
Maithra Raghu, Chiyuan Zhang, Jon Kleinberg, and Samy Bengio. Transfusion: Understand- ing transfer learning for medical imaging. In H. Wallach, H. Larochelle, A. Beygelzimer, F. d'Alché-Buc, E. Fox, and R. Garnett, editors,Advances in Neural Information Processing Sys- tems, volume 32. Curran Associates, Inc., 2019. URL https://proceedings.neurips.cc/ pa...
2019
-
[26]
Hashimoto, and Percy Liang
Shiori Sagawa, Pang Wei Koh, Tatsunori B. Hashimoto, and Percy Liang. Distributionally robust neural networks. InInternational Conference on Learning Representations, 2020. URL https://openreview.net/forum?id=ryxGuJrFvS
2020
-
[27]
Fairness and abstraction in sociotechnical systems
Andrew D Selbst, Danah Boyd, Sorelle A Friedler, Suresh Venkatasubramanian, and Janet Vertesi. Fairness and abstraction in sociotechnical systems. InProceedings of the conference on fairness, accountability, and transparency, pages 59–68, 2019
2019
-
[28]
Decline now: A combinatorial model for algorithmic collective action
Dorothee Sigg, Moritz Hardt, and Celestine Mendler-Dünner. Decline now: A combinatorial model for algorithmic collective action. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, CHI ’25. Association for Computing Machinery, 2025. doi: 10.1145/3706598.3713966
-
[29]
Crowding out the noise: Algorithmic collective action under differential privacy
Rushabh Solanki, Meghana Bhange, Ulrich Aïvodji, and Elliot Creager. Crowding out the noise: Algorithmic collective action under differential privacy. InNeurIPS 2025 (Non-archival) Workshop on Algorithmic Collective Action, 2025
2025
-
[30]
California privacy rights act of 2020 (cpra), 2020
State of California. California privacy rights act of 2020 (cpra), 2020. Proposition 24, approved November 3, 2020
2020
-
[31]
(un) informed consent: Studying gdpr consent notices in the field
Christine Utz, Martin Degeling, Sascha Fahl, Florian Schaub, and Thorsten Holz. (un) informed consent: Studying gdpr consent notices in the field. InProceedings of the 2019 acm sigsac conference on computer and communications security, pages 973–990, 2019
2019
-
[32]
Data leverage: A framework for empowering the public in its relationship with technology companies
Nicholas Vincent, Hanlin Li, Nicole Tilly, Stevie Chancellor, and Brent Hecht. Data leverage: A framework for empowering the public in its relationship with technology companies. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, pages 215–227, 2021. 11 A Proofs Proposition 2.1.Under the neutrality assumption P0(z) =P...
2021
-
[33]
We use ε-contamination-suboptimality of ˆmto obtain a pointwise margin condition under ˆPN that guarantees correct prediction at a feature value x∗ whenever a suitable margin inequality holds
-
[34]
We express this margin in terms of the empirical mixture ˆPN by decomposing contributions from each collective, and define the resulting exact empirical marginM c(x∗)
-
[35]
We lower bound Mc(x∗) by a fixed population-based margin M c(x∗) and then compare M c(x∗)to the corrected empirical margin appearing in the theorem statement. 12
-
[36]
We convert the resulting fixed margin condition into a lower bound on the test success probability underP X 0 , using concentration on the test sample
-
[37]
We replace this population probability by the corresponding empirical probability over the pre-edit feature distribution of collective c, again via Hoeffding’s inequality, and then pass pointwise to the corrected empirical margin event
-
[38]
Heat Watch
We combine all concentration events via a union bound and obtain the desired lower bound on ˆSc(αN,c). Throughout the proof, we work conditionally on the realized sample sizes {nN,0, nN,1, . . . , nN,M }, and all probabilities P[·] are with respect to the remaining randomness in the training and test draws. We writeR γ(k) = p log(1/γ)/(2k). Step 1.We firs...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.