Recognition: no theorem link
Advancing Reliable Synthetic Video Detection: Insights from the SAFE Challenge
Pith reviewed 2026-05-11 00:48 UTC · model grok-4.3
The pith
Synthetic video detectors advance across generators but not edits
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
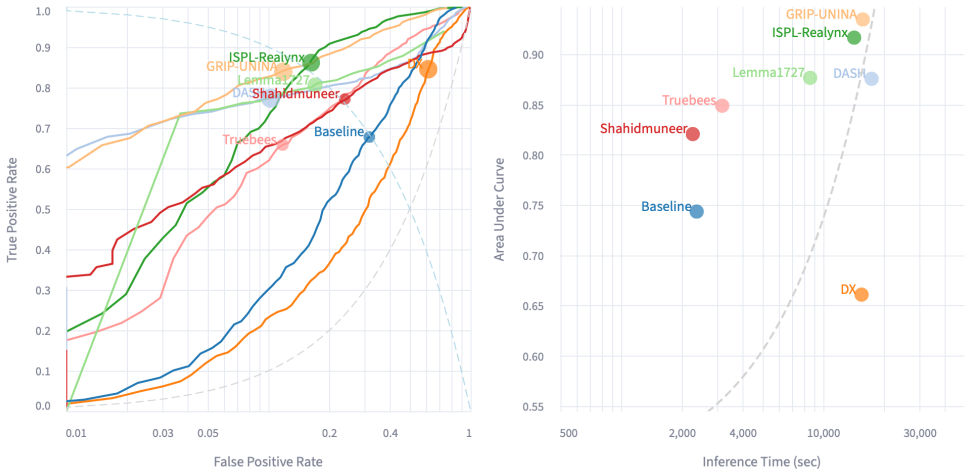
The SAFE challenge demonstrates that contemporary synthetic video detection methods exhibit measurable progress in cross-generator generalization, successfully identifying content produced by diverse state-of-the-art models, while displaying persistent vulnerabilities when the same content is subjected to post-processing operations including resizing, re-compression, motion blur, and similar transformations.
What carries the argument
The two-task challenge design, consisting of synthetic content detection from diverse generators and detection after post-processing, evaluated under fully blind conditions on a matched real-synthetic dataset of 6000 videos.
Load-bearing premise
The challenge dataset and its chosen post-processing operations sufficiently represent the range of real-world conditions that synthetic video detectors will encounter.
What would settle it
A new detector achieving consistently high accuracy on post-processed test videos in an independent evaluation using different operations or additional unseen generators would undermine the reported persistent vulnerabilities.
Figures





read the original abstract
The proliferation of generative video technologies has intensified the need for reliable methods to detect and characterize synthetic media. To address this challenge, we organized the \href{https://safe-video-2025.dsri.org}{SAFE: Synthetic Video Detection Challenge}, co-located with the \textit{Authenticity and Provenance in the Age of Generative AI (APAI) Workshop }at ICCV 2025. The competition invited participants to develop and evaluate algorithms capable of distinguishing real from synthetic videos under fully blind evaluation conditions with over 600 submissions from 12 teams over a 90 day span. Hosted on the Hugging Face platform, the challenge comprised two primary tasks: (1) detection of synthetic video content generated by diverse state-of-the-art models, and (2) detection of synthetic content following common post-processing operations such as resizing, re-compression, motion blur and others. The challenge data consisted of 13 modern high quality synthetic video models with generated content matched to real videos from 21 diverse and challenge sources, all adding up to 20 hours of 6,000 video samples. This paper describes the challenge design, dataset construction, evaluation methodology, and outcomes, offering insights into the generalization and robustness of contemporary synthetic video detection methods. Our findings highlight measurable progress in cross-generator generalization but also persistent vulnerabilities to post-processing artifacts. https://safe-video-2025.dsri.org
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript describes the organization and results of the SAFE: Synthetic Video Detection Challenge co-located with the APAI Workshop at ICCV 2025. It details the challenge design involving two tasks—synthetic video detection and detection under post-processing operations—using a dataset of 6,000 video samples (20 hours) from 13 synthetic generators matched to real videos from 21 sources. With over 600 submissions from 12 teams evaluated blindly on the Hugging Face platform, the paper reports measurable progress in cross-generator generalization while noting persistent vulnerabilities to post-processing artifacts such as resizing, re-compression, and motion blur.
Significance. If the detailed results and analysis support the high-level claims, this work is significant for providing a large-scale blind benchmark that evaluates both generalization across generators and robustness to common post-processing. Such benchmarks are timely for the synthetic media detection community and can inform the development of more reliable detectors. The public challenge platform and dataset scale add practical value beyond a standard methods paper.
major comments (1)
- [Abstract] Abstract: The central claim of 'measurable progress in cross-generator generalization but also persistent vulnerabilities to post-processing artifacts' depends on the post-processing operations (resizing, re-compression, motion blur and others) serving as a valid proxy for real-world conditions. The manuscript provides no external validation, such as statistical comparisons of artifact distributions against platform-collected videos or ablations with stronger real-world transforms, leaving this assumption untested and load-bearing for the robustness conclusions.
minor comments (2)
- [Abstract] Abstract: The phrase '21 diverse and challenge sources' appears to contain a possible typo or unclear phrasing; clarify whether this refers to 'challenging sources' or another intended meaning.
- [Abstract] The abstract summarizes outcomes at a high level but does not include specific metrics, error bars, or statistical analysis; the full results section should provide these to allow verification of the 'measurable progress' claim.
Simulated Author's Rebuttal
Thank you for the constructive feedback on our manuscript describing the SAFE challenge. We have carefully considered the major comment and provide our point-by-point response below. We are prepared to make revisions as outlined.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of 'measurable progress in cross-generator generalization but also persistent vulnerabilities to post-processing artifacts' depends on the post-processing operations (resizing, re-compression, motion blur and others) serving as a valid proxy for real-world conditions. The manuscript provides no external validation, such as statistical comparisons of artifact distributions against platform-collected videos or ablations with stronger real-world transforms, leaving this assumption untested and load-bearing for the robustness conclusions.
Authors: We agree that stronger external validation of the post-processing operations as real-world proxies would enhance the robustness claims. These operations were chosen as they represent frequently encountered manipulations in video distribution pipelines, drawing from prior work in media forensics. Nevertheless, we recognize the absence of direct artifact distribution comparisons or additional ablations. In the revised manuscript, we will update the abstract to avoid overgeneralizing the real-world implications and include a new subsection in the discussion that explicitly discusses the limitations of the chosen post-processing suite and proposes future directions for more comprehensive real-world testing. This revision will be made without altering the core challenge results. revision: partial
Circularity Check
Descriptive challenge report exhibits no circularity
full rationale
The paper is a descriptive summary of an external competition (SAFE challenge) including dataset construction, evaluation methodology, and empirical outcomes from participant submissions. It advances no mathematical derivations, predictions, fitted parameters, or first-principles results that could reduce to inputs by construction. Claims regarding cross-generator generalization and post-processing vulnerabilities are presented as observational findings from the blind evaluation on the provided test set, without self-definitional loops, ansatzes smuggled via citation, or load-bearing self-citations. The analysis remains self-contained against external benchmarks of the competition results themselves.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Rössler, et al., Faceforensics++: Learning to de- tect manipulated facial images, in: Proc
A. Rössler, et al., Faceforensics++: Learning to de- tect manipulated facial images, in: Proc. ICCV, 2019, pp. 1–11
2019
-
[2]
The DeepFake Detection Challenge (DFDC) Dataset
B. Dolhansky, et al., The deepfake detection challenge (dfdc) dataset, arXiv (2020).arXiv:2006.07397
work page internal anchor Pith review arXiv 2020
-
[3]
Jiang, W
L. Jiang, W. Wu, C. C. Li, C. Qian, C. C. Loy, Deeperforensics-1.0: A large-scale dataset for real- world face forgery detection, in: Proc. CVPR, 2020, pp. 2889–2898
2020
-
[4]
Kwon, et al., Kodf: A large-scale korean deepfake detection dataset, in: Proc
P. Kwon, et al., Kodf: A large-scale korean deepfake detection dataset, in: Proc. ICCV, 2021, pp. 10744– 10753
2021
- [5]
- [6]
-
[7]
Yan, et al., Df40: Toward next-generation deepfake detection, in: NeurIPS Datasets and Benchmarks, 2024
Z. Yan, et al., Df40: Toward next-generation deepfake detection, in: NeurIPS Datasets and Benchmarks, 2024
2024
-
[8]
R. Bharadwaj, et al., Vane-bench: Video anomaly evaluation benchmark for conversational lmms, arXiv (2024).arXiv:2406.10326. 10
- [9]
- [10]
-
[11]
F.-A. Croitoru, et al., Mavos-dd: Multilingual audio- video open-set deepfake detection benchmark, arXiv (2025).arXiv:2505.11109
-
[12]
rep., Partnership on AI, accessed 2025 (2020)
Partnership on AI, The deepfake detection challenge: Insights and recommendations for ai and media in- tegrity, Tech. rep., Partnership on AI, accessed 2025 (2020)
2025
-
[13]
URLhttps://huggingface.co/docs/ competitions/en/index
Hugging face competitions (2025). URLhttps://huggingface.co/docs/ competitions/en/index
2025
-
[14]
A. Yang, et al., Qwen3 technical report, arXiv (2025). arXiv:2505.09388
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[15]
Team Wan, et al., Wan: Open and advanced large- scale video generative models, arXiv (2025).arXiv: 2503.20314
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[16]
URLhttps://docs.cloud.google.com/ vertex-ai/generative-ai/docs/models/veo/ 2-0-generate
Veo 2 text+image-to-video generator (2024). URLhttps://docs.cloud.google.com/ vertex-ai/generative-ai/docs/models/veo/ 2-0-generate
2024
-
[17]
URLhttps://platform.pixverse.ai/onboard
Pixverse 4.5 text+image-to-video generator (2025). URLhttps://platform.pixverse.ai/onboard
2025
-
[18]
URLhttps://app.klingai.com/
Kling 2.0 text+image-to-video generator (2025). URLhttps://app.klingai.com/
2025
-
[19]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
W. Kong, et al., Hunyuanvideo: A systematic frame- work for large video generative models, arXiv (2024). arXiv:2412.03603
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[20]
Zhang, et al., Frame context packing and drift pre- vention in next-frame-prediction video diffusion mod- els, in: NeurIPS, 2025
L. Zhang, et al., Frame context packing and drift pre- vention in next-frame-prediction video diffusion mod- els, in: NeurIPS, 2025
2025
- [21]
-
[22]
URLhttps://platform.minimax.io
Minimax video-01 text+image-to-video generator (2024). URLhttps://platform.minimax.io
2024
-
[23]
Seedance 1.0: Exploring the Boundaries of Video Generation Models
Y. Gao, et al., Seedance 1.0: Exploring the bound- aries of video generation models, arXiv (2025). arXiv:2506.09113
work page internal anchor Pith review arXiv 2025
-
[24]
URLhttps://docs.dev.runwayml.com/api/
Runway gen-4.0 turbo text+image-to-video generator (2025). URLhttps://docs.dev.runwayml.com/api/
2025
-
[25]
Tang, et al., The 9th ai city challenge, in: Proc
Z. Tang, et al., The 9th ai city challenge, in: Proc. ICCV Workshops, 2025, pp. 5467–5476
2025
-
[26]
Wang, et al., The 8th ai city challenge, in: Proc
S. Wang, et al., The 8th ai city challenge, in: Proc. CVPR Workshops, 2024, pp. 7261–7272
2024
-
[27]
Wang, et al., Mcblt: Multi-camera multi-object 3d tracking in long videos, arXiv (2024).arXiv:2412
Y. Wang, et al., Mcblt: Multi-camera multi-object 3d tracking in long videos, arXiv (2024).arXiv:2412. 00692
2024
-
[28]
Y. Chen, et al., Hunyuanvideo-avatar: High-fidelity audio-driven human animation for multiple charac- ters, arXiv (2025).arXiv:2505.20156
-
[29]
Available: https://arxiv.org/abs/2506.09042
X. Ren, et al., Cosmos-drive-dreams: Scalable syn- thetic driving data generation with world foundation models, arXiv (2025).arXiv:2506.09042
-
[30]
Qwen-VL: A Versatile Vision-Language Model for Understanding, Localization, Text Reading, and Beyond
J. Bai, et al., Qwen-vl: A versatile vision-language model for understanding, localization, text reading, and beyond, arXiv (2023).arXiv:2308.12966
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[31]
D. S. Vahdati, et al., Beyond deepfake images: De- tecting ai-generated videos, in: CVPRW, 2024, pp. 4397–4408
2024
-
[32]
Corvi, et al., Seeing what matters: Generalizable ai-generated video detection with forensic-oriented augmentation, in: NeurIPS, 2025
R. Corvi, et al., Seeing what matters: Generalizable ai-generated video detection with forensic-oriented augmentation, in: NeurIPS, 2025. Appendix A. Additional Competition Details Additional details about the competition are provided below. 11 Figure A.7: Competition Setup: participants log in with their Hugging Face credentials and provide the submissio...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.