Recognition: 2 theorem links
· Lean TheoremMultiSoc-4D: A Benchmark for Diagnosing Instruction-Induced Label Collapse in Closed-Set LLM Annotation of Bengali Social Media
Pith reviewed 2026-05-11 00:48 UTC · model grok-4.3
The pith
LLMs collapse to fallback labels when annotating Bengali social media, missing most hate and sarcasm.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Instruction-induced label collapse causes LLMs to favor fallback labels such as Other, Neutral, and No during closed-set annotation of Bengali social media, producing failure to detect 79 percent of hateful and 75 percent of sarcastic instances relative to a human-calibrated reference and yielding near-null Fleiss kappa on sarcasm detection.
What carries the argument
Instruction-induced label collapse: the systematic shift by LLMs toward common fallback labels under fixed instruction sets, which suppresses detection of minority categories during annotation.
If this is right
- Resulting datasets will systematically under-represent hate speech and sarcasm relative to their true prevalence.
- Inter-annotator agreement scores among LLMs cannot be trusted as proof of label quality.
- The bias appears in more than forty models and does not depend on specific architecture or family.
- New diagnostic benchmarks are needed to detect and mitigate label collapse before LLM annotations are used for training data.
Where Pith is reading between the lines
- The same preference for safe labels is likely to appear when LLMs annotate social media in other low-resource languages.
- Models trained on the resulting datasets may show reduced ability to recognize hate and sarcasm in practice.
- Switching to open-ended prompts or combining multiple models could recover some of the missed minority labels.
- The effect may interact with the specific choice of Bengali social media sources and could be tested on parallel datasets from other platforms.
Load-bearing premise
Human annotations on the shared 20 percent validation set accurately reflect true label distributions without distortion from the guidelines or data sources.
What would settle it
A new round of human annotations on the validation set that shows LLM detection rates for hate and sarcasm matching or exceeding the original reference rates would falsify the collapse diagnosis.
Figures









read the original abstract
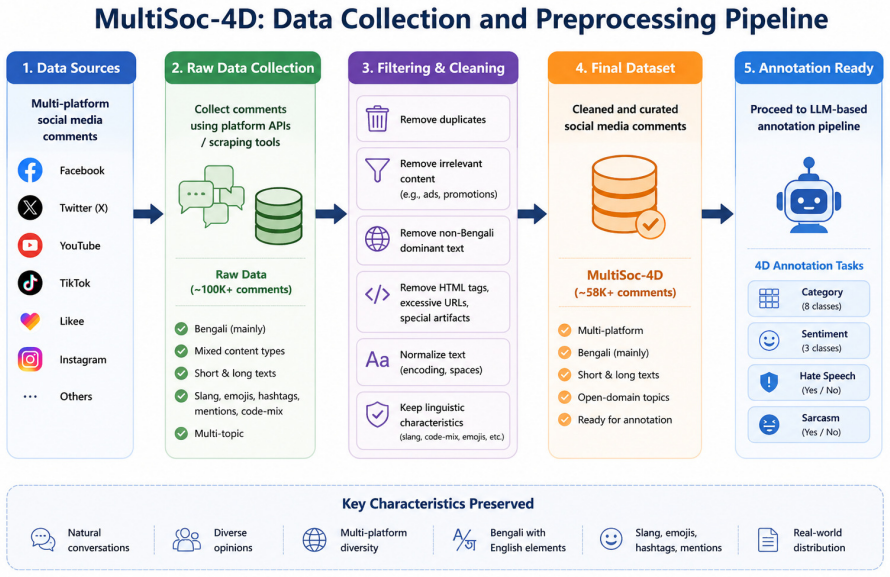
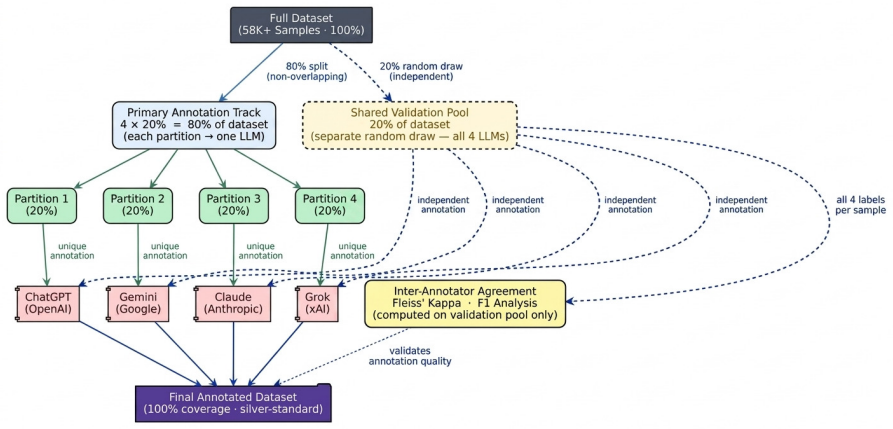
Annotation automation via Large Language Models (LLMs) is the core approach for scaling NLP datasets; however, LLM behavior with respect to closed-set instructions in low-resource languages has not been well studied. We present MultiSoc-4D, a Bengali social media dataset benchmark, which contains 58K+ social media comments from six sources annotated along four dimensions: category, sentiment, hate speech, and sarcasm. By employing a structured pipeline where ChatGPT, Gemini, Claude, and Grok individually annotate separate partitions, while sharing a common validation set of 20%, we diagnose LLM behavior systematically. We discover a prevalent phenomenon called "instruction-induced label collapse", wherein LLMs show a systematic preference towards fallback labels (Other, Neutral, No), leading to high agreement rates but under-detection of minority categories. For example, we find that LLMs failed to detect 79% and 75% of instances with hateful and sarcastic content compared to a human-calibrated reference. Furthermore, we prove that it represents a "label agreement illusion", statistically validated via almost null Fleiss' Kappa ($\kappa \approx -0.001$) on sarcasm detection. Across 40+ LLMs, we benchmark this annotation bias propagation within the training pipeline, regardless of architectural differences. We release MultiSoc-4D as a diagnostic benchmark for annotation biases in Bengali NLP.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MultiSoc-4D, a benchmark of 58K+ Bengali social media comments from six sources, annotated along four dimensions (category, sentiment, hate speech, sarcasm). LLMs (ChatGPT, Gemini, Claude, Grok and 40+ others) annotate separate partitions while sharing a 20% human-calibrated validation set; the work diagnoses 'instruction-induced label collapse' in which LLMs systematically favor fallback labels (Other/Neutral/No), under-detecting minority classes (79% and 75% failure rates on hateful and sarcastic content vs. the human reference) and producing a 'label agreement illusion' (Fleiss' κ ≈ -0.001 on sarcasm). The dataset is released as a diagnostic tool for annotation biases in low-resource LLM pipelines.
Significance. If the human reference is shown to be reliable, the empirical demonstration of label collapse across many LLMs, the concrete failure percentages, and the near-zero kappa statistic would constitute a useful contribution to understanding LLM annotation behavior in low-resource languages. The release of a multi-dimensional, multi-source Bengali dataset with a shared validation partition provides a concrete resource for future work on annotation bias.
major comments (3)
- [Human annotation and validation-set construction] The headline quantitative claims (79% and 75% under-detection of hateful/sarcastic content, plus the label-collapse diagnosis) rest entirely on comparison to the 'human-calibrated reference' on the shared 20% validation set. No inter-annotator agreement statistics for the human annotators, excerpts from the annotation guidelines for Bengali sarcasm/hate, or description of the calibration procedure are provided. Without these, it is impossible to rule out that human annotators themselves default to Neutral/No/Other on ambiguous cases, which would confound attribution of the observed rates to instruction-induced LLM collapse rather than reference noise.
- [Statistical validation of label agreement illusion] The claim that the near-zero Fleiss' Kappa (κ ≈ -0.001) on sarcasm detection 'proves' a label agreement illusion is load-bearing for the central diagnosis. The manuscript does not specify the exact label mapping, number of annotators per instance, or how the kappa is computed across LLM outputs and the human reference; without these details the statistic cannot be interpreted as evidence of collapse versus simple label imbalance or disagreement on the minority class.
- [Annotation pipeline and data partitioning] The pipeline description states that LLMs annotate separate partitions while sharing the 20% validation set, yet no information is given on how the partitions were sampled or whether stratification by source or label distribution was performed. This affects whether the reported collapse rates can be generalized beyond the particular validation slice.
minor comments (2)
- [Abstract] The abstract uses the verb 'prove' for the kappa result; this is an empirical observation rather than a formal proof and should be rephrased to 'demonstrate' or 'show'.
- [Related work] The manuscript would benefit from explicit comparison to prior studies of LLM annotation bias in other low-resource languages to situate the Bengali-specific findings.
Simulated Author's Rebuttal
We thank the referee for their constructive and detailed feedback. We address each major comment point by point below. Where details were missing, we have revised the manuscript to include them, strengthening the transparency and interpretability of our claims.
read point-by-point responses
-
Referee: [Human annotation and validation-set construction] The headline quantitative claims (79% and 75% under-detection of hateful/sarcastic content, plus the label-collapse diagnosis) rest entirely on comparison to the 'human-calibrated reference' on the shared 20% validation set. No inter-annotator agreement statistics for the human annotators, excerpts from the annotation guidelines for Bengali sarcasm/hate, or description of the calibration procedure are provided. Without these, it is impossible to rule out that human annotators themselves default to Neutral/No/Other on ambiguous cases, which would confound attribution of the observed rates to instruction-induced LLM collapse rather than reference noise.
Authors: We agree that these details are necessary to validate the human reference and rule out reference noise. In the revised manuscript we now report inter-annotator agreement statistics (Fleiss' κ per dimension on the validation set), provide targeted excerpts from the annotation guidelines addressing Bengali sarcasm and hate-speech cues, and describe the multi-round calibration procedure (initial independent annotation followed by adjudication meetings). These additions show that human annotators did not systematically default to fallback labels, supporting attribution of the observed collapse to the LLMs. revision: yes
-
Referee: [Statistical validation of label agreement illusion] The claim that the near-zero Fleiss' Kappa (κ ≈ -0.001) on sarcasm detection 'proves' a label agreement illusion is load-bearing for the central diagnosis. The manuscript does not specify the exact label mapping, number of annotators per instance, or how the kappa is computed across LLM outputs and the human reference; without these details the statistic cannot be interpreted as evidence of collapse versus simple label imbalance or disagreement on the minority class.
Authors: We acknowledge the need for full transparency on the statistic. The revised text now specifies the binary label mapping (Yes/No for sarcasm, with collapse to No), confirms that kappa was computed across all 40+ LLM outputs plus the human reference on every validation instance, and provides the exact multi-rater Fleiss' formula and implementation details. This clarifies that the near-zero value arises from systematic majority-label agreement rather than balanced disagreement or simple imbalance. revision: yes
-
Referee: [Annotation pipeline and data partitioning] The pipeline description states that LLMs annotate separate partitions while sharing the 20% validation set, yet no information is given on how the partitions were sampled or whether stratification by source or label distribution was performed. This affects whether the reported collapse rates can be generalized beyond the particular validation slice.
Authors: We thank the referee for noting this gap. The revised manuscript now details that the full 58K+ comments were obtained via stratified random sampling across the six sources to preserve source proportions, and that the 20% validation set was further stratified by both source and preliminary label distributions from a pilot annotation. These procedures support generalization of the collapse rates beyond the validation slice. revision: yes
Circularity Check
No circularity: claims rest on direct empirical comparison to held-out human reference
full rationale
The paper presents an empirical benchmark: LLMs annotate partitions of the MultiSoc-4D dataset while sharing a 20% human-calibrated validation set; failure rates (79% and 75% under-detection of hateful/sarcastic content) and Fleiss' Kappa (≈ -0.001) are computed directly from these outputs versus the reference. No equations, fitted parameters, or derivations are claimed; no self-citations are invoked as load-bearing uniqueness theorems or ansatzes; the label-collapse diagnosis is a statistical observation on the observed label distributions, not a tautological renaming or self-definition. The central results remain falsifiable against external human annotations and do not reduce to their inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Human annotations on the shared validation set serve as an accurate and unbiased ground truth for measuring LLM performance.
invented entities (1)
-
instruction-induced label collapse
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We discover a prevalent phenomenon called 'instruction-induced label collapse', wherein LLMs show a systematic preference towards fallback labels (Other, Neutral, No), leading to high agreement rates but under-detection of minority categories... Fleiss' Kappa (κ ≈ -0.001) on sarcasm detection.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat induction and recovery unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
MultiSoc-4D... 58K+ social media comments... annotated along four dimensions... Bias Ratio = LLM Label Frequency (Avg.) / Human Label Frequency.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Nuner: Entity recognition encoder pre- training via llm-annotated data . Preprint, arXiv:2402.15343. Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhari- wal, and 1 others. 2020. Language models are few-shot learners . Advances in Neural Informa- tion Processing Systems , 33. Juhwan Choi, Jungmin Yun, Kyohoon Jin, and Yo...
-
[2]
Cost-aware llm-based online dataset an- notation. Preprint, arXiv:2505.15101. Fabrizio Gilardi, Meysam Alizadeh, and Maël Kubli. 2023. Chatgpt outperforms crowd work- ers for text-annotation tasks . Proceedings of the National Academy of Sciences , 120(30). Fabiha Haider, Fariha Tanjim Shifat, Md Farhan Ishmam, Md Sakib Ul Rahman Sourove, Deeparghya Dutta...
-
[3]
In Findings of the Association for Computational Linguistics: ACL 2023 , Toronto, Canada
BanglaBook: A large-scale Bangla dataset for sentiment analysis from book reviews . In Findings of the Association for Computational Linguistics: ACL 2023 , Toronto, Canada. Asso- ciation for Computational Linguistics. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, and 1 others
2023
-
[4]
Advances in Neural Information Processing Systems , 35
Training language models to follow in- structions with human feedback . Advances in Neural Information Processing Systems , 35. Bidyarthi Paul, SM Musfiqur Rahman, Dipta Biswas, Md. Ziaul Hasan, and Md. Zahid Hos- sain. 2025. Analyzing emotions in bangla so- cial media comments using machine learning and lime. Preprint, arXiv:2506.10154. Faisal Hossain Ra...
-
[5]
Gemini: A Family of Highly Capable Multimodal Models
Data-augmentation for bangla-english code-mixed sentiment analysis: Enhancing cross linguistic contextual understanding . IEEE Ac- cess, 11:51657–51671. Gemini Team, Rohan Anil, Sebastian Borgeaud, Yonghui Wu, and 1 others. 2023. Gemini: A family of highly capable multimodal models . arXiv preprint arXiv:2312.11805 . Qwen Team, An Yang, Baosong Yang, Beic...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
Default Assignment (Confusion Rule): In cases of high ambiguity or lack of context, annotators must default to: Other, Neutral, No, No
-
[7]
Linguistic Nuance: Criticism of an idea is labeled as Hateful: No , whereas attacks on identity or personhood are labeled as Hateful: Y es
-
[8]
আমার লাভ লস নাই,, আমার জীবনটায় লস
Sarcasm Identification: Sarcasm is only labeled Y esif the intended meaning is the opposite of the literal text (irony). Annotation Prompt LLM Annotation Prompt Role: Act as a data annotator specializing in Bengali text classifier. Input: You are provided with: • A CSV file containing user comments. • An instruction document (Instruc- tion.docx) defining ...
-
[9]
Instruction-Tuned Large Language Mod- els
-
[10]
Multi-Lingual Tranformers (LLM)
-
[11]
Mono-Lingual Transformers (LLM)
-
[12]
For transformer based mono and multi-lingual models performance are pre- sented in Table 13
Traditional Machine Learning Model The performance benchmark of the instruction-tuned llms are shown in the Table 11. For transformer based mono and multi-lingual models performance are pre- sented in Table 13. And the Table 12 shows the benchmarking of traditional machine learning models. E Results Visualization Figure 12: Comparative Radar Charts illust...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.