Recognition: 2 theorem links
· Lean TheoremPLOT: Progressive Localization via Optimal Transport in Neural Causal Abstraction
Pith reviewed 2026-05-11 00:57 UTC · model grok-4.3
The pith
Optimal transport couplings between intervention effects localize causal variables in neural networks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
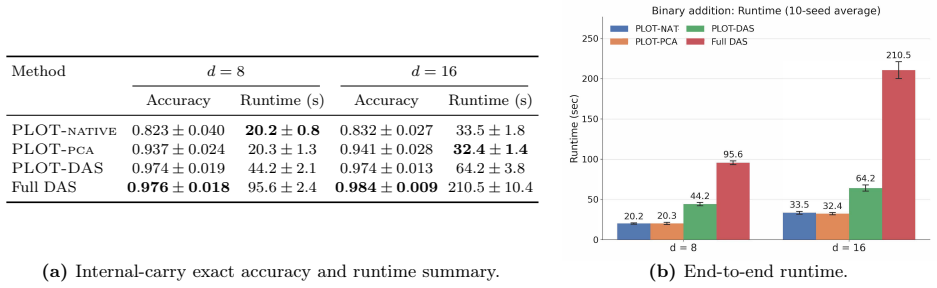
PLOT fits an optimal transport coupling between abstract variables and candidate neural sites based on the geometry of their intervention output effects, yielding a global soft correspondence that identifies the neural handles for causal variables and supports progressive refinement or guidance of other methods.
What carries the argument
Optimal transport coupling over intervention output geometries, which establishes soft alignments between abstract causal variables and neural sites.
If this is right
- In simple cases a single coupling over neurons gives accurate handles quickly.
- When guiding DAS, it reaches similar accuracy with much less computation.
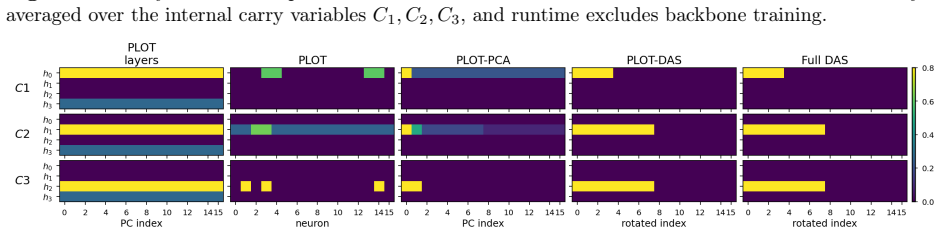
- Progressive localization from tokens or layers down to finer spans makes the approach work on larger networks.
- It offers a scalable way to perform causal abstraction analysis.
Where Pith is reading between the lines
- The same transport idea could apply to aligning other kinds of high-level descriptions with network internals beyond causal models.
- If it works reliably, researchers might use it to check proposed causal structures against actual network behavior more routinely.
- It might inspire hybrid methods that combine transport with other alignment techniques for even better efficiency.
Load-bearing premise
That the geometry of output effects from abstract and neural interventions admits a meaningful optimal transport coupling corresponding to true causal variable alignments.
What would settle it
A test case with known correct neural sites where the transport coupling selects different sites and intervening there does not match the abstract model's counterfactual predictions.
Figures





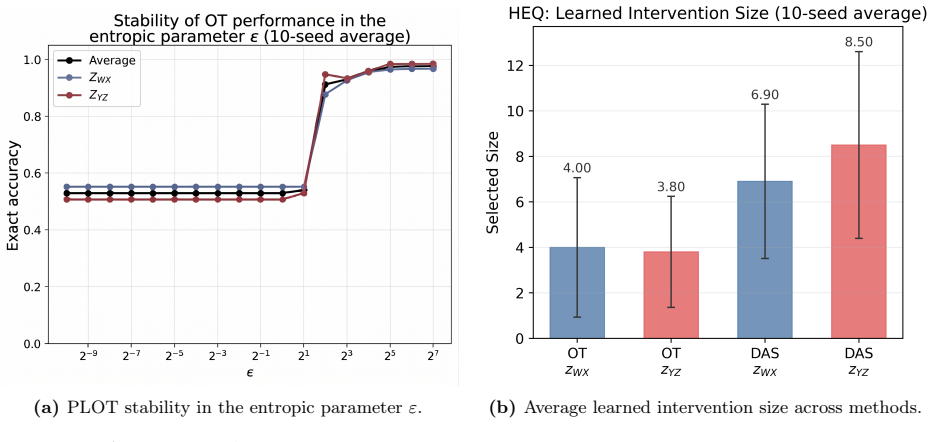
read the original abstract
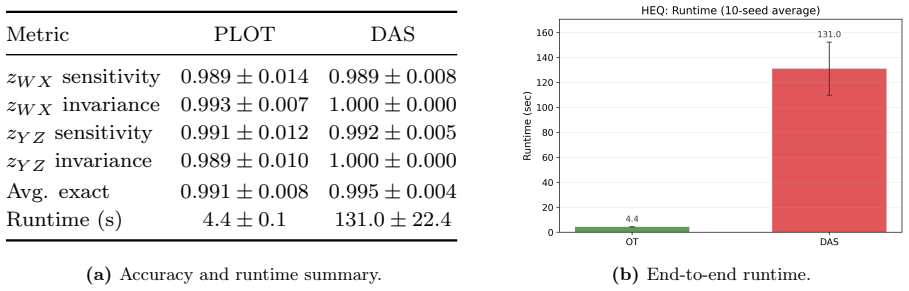
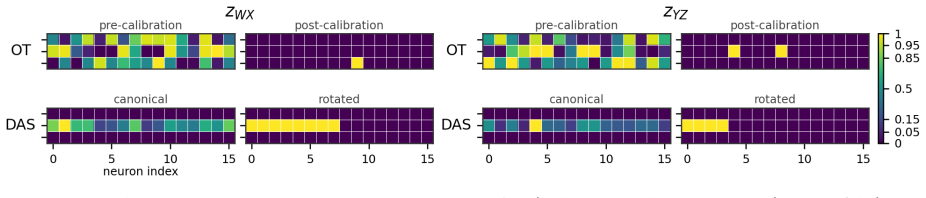
Causal abstraction offers a principled framework for mechanistic interpretability, aligning a high-level causal model with the low-level computation realized by a neural network through counterfactual intervention analysis. Existing methods such as distributed alignment search (DAS) learn expressive subspace interventions, but the relevant neural site is unknown a priori, so finding a handle requires a computationally burdensome search over candidate sites. We introduce PLOT (Progressive Localization via Optimal Transport), a transport-based framework that localizes causal variables from the output effect geometry of abstract and neural interventions. PLOT fits an optimal transport coupling between abstract variables and candidate neural sites, yielding a global soft correspondence that can be calibrated into intervention handles. In simple settings, a single coupling over individual neurons suffices. In larger models, PLOT is applied progressively, moving from coarse sites such as tokens, timesteps, or layers to finer supports such as coordinate groups or PCA spans, and optionally guiding DAS based on the localized signal. Across experiments of increasing complexity, transport-only PLOT handles are exceedingly fast and competitive on accuracy, while PLOT-guided DAS reaches DAS-level accuracy at a fraction of full DAS runtime, providing an efficient localization engine for causal abstraction research at scale.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces PLOT (Progressive Localization via Optimal Transport), a framework for localizing causal variables in neural networks by fitting optimal transport couplings between abstract variables and candidate neural sites based on the geometry of their intervention effects. It describes a progressive coarse-to-fine application from tokens/layers to finer supports and optional guidance for DAS, reporting that transport-only PLOT is fast and competitive in accuracy while PLOT-guided DAS achieves DAS-level performance at reduced runtime across experiments of increasing complexity.
Significance. If the OT-based couplings reliably recover true causal alignments rather than spurious effect matches, PLOT could provide a scalable localization engine that reduces the search burden in causal abstraction methods, enabling mechanistic interpretability at larger scales. The progressive schedule and DAS integration are practical strengths, but significance hinges on validation that effect-geometry transport corresponds to interchange-intervention equivalence.
major comments (2)
- [Section 4] Section 4 (Experiments): the reported competitive accuracy on experiments of increasing complexity does not specify whether the metric is strict interchange-intervention equivalence (IIE) with the high-level model or a proxy based solely on output-effect matching. This distinction is load-bearing for the central claim, as the OT coupling is constructed precisely to minimize effect-geometry distance and could succeed on proxies without ensuring causal fidelity when multiple sites induce similar perturbations.
- [Section 3.2] Section 3.2 (Progressive Localization): the coarse-to-fine schedule is presented without analysis or safeguards against early incorrect soft alignments propagating to finer supports (e.g., coordinate groups or PCA spans). If an initial token- or layer-level coupling selects a spurious site due to similar intervention effects, the subsequent refinement cannot recover the true causal variable.
minor comments (2)
- [Abstract] Abstract: the claim that 'transport-only PLOT handles are exceedingly fast' lacks quantitative runtime tables or speedup factors relative to exhaustive DAS search, reducing clarity on the efficiency contribution.
- [Method] Notation throughout: the cost function used for the OT plan (distance between effect vectors or distributions) is not explicitly defined with an equation, making it difficult to assess uniqueness or robustness to distributed representations.
Simulated Author's Rebuttal
We thank the referee for the careful reading and insightful comments, which help clarify the presentation of our results and the robustness of the progressive localization procedure. We address each major comment below and indicate the corresponding revisions.
read point-by-point responses
-
Referee: [Section 4] Section 4 (Experiments): the reported competitive accuracy on experiments of increasing complexity does not specify whether the metric is strict interchange-intervention equivalence (IIE) with the high-level model or a proxy based solely on output-effect matching. This distinction is load-bearing for the central claim, as the OT coupling is constructed precisely to minimize effect-geometry distance and could succeed on proxies without ensuring causal fidelity when multiple sites induce similar perturbations.
Authors: We agree that this distinction is important. The accuracy numbers reported in Section 4 are computed using the standard interchange-intervention accuracy metric from the causal abstraction literature (i.e., the fraction of test inputs on which the low-level model with the learned intervention matches the high-level model under interchange interventions). This is the same metric used to evaluate DAS and is directly tied to IIE rather than a pure output-effect proxy. Nevertheless, to make the evaluation fully transparent and to address the referee’s concern about possible spurious effect matches, we will add an explicit statement of the metric in Section 4, include a short derivation showing why the OT objective is consistent with IIE under the linear-intervention assumption used in our experiments, and report an additional column of strict IIE success rates (exact match on all counterfactuals) for the main tables. These changes will appear in the revised manuscript. revision: yes
-
Referee: [Section 3.2] Section 3.2 (Progressive Localization): the coarse-to-fine schedule is presented without analysis or safeguards against early incorrect soft alignments propagating to finer supports (e.g., coordinate groups or PCA spans). If an initial token- or layer-level coupling selects a spurious site due to similar intervention effects, the subsequent refinement cannot recover the true causal variable.
Authors: This is a valid concern. The current manuscript presents the progressive schedule as a practical heuristic without a formal analysis of error propagation. In practice, the coarse-stage couplings are stable because intervention-effect geometries are more separable at the token/layer level, and the soft OT plan retains probability mass on multiple candidates that are then refined. To strengthen the paper, we will (i) add a paragraph in Section 3.2 discussing the conditions under which early-stage errors are unlikely (distinct effect geometries at coarse scales), (ii) include a small ablation that measures alignment stability across stages on the synthetic tasks, and (iii) describe an optional safeguard—retaining the top-k soft assignments from the coarse stage for parallel refinement at the fine stage. These additions will be incorporated in the revision. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper defines PLOT as a new transport-based localization procedure that computes an optimal transport coupling on intervention effect geometries and optionally guides DAS. This is a constructive definition of a method rather than a claim that reduces by construction to its inputs. No load-bearing steps invoke self-citations, fitted parameters renamed as predictions, or uniqueness theorems from prior author work. Empirical accuracy claims are presented as experimental outcomes on held-out or increasing-complexity tasks, not as tautological consequences of the fitting procedure itself. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Intervention effect geometries can be meaningfully coupled via optimal transport to recover causal variable locations
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearPLOT fits an optimal transport coupling between abstract variables and candidate neural sites, yielding a global soft correspondence that can be calibrated into intervention handles.
-
IndisputableMonolith/Foundation/BranchSelection.leanbranch_selection unclearWe use the squared Euclidean cost c(x, y) = ∥x−y∥²
Reference graph
Works this paper leans on
-
[1]
URL https://doi.org/10.1016/j.spa.2019.08.009
doi: 10.1016/j.spa.2019.08.009. URL https://doi.org/10.1016/j.spa.2019.08.009. T. Bricken, A. Templeton, J. Batson, B. Chen, A. Jermyn, T. Conerly, N. Turner, C. Anil, C. Denison, A. Askell, R. Lasenby, Y. Wu, S. Kravec, N. Schiefer, T. Maxwell, N. Joseph, Z. Hatfield-Dodds, A. Tamkin, K. Nguyen, B. McLean, J. E. Burke, T. Hume, S. Carter, T. Henighan, an...
-
[2]
Maheep Chaudhary and Atticus Geiger
URLhttps://transformer-circuits.pub/2023/monosemantic-features/ index.html. Maheep Chaudhary and Atticus Geiger. Evaluating open-source sparse autoencoders on disentangling factual knowledge in GPT-2 small.CoRR, abs/2409.04478,
-
[3]
Maheep Chaudhary and Atticus Geiger
doi: 10.48550/arXiv.2409.04478. URLhttps://arxiv.org/abs/2409.04478. Patrick Cheridito and Stephan Eckstein. Optimal transport and Wasserstein distances for causal models.Bernoulli, 31(2):1351–1376,
-
[4]
doi: 10.3150/24-BEJ1773. URLhttps://doi.org/10. 3150/24-BEJ1773. Lénaïc Chizat, Gabriel Peyré, Bernhard Schmitzer, and François-Xavier Vialard. Scaling algorithms for unbalanced transport problems.Mathematics of Computation, 87(314):2563–2609,
-
[5]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
Hoagy Cunningham, Aidan Ewart, Logan Riggs Smith, Robert Huben, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models.CoRR, abs/2309.08600,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Sparse Autoencoders Find Highly Interpretable Features in Language Models
doi: 10.48550/arXiv.2309.08600. URLhttps://arxiv.org/abs/2309.08600. Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transport. InAdvances in Neural Information Processing Systems, volume 26,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2309.08600
-
[7]
Gemma 2: Improving Open Language Models at a Practical Size
Gemma Team. Gemma 2: Improving open language models at a practical size.CoRR, abs/2408.00118,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Gemma 2: Improving Open Language Models at a Practical Size
doi: 10.48550/arXiv.2408.00118. URLhttps://arxiv.org/abs/2408.00118. Robert Huben, Hoagy Cunningham, Logan Riggs Smith, Aidan Ewart, and Lee Sharkey. Sparse autoencoders find highly interpretable features in language models. InThe Twelfth Interna- tional Conference on Learning Representations,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2408.00118
-
[10]
Adam: A Method for Stochastic Optimization
URLhttps://arxiv.org/abs/1412.6980. Rémi Lassalle. Causal transport plans and their Monge–Kantorovich problems.Stochastic Analysis and Applications, 36(3):452–484,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
doi: 10.1080/07362994.2017.1422747. URLhttps://doi. org/10.1080/07362994.2017.1422747. Samuel Marks and Max Tegmark. The geometry of truth: Emergent linear structure in large language model representations of true/false datasets. InFirst Conference on Language Modeling,
-
[12]
Interpretability analysis of arithmetic in-context learning in large language models
Gregory Polyakov, Christian Hepting, Carsten Eickhoff, and Seyed Ali Bahrainian. Interpretability analysis of arithmetic in-context learning in large language models. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 1758–1777,
2025
-
[13]
URLhttps://aclanthology.org/2025.emnlp-main.92/
doi: 10.18653/v1/2025.emnlp-main.92. URLhttps://aclanthology.org/2025.emnlp-main.92/. Jiuding Sun, Jing Huang, Sidharth Baskaran, Karel D’Oosterlinck, Christopher Potts, Michael Sklar, and Atticus Geiger. HyperDAS: Towards automating mechanistic interpretability with hypernetworks.CoRR, abs/2503.10894,
-
[14]
Curt Tigges, Oskar John Hollinsworth, Atticus Geiger, and Neel Nanda
URLhttps://arxiv.org/abs/2503.10894. Curt Tigges, Oskar John Hollinsworth, Atticus Geiger, and Neel Nanda. Linear representations of sentiment in large language models.CoRR, abs/2310.15154,
-
[15]
doi: 10.48550/arXiv.2310.15154. URLhttps://arxiv.org/abs/2310.15154. Dor Tsur and Ziv Goldfeld. Neural entropic multi-marginal optimal transport and Gromov– Wasserstein alignment.CoRR, abs/2506.00573,
-
[16]
URL https://arxiv.org/abs/2506.00573
doi: 10.48550/arXiv.2506.00573. URL https://arxiv.org/abs/2506.00573. 13 Cédric Villani.Topics in optimal transportation, volume 58 ofGraduate Studies in Mathematics. American Mathematical Society,
-
[17]
URLhttps: //doi.org/10.1109/TIT.2026.3661439
doi: 10.1109/TIT.2026.3661439. URLhttps: //doi.org/10.1109/TIT.2026.3661439. Early access. Zhengxuan Wu, Atticus Geiger, Thomas Icard, Christopher Potts, and Noah D. Goodman. Inter- pretability at scale: Identifying causal mechanisms in Alpaca.CoRR, abs/2305.08809,
-
[18]
URL https://arxiv.org/abs/2305.08809. 14 Appendix A Additional Methodology Details We evaluate learned handles by interchange-intervention accuracy (Geiger et al., 2024). For a handle associated withZ i, calibration accuracy is Lcal(Zi) := 1 Tcal TcalX t=1 1n ynn_swap Π,i (xb t ,xs t)=yabs_swap i (xb t ,xs t) o, with test accuracy defined analogously onDt...
-
[19]
Indeed, a method that learns no handle can score perfectly on invariance-heavy test sets, yielding high average accuracy while being weak on sensitivity
which mixed sensitive and invariant pairs, leading to test accuracies that are less interpretable. Indeed, a method that learns no handle can score perfectly on invariance-heavy test sets, yielding high average accuracy while being weak on sensitivity. Unless stated otherwise, main-text accuracies average over all2m sensitive and invariant test sets, two ...
2017
-
[20]
to obtainℓ AP andℓ AT 3:forZ∈ {AP,AT}do 4:fork∈ {32,64,96,128,256,512,768,1024,1536,2048,2304}do 5:Train a DAS rotation forZonD ft at layerℓ Z with subspace intervention sizek 6:Evaluate the rotation handle forZonD cal 7:end for 8:Evaluate the best calibrated rotation forZonD te 9:end for 10:End timer and reportPLOT-DASruntime Algorithm 10MCQAPLOT-native-...
2048
-
[21]
to obtainℓ AP,ℓ AT,R AP,R AT,H pca AP,H pca AT 3:forZ∈ {AP,AT}do 4:Extractb ⋆ andK ⋆ fromH pca Z 5:Set effective dimensione:=⌊rank(R Z)/b⋆⌋K ⋆ 6:fork∈ {0.5e,0.75e, e,1.5e,2.0e}do 7:Train a DAS rotation on top ofR Z forZonD ft (DAS rotation has sizeRk×rank(RZ )) 8:Evaluate the rotation forZonD cal 9:end for 10:Evaluate the best calibrated rotation forZonD ...
2048
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.