Recognition: no theorem link
SmellBench: Evaluating LLM Agents on Architectural Code Smell Repair
Pith reviewed 2026-05-13 05:55 UTC · model grok-4.3
The pith
LLM agents repair under half of architectural code smells while often introducing new ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
LLM agents excel at localized code transformations yet lack the cross-module architectural understanding needed for reliable smell repair. When run on expert-validated smells from scikit-learn, the strongest configuration resolves 47.7 percent of issues and reaches expert-level agreement on false-positive identification, but more aggressive agents add up to 140 new smells, producing an inverse relationship between repair volume and net codebase quality. SmellBench supplies the orchestration, prompt templates, and multi-metric scoring that make this gap measurable and trackable.
What carries the argument
SmellBench, a task orchestration framework that applies smell-type-specific prompts, supports iterative multi-step execution, and scores agents on repair effectiveness, false-positive identification, and net codebase impact.
If this is right
- Automated refactoring tools will remain limited to local edits until models acquire better cross-file design reasoning.
- Benchmarks must separately measure false-positive rejection and net quality change, because raw repair counts can mislead.
- Progress on architectural smells will require new training signals that emphasize multi-module dependencies rather than single-file edits.
- Software teams using current agents for smell repair will still need human oversight to avoid quality regressions.
Where Pith is reading between the lines
- Extending the benchmark to other languages or larger projects could reveal whether the observed gap is language-specific or general.
- If agents improve on this task, they could eventually support continuous architectural maintenance in large codebases without manual intervention.
- The inverse relationship between aggressiveness and quality suggests training objectives should penalize smell creation, not just reward smell removal.
Load-bearing premise
The sixty-five smells found by the detector in one large Python project, once filtered by expert review, form a representative sample of the architectural repair problem that agents must solve.
What would settle it
A new agent configuration that consistently repairs every validated smell while leaving the total smell count unchanged or lower would falsify the claimed gap in cross-module capability.
Figures


read the original abstract
Architectural code smells erode software maintainability and are costly to repair manually, yet unlike localized bugs, they require cross-module reasoning about design intent that challenges both developers and automated tools. While large language model agents excel at bug fixing and code-level refactoring, their ability to repair architectural code smells remains unexplored. We present the first empirical evaluation of LLM agents on architectural code smell repair. We contribute SmellBench, a task orchestration framework that incorporates smell-type-specific optimized prompts and supports iterative multi-step execution, together with a scoring methodology that separately evaluates repair effectiveness, false positive identification, and net codebase impact. We evaluate 11 agent configurations from four model families (GPT, Claude, Gemini, Mistral) on 65 hard-severity architectural smells detected by PyExamine in the Python project scikit-learn, validated against expert judgments. Expert validation reveals that 63.1% of detected smells are false positives, while the best agent achieves a 47.7% resolution rate. Agents identify false positives with up to $\kappa = 0.94$ expert agreement, but repair aggressiveness and net codebase quality are inversely related: the most aggressive agent introduces 140 new smells. These findings expose a gap between current LLM capabilities in localized code transformations and the architectural understanding needed for cross-module refactoring. SmellBench provides reusable infrastructure for tracking progress on this underexplored dimension of automated software engineering. We release our code and data at https://doi.org/10.5281/zenodo.19247588.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SmellBench, a task orchestration framework for evaluating LLM agents on repairing architectural code smells. It evaluates 11 agent configurations across four model families on 65 hard-severity smells detected by PyExamine in scikit-learn (expert-validated), reporting a best resolution rate of 47.7%, expert agreement on false-positive identification up to κ=0.94, 63.1% false positives among detections, and an inverse relationship between repair aggressiveness and net codebase quality (most aggressive agent introduces 140 new smells). The central claim is that these results expose a gap between current LLM capabilities in localized code transformations and the cross-module architectural reasoning needed for genuine smell repair; the framework and data are released for future benchmarking.
Significance. If the evaluation methodology holds, the work is significant as the first empirical benchmark specifically targeting architectural (as opposed to localized) code smells for LLM agents. It supplies reusable infrastructure, released code/data, and concrete metrics that can track progress on an underexplored dimension of automated software engineering. The separation of repair effectiveness, false-positive identification, and net impact is a useful design choice, and the expert validation step strengthens the test set.
major comments (3)
- [abstract and scoring methodology (§3–4)] Scoring methodology (abstract and §3–4): The claim that the 47.7% resolution rate demonstrates a deficit in cross-module architectural reasoning depends on whether repair success is defined by independent expert judgment that the edit preserves or improves design intent across modules, or by the narrower criterion of the original PyExamine flag disappearing. The abstract states that the scoring “separately evaluates repair effectiveness” but does not specify an expert-judged architectural criterion; if effectiveness reduces to re-detection, localized edits that evade the detector without addressing architectural issues would suffice to produce the reported numbers.
- [§2 and §4] Test-set construction (§2 and §4): The 65 smells are described as “hard-severity” and “validated against expert judgments,” yet the paper does not report the precise exclusion rules, inter-expert agreement on smell validity, or sampling procedure used to ensure the set is representative rather than biased toward smells that PyExamine flags reliably. This directly affects the generalizability of the gap claim.
- [results section] Net-impact measurement (results): The finding that the most aggressive agent introduces 140 new smells is load-bearing for the aggressiveness–quality tradeoff. The paper should clarify whether “new smells” are counted only by PyExamine re-scan or also by expert review of whether the introduced issues are architecturally meaningful; without the latter, the metric risks conflating detector noise with genuine degradation.
minor comments (3)
- [abstract] The abstract reports “140 new smells” without stating whether this is an absolute count or normalized by lines of code or number of edits; a normalized figure would aid interpretation.
- [results] Table or figure presenting per-agent resolution rates, false-positive identification rates, and net smell change should be added or clarified if already present, with explicit formulas for each metric.
- [§3] The prompt templates and iteration limits for the 11 configurations are mentioned but not reproduced in sufficient detail for replication; the released repository should be cross-referenced explicitly in the text.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped clarify key aspects of our methodology and results presentation. We address each major comment below and have revised the manuscript to improve transparency without altering the core findings or data.
read point-by-point responses
-
Referee: [abstract and scoring methodology (§3–4)] Scoring methodology (abstract and §3–4): The claim that the 47.7% resolution rate demonstrates a deficit in cross-module architectural reasoning depends on whether repair success is defined by independent expert judgment that the edit preserves or improves design intent across modules, or by the narrower criterion of the original PyExamine flag disappearing. The abstract states that the scoring “separately evaluates repair effectiveness” but does not specify an expert-judged architectural criterion; if effectiveness reduces to re-detection, localized edits that evade the detector without addressing architectural issues would suffice to produce the reported numbers.
Authors: We appreciate this observation and agree that the abstract and scoring sections would benefit from greater precision. The 47.7% resolution rate is computed by re-running PyExamine after the agent's edit and checking whether the original smell flag has disappeared. This definition aligns with the automated, detector-driven nature of SmellBench and measures success against the same criterion used to identify the initial smells. We acknowledge that this metric does not incorporate a separate expert judgment on whether cross-module design intent was preserved or improved, which could allow certain localized changes to count as successes. In the revised manuscript we will update the abstract and §§3–4 to state explicitly that resolution is defined by non-re-detection, and we will add a brief discussion in the limitations section noting this distinction and its implications for interpreting the gap in architectural reasoning. revision: yes
-
Referee: [§2 and §4] Test-set construction (§2 and §4): The 65 smells are described as “hard-severity” and “validated against expert judgments,” yet the paper does not report the precise exclusion rules, inter-expert agreement on smell validity, or sampling procedure used to ensure the set is representative rather than biased toward smells that PyExamine flags reliably. This directly affects the generalizability of the gap claim.
Authors: We thank the referee for highlighting this omission. The 65 smells comprise the complete set of hard-severity architectural smells returned by PyExamine on scikit-learn; expert validation was performed to confirm each as a genuine architectural issue before inclusion. We will revise §§2 and §4 to report the precise exclusion rules applied during validation, the inter-expert agreement on validity, and to confirm that the set is exhaustive rather than a sampled subset. These additions will strengthen the description of the test set and support the generalizability of the reported gap. revision: yes
-
Referee: [results section] Net-impact measurement (results): The finding that the most aggressive agent introduces 140 new smells is load-bearing for the aggressiveness–quality tradeoff. The paper should clarify whether “new smells” are counted only by PyExamine re-scan or also by expert review of whether the introduced issues are architecturally meaningful; without the latter, the metric risks conflating detector noise with genuine degradation.
Authors: We agree that explicit clarification is warranted. The count of 140 new smells is obtained solely by re-running PyExamine on the post-repair codebase and tallying additional detections. This approach ensures methodological consistency with the original smell identification. We recognize that the metric may therefore include some detector noise. In the revised results section we will state this explicitly and add a short discussion of the limitation, noting that future benchmark extensions could incorporate expert review of introduced smells to further isolate genuine architectural degradation. revision: yes
Circularity Check
No significant circularity: empirical benchmark with expert validation and released artifacts
full rationale
The paper is a self-contained empirical evaluation study that introduces SmellBench, applies PyExamine detection to scikit-learn, performs expert validation of the 65 smells (reporting 63.1% false positives), and measures agent performance via resolution rate, kappa agreement on false-positive identification, and net smell count impact. No mathematical derivations, equations, fitted parameters, or predictions appear in the provided text. The scoring methodology is described as separating repair effectiveness from false-positive identification and net impact, with explicit expert judgments and public code/data release. No self-citation load-bearing steps, uniqueness theorems, or ansatzes are invoked. The central claims rest on observable experimental outcomes rather than reducing to inputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Expert human judgments constitute reliable ground truth for validating detected architectural code smells and agent repairs.
- domain assumption The 65 hard-severity smells in scikit-learn are representative of architectural smells requiring cross-module reasoning.
invented entities (1)
-
SmellBench framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
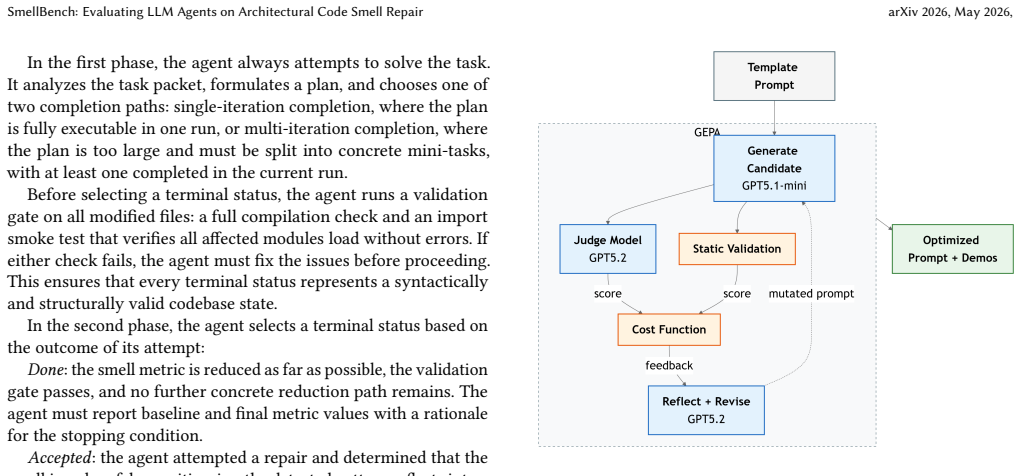
GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning
Lakshya A. Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl-Ong, Arnav Singhvi, Herumb Shandilya, Michael J. Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alexandros G. Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab. 2026. GEPA: Reflective Prompt Evolution Can Outperform Reinforcement Learning.arXiv preprint...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2507.19457 2026
-
[2]
Anthropic. 2024. Introducing the Model Context Protocol. Anthropic Blog. https://www.anthropic.com/news/model-context-protocol Accessed: 2026-03- 21
work page 2024
-
[3]
Anthropic. 2025. Claude Code: Agentic Coding Tool. https://github.com/ anthropics/claude-code Accessed: 2026-03-15
work page 2025
-
[4]
Andrea Arcuri and Lionel Briand. 2011. A practical guide for using statistical tests to assess randomized algorithms in software engineering. InProceedings of the 33rd International Conference on Software Engineering(Waikiki, Honolulu, HI, USA)(ICSE ’11). Association for Computing Machinery, New York, NY, USA, 1–10. doi:10.1145/1985793.1985795
-
[5]
Nguyen, Robert Dyer, and Hridesh Rajan
Fraol Batole, David OBrien, Tien N. Nguyen, Robert Dyer, and Hridesh Rajan
-
[6]
In: 2025 IEEE/ACM 47th International Conference on Software Engineering (ICSE)
An LLM-Based Agent-Oriented Approach for Automated Code Design Issue Localization. InProceedings of the IEEE/ACM 47th International Conference on Software Engineering(Ottawa, Ontario, Canada)(ICSE ’25). IEEE Press, 1320–1332. doi:10.1109/ICSE55347.2025.00100
-
[7]
Islem Bouzenia, Premkumar Devanbu, and Michael Pradel. 2025. RepairAgent: An Autonomous, LLM-Based Agent for Program Repair(ICSE ’25). IEEE Press, 2188–2200. doi:10.1109/ICSE55347.2025.00157
-
[8]
Jonathan Cordeiro, Shayan Noei, and Ying Zou. 2024. An Empirical Study on the Code Refactoring Capability of Large Language Models.arXiv preprint arXiv:2411.02320(2024). https://doi.org/10.48550/arXiv.2411.02320
-
[9]
Dhruv Gautam, Spandan Garg, Jinu Jang, Neel Sundaresan, and Roshanak Zilouch- ian Moghaddam. 2025. RefactorBench: Evaluating Stateful Reasoning in Lan- guage Agents Through Code.arXiv preprint arXiv:2503.07832v1(2025). https: //doi.org/10.48550/arXiv.2503.07832
-
[10]
Google. 2025. Gemini CLI: AI Agent for the Command Line. https://github.com/ google-gemini/gemini-cli Accessed: 2026-03-15
work page 2025
-
[11]
Zhaoqiang Guo, Tingting Tan, Shiran Liu, Xutong Liu, Wei Lai, Yibiao Yang, Yanhui Li, Lin Chen, Wei Dong, and Yuming Zhou. 2023. Mitigating False Pos- itive Static Analysis Warnings: Progress, Challenges, and Opportunities.IEEE Transactions on Software Engineering49, 12 (2023), 5154–5188. doi:10.1109/TSE. 2023.3329667
work page doi:10.1109/tse 2023
-
[12]
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. 2024. SWE-bench: Can Language Models Resolve Real-world Github Issues?. InThe Twelfth International Conference on Learning Representations. https://openreview.net/forum?id=VTF8yNQM66
work page 2024
-
[13]
Rodi Jolak, Simon Karlsson, and Felix Dobslaw. 2025. An empirical investigation of the impact of architectural smells on software maintainability.Journal of Systems and Software225 (2025), 112382. doi:10.1016/j.jss.2025.112382
-
[14]
Mistral AI. 2025. Mistral Vibe: Agentic Coding Assistant. https://github.com/ mistralai/mistral-vibe Accessed: 2026-03-15
work page 2025
-
[15]
Haris Mumtaz, Paramvir Singh, and Kelly Blincoe. 2021. A systematic mapping study on architectural smells detection.Journal of Systems and Software173 (2021), 110885. doi:10.1016/j.jss.2020.110885
-
[16]
Samal Nursapa, Anastassiya Samuilova, Alessio Bucaioni, and Phuong Nguyen
-
[17]
ROSE: Transformer-Based Refactoring Recommendation for Architectural Smells. 421–427. doi:10.1109/ESEM64174.2025.00019
-
[18]
OpenAI. 2025. Codex CLI: Open-Source Coding Agent. https://github.com/ openai/codex Accessed: 2026-03-15
work page 2025
-
[19]
Khouloud Oueslati, Maxime Lamothe, and Foutse Khomh. 2026. RefAgent: A Multi-agent LLM-based Framework for Automatic Software Refactoring.arXiv preprint arXiv:2511.03153v2(2026). https://doi.org/10.48550/arXiv.2511.03153
-
[20]
Fabian Pedregosa, Gaël Varoquaux, Alexandre Gramfort, Vincent Michel, Bertrand Thirion, Olivier Grisel, Mathieu Blondel, Peter Prettenhofer, Ron Weiss, Vincent Dubourg, Jake Vanderplas, Alexandre Passos, David Cournapeau, Matthieu Brucher, Matthieu Perrot, and Édouard Duchesnay. 2011. Scikit-learn: Machine Learning in Python.J. Mach. Learn. Res.12 (Nov. 2...
work page 2011
- [21]
-
[22]
Toward Realistic AI-Generated Student Questions to Support Instructor Training
Claudio Tessa, Matteo Bochicchio, and Francesca Arcelli Fontana. 2025.Exploring Architectural Smells Detection Through LLMs. 90–98. doi:10.1007/978-3-032- 02138-0_6
-
[23]
Will Tracz. 2015. Refactoring for Software Design Smells: Managing Techni- cal Debt by Girish Suryanarayana, Ganesh Samarthyam, and Tushar Sharma. SIGSOFT Softw. Eng. Notes40, 6 (Nov. 2015), 36. doi:10.1145/2830719.2830739
-
[24]
Palacio, Luftar Rahman Alif, and Denys Poshyvanyk
Alejandro Velasco, Daniel Rodriguez-Cardenas, Dipin Khati, David N. Palacio, Luftar Rahman Alif, and Denys Poshyvanyk. 2026. A Causal Perspective on Measuring, Explaining and Mitigating Smells in LLM-Generated Code.arXiv preprint arXiv:2511.15817v5(2026). https://doi.org/10.48550/arXiv.2511.15817 SmellBench: Evaluating LLM Agents on Architectural Code Sme...
-
[25]
Di Wu, Fangwen Mu, Lin Shi, Zhaoqiang Guo, Kui Liu, Weiguang Zhuang, Yuqi Zhong, and Li Zhang. 2024. iSMELL: Assembling LLMs with Expert Toolsets for Code Smell Detection and Refactoring. InProceedings of the 39th IEEE/ACM International Conference on Automated Software Engineering(Sacramento, CA, USA)(ASE ’24). Association for Computing Machinery, New Yor...
-
[26]
Chunqiu Steven Xia, Yinlin Deng, Soren Dunn, and Lingming Zhang. 2025. De- mystifying LLM-Based Software Engineering Agents.Proc. ACM Softw. Eng.2, FSE, Article FSE037 (June 2025), 24 pages. doi:10.1145/3715754
-
[27]
Chunqiu Steven Xia, Yuxiang Wei, and Lingming Zhang. 2023. Automated Program Repair in the Era of Large Pre-Trained Language Models(ICSE ’23). IEEE Press, 1482–1494. doi:10.1109/ICSE48619.2023.00129
-
[28]
Yisen Xu, Feng Lin, Jinqiu Yang, Tse-Hsun (Peter) Chen, and Nikolaos Tsantalis
-
[29]
MANTRA: Enhancing Automated Method-Level Refactoring with Contex- tual RAG and Multi-Agent LLM Collaboration.arXiv preprint arXiv:2503.14340v2 (2025). https://doi.org/10.48550/arXiv.2503.14340
-
[30]
Zhipeng Xue, Xiaoting Zhang, Zhipeng Gao, Xing Hu, Shan Gao, Xin Xia, and Shanping Li. 2026. Clean Code, Better Models: Enhancing LLM Performance with Smell-Cleaned Dataset.ACM Trans. Softw. Eng. Methodol.(Feb. 2026). doi:10. 1145/3793252
work page 2026
-
[31]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. 2024. SWE-agent: agent-computer interfaces enable automated software engineering. InProceedings of the 38th International Conference on Neural Information Processing Systems(Vancouver, BC, Canada) (NIPS ’24). Curran Associates Inc., Red Hook, NY,...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.