Recognition: no theorem link
A Systematic Investigation of The RL-Jailbreaker in LLMs
Pith reviewed 2026-05-11 01:29 UTC · model grok-4.3
The pith
Dense rewards and longer episodes drive the success of reinforcement learning jailbreaks on language models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
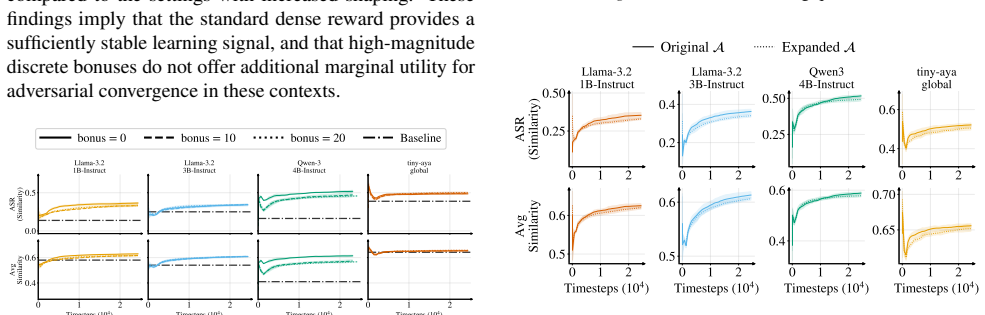
Through a controlled breakdown of the RL jailbreaking framework, the study establishes that problem formalization elements, specifically dense reward functions and extended episode lengths, are the dominant factors enabling the RL-jailbreaker to compromise all targeted language models and their safeguards, while variations in algorithmic measures such as the choice of RL algorithm or training data produce comparatively smaller effects.
What carries the argument
The decomposition of RL jailbreaking into problem formalization components (reward function, action space, episode length) and algorithmic measures (RL algorithm, training data, reward-shaping).
If this is right
- Adjusting reward density and episode length provides a direct lever for raising the efficiency of RL-based jailbreaks.
- Defenses that alter how an attacker can define rewards or episode length could reduce vulnerability more effectively than algorithm-specific countermeasures.
- The same decomposition supplies a repeatable method for testing and hardening models against RL-style attacks.
- Broad success across tested models and safeguards indicates that environment formalization weaknesses are not limited to particular model families.
Where Pith is reading between the lines
- The same environmental factors may explain why other sequential attack methods succeed even without reinforcement learning.
- Model developers could proactively limit an attacker's ability to set custom dense rewards or long interaction lengths as a general safeguard.
- Testing whether non-RL jailbreaks also improve when given denser feedback signals would check if the finding is specific to reinforcement learning.
- The approach could extend to evaluating safety in multi-turn agent systems where reward design similarly shapes behavior.
Load-bearing premise
The chosen split between environment setup and algorithmic choices identifies the main causes of success, and the patterns observed hold for models and attack configurations beyond those tested.
What would settle it
Running the same RL-jailbreaker with sparse rewards and short episode lengths on the original models and measuring whether success rates fall sharply while algorithmic choices remain fixed.
Figures












read the original abstract
The evolution of generative models from next-token predictors to autonomous engines of complex systems necessitates rigorous safety hardening. Adversarial jailbreaking, the strategic manipulation of models to elicit harmful output, remains a primary threat to safe deployment. While Reinforcement Learning (RL) frames jailbreaking as a multi-step attack through sequential optimization, a mechanistic understanding of why the framework succeeds remains incomplete. To fill this gap, we present the first systematic decomposition of RL jailbreaking. We deconstruct the framework into problem formalization (reward function, action space, episode length), and algorithmic measures (RL algorithm, training data, reward-shaping) to identify the structural determinants of adversarial success. Our results reveal that the RL-jailbreaker successfully compromised all targeted models and safeguards. Through this first-of-its-kind analysis, we demonstrate that environment formalization, specifically dense rewards and extended episode lengths, is the primary driver of jailbreaking success. This work provides a tool for improving RL-jailbreaker efficiency and, ultimately, harden generative models resistant to RL-based attacks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
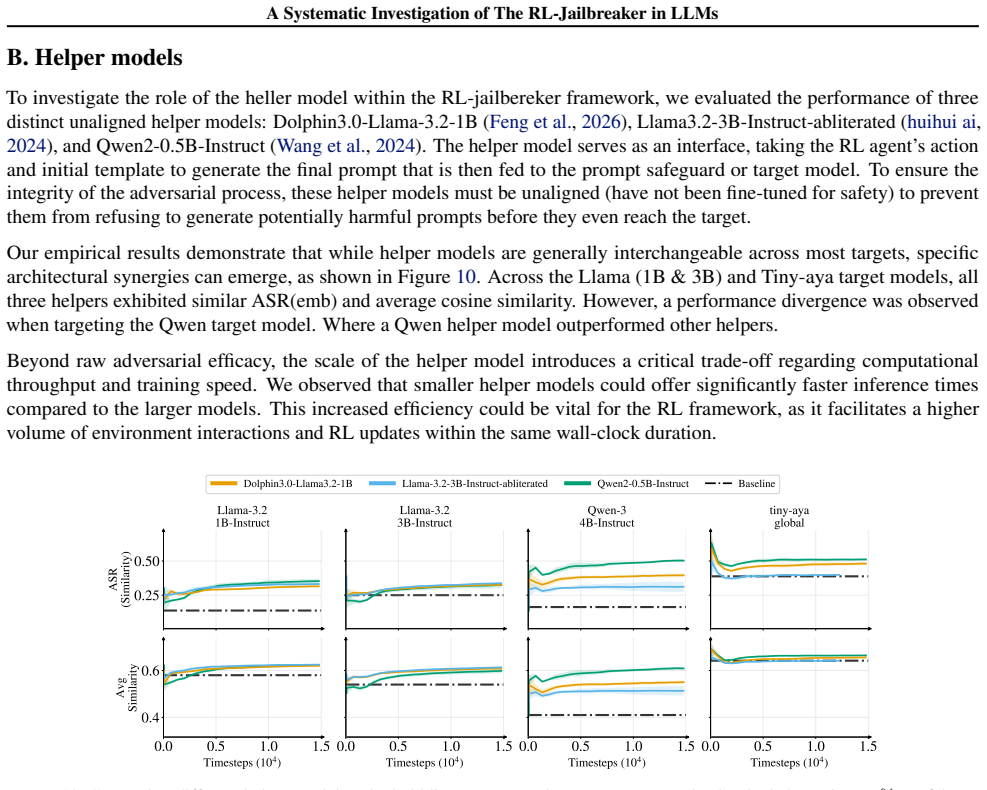
Summary. The paper claims to provide the first systematic decomposition of RL-based jailbreaking on LLMs into problem formalization (reward function, action space, episode length) and algorithmic measures (RL algorithm, training data, reward-shaping). It reports that the RL-jailbreaker successfully compromised all targeted models and safeguards, identifying environment formalization—specifically dense rewards and extended episode lengths—as the primary driver of adversarial success.
Significance. If the quantitative results hold, the work would supply a useful structural breakdown of RL jailbreak mechanisms, potentially guiding more efficient attack implementations and stronger defenses by highlighting the outsized role of reward density and episode length over algorithmic choices.
major comments (1)
- [Experimental Results] The assertion that environment formalization is the primary driver lacks supporting quantitative evidence. No effect sizes, confidence intervals, or head-to-head ablations are described that hold algorithmic factors fixed while varying reward density and episode length (or vice versa) to demonstrate larger, consistent deltas from formalization choices. Without these controls the primacy conclusion remains unverified and could be falsified by comparable algorithmic effects.
minor comments (1)
- [Abstract] The abstract states that all targeted models were compromised but provides no list of the specific models, safeguards, or evaluation metrics used, which hinders assessment of generalizability.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback on our manuscript. We address the major comment point by point below and outline the revisions we will make to strengthen the evidence supporting our claims.
read point-by-point responses
-
Referee: The assertion that environment formalization is the primary driver lacks supporting quantitative evidence. No effect sizes, confidence intervals, or head-to-head ablations are described that hold algorithmic factors fixed while varying reward density and episode length (or vice versa) to demonstrate larger, consistent deltas from formalization choices. Without these controls the primacy conclusion remains unverified and could be falsified by comparable algorithmic effects.
Authors: We acknowledge that the current version of the manuscript presents comparative results across configurations but does not include the specific controlled head-to-head ablations with algorithmic factors held fixed, nor does it report effect sizes or confidence intervals from repeated trials. In the revised manuscript, we will add these experiments: we will fix the RL algorithm, training data, and reward-shaping while systematically varying reward density and episode length (and vice versa), reporting success rate deltas, effect sizes, and 95% confidence intervals. These additions will provide the quantitative support needed to substantiate that formalization choices produce larger and more consistent effects. revision: yes
Circularity Check
No circularity: empirical investigation without derivational reduction
full rationale
The paper is a systematic empirical study that decomposes RL jailbreaking into problem formalization (reward function, action space, episode length) and algorithmic measures, then reports experimental outcomes on model compromises. No equations, derivations, or parameter-fitting steps are described that could reduce a claimed prediction or primary driver back to its inputs by construction. The assertion that dense rewards and extended episode lengths are the primary driver rests on observed results rather than self-definition, fitted-input renaming, or self-citation chains. The work is self-contained against external benchmarks in the sense that its claims are falsifiable via replication of the reported experiments; no load-bearing uniqueness theorems or ansatzes imported from prior author work appear. This is the expected non-finding for an empirical investigation.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Explore, Establish, Ex- ploit: Red Teaming Language Models from Scratch
Casper, S., Lin, J., Kwon, J., Culp, G., and Hadfield-Menell, D. Explore, Establish, Exploit: Red teaming Language Models from scratch.arXiv preprint 2306.09442,
-
[2]
Chen, M., Tworek, J., Jun, H., Yuan, Q., Pinto, H. P. D. O., Kaplan, J., Edwards, H., Burda, Y ., Joseph, N., Brockman, G., et al. Evaluating large language models trained on code. InarXiv preprint 2107.03374,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Vullibgen: Identifying vulnerable third- party libraries via generative pre-trained model
Chen, T., Li, L., Zhu, L., Li, Z., Liang, G., Li, D., Wang, Q., and Xie, T. Vullibgen: Identifying vulnerable third- party libraries via generative pre-trained model. InarXiv preprint 2308.04662,
-
[4]
When LLM meets DRL: Advancing Jailbreaking Efficiency via DRL- guided Search
Chen, X., Nie, Y ., Guo, W., and Zhang, X. When LLM meets DRL: Advancing Jailbreaking Efficiency via DRL- guided Search. InAdvances in Neural Information Pro- cessing Systems, 2024a. Chen, X., Nie, Y ., Yan, L., Mao, Y ., Guo, W., and Zhang, X. RL-JACK: Reinforcement learning-powered black- box jailbreaking attack against LLMs. InarXiv preprint 2406.08725...
-
[5]
Feng, H., Shi, W., Zhang, K., Fei, X., Liao, L., Yang, D., Du, Y ., Wu, X., Tang, J., Liu, Y ., et al. Dolphin-v2: Universal document parsing via scalable anchor prompting.arXiv preprint 2602.05384,
-
[6]
Grattafiori, A., Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Vaughan, A., et al. The llama 3 herd of models.arXiv preprint 2407.21783,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Wang, P., Zhu, Q., Xu, R., Zhang, R., Ma, S., Bi, X., et al. Deepseek- R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning.arXiv preprint 2501.12948, 2025a. Guo, W., Shi, Z., Li, Z., Wang, Y ., Liu, X., Wang, W., Liu, F., Zhang, M., and Li, J. Jailbreak-R1: Exploring the Jailbreak Capabilities ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Liu, Y ., Zhou, S., Lu, Y ., Zhu, H., Wang, W., Lin, H., He, B., Han, X., and Sun, L. Auto-RT: Automatic Jailbreak Strategy Exploration for Red-Teaming Large Language Models.arXiv preprint 2501.01830,
-
[9]
Nasr, M., Carlini, N., Sitawarin, C., Schulhoff, S. V ., Hayes, J., Ilie, M., Pluto, J., Song, S., Chaudhari, H., Shumailov, I., et al. The Attacker Moves Second: Stronger Adaptive Attacks bypass Defenses against LLM Jailbreaks and Prompt Injections.arXiv preprint 2510.09023,
-
[10]
doi: 10.3390/healthcare13141649. Salamanca, A. R., Abagyan, D., D’souza, D., Khairi, A., Mora, D., Dash, S., Aryabumi, V ., Rajaee, S., Mofakhami, M., Sahu, A., et al. Tiny aya: Bridging scale and multi- lingual depth.arXiv preprint 2603.11510,
-
[11]
arXiv preprint arXiv:2412.12509 , year =
Schroeder, K. and Wood-Doughty, Z. Can you trust llm judgments? reliability of llm-as-a-judge.arXiv preprint arXiv:2412.12509,
-
[12]
Proximal Policy Optimization Algorithms
Schulman, J., Wolski, F., Dhariwal, P., Radford, A., and Klimov, O. Proximal Policy Optimization Algorithms. arXiv preprint 1707.06347,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
A coin flip for safety: Llm judges fail to reliably measure adversarial robustness
Schwinn, L., Ladenburger, M., Beyer, T., Mofakhami, M., Gidel, G., and G¨unnemann, S. A coin flip for safety: Llm 9 A Systematic Investigation of The RL-Jailbreaker in LLMs judges fail to reliably measure adversarial robustness. arXiv preprint 2603.06594,
-
[14]
Sharma, M., Tong, M., Mu, J., Wei, J., Kruthoff, J., Good- friend, S., Ong, E., Peng, A., Agarwal, R., Anil, C., et al. Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming. arXiv preprint 2501.18837,
-
[15]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Wang, H., Qin, Z., Zhao, Y ., Du, C., Lin, M., Wang, X., and Pang, T. Lifelong Safety Alignment for Language Models. InAdvances in Neural Information Processing Systems, 2025a. Wang, P., Bai, S., Tan, S., Wang, S., Fan, Z., Bai, J., Chen, K., Liu, X., Wang, J., Ge, W., et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resol...
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Wang, Z., He, D., Zhang, Z., Li, X., Zhu, L., Li, M., and Liu, J. Formalization Driven LLM Prompt Jailbreaking via Reinforcement Learning.arXiv preprint 2509.23558, 2025b. Wei, A., Haghtalab, N., and Steinhardt, J. Jailbroken: How does LLM safety training fail? InAdvances in Neural Information Processing Systems,
-
[17]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report.arXiv preprint 2505.09388,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Gpt-4 is too smart to be safe: Stealthy chat with llms via cipher
Yuan, Y ., Jiao, W., Wang, W., Huang, J.-t., He, P., Shi, S., and Tu, Z. GPT-4 is too smart to be safe: Stealthy Chat with LLMs via Cipher. InarXiv preprint 2308.06463,
-
[19]
arXiv preprint arXiv:2407.21772 , year=
Zeng, W., Liu, Y ., Mullins, R., Peran, L., Fernandez, J., Harkous, H., Narasimhan, K., Proud, D., Kumar, P., Rad- harapu, B., et al. Shieldgemma: Generative ai content moderation based on gemma.arXiv preprint 2407.21772, 2024a. Zeng, Y ., Lin, H., Zhang, J., Yang, D., Jia, R., and Shi, W. How Johnny Can Persuade LLMs to Jailbreak Them: Re- thinking Persu...
-
[20]
CrossGuard: Safeguarding MLLMs against Joint-Modal Implicit Malicious Attacks
10 A Systematic Investigation of The RL-Jailbreaker in LLMs Zhang, X., Li, H., and Lu, Z. CrossGuard: Safeguarding MLLMs against Joint-Modal Implicit Malicious Attacks. arXiv preprint 2510.17687,
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
The queue is initialised from the hand-crafted jailbreak templates of Chen et al
Template initialization and Selection.Each episode selects an initial template from a seed queue using a UCB-style MCTS rule: UCB(v) = rv nv + 1 +c s 2 lntglobal nv + 1 , c= 0.5, where rv and nv are the accumulated reward and visit count of node v, and tglobal is the global episode counter. The queue is initialised from the hand-crafted jailbreak template...
work page 2048
-
[22]
on aLlama-3.2-3B-Instructtarget model. 10 5 10 3 0.34 0.35 Step-size sweep ASR (Similarity) 10 5 10 3 0.07 0.08 ASR (Keyword) 10 5 10 3 0.50 0.52 ASR (Q-R Similarity) 10 5 10 3 0.600 0.605 Avg Similarity 10 5 10 3 0.645 0.650 0.655 Avg Q-R Similarity 0.8 0.9 0.325 0.350 GAE ( ) sweep 0.8 0.9 0.06 0.08 0.8 0.9 0.500 0.525 0.8 0.9 0.60 0.61 0.8 0.9 0.64 0.6...
work page 1987
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.