Recognition: 2 theorem links
· Lean TheoremAn Interpretable and Scalable Framework for Evaluating Large Language Models
Pith reviewed 2026-05-11 01:05 UTC · model grok-4.3
The pith
Reformulating item response theory as constrained matrix factorization lets researchers evaluate large language models faster and more stably.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
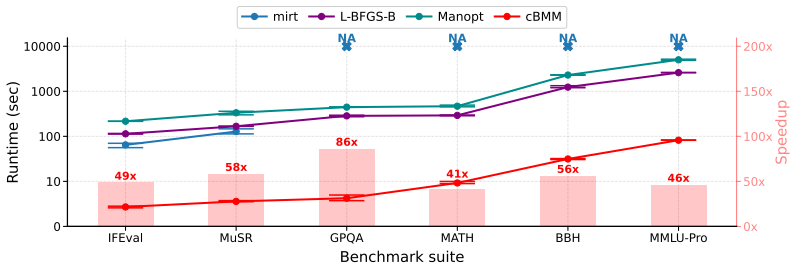
Our approach reformulates the problem as a sequence of constrained matrix factorization subproblems, enabling stable and efficient parameter estimation with theoretical guarantees for identifiability and convergence. Experiments on synthetic and real-world datasets, including MATH-500 and six Open LLM Leaderboard benchmarks, demonstrate that our method achieves superior scalability and interpretability. It delivers orders-of-magnitude speedups over competing methods while maintaining comparable or even higher estimation accuracy.
What carries the argument
The majorization-minimization principle that converts item response theory estimation into a sequence of constrained matrix factorization subproblems.
If this is right
- Computation time for full IRT-based evaluation drops by orders of magnitude.
- Parameter estimates remain stable and at least as accurate as prior methods.
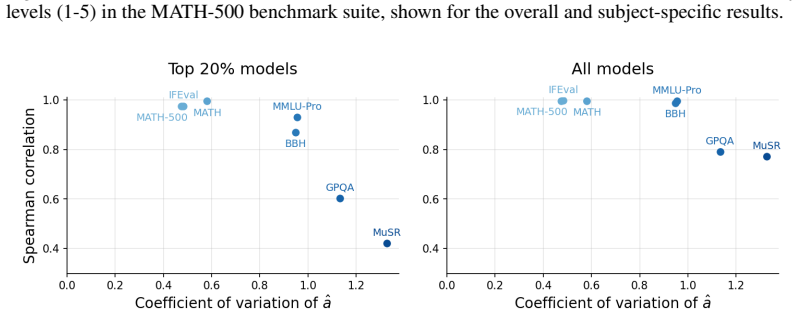
- Item difficulty and discrimination values become available to inform benchmark design.
- The estimates are consistent with established LLM scaling laws.
Where Pith is reading between the lines
- The speed gain could make routine IRT analysis feasible for every new model release and every large benchmark.
- Item-level insights might help construct balanced test sets that avoid over-representing easy or hard items.
- If the underlying response model holds, the same factorization approach could extend to evaluating other stochastic systems such as reinforcement-learning agents.
Load-bearing premise
That the standard item response theory model, with its logistic relation between latent ability and item parameters, adequately describes LLM response patterns.
What would settle it
A new benchmark where the ability estimates produced by this method fail to predict performance on held-out items or deviate from observed scaling-law trends.
Figures



read the original abstract
Evaluation of large language models (LLMs) is increasingly critical, yet standard benchmarking methods rely on average accuracy, overlooking both the inherent stochasticity of LLM outputs and the heterogeneity of benchmark items. Item Response Theory (IRT) offers a principled framework for modeling latent model abilities and item characteristics, but conventional methods are computationally expensive and numerically unstable, limiting large-scale implementations. To address these challenges, we propose an interpretable and scalable framework for LLM evaluation based on the majorization-minimization principle. Our approach reformulates the problem as a sequence of constrained matrix factorization subproblems, enabling stable and efficient parameter estimation with theoretical guarantees for identifiability and convergence. Experiments on synthetic and real-world datasets, including MATH-500 and six Open LLM Leaderboard benchmarks, demonstrate that our method achieves superior scalability and interpretability. It delivers orders-of-magnitude speedups over competing methods while maintaining comparable or even higher estimation accuracy. Our results align with established scaling laws and offer insights into item difficulty and discrimination, informing more principled benchmark design.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to introduce a scalable IRT-based framework for LLM evaluation by reformulating latent ability and item parameter estimation as a sequence of constrained matrix factorization subproblems solved via majorization-minimization. This yields theoretical guarantees for identifiability and convergence, orders-of-magnitude speedups over baselines, and comparable or superior accuracy on synthetic data plus real benchmarks (MATH-500 and six Open LLM Leaderboard tasks), while providing interpretable insights into item difficulty and discrimination that align with scaling laws.
Significance. If the central claims hold, the work would enable efficient large-scale IRT application to LLM evaluation, moving beyond average accuracy to model stochasticity and item heterogeneity. The matrix-factorization reformulation addresses a key computational barrier in traditional IRT, and the empirical results on established benchmarks plus alignment with scaling laws are strengths. However, these benefits are conditional on the IRT model being appropriate for LLM response patterns.
major comments (2)
- [Abstract and §3] Abstract and §3 (method): The abstract asserts 'theoretical guarantees for identifiability and convergence' from the majorization-minimization reformulation, but no derivation, proof sketch, or reference to supplementary material is provided. This is load-bearing for the scalability and stability claims.
- [§5] §5 (experiments): No error bars, statistical significance tests, or ablation on IRT model fit (e.g., goodness-of-fit diagnostics, residual analysis, or comparison to non-IRT baselines) are reported for the real datasets (MATH-500, Open LLM Leaderboard). Without these, the claim of 'higher estimation accuracy' cannot be distinguished from optimization artifacts or model misspecification.
minor comments (2)
- [§3] The description of the constraint sets in the matrix factorization subproblems would benefit from explicit notation or a small illustrative example in the main text.
- [§4] Consider adding a brief discussion of how the method handles the stochasticity of LLM outputs beyond the standard logistic IRT link.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the presentation of our work. We address each major comment below and have revised the manuscript accordingly to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (method): The abstract asserts 'theoretical guarantees for identifiability and convergence' from the majorization-minimization reformulation, but no derivation, proof sketch, or reference to supplementary material is provided. This is load-bearing for the scalability and stability claims.
Authors: We agree that an explicit derivation strengthens the claims. The majorization-minimization reformulation yields identifiability from the constrained matrix factorization (via uniqueness of the low-rank decomposition under the given constraints) and convergence from the standard MM properties (monotonic decrease of the objective and boundedness). In the revised version, we add a concise proof sketch to §3 and explicitly reference the supplementary material containing the full proofs. revision: yes
-
Referee: [§5] §5 (experiments): No error bars, statistical significance tests, or ablation on IRT model fit (e.g., goodness-of-fit diagnostics, residual analysis, or comparison to non-IRT baselines) are reported for the real datasets (MATH-500, Open LLM Leaderboard). Without these, the claim of 'higher estimation accuracy' cannot be distinguished from optimization artifacts or model misspecification.
Authors: We acknowledge the need for greater statistical transparency on real data. In the revision, we will report error bars (standard deviations across repeated runs with different initializations), conduct statistical significance tests (paired t-tests against baselines), and add model-fit diagnostics including residual analysis and a direct comparison to non-IRT baselines such as mean accuracy. These additions will be included for both MATH-500 and the Open LLM Leaderboard tasks. revision: yes
Circularity Check
No significant circularity; derivation is self-contained optimization reformulation
full rationale
The paper reformulates standard IRT parameter estimation for LLM responses as a sequence of constrained matrix-factorization subproblems solved by majorization-minimization, claiming identifiability, convergence, and scalability gains. No quoted step defines target quantities in terms of fitted outputs, renames a known result, imports uniqueness via self-citation, or smuggles an ansatz; the central claims rest on the external IRT model plus the new solver, with experiments on MATH-500 and Open LLM Leaderboard providing independent validation. This is the common honest case of an applied optimization contribution whose correctness hinges on model assumptions rather than internal circularity.
Axiom & Free-Parameter Ledger
free parameters (1)
- latent ability and item parameters
axioms (1)
- domain assumption LLM responses are generated according to an IRT model with logistic or similar link
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearreformulates the problem as a sequence of constrained matrix factorization subproblems... majorization-minimization principle... quadratic majorization g(X|˜X)=L/2∥X−˜Y∥²_F(Ω)... cBMM algorithm
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclearTheorem 1 (Structural preservation). The latent probabilistic model (1) is identifiable up to an equivalence class if θ≠c and a≥0 with a≠0.
Reference graph
Works this paper leans on
-
[1]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Passonneau, Evan Radcliffe, Guru Rajan Rajagopal, Adam Sloan, Tomasz Tudrej, Ferhan Ture, et al
Berk Atıl, Sarp Aykent, Alexa Chittams, Lisheng Fu, Rebecca J. Passonneau, Evan Radcliffe, Guru Rajan Rajagopal, Adam Sloan, Tomasz Tudrej, Ferhan Ture, et al. Non-determinism of ‘deterministic’ LLM system settings in hosted environments. InProceedings of the 5th Workshop on Evaluation and Comparison of NLP Systems, pages 135–148, Mumbai, India, December ...
2025
-
[3]
Hédy Attouch, Jérôme Bolte, and Benar Fux Svaiter. Convergence of descent methods for semi-algebraic and tame problems: Proximal algorithms, forward–backward splitting, and regularized Gauss–Seidel methods.Mathematical Programming, 137(1):91–129, 2013
2013
-
[4]
Baker and Seock-Ho Kim, editors.Item Response Theory: Parameter Estimation Techniques
Frank B. Baker and Seock-Ho Kim, editors.Item Response Theory: Parameter Estimation Techniques. CRC Press, 2nd edition, 2004
2004
-
[5]
Mislav Balunovi ´c, Jasper Dekoninck, Ivo Petrov, Nikola Jovanovi ´c, and Martin Vechev. MathArena: Evaluating LLMs on uncontaminated math competitions.arXiv preprint arXiv:2505.23281, 2026
-
[6]
Bhaskar and Adel Javanmard
Sonia A. Bhaskar and Adel Javanmard. 1-bit matrix completion under exact low-rank constraint. In2015 49th Annual Conference on Information Sciences and Systems (CISS), pages 1–6, 2015
2015
-
[7]
Proximal alternating linearized minimization for nonconvex and nonsmooth problems.Mathematical Programming, 146(1):459–494, 2014
Jérôme Bolte, Shoham Sabach, and Marc Teboulle. Proximal alternating linearized minimization for nonconvex and nonsmooth problems.Mathematical Programming, 146(1):459–494, 2014
2014
-
[8]
Absil, and Rodolphe Sepulchre
Nicolas Boumal, Bamdev Mishra, P.-A. Absil, and Rodolphe Sepulchre. Manopt, a Matlab toolbox for optimization on manifolds.Journal of Machine Learning Research, 15(42):1455– 1459, 2014
2014
-
[9]
Ullman, Fernando Martinez-Plumed, Joshua B
Ryan Burnell, Wout Schellaert, John Burden, Tomer D. Ullman, Fernando Martinez-Plumed, Joshua B. Tenenbaum, Danaja Rutar, Lucy G. Cheke, Jascha Sohl-Dickstein, Melanie Mitchell, et al. Rethink reporting of evaluation results in AI.Science, 380(6641):136–138, 2023
2023
-
[10]
Byrd, Peihuang Lu, Jorge Nocedal, and Ciyou Zhu
Richard H. Byrd, Peihuang Lu, Jorge Nocedal, and Ciyou Zhu. A limited memory algorithm for bound constrained optimization.SIAM Journal on Scientific Computing, 16(5):1190–1208, 1995
1995
-
[11]
A max-norm constrained minimization approach to 1-bit matrix completion.Journal of Machine Learning Research, 14(78):3619–3647, 2013
Tony Cai and Wen-Xin Zhou. A max-norm constrained minimization approach to 1-bit matrix completion.Journal of Machine Learning Research, 14(78):3619–3647, 2013
2013
-
[12]
Rethinking math benchmarks: Implications for AI in education
Jane Castleman, Nimra Nadeem, Tanvi Namjoshi, and Lydia Liu. Rethinking math benchmarks: Implications for AI in education. InProceedings of the Innovation and Responsibility in AI- Supported Education Workshop, volume 273 ofProceedings of Machine Learning Research, pages 66–82. PMLR, 03 Mar 2025
2025
-
[13]
Jianzhe Chai, Yu Zhe, and Jun Sakuma. When benchmarks leak: Inference-time decontamina- tion for LLMs.arXiv preprint arXiv:2601.19334, 2026
-
[14]
Philip Chalmers
R. Philip Chalmers. mirt: A multidimensional item response theory package for the R environ- ment.Journal of Statistical Software, 48(6):1–29, 2012
2012
-
[15]
A Simple Framework for Contrastive Learning of Visual Representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations.arXiv preprint arXiv:2002.05709, 2020
work page internal anchor Pith review arXiv 2002
-
[16]
Item response theory—a statistical framework for educational and psychological measurement.Statistical Science, 40(2):167 – 194, 2025
Yunxiao Chen, Xiaoou Li, Jingchen Liu, and Zhiliang Ying. Item response theory—a statistical framework for educational and psychological measurement.Statistical Science, 40(2):167 – 194, 2025. 10
2025
-
[17]
Zhiyu Zoey Chen, Jing Ma, Xinlu Zhang, Nan Hao, An Yan, Armineh Nourbakhsh, Xianjun Yang, Julian McAuley, Linda Petzold, and William Yang Wang. A survey on large language mod- els for critical societal domains: Finance, healthcare, and law.arXiv preprint arXiv:2405.01769, 2024
-
[18]
Introducing SWE-bench verified, 2024
Neil Chowdhury, James Aung, Chan Jun Shern, Oliver Jaffe, Dane Sherburn, Giulio Starace, Evan Mays, Rachel Dias, Marwan Aljubeh, Mia Glaese, et al. Introducing SWE-bench verified, 2024
2024
-
[19]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[20]
Davenport, Yaniv Plan, Ewout van den Berg, and Mary Wootters
Mark A. Davenport, Yaniv Plan, Ewout van den Berg, and Mary Wootters. 1-bit matrix completion.Information and Inference: A Journal of the IMA, 3(3):189–223, 07 2014
2014
-
[21]
A. P. Dempster, N. M. Laird, and D. B. Rubin. Maximum likelihood from incomplete data via the EM algorithm.Journal of the Royal Statistical Society: Series B (Methodological), 39(1):1–22, 9 1977
1977
-
[22]
Large language model agents in finance: A survey bridging research, practice, and real-world deployment
Yifei Dong, Fengyi Wu, Kunlin Zhang, Yilong Dai, Sanjian Zhang, Wanghao Ye, Sihan Chen, and Zhi-Qi Cheng. Large language model agents in finance: A survey bridging research, practice, and real-world deployment. InFindings of the Association for Computational Lin- guistics: EMNLP 2025, pages 17889–17907, Suzhou, China, November 2025. Association for Comput...
2025
-
[23]
Can we trust AI benchmarks? an interdisciplinary review of current issues in AI evaluation.Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, 8(1):850–864, Oct
Maria Eriksson, Erasmo Purificato, Arman Noroozian, João Vinagre, Guillaume Chaslot, Emilia Gomez, and David Fernandez-Llorca. Can we trust AI benchmarks? an interdisciplinary review of current issues in AI evaluation.Proceedings of the AAAI/ACM Conference on AI, Ethics, and Society, 8(1):850–864, Oct. 2025
2025
-
[24]
Open LLM Leaderboard v2
Clémentine Fourrier, Nathan Habib, Alina Lozovskaya, Konrad Szafer, and Thomas Wolf. Open LLM Leaderboard v2. https://huggingface.co/spaces/open-llm-leaderboard/ open_llm_leaderboard, 2024
2024
-
[25]
Weinberger
Chuan Guo, Geoff Pleiss, Yu Sun, and Kilian Q. Weinberger. On calibration of modern neural networks. InProceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 1321–1330. PMLR, 06–11 Aug 2017
2017
-
[26]
Hambleton and Hariharan Swaminathan.Item Response Theory: Principles and Applications
Ronald K. Hambleton and Hariharan Swaminathan.Item Response Theory: Principles and Applications. Springer Dordrecht, Dordrecht, 1 edition, 1985
1985
-
[27]
Measuring mathematical problem solving with the MATH dataset
Dan Hendrycks, Collin Burns, Saurav Kadavath, Akul Arora, Steven Basart, Eric Tang, Dawn Song, and Jacob Steinhardt. Measuring mathematical problem solving with the MATH dataset. InThirty-fifth Conference on Neural Information Processing Systems Datasets and Benchmarks Track (Round 2), 2021
2021
-
[28]
Training Compute-Optimal Large Language Models
Jordan Hoffmann, Sebastian Borgeaud, Arthur Mensch, Elena Buchatskaya, Trevor Cai, Eliza Rutherford, Diego de Las Casas, Lisa Anne Hendricks, Johannes Welbl, Aidan Clark, et al. Training compute-optimal large language models.arXiv preprint arXiv:2203.15556, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[29]
A tutorial on MM algorithms.The American Statistician, 58(1):30–37, 2004
David R Hunter and Kenneth Lange. A tutorial on MM algorithms.The American Statistician, 58(1):30–37, 2004
2004
-
[30]
David Ili´c and Gilles E. Gignac. Evidence of interrelated cognitive-like capabilities in large language models: Indications of artificial general intelligence or achievement?Intelligence, 106:101858, 2024
2024
-
[31]
SWE-bench: Can language models resolve real-world Github issues? InThe Twelfth International Conference on Learning Representations, 2024
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik R Narasimhan. SWE-bench: Can language models resolve real-world Github issues? InThe Twelfth International Conference on Learning Representations, 2024. 11
2024
-
[32]
Language Models (Mostly) Know What They Know
Saurav Kadavath, Tom Conerly, Amanda Askell, Tom Henighan, Dawn Drain, Ethan Perez, Nicholas Schiefer, Zac Hatfield-Dodds, Nova DasSarma, Eli Tran-Johnson, et al. Language models (mostly) know what they know.arXiv preprint arXiv:2207.05221, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[33]
Scaling Laws for Neural Language Models
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models.arXiv preprint arXiv:2001.08361, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2001
-
[34]
Lim- itations of large language models in clinical problem-solving arising from inflexible reasoning
Jonathan Kim, Anna Podlasek, Kie Shidara, Feng Liu, Ahmed Alaa, and Danilo Bernardo. Lim- itations of large language models in clinical problem-solving arising from inflexible reasoning. Scientific Reports, 15(1):39426, 2025
2025
-
[35]
Auto-Encoding Variational Bayes
Diederik P Kingma and Max Welling. Auto-encoding variational bayes.arXiv preprint arXiv:1312.6114, 2013
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[36]
py-irt: A scalable item response theory library for Python.INFORMS Journal on Computing, 35(1):5–13, 2023
John Patrick Lalor and Pedro Rodriguez. py-irt: A scalable item response theory library for Python.INFORMS Journal on Computing, 35(1):5–13, 2023
2023
-
[37]
Hunter, and Ilsoon Yang
Kenneth Lange, David R. Hunter, and Ilsoon Yang. Optimization transfer using surrogate objective functions.Journal of Computational and Graphical Statistics, 9(1):1–20, 2000
2000
-
[38]
Lawson and Richard J
Charles L. Lawson and Richard J. Hanson.Solving Least Squares Problems. Society for Industrial and Applied Mathematics, 1995
1995
-
[39]
Yucheng Li. Estimating contamination via perplexity: Quantifying memorisation in language model evaluation.arXiv preprint arXiv:2309.10677, 2023
-
[40]
Let’s verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let’s verify step by step. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[41]
Bridging artificial intelligence and biological sciences: A comprehensive review of large language models in bioinformatics.Briefings in Bioinformatics, 26, 07 2025
Anqi Lin, Junpu Ye, Chang Qi, Lingxuan Zhu, Weiming Mou, Wenyi Gan, Dongqiang Zeng, Bufu Tang, Mingjia Xiao, Guangdi Chu, et al. Bridging artificial intelligence and biological sciences: A comprehensive review of large language models in bioinformatics.Briefings in Bioinformatics, 26, 07 2025
2025
-
[42]
Chi, and Boaz Nadler
Xiaoqian Liu, Xu Han, Eric C. Chi, and Boaz Nadler. A majorization-minimization Gauss- Newton method for 1-bit matrix completion.Journal of Computational and Graphical Statistics, 34(3):1017–1029, 2025
2025
-
[43]
Une propriété topologique des sous-ensembles analytiques réels.Les Équations aux Dérivées Partielles, 117:87–89, 1963
Stanisław Łojasiewicz. Une propriété topologique des sous-ensembles analytiques réels.Les Équations aux Dérivées Partielles, 117:87–89, 1963
1963
-
[44]
Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity
Yao Lu, Max Bartolo, Alastair Moore, Sebastian Riedel, and Pontus Stenetorp. Fantastically ordered prompts and where to find them: Overcoming few-shot prompt order sensitivity. In Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8086–8098, Dublin, Ireland, May 2022. Association for Comp...
2022
-
[45]
GAIA: a benchmark for general AI assistants
Grégoire Mialon, Clémentine Fourrier, Thomas Wolf, Yann LeCun, and Thomas Scialom. GAIA: a benchmark for general AI assistants. In B. Kim, Y . Yue, S. Chaudhuri, K. Fragkiadaki, M. Khan, and Y . Sun, editors,International Conference on Learning Representations, volume 2024, pages 9025–9049, 2024
2024
-
[46]
Adversarial NLI: A new benchmark for natural language understanding
Yixin Nie, Adina Williams, Emily Dinan, Mohit Bansal, Jason Weston, and Douwe Kiela. Adversarial NLI: A new benchmark for natural language understanding. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 4885–4901, Online, July 2020. Association for Computational Linguistics
2020
-
[47]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of Machine Learning Research, page...
2021
-
[48]
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R. Bowman. GPQA: A graduate-level google-proof Q&A benchmark.arXiv preprint arXiv:2311.12022, 2023
work page internal anchor Pith review arXiv 2023
-
[49]
XSTest: A test suite for identifying exaggerated safety behaviours in large language models
Paul Röttger, Hannah Kirk, Bertie Vidgen, Giuseppe Attanasio, Federico Bianchi, and Dirk Hovy. XSTest: A test suite for identifying exaggerated safety behaviours in large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers),...
2024
-
[50]
Survey of vulnerabilities in large language models revealed by adversarial attacks,
Erfan Shayegani, Md Abdullah Al Mamun, Yu Fu, Pedram Zaree, Yue Dong, and Nael Abu- Ghazaleh. Survey of vulnerabilities in large language models revealed by adversarial attacks. arXiv preprint arXiv:2310.10844, 2023
-
[51]
Analyzing uncertainty of LLM-as-a-Judge: Interval evaluations with conformal prediction
Huanxin Sheng, Xinyi Liu, Hangfeng He, Jieyu Zhao, and Jian Kang. Analyzing uncertainty of LLM-as-a-Judge: Interval evaluations with conformal prediction. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 11286–11328, Suzhou, China, November 2025. Association for Computational Linguistics
2025
-
[52]
Musr: Testing the limits of chain-of-thought with multistep soft reasoning.arXiv:2310.16049,
Zayne Sprague, Xi Ye, Kaj Bostrom, Swarat Chaudhuri, and Greg Durrett. MuSR: Testing the limits of chain-of-thought with multistep soft reasoning.arXiv preprint arXiv:2310.16049, 2024
-
[53]
Challenging BIG- bench tasks and whether chain-of-thought can solve them
Mirac Suzgun, Nathan Scales, Nathanael Schärli, Sebastian Gehrmann, Yi Tay, Hyung Won Chung, Aakanksha Chowdhery, Quoc Le, Ed Chi, Denny Zhou, et al. Challenging BIG- bench tasks and whether chain-of-thought can solve them. InFindings of the Association for Computational Linguistics: ACL 2023, pages 13003–13051, Toronto, Canada, July 2023. Association for...
2023
-
[54]
Evaluating general-purpose AI with psychometrics.arXiv preprint arXiv:2310.16379, 2023
Xiting Wang, Liming Jiang, Jose Hernandez-Orallo, David Stillwell, Luning Sun, Fang Luo, and Xing Xie. Evaluating general-purpose AI with psychometrics.arXiv preprint arXiv:2310.16379, 2023
-
[55]
MMLU-Pro: A More Robust and Challenging Multi-Task Language Understanding Benchmark
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. MMLU-Pro: A more robust and challenging multi-task language understanding benchmark.arXiv preprint arXiv:2406.01574, 2024
work page internal anchor Pith review arXiv 2024
-
[56]
Mike Wu, Richard L. Davis, Benjamin W. Domingue, Chris Piech, and Noah Goodman. Varia- tional item response theory: Fast, accurate, and expressive.arXiv preprint arXiv:2002.00276, 2020
-
[57]
Skyler Wu, Yash Nair, and Emmanuel J. Candès. Efficient evaluation of LLM performance with statistical guarantees.arXiv preprint arXiv:2601.20251, 2026
work page internal anchor Pith review arXiv 2026
-
[58]
Zhiyu Xu, Jia Liu, Yixin Wang, and Yuqi Gu. Latency-response theory model: Evaluating large language models via response accuracy and chain-of-thought length.arXiv preprint arXiv:2512.07019, 2025
-
[59]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, Haoran Wei, et al. Qwen2.5 technical report.arXiv preprint arXiv:2412.15115, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Yi: Open Foundation Models by 01.AI
Alex Young, Bei Chen, Chao Li, Chengen Huang, Ge Zhang, Guanwei Zhang, Guoyin Wang, Heng Li, Jiangcheng Zhu, Jianqun Chen, et al. Yi: Open foundation models by 01.AI.arXiv preprint arXiv:2403.04652, 2025
work page internal anchor Pith review arXiv 2025
-
[61]
SKILL-MIX: A flexible and expandable family of evaluations for AI models
Dingli Yu, Simran Kaur, Arushi Gupta, Jonah Brown-Cohen, Anirudh Goyal, and Sanjeev Arora. SKILL-MIX: A flexible and expandable family of evaluations for AI models. InThe Twelfth International Conference on Learning Representations, 2024. 13
2024
-
[62]
Redundancy principles for MLLMs benchmarks
Zicheng Zhang, Xiangyu Zhao, Xinyu Fang, Chunyi Li, Xiaohong Liu, Xiongkuo Min, Haodong Duan, Kai Chen, and Guangtao Zhai. Redundancy principles for MLLMs benchmarks. InPro- ceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12492–12504, Vienna, Austria, 2025. Association for Computational L...
2025
-
[63]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[64]
Collins, Yael Moros-Daval, Seraphina Zhang, Qinlin Zhao, Yitian Huang, Luning Sun, Jonathan E
Lexin Zhou, Lorenzo Pacchiardi, Fernando Martínez-Plumed, Katherine M. Collins, Yael Moros-Daval, Seraphina Zhang, Qinlin Zhao, Yitian Huang, Luning Sun, Jonathan E. Prunty, et al. General scales unlock AI evaluation with explanatory and predictive power.Nature, 652:58–67, Apr 2026
2026
-
[65]
PromptBench: A unified library for evaluation of large language models.Journal of Machine Learning Research, 25(254):1–22, 2024
Kaijie Zhu, Qinlin Zhao, Hao Chen, Jindong Wang, and Xing Xie. PromptBench: A unified library for evaluation of large language models.Journal of Machine Learning Research, 25(254):1–22, 2024
2024
-
[66]
{problem}
Yan Zhuang, Qi Liu, Zachary Pardos, Patrick C. Kyllonen, Jiyun Zu, Zhenya Huang, Shijin Wang, and Enhong Chen. Position: AI evaluation should learn from how we test humans. InProceedings of the 42nd International Conference on Machine Learning, volume 267 of Proceedings of Machine Learning Research, pages 82483–82508. PMLR, 13–19 Jul 2025. 14 A Appendices...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.