Recognition: 2 theorem links
· Lean TheoremPan-FM: A Pan-Organ Foundation Model with Saliency-Guided Masking for Missing Robustness
Pith reviewed 2026-05-11 02:39 UTC · model grok-4.3
The pith
A foundation model for seven organs uses attention-based masking to learn balanced whole-body representations that predict diseases more accurately even with missing scans.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Pan-FM is pre-trained on imaging from seven organs using a unified backbone and masking-based self-distillation, with Saliency-Guided Masking (SGM) that adaptively masks dominant organs based on attention distribution to prevent shortcut learning and encourage balanced cross-organ representations; this yields superior prediction performance across multiple diseases and improved robustness under missing-organ conditions compared to baselines.
What carries the argument
Saliency-Guided Masking (SGM): a technique that leverages the model's attention distribution during pre-training to adaptively mask dominant organs, thereby reducing bias toward any single organ and promoting more comprehensive whole-body learning.
Load-bearing premise
That adaptively masking organs based on the model's evolving attention maps during pre-training successfully balances learning without introducing new biases or overfitting to the masking strategy.
What would settle it
Failure to outperform baselines on UK Biobank disease prediction tasks or loss of robustness when specific organs are withheld at test time would indicate the approach does not achieve its intended balanced representations.
Figures



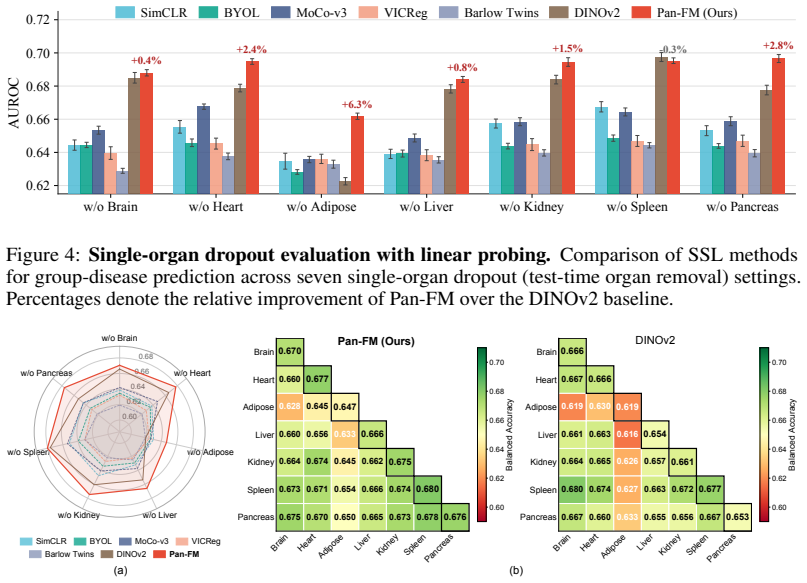







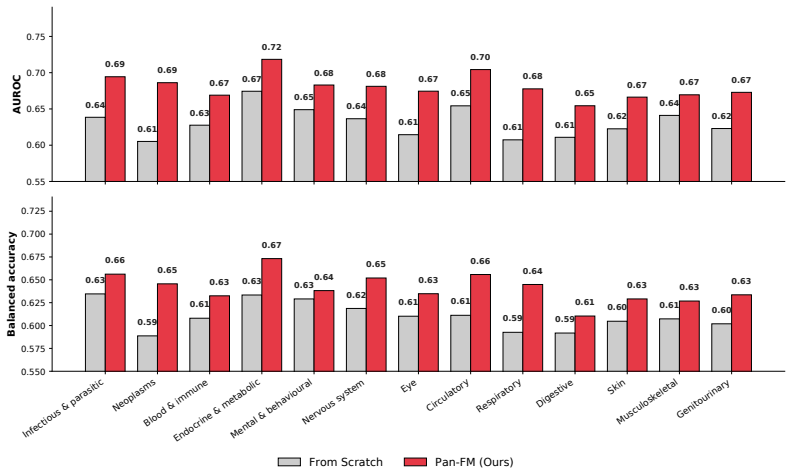

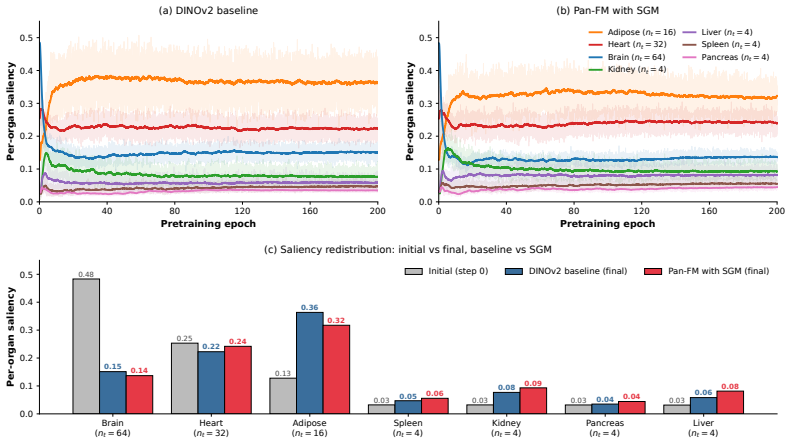
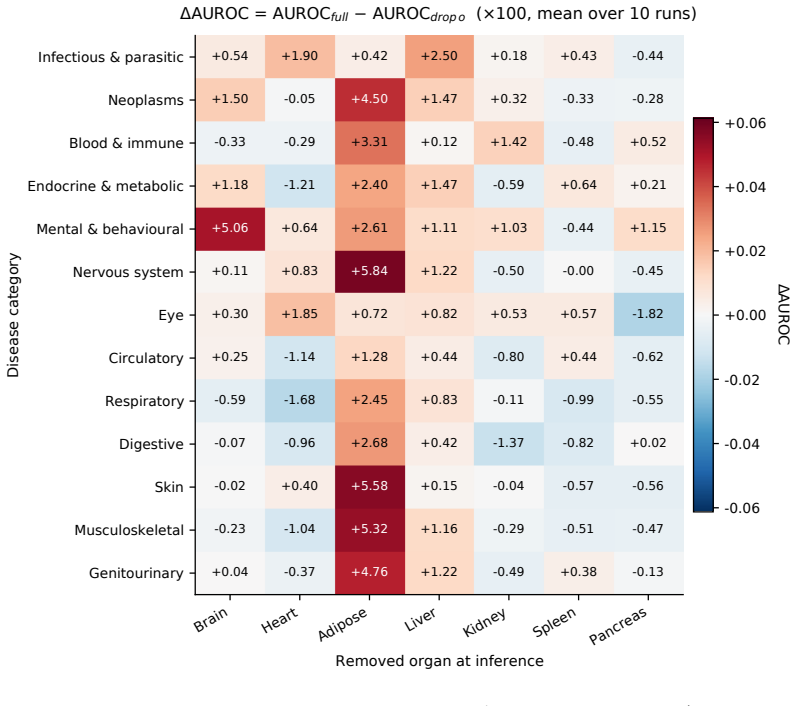
read the original abstract
Foundation models (FMs) have shown great promise in medical imaging, but most FMs are trained on unimodal data within isolated domains, such as brain MRI alone. Human aging and disease arise through coordinated biological processes across organs, therefore motivating multimodal FMs that learn whole-body representations. A key challenge, however, is that real-world multimodal biomedical data are often missing not at random, which can reduce power, limit generalizability, and introduce bias. We propose Pan-FM, a pan-organ foundation model pre-trained on imaging from seven organs (Brain, Heart, Adipose, Liver, Kidney, Spleen, and Pancreas) under realistic missing-organ scenarios. Pan-FM uses a unified backbone that handles organ missingness during both training and inference, and is pre-trained with masking-based self-distillation. We find that naive multimodal pre-training leads to dominant-organ shortcut learning bias, with the model over-relying on dominant organs such as adipose and heart. To address this, we introduce Saliency-Guided Masking (SGM), which uses the model attention distribution to adaptively mask dominant organs during pre-training, thus encouraging more balanced cross-organ, whole-body learning. Notably, SGM introduces negligible computational overhead and can be seamlessly integrated into existing self-supervised learning frameworks to improve multi-organ representation learning. On the UK Biobank, Pan-FM achieves stronger prediction across 13 disease categories and 14 single disease entities than single-organ and multi-organ baselines, with improved robustness under missing-organ settings. Pan-FM serves as a scalable solution to realistic modality-missingness in multimodal learning in system neuroscience and as a step toward more generalizable whole-body FMs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes Pan-FM, a pan-organ foundation model pre-trained on imaging from seven organs (Brain, Heart, Adipose, Liver, Kidney, Spleen, Pancreas) using a unified backbone that accommodates missing organs during training and inference, combined with masking-based self-distillation. It identifies dominant-organ shortcut learning in naive multimodal pre-training and introduces Saliency-Guided Masking (SGM), which adaptively masks organs based on the model's attention distribution to encourage balanced whole-body representations. The central empirical claim is that Pan-FM outperforms single-organ and multi-organ baselines in predicting 13 disease categories and 14 single disease entities on UK Biobank data, with improved robustness under missing-organ settings.
Significance. If the performance gains and robustness claims hold under rigorous validation, this work would advance multimodal foundation models in medical imaging by directly tackling realistic missing-modality bias and shortcut learning, a practical barrier in whole-body and system-neuroscience applications. The negligible overhead of SGM and its seamless integration into existing SSL frameworks are practical strengths that could facilitate adoption.
major comments (2)
- [Results (UK Biobank experiments) and Methods (SGM description)] The attribution of performance gains and missing-organ robustness specifically to SGM (rather than the unified backbone or data volume) is load-bearing but unsupported by direct evidence. No pre/post-SGM attention entropy per organ, organ-wise feature importance on held-out tasks, or ablation of prediction performance under targeted organ occlusion is reported, leaving open the possibility that gains arise from other factors.
- [Methods (Saliency-Guided Masking) and Results (ablation studies)] The claim that SGM 'correctly identify[s] dominance without circular reinforcement' requires validation that the attention-derived masks do not simply reinforce the model's initial biases; without metrics showing increased cross-organ balance (e.g., reduced dominance of adipose/heart in downstream features), the mechanism remains unverified.
minor comments (2)
- [Abstract] The abstract states empirical gains but supplies no quantitative results, baselines, statistical tests, or error bars; including at least headline numbers (e.g., AUC improvements or p-values) would strengthen the summary.
- [Methods] Notation for the unified backbone and self-distillation loss should be introduced with explicit equations to clarify how missing-organ handling is implemented at both training and inference stages.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment below, clarifying the role of our experiments and outlining revisions to provide stronger direct evidence for the contribution of Saliency-Guided Masking.
read point-by-point responses
-
Referee: [Results (UK Biobank experiments) and Methods (SGM description)] The attribution of performance gains and missing-organ robustness specifically to SGM (rather than the unified backbone or data volume) is load-bearing but unsupported by direct evidence. No pre/post-SGM attention entropy per organ, organ-wise feature importance on held-out tasks, or ablation of prediction performance under targeted organ occlusion is reported, leaving open the possibility that gains arise from other factors.
Authors: We appreciate this observation. Our multi-organ baseline employs the identical unified backbone, training data volume, and missing-organ handling as Pan-FM, differing only in the absence of SGM; performance differences are therefore attributable to SGM. Nevertheless, we agree that additional direct metrics would strengthen the attribution. In the revision we will report pre- and post-SGM attention entropy per organ, organ-wise feature importance on held-out tasks, and prediction performance under targeted organ occlusion. revision: yes
-
Referee: [Methods (Saliency-Guided Masking) and Results (ablation studies)] The claim that SGM 'correctly identify[s] dominance without circular reinforcement' requires validation that the attention-derived masks do not simply reinforce the model's initial biases; without metrics showing increased cross-organ balance (e.g., reduced dominance of adipose/heart in downstream features), the mechanism remains unverified.
Authors: We acknowledge that explicit verification of the mechanism is warranted. While our existing ablation studies demonstrate downstream performance gains when SGM is applied, we agree that quantitative confirmation of increased cross-organ balance is needed to rule out reinforcement of initial biases. We will add metrics in the revised manuscript, including changes in organ dominance within downstream features and attention distributions before versus after SGM, to verify the balanced learning effect. revision: yes
Circularity Check
No circularity: empirical method proposal with no self-referential derivations
full rationale
The paper introduces Pan-FM as a practical architecture with a new pre-training component (Saliency-Guided Masking) that adaptively masks based on attention maps to mitigate observed dominant-organ bias. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text; the central claims rest on downstream empirical comparisons to single- and multi-organ baselines on UK Biobank data under missing-organ conditions. The method is presented as an added engineering choice rather than a quantity derived from its own outputs, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce Saliency-Guided Masking (SGM), which uses the model attention distribution to adaptively mask dominant organs during pre-training, thus encouraging more balanced cross-organ, whole-body learning.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Pan-FM achieves stronger prediction across 13 disease categories and 14 single disease entities than single-organ and multi-organ baselines, with improved robustness under missing-organ settings.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Quantifying attention flow in transformers
Samira Abnar and Willem Zuidema. Quantifying attention flow in transformers. InProceedings of the 58th annual meeting of the association for computational linguistics, pages 4190–4197, 2020
work page 2020
-
[2]
arXiv preprint arXiv:2511.17803 (2025)
Kumar Krishna Agrawal, Longchao Liu, Long Lian, Michael Nercessian, Natalia Harguindeguy, Yufu Wu, Peter Mikhael, Gigin Lin, Lecia V Sequist, Florian Fintelmann, et al. Pillar-0: A new frontier for radiology foundation models.arXiv preprint arXiv:2511.17803, 2025
-
[3]
Self-supervised learning from images with a joint- embedding predictive architecture
Mahmoud Assran, Quentin Duval, Ishan Misra, Piotr Bojanowski, Pascal Vincent, Michael Rabbat, Yann LeCun, and Nicolas Ballas. Self-supervised learning from images with a joint- embedding predictive architecture. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15619–15629, 2023
work page 2023
-
[4]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Beit: Bert pre-training of image trans- formers
Hangbo Bao, Li Dong, Songhao Piao, and Furu Wei. Beit: Bert pre-training of image trans- formers. 2021
work page 2021
-
[6]
Anatomical foundation models for brain mris.Pattern Recognition Letters, 2025
Carlo Alberto Barbano, Matteo Brunello, Benoit Dufumier, Marco Grangetto, Alzheimer’s Disease Neuroimaging Initiative, et al. Anatomical foundation models for brain mris.Pattern Recognition Letters, 2025
work page 2025
-
[7]
Variance-invariance-covariance regularization for self-supervised learning
Adrien Bardes, Jean Ponce, and Yann LeCun. Variance-invariance-covariance regularization for self-supervised learning. 2022
work page 2022
-
[8]
A pan-organ vision- language model for generalizable 3d ct representations.medRxiv, 2025
Cameron Beeche, Joonghyun Kim, Hamed Tavolinejad, Bingxin Zhao, Rakesh Sharma, Jeffrey Duda, James Gee, Farouk Dako, Anurag Verma, Colleen Morse, et al. A pan-organ vision- language model for generalizable 3d ct representations.medRxiv, 2025
work page 2025
-
[9]
The uk biobank resource with deep phenotyping and genomic data.Nature, 562(7726):203–209, 2018
Clare Bycroft, Colin Freeman, Desislava Petkova, Gavin Band, Lloyd T Elliott, Kevin Sharp, Allan Motyer, Damjan Vukcevic, Olivier Delaneau, Jared O’Connell, et al. The uk biobank resource with deep phenotyping and genomic data.Nature, 562(7726):203–209, 2018
work page 2018
-
[10]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
work page 2021
-
[11]
Chen, Chengkuan Chen, Yicong Li, et al
Richard J. Chen, Chengkuan Chen, Yicong Li, et al. Scaling vision transformers to gigapixel images via hierarchical self-supervised learning. InCVPR, 2022
work page 2022
-
[12]
Richard J Chen, Tong Ding, Ming Y Lu, Drew FK Williamson, Guillaume Jaume, Andrew H Song, Bowen Chen, Andrew Zhang, Daniel Shao, Muhammad Shaban, et al. Towards a general- purpose foundation model for computational pathology.Nature medicine, 30(3):850–862, 2024
work page 2024
-
[13]
A simple framework for contrastive learning of visual representations
Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning of visual representations. InInternational conference on machine learning, pages 1597–1607. PmLR, 2020
work page 2020
-
[14]
Exploring simple siamese representation learning
Xinlei Chen and Kaiming He. Exploring simple siamese representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 15750–15758, 2021
work page 2021
-
[15]
An empirical study of training self-supervised vision transformers
Xinlei Chen, Saining Xie, and Kaiming He. An empirical study of training self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9640–9649, 2021
work page 2021
-
[16]
EchoCLIP: Vision-language foundation model for echocardiography
Matthew Christensen et al. EchoCLIP: Vision-language foundation model for echocardiography. Nature Medicine, 2024. 11
work page 2024
-
[17]
MULTI consortium, Filippos Anagnostakis, Sarah Ko, Mehrshad Saadatinia, Jingyue Wang, Christos Davatzikos, and Junhao Wen. Multi-organ metabolome biological age implicates cardiometabolic conditions and mortality risk.Nature Communications, 16(1):4871, 2025
work page 2025
-
[18]
Brain–heart–eye axis revealed by multi-organ imaging genetics and proteomics
MULTI Consortium, Aleix Boquet-Pujadas, Filippos Anagnostakis, Michael R Duggan, Cas- sandra M Joynes, Arthur W Toga, Zhijian Yang, Keenan A Walker, Christos Davatzikos, and Junhao Wen. Brain–heart–eye axis revealed by multi-organ imaging genetics and proteomics. Nature Biomedical Engineering, pages 1–23, 2025
work page 2025
-
[19]
Multi-organ ai endophenotypes chart the heterogeneity of brain, eye and heart pan-disease
MULTI Consortium, Aleix Boquet-Pujadas, Filippos Anagnostakis, Zhijian Yang, Ye Ella Tian, Michael R Duggan, Guray Erus, Dhivya Srinivasan, Cassandra M Joynes, Wenjia Bai, et al. Multi-organ ai endophenotypes chart the heterogeneity of brain, eye and heart pan-disease. Nature Mental Health, pages 1–28, 2026
work page 2026
-
[20]
MULTI Consortium, Huizi Cao, Zhiyuan Song, Michael R Duggan, Guray Erus, Dhivya Srinivasan, Ye Ella Tian, Wenjia Bai, Michael S Rafii, Paul Aisen, et al. Mri-based multi-organ clocks for healthy aging and disease assessment.Nature Medicine, 32(1):82–92, 2026
work page 2026
-
[21]
Jimit Doshi, Guray Erus, Yangming Ou, Susan M Resnick, Ruben C Gur, Raquel E Gur, Theodore D Satterthwaite, Susan Furth, Christos Davatzikos, Alzheimer’s Neuroimaging Initia- tive, et al. Muse: Multi-atlas region segmentation utilizing ensembles of registration algorithms and parameters, and locally optimal atlas selection.Neuroimage, 127:186–195, 2016
work page 2016
-
[22]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[23]
Bootstrap your own latent-a new approach to self-supervised learning
Jean-Bastien Grill, Florian Strub, Florent Altché, Corentin Tallec, Pierre Richemond, Elena Buchatskaya, Carl Doersch, Bernardo Avila Pires, Zhaohan Guo, Mohammad Gheshlaghi Azar, et al. Bootstrap your own latent-a new approach to self-supervised learning. volume 33, pages 21271–21284, 2020
work page 2020
-
[24]
Momentum contrast for unsupervised visual representation learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross Girshick. Momentum contrast for unsupervised visual representation learning. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9729–9738, 2020
work page 2020
-
[25]
Masked autoencoders are scalable vision learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, and Ross Girshick. Masked autoencoders are scalable vision learners. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 16000–16009, 2022
work page 2022
-
[26]
Jiao Jiao et al. USFM: A universal ultrasound foundation model generalized to tasks and organs within 15 populations.Medical Image Analysis, 2024
work page 2024
-
[27]
What to hide from your students: Attention-guided masked image modeling
Ioannis Kakogeorgiou, Spyros Gidaris, Bill Psomas, Yannis Avrithis, Andrei Bursuc, Konstanti- nos Karantzalos, and Nikos Komodakis. What to hide from your students: Attention-guided masked image modeling. InEuropean Conference on Computer Vision, pages 300–318. Springer, 2022
work page 2022
-
[28]
A foundation model for clinical-grade dermatology.Nature Medicine, 2024
Chanwoo Kim et al. A foundation model for clinical-grade dermatology.Nature Medicine, 2024
work page 2024
-
[29]
Gang Li, Heliang Zheng, Daqing Liu, Chaoyue Wang, Bing Su, and Changwen Zheng. Semmae: Semantic-guided masking for learning masked autoencoders.Advances in Neural Information Processing Systems, 35:14290–14302, 2022
work page 2022
-
[30]
Segment anything in medical images.Nature Communications, 2024
Jun Ma, Bo Wang, et al. Segment anything in medical images.Nature Communications, 2024
work page 2024
-
[31]
Towards generalisable foundation models for brain mri.arXiv preprint arXiv:2510.23415, 2025
Moona Mazher, Geoff JM Parker, and Daniel C Alexander. Towards generalisable foundation models for brain mri.arXiv preprint arXiv:2510.23415, 2025
-
[32]
Celeste McCracken, Zahra Raisi-Estabragh, Michele Veldsman, Betty Raman, Andrea Dennis, Masud Husain, Thomas E Nichols, Steffen E Petersen, and Stefan Neubauer. Multi-organ imag- ing demonstrates the heart-brain-liver axis in uk biobank participants.Nature Communications, 13(1):7839, 2022. 12
work page 2022
-
[33]
Xueyan Mei, Zelong Liu, Philip M Robson, Brett Marinelli, Mingqian Huang, Amish Doshi, Adam Jacobi, Chendi Cao, Katherine E Link, Thomas Yang, et al. Radimagenet: an open radiologic deep learning research dataset for effective transfer learning.Radiology: Artificial Intelligence, 4(5):e210315, 2022
work page 2022
-
[34]
American Heart Association Writing Group on Myocardial Segmentation, Registration for Cardiac Imaging:, Manuel D Cerqueira, Neil J Weissman, Vasken Dilsizian, Alice K Jacobs, Sanjiv Kaul, Warren K Laskey, Dudley J Pennell, John A Rumberger, Thomas Ryan, et al. Standardized myocardial segmentation and nomenclature for tomographic imaging of the heart: a st...
work page 2002
-
[35]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Ronald Carl Petersen, Paul S Aisen, Laurel A Beckett, Michael C Donohue, Anthony Collins Gamst, Danielle J Harvey, Clifford R Jack Jr, William J Jagust, Leslie M Shaw, Arthur W Toga, et al. Alzheimer’s disease neuroimaging initiative (adni) clinical characterization.Neurology, 74(3):201–209, 2010
work page 2010
-
[37]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PmLR, 2021
work page 2021
-
[38]
Mm-dinov2: Adapting foundation models for multi-modal medical image analysis
Daniel Scholz, Ayhan Can Erdur, Viktoria Ehm, Anke Meyer-Baese, Jan C Peeken, Daniel Rueckert, and Benedikt Wiestler. Mm-dinov2: Adapting foundation models for multi-modal medical image analysis. InInternational Conference on Medical Image Computing and Computer-Assisted Intervention, pages 320–330. Springer, 2025
work page 2025
-
[39]
Rohan Shad, Cyril Zakka, Dhamanpreet Kaur, Mrudang Mathur, Robyn Fong, Joseph Cho, Ross Warren Filice, John Mongan, Kimberly Kallianos, Nishith Khandwala, et al. A gener- alizable deep learning system for cardiac mri.Nature Biomedical Engineering, pages 1–16, 2026
work page 2026
-
[40]
Danli Shi, Weiyi Zhang, Jiancheng Yang, Siyu Huang, Xiaolan Chen, Pusheng Xu, Kai Jin, Shan Lin, Jin Wei, Mayinuer Yusufu, et al. A multimodal visual–language foundation model for computational ophthalmology.npj digital medicine, 8(1):381, 2025
work page 2025
-
[41]
Divyanshu Tak, Biniam A Garomsa, Anna Zapaishchykova, Tafadzwa L Chaunzwa, Juan Carlos Climent Pardo, Zezhong Ye, John Zielke, Yashwanth Ravipati, Suraj Pai, Sri Vajapeyam, et al. A generalizable foundation model for analysis of human brain mri.Nature Neuroscience, pages 1–12, 2026
work page 2026
-
[42]
Ye Ella Tian, Vanessa Cropley, Andrea B Maier, Nicola T Lautenschlager, Michael Breakspear, and Andrew Zalesky. Heterogeneous aging across multiple organ systems and prediction of chronic disease and mortality.Nature medicine, 29(5):1221–1231, 2023
work page 2023
-
[43]
Ekin Tiu, Ellie Talius, Pujan Patel, Curtis P Langlotz, Andrew Y Ng, and Pranav Rajpurkar. Expert-level detection of pathologies from unannotated chest x-ray images via self-supervised learning.Nature biomedical engineering, 6(12):1399–1406, 2022
work page 2022
-
[44]
Eugene V orontsov, Alican Bozkurt, Adam Casson, et al. A foundation model for clinical-grade computational pathology and rare cancers detection.Nature Medicine, 2024
work page 2024
-
[45]
Hard patches mining for masked image modeling
Haochen Wang, Kaiyou Song, Junsong Fan, Yuxi Wang, Jin Xie, and Zhaoxiang Zhang. Hard patches mining for masked image modeling. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10375–10385, 2023
work page 2023
-
[46]
Shansong Wang, Mojtaba Safari, Qiang Li, Chih-Wei Chang, Richard LJ Qiu, Justin Roper, David S Yu, and Xiaofeng Yang. Triad: Vision foundation model for 3d magnetic resonance imaging.arXiv preprint arXiv:2502.14064, 2025. 13
-
[47]
Xiyue Wang, Sen Yang, Jun Zhang, et al. Transformer-based unsupervised contrastive learning for histopathological image classification.Medical Image Analysis, 2022
work page 2022
-
[48]
MedCLIP: Contrastive learning from unpaired medical images and text
Zifeng Wang, Zhenbang Wu, Dinesh Agarwal, and Jimeng Sun. MedCLIP: Contrastive learning from unpaired medical images and text. 2022
work page 2022
-
[49]
Hao Wei, Bowen Liu, Minqing Zhang, Peilun Shi, and Wu Yuan. Visionclip: An med-aigc based ethical language-image foundation model for generalizable retina image analysis.arXiv preprint arXiv:2403.10823, 2024
-
[50]
Biological age shows that no organ system is an island.Nature, 4:1182–1183, 2024
Junhao Wen. Biological age shows that no organ system is an island.Nature, 4:1182–1183, 2024
work page 2024
-
[51]
Multi-organ and multi-omics aging clocks digitize human biological age.medRxiv, pages 2025–02, 2025
Junhao Wen. Multi-organ and multi-omics aging clocks digitize human biological age.medRxiv, pages 2025–02, 2025
work page 2025
-
[52]
Junhao Wen. Refining the generation, interpretation and application of multi-organ, multi-omics biological aging clocks.Nature Aging, 5(9):1897–1913, 2025
work page 1913
-
[53]
Junhao Wen. Towards a multi-organ, multi-omics medical digital twin.Nature Biomedical Engineering, 9(9):1386–1389, 2025
work page 2025
-
[54]
Junhao Wen, Ye Ella Tian, Ioanna Skampardoni, Zhijian Yang, Yuhan Cui, Filippos Anagnos- takis, Elizabeth Mamourian, Bingxin Zhao, Arthur W Toga, Andrew Zalesky, et al. The genetic architecture of biological age in nine human organ systems.Nature aging, 4(9):1290–1307, 2024
work page 2024
-
[55]
Chaoyi Wu et al. Towards generalist foundation model for radiology.arXiv preprint arXiv:2308.02463, 2023
-
[56]
Progressive unsupervised learning for visual object tracking
Qiangqiang Wu, Jia Wan, and Antoni B Chan. Progressive unsupervised learning for visual object tracking. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 2993–3002, 2021
work page 2021
-
[57]
Dropmae: Masked autoencoders with spatial-attention dropout for tracking tasks
Qiangqiang Wu, Tianyu Yang, Ziquan Liu, Baoyuan Wu, Ying Shan, and Antoni B Chan. Dropmae: Masked autoencoders with spatial-attention dropout for tracking tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14561–14571, 2023
work page 2023
-
[58]
Simmim: A simple framework for masked image modeling
Zhenda Xie, Zheng Zhang, Yue Cao, Yutong Lin, Jianmin Bao, Zhuliang Yao, Qi Dai, and Han Hu. Simmim: A simple framework for masked image modeling. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9653–9663, 2022
work page 2022
-
[59]
Zhijian Yang, Noel DSouza, Istvan Megyeri, Xiaojian Xu, Amin Honarmandi Shandiz, Farzin Haddadpour, Krisztian Koos, Laszlo Rusko, Emanuele Valeriano, Bharadwaj Swaminathan, et al. Decipher-mr: a vision-language foundation model for 3d mri representations.npj Digital Medicine, 2026
work page 2026
-
[60]
Barlow twins: Self- supervised learning via redundancy reduction
Jure Zbontar, Li Jing, Ishan Misra, Yann LeCun, and Stéphane Deny. Barlow twins: Self- supervised learning via redundancy reduction. InInternational conference on machine learning, pages 12310–12320. PMLR, 2021
work page 2021
-
[61]
On the foundation model for cardiac mri reconstruction
Chi Zhang, Michael Loecher, Cagan Alkan, Mahmut Yurt, Shreyas S Vasanawala, and Daniel B Ennis. On the foundation model for cardiac mri reconstruction. InInternational Workshop on Statistical Atlases and Computational Models of the Heart, pages 226–235. Springer, 2024
work page 2024
-
[62]
Kai Zhang et al. BiomedGPT: A generalist vision–language foundation model for diverse biomedical tasks.arXiv preprint arXiv:2305.17100, 2023
-
[63]
Sheng Zhang, Yanbo Xu, Naoto Usuyama, Hanwen Xu, Jaspreet Bagga, Robert Tinn, Sam Preston, Rajesh Rao, Mu Wei, Naveen Valluri, et al. Biomedclip: a multimodal biomedical foundation model pretrained from fifteen million scientific image-text pairs.arXiv preprint arXiv:2303.00915, 2023. 14
work page internal anchor Pith review arXiv 2023
-
[64]
ibot: Image bert pre-training with online tokenizer
Jinghao Zhou, Chen Wei, Huiyu Wang, Wei Shen, Cihang Xie, Alan Yuille, and Tao Kong. ibot: Image bert pre-training with online tokenizer. 2021
work page 2021
-
[65]
Yukun Zhou, Mark A Chia, Siegfried K Wagner, Murat S Ayhan, Dominic J Williamson, Robbert R Struyven, Timing Liu, Moucheng Xu, Mateo G Lozano, Peter Woodward-Court, et al. A foundation model for generalizable disease detection from retinal images.Nature, 622 (7981):156–163, 2023. 15 Appendix Contents A Data Details 16 A.1 Dataset . . . . . . . . . . . . ....
work page 2023
-
[66]
All baselines and our Pan-FM are evaluated under this same protocol for fair comparison. Each linear probe is trained with 10 different random seeds, and we report the average performance on the held-out test set. Full Backbone Fine-tuning. We additionally evaluate each pre-trained backbone under the end-to- end fine-tuning protocol. For each downstream d...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.