Recognition: no theorem link
Every Feedforward Neural Network Definable in an o-Minimal Structure Has Finite Sample Complexity
Pith reviewed 2026-05-11 01:02 UTC · model grok-4.3
The pith
Every fixed feedforward neural network with o-minimal definable layers has finite sample complexity in the agnostic PAC setting, even with unbounded parameters.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
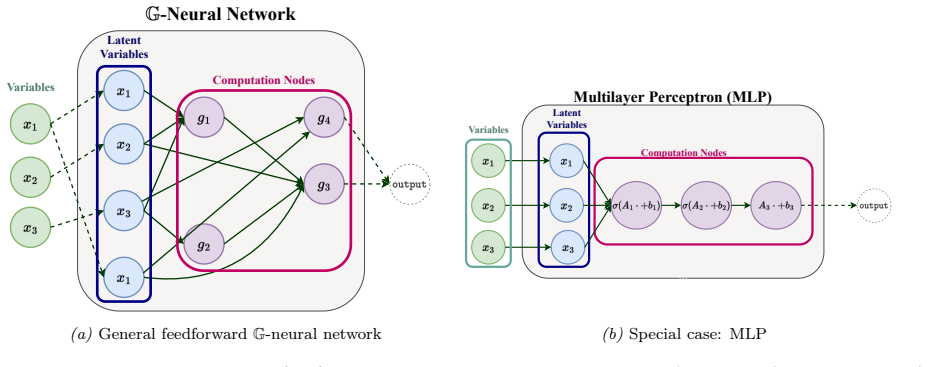
We show that, in a precise sense, a broad class of feedforward neural networks learn (have finite sample complexity) in the PAC model: every fixed finite feedforward architecture whose layers are definable in an o-minimal structure has finite sample complexity in the agnostic PAC setting, even with unbounded parameters. This covers standard fixed-size MLPs, CNNs, GNNs, and transformers with fixed sequence length, together with the operations and layers typically used in such architectures, including linear projections, residual connections, attention mechanisms, pooling layers, normalization layers, and admissible positional encodings. Hence, distribution-free learnability for modern non-re
What carries the argument
O-minimal definability of layer functions and its preservation under standard network operations, which guarantees finite sample complexity for the resulting hypothesis class.
Load-bearing premise
That definability in an o-minimal structure for each layer is preserved through all the compositions and operations in the full architecture, and that such definability ensures finite sample complexity in the agnostic PAC model.
What would settle it
Finding a counterexample fixed feedforward architecture with o-minimal definable layers but without finite sample complexity in the agnostic PAC setting.
Figures
read the original abstract
We show that, in a precise sense, a broad class of feedforward neural networks learn (have finite sample complexity) in the PAC model: every fixed finite feedforward architecture whose layers are definable in an o-minimal structure has finite sample complexity in the agnostic PAC setting, even with unbounded parameters. This covers standard fixed-size MLPs, CNNs, GNNs, and transformers with fixed sequence length, together with the operations and layers typically used in such architectures, including linear projections, residual connections, attention mechanisms, pooling layers, normalization layers, and admissible positional encodings. Hence, distribution-free learnability for modern non-recurrent architectures is not an exceptional property of particular activations or architecture-specific VC arguments, but a consequence of tame feedforward computation. Our results reposition finite-sample PAC learnability as a baseline rather than a differentiator: they shift the focus of architectural comparison toward inductive biases, symmetries and geometric priors, scalability, and optimization behaviour.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proves that every fixed finite feedforward neural network whose layers are definable in an o-minimal structure has finite sample complexity in the agnostic PAC model, even with unbounded parameters. This covers standard MLPs, CNNs, GNNs, and fixed-sequence-length transformers using operations including linear projections, residual connections, attention, pooling, normalization, and admissible positional encodings. The argument proceeds by showing that the parameterized input-to-output map is definable in a suitable o-minimal expansion of the reals (such as the semialgebraic or R_exp structure), which implies that the function class has finite VC-dimension or pseudo-dimension by model-theoretic results, and hence finite agnostic PAC sample complexity.
Significance. If the central theorem holds, the result supplies a unified, architecture-independent explanation for the PAC learnability of modern feedforward networks, deriving finite sample complexity directly from the tameness of definable computation rather than case-by-case VC calculations. It repositions learnability as a baseline property of fixed finite architectures and shifts emphasis to inductive biases, symmetries, optimization, and scalability. The approach leverages standard facts from o-minimality theory and PAC learning without introducing new parameters or bounds.
major comments (2)
- [§3] §3 (Main Theorem): The preservation of definability under composition, finite sums, and projections is invoked to conclude that the full network map remains definable; while this follows from the general properties of o-minimal structures, the manuscript should explicitly verify that the specific operations listed (e.g., softmax in attention and layer-norm) are definable in the chosen expansion before applying the VC-finiteness theorem.
- [§4.2] §4.2 (Examples): The treatment of GNNs and transformers assumes fixed graph or sequence size to keep the architecture finite; the finite-sample-complexity claim would be strengthened by a brief remark confirming that this fixed-size restriction is maintained throughout the definability argument.
minor comments (3)
- [Abstract] Abstract: The qualifier 'in a precise sense' should be expanded to name the model-theoretic theorem (finite VC-dimension for definable families) that bridges o-minimality to PAC sample complexity.
- [Introduction] Introduction: Include a short reference to the foundational results on o-minimal structures (e.g., van den Dries or Pillay-Steinhorn) and to the standard PAC theorem relating pseudo-dimension to agnostic sample complexity.
- [Notation] Notation: Ensure consistent use of 'definable family' versus 'parameterized function class' when moving between model theory and learning-theoretic statements.
Simulated Author's Rebuttal
We thank the referee for the supportive summary and recommendation of minor revision. The comments are helpful for improving clarity. We address each major comment below.
read point-by-point responses
-
Referee: [§3] §3 (Main Theorem): The preservation of definability under composition, finite sums, and projections is invoked to conclude that the full network map remains definable; while this follows from the general properties of o-minimal structures, the manuscript should explicitly verify that the specific operations listed (e.g., softmax in attention and layer-norm) are definable in the chosen expansion before applying the VC-finiteness theorem.
Authors: We agree that adding explicit verification improves self-containment. In the revised §3 we will insert a short paragraph confirming that the listed operations (softmax via exponentials and normalization, layer-norm via arithmetic means/variances and divisions, attention via the same, etc.) are definable in the semialgebraic structure or in R_exp, as appropriate, prior to invoking the model-theoretic VC/pseudo-dimension results. This uses only standard facts already implicit in the paper. revision: yes
-
Referee: [§4.2] §4.2 (Examples): The treatment of GNNs and transformers assumes fixed graph or sequence size to keep the architecture finite; the finite-sample-complexity claim would be strengthened by a brief remark confirming that this fixed-size restriction is maintained throughout the definability argument.
Authors: We thank the referee for the suggestion. The fixed-size restriction is part of the problem statement (fixed finite architecture) and is preserved by construction in the definability argument. We will add one clarifying sentence in §4.2 stating that the fixed graph or sequence length is maintained throughout the composition, so that the overall input-to-output map remains a finite definable function in the chosen o-minimal structure. revision: yes
Circularity Check
No circularity; derivation relies on external model-theoretic facts
full rationale
The paper establishes that definability of each layer operation in an o-minimal structure is preserved under the finite compositions, sums, and projections that define a fixed feedforward architecture. It then invokes the standard, externally established theorem that any definable family in an o-minimal structure has finite VC-dimension (or pseudo-dimension). This directly yields finite agnostic PAC sample complexity without parameter bounds. No equation or step equates the target conclusion to a fitted quantity, a self-referential definition, or a load-bearing self-citation whose validity depends on the present work. The argument is therefore self-contained against independent benchmarks from model theory and statistical learning theory.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Definable sets and functions in an o-minimal structure yield function classes with finite sample complexity in the agnostic PAC model
Reference graph
Works this paper leans on
-
[1]
Open prob- lem: Are all VC-classes CPAC learnable? InProceedings of the 34th Conference on Learning Theory, volume 134 ofProceedings of Machine Learning Research, pages 4636–4641
Sushant Agarwal, Nivasini Ananthakrishnan, Shai Ben-David, Tosca Lechner, and Ruth Urner. Open prob- lem: Are all VC-classes CPAC learnable? InProceedings of the 34th Conference on Learning Theory, volume 134 ofProceedings of Machine Learning Research, pages 4636–4641. PMLR, 2021
2021
-
[2]
Scale-sensitive dimensions, uniform convergence, and learnability.J
Noga Alon, Shai Ben-David, Nicolò Cesa-Bianchi, and David Haussler. Scale-sensitive dimensions, uniform convergence, and learnability.J. ACM, 44(4):615–631, 1997
1997
-
[3]
Zico Kolter
Brandon Amos and J. Zico Kolter. OptNet: Differentiable optimization as a layer in neural networks. In Proceedings of the 34th International Conference on Machine Learning, volume 70 ofProceedings of Machine Learning Research, pages 136–145. PMLR, 2017
2017
-
[4]
Bartlett.Neural Network Learning: Theoretical Foundations
Martin Anthony and Peter L. Bartlett.Neural Network Learning: Theoretical Foundations. Cambridge University Press, Cambridge, 1999
1999
-
[5]
Optimal learners for realizable regression: PAC learning and online learning
Idan Attias, Steve Hanneke, Alkis Kalavasis, Amin Karbasi, and Grigoris Velegkas. Optimal learners for realizable regression: PAC learning and online learning. InThirty-seventh Conference on Neural Information Processing Systems, 2023
2023
-
[6]
Jimmy Lei Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer normalization.arXiv preprint arXiv:1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[7]
Neural machine translation by jointly learning to align and translate
Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. Neural machine translation by jointly learning to align and translate. InICLR, 2015
2015
-
[8]
Deepequilibriummodels
ShaojieBai, J.ZicoKolter, andVladlenKoltun. Deepequilibriummodels. InAdvances in Neural Information Processing Systems, volume 32, 2019
2019
-
[9]
Springer Science & Business Media, 2008
Jørgen Bang-Jensen and Gregory Z Gutin.Digraphs: Theory, Algorithms and Applications. Springer Science & Business Media, 2008
2008
-
[10]
P. L. Bartlett, S. R. Kulkarni, and S. E. Posner. Covering numbers for real-valued function classes.IEEE Trans. Inform. Theory, 43(5):1721–1724, 1997
1997
-
[11]
Bartlett and Wolfgang Maass
Peter L. Bartlett and Wolfgang Maass. Vapnik-Chervonenkis dimension of neural nets. In Michael A. Arbib, editor,The Handbook of Brain Theory and Neural Networks, pages 1188–1192. MIT Press, 2 edition, 2003
2003
-
[12]
Bartlett, Nick Harvey, Christopher Liaw, and Abbas Mehrabian
Peter L. Bartlett, Nick Harvey, Christopher Liaw, and Abbas Mehrabian. Nearly-tight VC-dimension and pseudodimension bounds for piecewise linear neural networks.J. Mach. Learn. Res., 20:63:1–63:17, 2019
2019
-
[13]
Tameness in geometry and arithmetic: beyond o-minimality
Gal Binyamini and Dmitry Novikov. Tameness in geometry and arithmetic: beyond o-minimality. InInter- national Congress of Mathematicians, pages 1440–1461. European Mathematical Society-EMS-Publishing House GmbH, 2023
2023
-
[14]
Gal Binyamini, Dmitri Novikov, and Benny Zack. Sharply o-minimal structures and sharp cellular decom- position.arXiv preprint arXiv:2209.10972, 2022. 10
-
[15]
Wilkie’s conjecture for Pfaffian structures.Annals of Mathematics, 199(2):795–821, 2024
Gal Binyamini, Dmitry Novikov, and Benny Zak. Wilkie’s conjecture for Pfaffian structures.Annals of Mathematics, 199(2):795–821, 2024
2024
-
[16]
Anselm Blumer, Andrzej Ehrenfeucht, David Haussler, and Manfred K. Warmuth. Learnability and the Vapnik-Chervonenkis dimension.Journal of the ACM, 36(4):929–965, 1989
1989
-
[17]
A fine-grained characterization of PAC learnability
Marco Bressan, Nataly Brukhim, Nicolò Cesa-Bianchi, Emmanuel Esposito, Yishay Mansour, Shay Moran, and Maximilian Thiessen. A fine-grained characterization of PAC learnability. InCOLT, Proceedings of Machine Learning Research, pages 641–676. PMLR, 2025
2025
-
[18]
Bronstein, Joan Bruna, Yann LeCun, Arthur Szlam, and Pierre Vandergheynst
Michael M. Bronstein, Joan Bruna, Yann LeCun, Arthur Szlam, and Pierre Vandergheynst. Geometric deep learning: Going beyond Euclidean data.IEEE Signal Process. Mag., 34:18–42, 2016
2016
-
[19]
Geometric Deep Learning: Grids, Groups, Graphs, Geodesics, and Gauges
Michael M Bronstein, Joan Bruna, Taco Cohen, and Petar Veličković. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges.arXiv preprint arXiv:2104.13478, 2021
work page internal anchor Pith review arXiv 2021
-
[20]
Model theory and machine learning.Bulletin of Symbolic Logic, 25(3): 319–332, 2019
Hunter Chase and James Freitag. Model theory and machine learning.Bulletin of Symbolic Logic, 25(3): 319–332, 2019
2019
-
[21]
Ricky T. Q. Chen, Yulia Rubanova, Jesse Bettencourt, and David K. Duvenaud. Neural ordinary differential equations. InAdvances in Neural Information Processing Systems, volume 31, pages 6572–6583, 2018
2018
-
[22]
Transformers in Uniform TC0.Transactions on Machine Learning Research, 2025
David Chiang. Transformers in Uniform TC0.Transactions on Machine Learning Research, 2025
2025
-
[23]
Probabilistic circuits: A unifying framework for tractable probabilistic models.UCLA
Y Choi, Antonio Vergari, and Guy Van den Broeck. Probabilistic circuits: A unifying framework for tractable probabilistic models.UCLA. URL: http://starai.cs.ucla.edu/papers/ProbCirc20.pdf, 6, 2020
2020
-
[24]
Fast and accurate deep network learning by Exponential Linear Units (ELUs)
Djork-Arné Clevert, Thomas Unterthiner, and Sepp Hochreiter. Fast and accurate deep network learning by Exponential Linear Units (ELUs). InProceedings of the International Conference on Learning Represen- tations (ICLR), 2016
2016
-
[25]
Institut de Recherche Mathématique de Rennes (IRMAR), Rennes, France, 1999
Michel Coste.An Introduction to O-Minimal Geometry. Institut de Recherche Mathématique de Rennes (IRMAR), Rennes, France, 1999. Lecture notes
1999
-
[26]
Mathematical foundations of geometric deep learning
Haitz Sáez de Ocáriz Borde and Michael Bronstein. Mathematical foundations of geometric deep learning. arXiv preprint arXiv:2508.02723, 2025
-
[27]
DeepSeek-AI. DeepSeek-V3 technical report.CoRR, abs/2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[28]
Universal trans- formers
Mostafa Dehghani, Stephan Gouws, Oriol Vinyals, Jakob Uszkoreit, and Łukasz Kaiser. Universal trans- formers. InInternational Conference on Learning Representations, 2019
2019
-
[29]
Find a witness or shatter: the landscape of computable PAC learning
Valentino Delle Rose, Alexander Kozachinskiy, Cristóbal Rojas, and Tomasz Steifer. Find a witness or shatter: the landscape of computable PAC learning. InProceedings of the 36th Conference on Learning Theory, volume 195 ofProceedings of Machine Learning Research, pages 511–524. PMLR, 2023
2023
-
[30]
VC dimension of graph neural networks with Pfaffian activation functions.Neural Networks, 182:106924, 2025
Giuseppe Alessio D’Inverno, Monica Bianchini, and Franco Scarselli. VC dimension of graph neural networks with Pfaffian activation functions.Neural Networks, 182:106924, 2025
2025
-
[31]
Nan Du, Yanping Huang, Andrew M. Dai, Simon Tong, Dmitry Lepikhin, Yuanzhong Xu, Maxim Krikun, Yanqi Zhou, Adams Wei Yu, Orhan Firat, Barret Zoph, Liam Fedus, Maarten Bosma, Zongwei Zhou, Tao Wang, Yu Emma Wang, Kellie Webster, Marie Pellat, Kevin Robinson, Kathleen Meier-Hellstern, Toju Duke, Lucas Dixon, Kun Zhang, Quoc V Le, Yonghui Wu, Zhifeng Chen, a...
2022
-
[32]
Edelman, Surbhi Goel, Sham M
Benjamin L. Edelman, Surbhi Goel, Sham M. Kakade, and Cyril Zhang. Inductive biases and variable creation in self-attention mechanisms. InICML, Proceedings of Machine Learning Research, pages 5793–
-
[33]
Jeffrey L. Elman. Finding structure in time.Cognitive Science, 14(2):179–211, 1990
1990
-
[34]
Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position.Biological Cybernetics, 36(4):193–202, 1980
Kunihiko Fukushima. Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position.Biological Cybernetics, 36(4):193–202, 1980. 11
1980
-
[35]
Complexity of computations with Pfaffian and Noetherian functions
Andrei Gabrielov and Nicolai Vorobjov. Complexity of computations with Pfaffian and Noetherian functions. InNormal Forms, Bifurcations and Finiteness Problems in Differential Equations, volume 137 ofNATO Sci. Ser. II Math. Phys. Chem., pages 211–250. Kluwer Acad. Publ., Dordrecht, 2004
2004
-
[36]
Generalization and representational limits of graph neural networks
Vikas Garg, Stefanie Jegelka, and Tommi Jaakkola. Generalization and representational limits of graph neural networks. InProceedings of the 37th International Conference on Machine Learning, volume 119 of Proceedings of Machine Learning Research, pages 3419–3430. PMLR, 2020
2020
-
[37]
Lee, and Dimitris Papailiopou- los
Angeliki Giannou, Shashank Rajput, Jy-Yong Sohn, Kangwook Lee, Jason D. Lee, and Dimitris Papailiopou- los. Looped transformers as programmable computers. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 11398–11442. PMLR, 2023
2023
-
[38]
Deep sparse rectifier neural networks
Xavier Glorot, Antoine Bordes, and Yoshua Bengio. Deep sparse rectifier neural networks. InProceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, volume 15 ofProceedings of Machine Learning Research, pages 315–323. PMLR, 2011
2011
-
[39]
Goldberg and Mark R
Paul W. Goldberg and Mark R. Jerrum. Bounding the Vapnik-Chervonenkis dimension of concept classes parameterized by real numbers.Machine Learning, 18:131–148, 1995
1995
-
[40]
Gemma 4 model card.https://ai.google.dev/gemma/docs/core/model_card_4, 2026
Google. Gemma 4 model card.https://ai.google.dev/gemma/docs/core/model_card_4, 2026
2026
-
[41]
On the hardness of robust classification.Journal of Machine Learning Research, 22(273):1–29, 2021
Pascale Gourdeau, Varun Kanade, Marta Kwiatkowska, and James Worrell. On the hardness of robust classification.Journal of Machine Learning Research, 22(273):1–29, 2021
2021
-
[42]
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, Xiaokang Zhang, Xingkai Yu, Yu Wu, Z. F. Wu, Zhibin Gou, Zhihong Shao, Zhuoshu Li, Ziyi Gao, Aixin Liu, Bing Xue, Bingxuan Wang, Bochao Wu, Bei Feng, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chong Ruan, Damai Dai, Deli Chen, Dongjie Ji, ...
2025
-
[43]
Deep residual learning for image recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pages 770–778, 2016
2016
-
[44]
Gaussian Error Linear Units (GELUs)
Dan Hendrycks and Kevin Gimpel. Gaussian Error Linear Units (GELUs).arXiv preprint arXiv:1606.08415, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[45]
Long short-term memory.Neural Computation, 9(8):1735–1780, 1997
Sepp Hochreiter and Jürgen Schmidhuber. Long short-term memory.Neural Computation, 9(8):1735–1780, 1997. 12
1997
-
[46]
Batch normalization: Accelerating deep network training by reducing internal covariate shift
Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. InProceedings of the 32nd International Conference on Machine Learning, volume 37 ofProceedings of Machine Learning Research, pages 448–456. PMLR, 2015
2015
-
[47]
Albert Q Jiang, Alexandre Sablayrolles, Antoine Roux, Arthur Mensch, Blanche Savary, Chris Bamford, Devendra Singh Chaplot, Diego de las Casas, Emma Bou Hanna, Florian Bressand, et al. Mixtral of experts.arXiv preprint arXiv:2401.04088, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[48]
Springer, Heidel- berg, 2012
Stasys Jukna.Boolean Function Complexity, volume 27 ofAlgorithms and Combinatorics. Springer, Heidel- berg, 2012. Advances and frontiers
2012
-
[49]
Tropical circuit complexity.Limits of Pure Dynamic Programming/by Stasys Jukna, 2, 2023
Stasys Jukna. Tropical circuit complexity.Limits of Pure Dynamic Programming/by Stasys Jukna, 2, 2023
2023
-
[50]
Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei
Jared Kaplan, Sam McCandlish, Tom Henighan, Tom B. Brown, Benjamin Chess, Rewon Child, Scott Gray, Alec Radford, Jeffrey Wu, and Dario Amodei. Scaling laws for neural language models, 2020
2020
-
[51]
Polynomial bounds for VC dimension of sigmoidal and general Pfaffian neural networks.Journal of Computer and System Sciences, 54(1):169–176, 1997
Marek Karpinski and Angus Macintyre. Polynomial bounds for VC dimension of sigmoidal and general Pfaffian neural networks.Journal of Computer and System Sciences, 54(1):169–176, 1997
1997
-
[52]
Kearns and Robert E
Michael J. Kearns and Robert E. Schapire. Efficient distribution-free learning of probabilistic concepts.J. Comput. Syst. Sci., 48(3):464–497, 1994
1994
-
[53]
A. G. Khovanski˘i.Fewnomials, volume 88 ofTranslations of Mathematical Monographs. American Mathe- matical Society, Providence, RI, 1991. Translated from the Russian by Smilka Zdravkovska
1991
-
[54]
Anastasis Kratsios, Dennis Zvigelsky, and Bradd Hart. Quantifying the limits of AI reasoning: Systematic neural network representations of algorithms.arXiv preprint arXiv:2508.18526, 2025
-
[55]
Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton. Imagenet classification with deep convolutional neural networks. InNIPS, pages 1106–1114, 2012
2012
-
[56]
Laskowski
Michael C. Laskowski. Vapnik-Chervonenkis classes of definable sets.Journal of the London Mathematical Society, 45(2):377–384, 1992
1992
-
[57]
Gradient-based learning applied to docu- ment recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to docu- ment recognition.Proceedings of the IEEE, 86(11):2278–2324, 1998
1998
-
[58]
Certifiable Boolean reasoning is universal.arXiv preprint arXiv:2602.05120, 2026
Wenhao Li, Anastasis Kratsios, Hrad Ghoukasian, and Dennis Zvigelsky. Certifiable Boolean reasoning is universal.arXiv preprint arXiv:2602.05120, 2026
-
[59]
Yannick Limmer, Anastasis Kratsios, Xuwei Yang, Raeid Saqur, and Blanka Horvath. Higher-order trans- former derivative estimates for explicit pathwise learning guarantees.arXiv preprint arXiv:2405.16563, 2024
-
[60]
Learning quickly when irrelevant attributes abound: A new linear-threshold algorithm
Nick Littlestone. Learning quickly when irrelevant attributes abound: A new linear-threshold algorithm. Machine Learning, 2(4):285–318, 1988
1988
-
[61]
Hou, and Max Tegmark
Ziming Liu, Yixuan Wang, Sachin Vaidya, Fabian Ruehle, James Halverson, Marin Soljacic, Thomas Y. Hou, and Max Tegmark. KAN: Kolmogorov-Arnold Networks. InICLR, 2025
2025
-
[62]
Springer, Heidelberg, 2014
Antonio Lloris Ruiz, Encarnación Castillo Morales, Luis Parrilla Roure, and Antonio García Ríos.Algebraic Circuits, volume 66 ofIntelligent Systems Reference Library. Springer, Heidelberg, 2014
2014
-
[63]
Maas, Awni Y
Andrew L. Maas, Awni Y. Hannun, and Andrew Y. Ng. Rectifier nonlinearities improve neural network acousticmodels. InProceedings of the 30th International Conference on Machine Learning (ICML) Workshop on Deep Learning for Audio, Speech and Language Processing, 2013
2013
-
[64]
Angus Macintyre and Eduardo D. Sontag. Finiteness results for sigmoidal “neural” networks. InProceedings of the Twenty-Fifth Annual ACM Symposium on Theory of Computing, pages 325–334, 1993
1993
-
[65]
WL meet VC
Christopher Morris, Floris Geerts, Jan Tönshoff, and Martin Grohe. WL meet VC. InProceedings of the 40th International Conference on Machine Learning, volume 202 ofProceedings of Machine Learning Research, pages 25275–25302. PMLR, 2023. 13
2023
-
[66]
Vinod Nair and Geoffrey E. Hinton. Rectified linear units improve restricted Boltzmann machines. In Proceedings of the 27th International Conference on Machine Learning, pages 807–814, 2010
2010
-
[67]
arXiv preprint arXiv:2407.18384 , year=
Philipp Petersen and Jakob Zech. Mathematical Theory of Deep Learning.arXiv preprint arXiv:2407.18384, 2024
-
[68]
Definable sets in ordered structures
Anand Pillay and Charles Steinhorn. Definable sets in ordered structures. i.Transactions of the American Mathematical Society, 295(2):565–592, 1986
1986
-
[69]
Prajit Ramachandran, Barret Zoph, and Quoc V. Le. Searching for activation functions. InInternational Conference on Learning Representations Workshop, 2018
2018
-
[70]
Hierarchical models of object recognition in cortex.Nature Neuroscience, 2(11):1019–1025, 1999
Maximilian Riesenhuber and Tomaso Poggio. Hierarchical models of object recognition in cortex.Nature Neuroscience, 2(11):1019–1025, 1999
1999
-
[71]
Elucidating graph neural networks, transformers, and graph transformers
Haitz Sáez De Ocáriz Borde. Elucidating graph neural networks, transformers, and graph transformers. ResearchGate, 2024
2024
-
[72]
Cambridge University Press, 2014
Shai Shalev-Shwartz and Shai Ben-David.Understanding Machine Learning: From Theory to Algorithms. Cambridge University Press, 2014
2014
-
[73]
GLU Variants Improve Transformer
Noam Shazeer. GLU variants improve transformer.arXiv preprint arXiv:2002.05202, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2002
-
[74]
Bounds on the number of examples needed for learning functions.SIAM Journal on Computing, 26(3):751–763, 1997
Hans Ulrich Simon. Bounds on the number of examples needed for learning functions.SIAM Journal on Computing, 26(3):751–763, 1997
1997
-
[75]
The Pfaffian closure of ano-minimal structure.Journal für die Reine und Angewandte Mathematik, 1999(508):189–211, 1999
Patrick Speissegger. The Pfaffian closure of ano-minimal structure.Journal für die Reine und Angewandte Mathematik, 1999(508):189–211, 1999
1999
-
[76]
Training very deep networks
Rupesh Kumar Srivastava, Klaus Greff, and Jürgen Schmidhuber. Training very deep networks. InProceed- ings of the 29th International Conference on Neural Information Processing Systems - Volume 2, NIPS’15, page 2377–2385, Cambridge, MA, USA, 2015. MIT Press
2015
-
[77]
Rupesh Kumar Srivastava, Klaus Greff, and Jürgen Schmidhuber. Highway networks.arXiv preprint arXiv:1505.00387, 2015
work page Pith review arXiv 2015
-
[78]
Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
Jianlin Su, Murtadha Ahmed, Yu Lu, Shengfeng Pan, Wen Bo, and Yunfeng Liu. Roformer: Enhanced transformer with rotary position embedding.Neurocomputing, 568:127063, 2024
2024
-
[79]
Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T
Matthew Tancik, Pratul P. Srinivasan, Ben Mildenhall, Sara Fridovich-Keil, Nithin Raghavan, Utkarsh Singhal, Ravi Ramamoorthi, Jonathan T. Barron, and Ren Ng. Fourier features let networks learn high frequency functions in low dimensional domains. InAdvances in Neural Information Processing Systems, volume 33, pages 7537–7547, 2020
2020
-
[80]
Gemma Team. Gemma 3 technical report.CoRR, abs/2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.