Recognition: 2 theorem links
· Lean TheoremDecentralized Diffusion Policy Learning for Enhanced Exploration in Cooperative Multi-agent Reinforcement Learning
Pith reviewed 2026-05-11 01:04 UTC · model grok-4.3
The pith
Diffusion policies overcome the exploration limits of Gaussian approximations in decentralized multi-agent reinforcement learning.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that Gaussian projections in DecSPG severely constrain exploration in cooperative MARL and that this constraint grows worse with more agents; replacing the Gaussian class with diffusion policies trained via importance sampling score matching restores expressiveness while remaining tractable for decentralized online updates.
What carries the argument
Importance sampling score matching (ISSM) applied to denoising diffusion probabilistic models that serve as per-agent policies.
If this is right
- Expressive multi-modal action distributions become available without sacrificing decentralized online training.
- Exploration deficits no longer scale unfavorably with the number of agents.
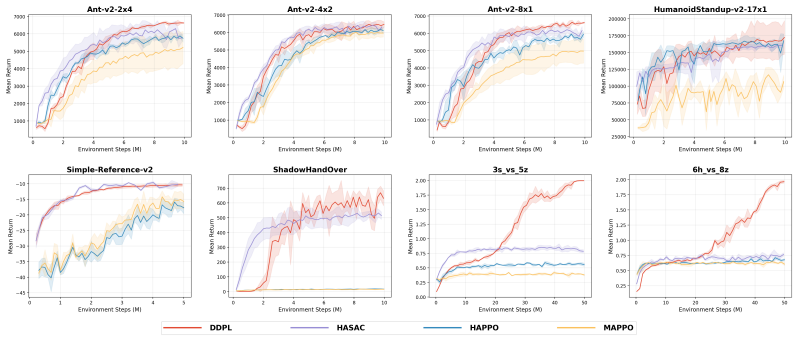
- Consistent performance improvements appear across particle, MuJoCo, IsaacLab, and StarCraft-style environments.
- Theoretical guarantees on the ISSM training step support reliable deployment.
Where Pith is reading between the lines
- The same diffusion parameterization might reduce reliance on hand-crafted exploration bonuses in other MARL algorithms.
- Single-agent continuous control tasks facing multi-modal action needs could adopt the ISSM training recipe directly.
- The method opens a path to policy classes beyond diffusion that preserve online decentralizability while increasing expressiveness.
Load-bearing premise
The Gaussian projection of energy-based policies is the main source of poor exploration, and diffusion policies can be trained stably and efficiently online in a decentralized setting without new intractabilities.
What would settle it
A controlled experiment in which DDPL is run on the same benchmarks but shows no exploration or performance advantage over well-tuned Gaussian DecSPG, or in which training becomes unstable or diverges.
Figures



read the original abstract
Cooperative multi-agent reinforcement learning (MARL) involves complex agent interactions and requires effective exploration strategies. A prominent class of MARL algorithms, decentralized softmax policy gradient (DecSPG), addresses this through energy-based policy updates. In practice, however, such energy-based policies are intractable to maintain and are commonly projected onto the Gaussian policy class. In this work, we show that the limited expressiveness of Gaussian policies severely hinders exploration in DecSPG, and this limitation worsens as the number of agents grows. To address this issue, we propose decentralized diffusion policy learning (DDPL), which parameterizes each agent's policy with a denoising diffusion probabilistic model, an expressive generative model that captures multi-modal action distributions for enhanced exploration. DDPL enables efficient online training of diffusion policies via importance sampling score matching (ISSM), a novel training method with theoretical guarantee. We evaluate DDPL on representative continuous-action MARL benchmarks, including multi-agent particle environment, multi-agent MuJoCo, IsaacLab, and JAX-reimplemented StarCraft multi-agent challenge, and observe consistently improved performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that projecting energy-based policies onto the Gaussian class in decentralized softmax policy gradient (DecSPG) methods severely limits exploration in cooperative multi-agent RL, with the limitation worsening as agent count grows. It proposes Decentralized Diffusion Policy Learning (DDPL) that parameterizes each agent's policy as a denoising diffusion probabilistic model to capture multi-modal action distributions. DDPL trains these policies online via a novel importance sampling score matching (ISSM) procedure asserted to possess a theoretical guarantee. Evaluations on multi-agent particle environments, multi-agent MuJoCo, IsaacLab, and a JAX-reimplemented StarCraft multi-agent challenge report consistent performance gains.
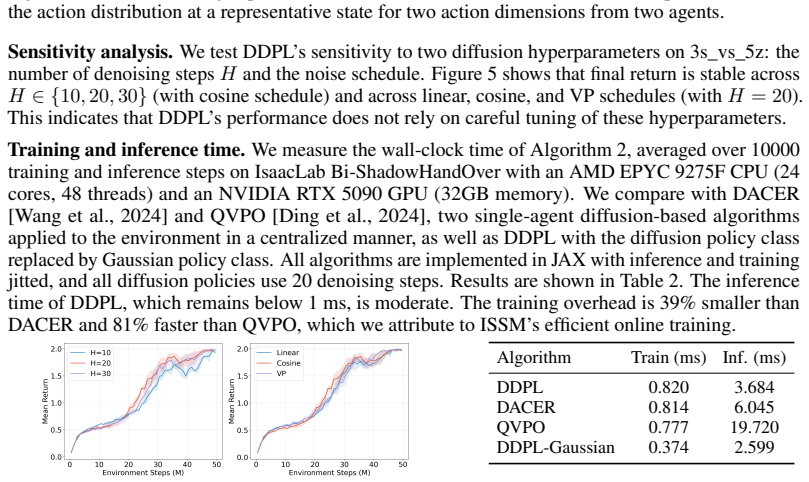
Significance. If the ISSM guarantee survives the non-stationarity of simultaneous decentralized policy updates and the reported gains are robustly attributable to the diffusion parameterization rather than other factors, the work would offer a concrete route to more expressive policies in online MARL without sacrificing tractability. It would also substantiate a scaling diagnosis of exploration failure that is currently only asserted.
major comments (2)
- [Abstract] Abstract: the manuscript asserts a 'theoretical guarantee' for ISSM yet supplies no derivation, proof sketch, or analysis of variance/bias under the distribution shifts that arise when every agent updates its policy simultaneously. This is load-bearing for the central claim; the stress-test concern that standard importance-sampling assumptions (fixed behavior policy, bounded density ratios) are violated is not addressed.
- [Abstract] Abstract / Empirical Evaluation: the claim that Gaussian-policy expressiveness is the primary exploration bottleneck (and worsens with agent count) is presented without controlled experiments that isolate policy class from other DecSPG components, nor any scaling analysis or ablation that holds other factors fixed. The reported benchmark gains therefore cannot yet be attributed to the proposed mechanism.
minor comments (1)
- The abstract lists four benchmark suites but does not indicate whether the same hyper-parameter budgets, network sizes, or number of seeds were used across all methods; adding this information would strengthen the reproducibility claim.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed comments, which highlight important areas for strengthening the theoretical and empirical foundations of our work. We address each major comment below and commit to revisions that directly respond to the concerns raised.
read point-by-point responses
-
Referee: [Abstract] Abstract: the manuscript asserts a 'theoretical guarantee' for ISSM yet supplies no derivation, proof sketch, or analysis of variance/bias under the distribution shifts that arise when every agent updates its policy simultaneously. This is load-bearing for the central claim; the stress-test concern that standard importance-sampling assumptions (fixed behavior policy, bounded density ratios) are violated is not addressed.
Authors: We agree that the claim of a theoretical guarantee requires explicit substantiation in the manuscript. While the full paper describes the ISSM objective and states the guarantee at a high level, it does not include a derivation or analysis of bias/variance under simultaneous decentralized updates. In the revised version, we will add a dedicated appendix containing: (i) a full derivation of the ISSM loss from the score-matching objective under importance sampling, (ii) a proof sketch establishing the guarantee under the stated assumptions, and (iii) a discussion of the non-stationarity induced by concurrent policy updates, including conditions for bounded density ratios and an empirical variance analysis on representative environments. This will directly address the load-bearing nature of the claim. revision: yes
-
Referee: [Abstract] Abstract / Empirical Evaluation: the claim that Gaussian-policy expressiveness is the primary exploration bottleneck (and worsens with agent count) is presented without controlled experiments that isolate policy class from other DecSPG components, nor any scaling analysis or ablation that holds other factors fixed. The reported benchmark gains therefore cannot yet be attributed to the proposed mechanism.
Authors: We acknowledge that stronger isolation is needed to attribute gains specifically to the diffusion parameterization. Our existing results compare DDPL against Gaussian DecSPG baselines across environments, but do not include ablations that hold all other algorithmic components fixed while varying only the policy class. In the revision, we will add: (1) controlled experiments replacing the diffusion model with a Gaussian policy while retaining the ISSM training procedure (adapted for the Gaussian case), and (2) scaling studies in the multi-agent particle environments that increase agent count (e.g., 3, 6, 9 agents) while measuring both performance and exploration metrics such as action-space coverage and entropy. These additions will allow readers to better assess whether the expressiveness limitation is the dominant factor. revision: yes
Circularity Check
No significant circularity; derivation introduces independent method and guarantee.
full rationale
The paper proposes a new policy class (diffusion models) and training procedure (ISSM) for decentralized MARL, claiming a theoretical guarantee for the latter. No load-bearing step reduces a claimed prediction or result to a fitted parameter, self-citation chain, or definitional equivalence within the paper's own equations. The exploration limitation of Gaussians and the benefits of diffusion policies are presented as empirical and architectural observations rather than tautological outputs of prior fits. The derivation chain remains self-contained against external benchmarks and does not rely on renaming known results or smuggling ansatzes via self-citation.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
DDPL enables efficient online training of diffusion policies via importance sampling score matching (ISSM), a novel training method with theoretical guarantee... D2_TV(π⋆,k_i ∥ πbθi_i) ≲ d² log⁶H/H² + d exp(¾ D⁴(π⋆,k_i ∥ p̃)) / √N
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
the limited expressiveness of Gaussian policies severely hinders exploration in DecSPG, and this limitation worsens as the number of agents grows
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Sitan Chen, Sinho Chewi, Jerry Li, Yuanzhi Li, Adil Salim, and Anru R Zhang. Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions.arXiv preprint arXiv:2209.11215,
-
[2]
Shutong Ding, Ke Hu, Shan Zhong, Haoyang Luo, Weinan Zhang, Jingya Wang, Jun Wang, and Ye Shi. Genpo: Generative diffusion models meet on-policy reinforcement learning.arXiv preprint arXiv:2505.18763,
-
[3]
Maximum entropy reinforcement learning with diffusion policy.arXiv preprint arXiv:2502.11612,
Xiaoyi Dong, Jian Cheng, and Xi Sheryl Zhang. Maximum entropy reinforcement learning with diffusion policy.arXiv preprint arXiv:2502.11612,
-
[4]
Sampling from energy-based policies using diffusion.arXiv preprint arXiv:2410.01312,
Vineet Jain, Tara Akhound-Sadegh, and Siamak Ravanbakhsh. Sampling from energy-based policies using diffusion.arXiv preprint arXiv:2410.01312,
-
[5]
Flow Matching for Generative Modeling
Gen Li and Yuling Yan. O (d/t) convergence theory for diffusion probabilistic models under minimal assumptions. InThe Thirteenth International Conference on Learning Representations. Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Efficient online reinforcement learning for diffusion policy.arXiv preprint arXiv:2502.00361, 2025
Haitong Ma, Tianyi Chen, Kai Wang, Na Li, and Bo Dai. Efficient online reinforcement learning for diffusion policy.arXiv preprint arXiv:2502.00361, 2025a. 10 Haitong Ma, Tianyi Chen, Kai Wang, Na Li, and Bo Dai. Efficient online reinforcement learning for diffusion policy. In Aarti Singh, Maryam Fazel, Daniel Hsu, Simon Lacoste-Julien, Felix Berkenkamp, T...
-
[7]
Learning a diffusion model policy from rewards via q-score matching.arXiv preprint arXiv:2312.11752,
Michael Psenka, Alejandro Escontrela, Pieter Abbeel, and Yi Ma. Learning a diffusion model policy from rewards via q-score matching.arXiv preprint arXiv:2312.11752,
-
[8]
Inde- pendent learning in performative markov potential games.arXiv preprint arXiv:2504.20593,
Rilind Sahitaj, Paulius Sasnauskas, Yi ˘git Yalın, Debmalya Mandal, and Goran Radanovi´c. Inde- pendent learning in performative markov potential games.arXiv preprint arXiv:2504.20593,
-
[9]
How to train your energy-based models.arXiv preprint arXiv:2101.03288,
Yang Song and Diederik P Kingma. How to train your energy-based models.arXiv preprint arXiv:2101.03288,
-
[10]
arXiv preprint arXiv:2305.13122 , year=
Long Yang, Zhixiong Huang, Fenghao Lei, Yucun Zhong, Yiming Yang, Cong Fang, Shiting Wen, Binbin Zhou, and Zhouchen Lin. Policy representation via diffusion probability model for reinforcement learning.arXiv preprint arXiv:2305.13122,
-
[11]
On the global convergence rates of decentralized softmax gradient play in markov potential games.Advances in Neural Information Processing Systems, 35:1923–1935,
Runyu Zhang, Jincheng Mei, Bo Dai, Dale Schuurmans, and Na Li. On the global convergence rates of decentralized softmax gradient play in markov potential games.Advances in Neural Information Processing Systems, 35:1923–1935,
1923
-
[12]
Yixian Zhang, Shu’ang Yu, Tonghe Zhang, Mo Guang, Haojia Hui, Kaiwen Long, Yu Wang, Chao Yu, and Wenbo Ding. Sac flow: Sample-efficient reinforcement learning of flow-based policies via velocity-reparameterized sequential modeling.arXiv preprint arXiv:2509.25756,
-
[13]
Then P(visits=1 n at least once)≤P \ i∈[n] Ei .(18) Notice that event Ec i , i.e., the agents never visit [s]i = 1, only depends on the individual policy πk i (·|sstart) for epoch k≤k i. Moreover, the individual policy πk i with k≤k i can be expressed recursively as πk i (·|sstart) = arg min πi KL πi∥˜πk i ,˜π k i (·)∝π k−1 i (·|s0) exp ηbQπk−1 i (...
2017
-
[14]
By the triangle inequality, we have that D2 TV(PX0 ∥PY0)≤2D 2 TV(PX0 ∥P ˜X0 ) + 2D2 TV(P ˜X0 ∥PY0)
Connecting DTV(PX0 ∥PY0 ) to the score difference.Define auxiliary random variable ˜X0 = (X1 +βs 1(X1))/ √α+σϵforϵ∼ N(0, I). By the triangle inequality, we have that D2 TV(PX0 ∥PY0)≤2D 2 TV(PX0 ∥P ˜X0 ) + 2D2 TV(P ˜X0 ∥PY0). (50) Since ˜X0 and Y0 are generated by the same backward process (Equation (48)) from distribu- tions X1 and Y1, respectively, by th...
2019
-
[15]
(61) Since the above holds for alli∈[d], we know that 0 = Z ∇x0 PX0|x1(x0)dx0 =E X0|x1 ∇x0 logP X0|x1(x0) =E X0|x1 − α β x0 − x1√α +s ⋆ 0(x0)
(60) Therefore, 0 = Z div PX0|x1(x0)ei dx0 = Z ∇x0 PX0|x1(x0)·e idx0 + Z PX0|x1(x0)div(ei)dx0 = Z ∇PX0|x1(x0)·e idx0. (61) Since the above holds for alli∈[d], we know that 0 = Z ∇x0 PX0|x1(x0)dx0 =E X0|x1 ∇x0 logP X0|x1(x0) =E X0|x1 − α β x0 − x1√α +s ⋆ 0(x0) . (62) Here the last line is by Equation (55). Therefore, combining with the definition ofIgives ...
2019
-
[16]
Conclusion.Substituting the above inequality back into Equation (57) gives D2 TV(PX0 ∥PY0)≤ β2 2σ2α Ex1∼X1 ∥s⋆ 1(x1)−s 1(x1)∥2 + σ2βd α−c 2β c2 2 + 1 σ2 − α β 2! + 2D2 TV(PX1 ∥PY1). (67) Similarly, one can derive a bound on KL divergence: DKL(PX0 ∥PY0)≤E X1 h DKL PX0|x1 ∥P ˜X0|x1 i +D KL(PX1 ∥PY1) ≤ σ2 2 Ex1∼PX1 Ex0∼PX0 |x1 ∥I∥2 +D KL(PX1 ∥PY1) ≤ β2 2σ2α ...
2022
-
[17]
Proof of Theorem C.2
Suppose in every epoch k, the learned policy πk i of all agents i∈[n] satisfies DTV(πk i (·|s), π⋆,k i (·|s))≤ϵ is for all i∈[n], k∈ [K],s∈ S, then PK−1 k=0 NE-gap πk 2 K ≤ 6M(rmax −r min)2 c(1−γ) 3 n K + 12M(rmax −r min)2 c(1−γ) 4 n2ϵis, whereMandcare defined in Theorem C.1. Proof of Theorem C.2. We let πk i (·|s) denote the approximate policy learned by...
2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.