Recognition: 2 theorem links
· Lean TheoremBeyond LoRA vs. Full Fine-Tuning: Gradient-Guided Optimizer Routing for LLM Adaptation
Pith reviewed 2026-05-11 01:06 UTC · model grok-4.3
The pith
Gradient routing between full and LoRA tuning beats static choices
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
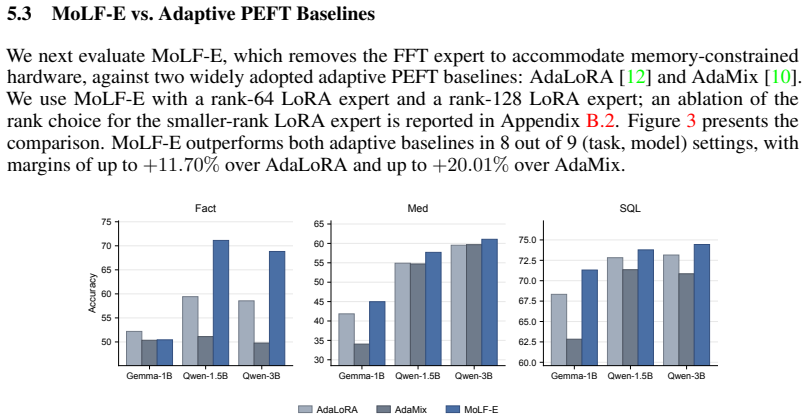
The authors establish that a Mixture of LoRA and Full fine-tuning (MoLF) dynamically routes updates between full-parameter and low-rank experts at the optimizer level using gradient guidance. Both experts therefore receive precise gradient information throughout training, allowing the process to select the more suitable regime without committing to one static architecture in advance. Evaluations confirm that MoLF matches or exceeds the better of FFT and LoRA across the tested settings, while the efficient variant outperforms earlier adaptive LoRA techniques by up to 20 percent on fact-based tasks and 9 percent on medical and SQL tasks.
What carries the argument
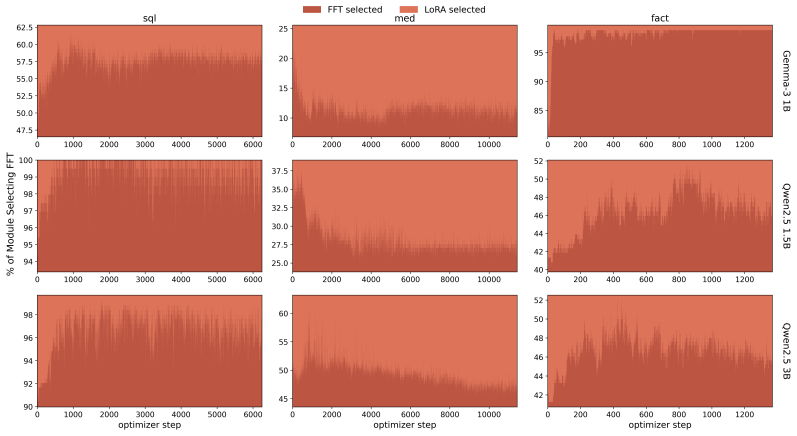
The gradient-guided optimizer router in MoLF, which assigns each update to either a full fine-tuning optimizer or a LoRA optimizer so both receive exact gradients and training can switch regimes continuously.
If this is right
- Training no longer requires an upfront choice between full fine-tuning and LoRA, as the router selects during the run.
- Both update paths stay available with accurate gradients, preserving stable dynamics.
- The memory-efficient variant achieves gains over previous adaptive LoRA methods without unfreezing base weights.
- Results hold across tasks that differ in how much high-entropy knowledge injection they need.
- The same routing principle applies to models ranging from 1B to 3B parameters.
Where Pith is reading between the lines
- The routing mechanism could be paired with other adaptation techniques beyond the FFT-LoRA pair.
- It may lower the cost of trying multiple fine-tuning methods by letting one run explore both options.
- Verification on larger models and broader domains would test whether the observed performance bounds generalize.
Load-bearing premise
That gradient signals can be used to route updates to the better expert at each step without introducing training instability or systematically poor choices.
What would settle it
Consistent training instability or performance more than 1.5 percent below the better static baseline on additional models or tasks would disprove the central claim.
Figures




read the original abstract
Recent literature on fine-tuning Large Language Models highlights a fundamental debate. While Full Fine-Tuning (FFT) provides the representational plasticity required for high-entropy knowledge injection, Low-Rank Adaptation (LoRA) can match or surpass FFT performance because many tasks only require updates in a low-rank space and benefit from LoRA's additional regularization. Through empirical evaluation across diverse tasks (SQL, Medical QA, and Counterfactual Knowledge) and varying language models (Gemma-3-1B, Qwen2.5-1.5B, and Qwen2.5-3B), we verify both trends and demonstrate that relying solely on either static architecture is structurally limited. To address this challenge, we propose a Mixture of LoRA and Full (MoLF) Fine-Tuning, a unified framework that enables continuous navigation between both training regimes. MoLF dynamically routes updates between FFT and LoRA at the optimizer level to ensure that exact gradient signals are available to both experts throughout training, yielding stable training dynamics. For memory-constrained environments, we also introduce MoLF-Efficient, which freezes base weights and only routes updates among a pair of LoRA experts of potentially varying rank. Our evaluations show that MoLF either improves on or stays within $1.5\%$ of the better of FFT and LoRA across all settings, while MoLF-Efficient outperforms prior adaptive LoRA approaches by up to $20\%$ on Fact and $9\%$ on Med and SQL.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that static choices between full fine-tuning (FFT) and LoRA are suboptimal for LLM adaptation because tasks vary in required representational plasticity versus regularization. It introduces MoLF, which routes updates between FFT and LoRA experts at the optimizer level via gradient guidance to keep exact gradients available to both throughout training, plus MoLF-Efficient (freezing base weights and routing between two LoRA experts) for memory limits. Experiments on Gemma-3-1B, Qwen2.5-1.5B and Qwen2.5-3B across SQL, Medical QA and Counterfactual Knowledge tasks report that MoLF matches or exceeds the better static baseline within 1.5% while MoLF-Efficient beats prior adaptive LoRA methods by up to 20% on Fact and 9% on Med/SQL.
Significance. If the routing mechanism proves stable and the empirical margins hold under proper statistical controls, the work offers a practical hybrid that sidesteps the FFT-LoRA trade-off without requiring task-specific architecture selection. The optimizer-level design and efficient variant address real deployment constraints; reproducible code or machine-checked routing logic would further strengthen the contribution.
major comments (3)
- [§3] §3 (MoLF routing): the gradient-guided routing rule is described only at a high level; no equation, threshold, or pseudocode specifies how per-parameter gradients are compared or how routing decisions are made without creating update conflicts or variance spikes. This detail is load-bearing for the central claim of stable dynamics and exact gradient availability to both experts.
- [§4] §4, all results tables: no error bars, standard deviations across seeds, or statistical tests (e.g., paired t-tests) accompany the reported accuracies or the 1.5% bound. Without these, it is impossible to verify that MoLF reliably stays within 1.5% of the better baseline or that the 20%/9% margins over prior adaptive LoRA are robust rather than run-specific.
- [§4.3] §4.3 (generalization): experiments are confined to 1-3B models and three tasks; no ablation or analysis examines whether routing decisions correlate with model scale or domain entropy. This directly affects whether the headline performance claims transfer beyond the tested regime.
minor comments (2)
- [§2] The abstract and §2 cite prior adaptive LoRA methods but do not list their exact names or citations in the main text; a dedicated related-work paragraph would improve clarity.
- [§3.1] Notation for the two experts (FFT expert vs. LoRA expert) is introduced inconsistently between §3.1 and the MoLF-Efficient description; a single consistent symbol table would help.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive suggestions. We address each of the major comments below and outline the revisions we will make to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3] §3 (MoLF routing): the gradient-guided routing rule is described only at a high level; no equation, threshold, or pseudocode specifies how per-parameter gradients are compared or how routing decisions are made without creating update conflicts or variance spikes. This detail is load-bearing for the central claim of stable dynamics and exact gradient availability to both experts.
Authors: We agree that additional detail on the routing rule is necessary. In the revised manuscript, we will include the precise mathematical formulation of the gradient-guided routing, specifying how gradients are compared per parameter, the threshold used for routing decisions, and pseudocode illustrating the process. This will demonstrate how the mechanism ensures exact gradients are available to both experts without introducing conflicts or variance spikes, thereby supporting the stability claims. revision: yes
-
Referee: [§4] §4, all results tables: no error bars, standard deviations across seeds, or statistical tests (e.g., paired t-tests) accompany the reported accuracies or the 1.5% bound. Without these, it is impossible to verify that MoLF reliably stays within 1.5% of the better baseline or that the 20%/9% margins over prior adaptive LoRA are robust rather than run-specific.
Authors: The absence of statistical measures is a valid concern. We will conduct additional runs with multiple seeds and update all result tables to include error bars, standard deviations, and statistical significance tests (such as paired t-tests) to confirm that MoLF remains within 1.5% of the better baseline and that the improvements over prior methods are robust. revision: yes
-
Referee: [§4.3] §4.3 (generalization): experiments are confined to 1-3B models and three tasks; no ablation or analysis examines whether routing decisions correlate with model scale or domain entropy. This directly affects whether the headline performance claims transfer beyond the tested regime.
Authors: We recognize the limitation regarding generalization. Our current experiments span models from 1B to 3B parameters and tasks that vary in entropy and domain (SQL, Medical QA, Counterfactual Knowledge). In the revision, we will add an analysis section correlating routing decisions with task characteristics and model scale based on the collected data. However, experiments on larger models are beyond our current computational budget and will be noted as future work. revision: partial
Circularity Check
No circularity: empirical proposal and direct comparisons
full rationale
The paper advances MoLF as a new optimizer-level routing framework and validates it through direct empirical comparisons on Gemma-3-1B, Qwen2.5-1.5B, and Qwen2.5-3B across SQL, Medical QA, and Counterfactual Knowledge tasks. No equations, fitted parameters, or predictions are defined in terms of the target metrics; performance claims (within 1.5% of best baseline, up to 20% gains for MoLF-Efficient) are measured against external static and adaptive baselines rather than reducing to self-referential inputs. The design choices are presented as engineering decisions whose stability is assessed experimentally, with no load-bearing self-citations or ansatz smuggling.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearMoLF dynamically routes updates between FFT and LoRA at the optimizer level... Expected Preconditioned Descent (EPD) score S(i)_t = η(i)_t / N(i)_params Σ (m(i)_t)^2 / √(v(i)_t + ϵ)
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearAll fine-tuning experiments... on Gemma-3-1B / Qwen2.5-1.5B / 3B
Reference graph
Works this paper leans on
-
[1]
Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
Tom Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared D Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, et al. Language models are few-shot learners.Advances in neural information processing systems, 33:1877–1901, 2020
1901
-
[2]
LLaMA: Open and Efficient Foundation Language Models
Hugo Touvron, Thibaut Lavril, Gautier Izacard, Xavier Martinet, Marie-Anne Lachaux, Timo- thée Lacroix, Baptiste Rozière, Naman Goyal, Eric Hambro, Faisal Azhar, et al. Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[3]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Hugo Touvron, Louis Martin, Kevin Stone, Peter Albert, Amjad Almahairi, Yasmine Babaei, Nikolay Bashlykov, Soumya Batra, Prajjwal Bhargava, Shruti Bhosale, et al. Llama 2: Open foundation and fine-tuned chat models.arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[4]
Scaling instruction-finetuned language models.Journal of Machine Learning Research, 25(70):1–53, 2024
Hyung Won Chung, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, et al. Scaling instruction-finetuned language models.Journal of Machine Learning Research, 25(70):1–53, 2024
2024
-
[5]
Smart: Robust and efficient fine-tuning for pre-trained natural language models through princi- pled regularized optimization
Haoming Jiang, Pengcheng He, Weizhu Chen, Xiaodong Liu, Jianfeng Gao, and Tuo Zhao. Smart: Robust and efficient fine-tuning for pre-trained natural language models through princi- pled regularized optimization. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 2177–2190, 2020
2020
-
[6]
Better fine-tuning by reducing representational collapse
Armen Aghajanyan, Akshat Shrivastava, Anchit Gupta, Naman Goyal, Luke Zettlemoyer, and Sonal Gupta. Better fine-tuning by reducing representational collapse. InInternational Conference on Learning Representations, 2020
2020
-
[7]
Ning Ding, Yujia Qin, Guang Yang, Fuchao Wei, Zonghan Yang, Yusheng Su, Shengding Hu, Yulin Chen, Chi-Min Chan, Weize Chen, et al. Delta tuning: A comprehensive study of parameter efficient methods for pre-trained language models.arXiv preprint arXiv:2203.06904, 2022
-
[8]
Parameter-efficient fine-tuning methods for pretrained language models: A critical review and assessment.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
Lingling Xu, Haoran Xie, S Joe Qin, Xiaohui Tao, and Fu Lee Wang. Parameter-efficient fine-tuning methods for pretrained language models: A critical review and assessment.IEEE Transactions on Pattern Analysis and Machine Intelligence, 2026
2026
-
[9]
LoRA: Low-rank adaptation of large language models.ICLR, 1 (2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen, et al. LoRA: Low-rank adaptation of large language models.ICLR, 1 (2):3, 2022
2022
-
[10]
AdaMix: Mixture-of-adaptations for parameter-efficient model tuning
Yaqing Wang, Sahaj Agarwal, Subhabrata Mukherjee, Xiaodong Liu, Jing Gao, Ahmed Hassan, and Jianfeng Gao. AdaMix: Mixture-of-adaptations for parameter-efficient model tuning. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, pages 5744–5760, 2022
2022
-
[11]
RandLoRA: Full rank parameter-efficient fine-tuning of large models
Paul Albert, Frederic Z Zhang, Hemanth Saratchandran, Cristian Rodriguez-Opazo, Anton van den Hengel, and Ehsan Abbasnejad. RandLoRA: Full rank parameter-efficient fine-tuning of large models. InThe Thirteenth International Conference on Learning Representations, 2025
2025
-
[12]
Adaptive budget allocation for parameter-efficient fine-tuning
Qingru Zhang, Minshuo Chen, Alexander Bukharin, Pengcheng He, Yu Cheng, Weizhu Chen, and Tuo Zhao. Adaptive budget allocation for parameter-efficient fine-tuning. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[13]
arXiv preprint arXiv:2308.12043 , year =
Feiyu Zhang, Liangzhi Li, Junhao Chen, Zhouqiang Jiang, Bowen Wang, and Yiming Qian. IncreLoRA: Incremental parameter allocation method for parameter-efficient fine-tuning.arXiv preprint arXiv:2308.12043, 2023
-
[14]
ALoRA: Allocating low-rank adaptation for fine-tuning large language models
Zequan Liu, Jiawen Lyn, Wei Zhu, Xing Tian, and Yvette Graham. ALoRA: Allocating low-rank adaptation for fine-tuning large language models. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers), pages 622–641, 2024. 10
2024
-
[15]
Lora learns less and forgets less.arXiv preprint arXiv:2405.09673, 2024
Dan Biderman, Jacob Portes, Jose Javier Gonzalez Ortiz, Mansheej Paul, Philip Greengard, Connor Jennings, Daniel King, Sam Havens, Vitaliy Chiley, Jonathan Frankle, et al. LoRA learns less and forgets less.arXiv preprint arXiv:2405.09673, 2024
-
[16]
Intrinsic dimensionality explains the effectiveness of language model fine-tuning
Armen Aghajanyan, Sonal Gupta, and Luke Zettlemoyer. Intrinsic dimensionality explains the effectiveness of language model fine-tuning. InProceedings of the 59th annual meeting of the association for computational linguistics and the 11th international joint conference on natural language processing (volume 1: long papers), pages 7319–7328, 2021
2021
-
[17]
Lora without regret, September 2025
John Schulman and Thinking Machines. Lora without regret, September 2025. URL https: //thinkingmachines.ai/blog/lora/. Accessed: 2026-05-06
2025
-
[18]
FLoRA: Low-rank adapters are secretly gradient compressors
Yongchang Hao, Yanshuai Cao, and Lili Mou. FLoRA: Low-rank adapters are secretly gradient compressors. InInternational Conference on Machine Learning, pages 17554–17571. PMLR, 2024
2024
-
[19]
LoRA-GA: Low-rank adaptation with gradient approxi- mation.Advances in Neural Information Processing Systems, 37:54905–54931, 2024
Shaowen Wang, Linxi Yu, and Jian Li. LoRA-GA: Low-rank adaptation with gradient approxi- mation.Advances in Neural Information Processing Systems, 37:54905–54931, 2024
2024
-
[20]
ReLoRA: High-rank training through low-rank updates
Vladislav Lialin, Sherin Muckatira, Namrata Shivagunde, and Anna Rumshisky. ReLoRA: High-rank training through low-rank updates. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[21]
Simeng Sun, Dhawal Gupta, and Mohit Iyyer. Exploring the impact of low-rank adaptation on the performance, efficiency, and regularization of RLHF.arXiv preprint arXiv:2309.09055, 2023
-
[22]
A study on improving reasoning in language models
Yuqing Du, Alexander Havrilla, Sainbayar Sukhbaatar, Pieter Abbeel, and Roberta Raileanu. A study on improving reasoning in language models. InI Can’t Believe It’s Not Better Workshop: Failure Modes in the Age of F oundation Models, 2024
2024
-
[23]
arXiv preprint arXiv:2311.10702 , year=
Hamish Ivison, Yizhong Wang, Valentina Pyatkin, Nathan Lambert, Matthew Peters, Pradeep Dasigi, Joel Jang, David Wadden, Noah A Smith, Iz Beltagy, et al. Camels in a changing climate: Enhancing LM adaptation with Tulu 2.arXiv preprint arXiv:2311.10702, 2023
-
[24]
Sergey Pletenev, Maria Marina, Daniil Moskovskiy, Vasily Konovalov, Pavel Braslavski, Alexan- der Panchenko, and Mikhail Salnikov. How much knowledge can you pack into a LoRA adapter without harming LLM?arXiv preprint arXiv:2502.14502, 2025
-
[25]
LoRA vs full fine-tuning: An illusion of equivalence
Reece S Shuttleworth, Jacob Andreas, Antonio Torralba, and Pratyusha Sharma. LoRA vs full fine-tuning: An illusion of equivalence. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
2025
-
[26]
ElaLoRA: Elastic & learnable low-rank adaptation for efficient model fine-tuning
Huandong Chang, Zicheng Ma, Mingyuan Ma, Zhenting Qi, Andrew Sabot, Hong Jiang, and HT Kung. ElaLoRA: Elastic & learnable low-rank adaptation for efficient model fine-tuning. arXiv preprint arXiv:2504.00254, 2025
-
[27]
Sparse low-rank adaptation of pre-trained language models
Ning Ding, Xingtai Lv, Qiaosen Wang, Yulin Chen, Bowen Zhou, Zhiyuan Liu, and Maosong Sun. Sparse low-rank adaptation of pre-trained language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 4133–4145, 2023
2023
-
[28]
AutoLoRA: Automatically tuning matrix ranks in low-rank adaptation based on meta learning
Ruiyi Zhang, Rushi Qiang, Sai Ashish Somayajula, and Pengtao Xie. AutoLoRA: Automatically tuning matrix ranks in low-rank adaptation based on meta learning. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (V olume 1: Long Papers), pages 5048–5060, 2024
2024
-
[29]
DoRA: Enhancing parameter-efficient fine-tuning with dynamic rank distribution
Yulong Mao, Kaiyu Huang, Changhao Guan, Ganglin Bao, Fengran Mo, and Jinan Xu. DoRA: Enhancing parameter-efficient fine-tuning with dynamic rank distribution. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 11662–11675, 2024
2024
-
[30]
DyLoRA: Parameter- efficient tuning of pre-trained models using dynamic search-free low-rank adaptation
Mojtaba Valipour, Mehdi Rezagholizadeh, Ivan Kobyzev, and Ali Ghodsi. DyLoRA: Parameter- efficient tuning of pre-trained models using dynamic search-free low-rank adaptation. In Proceedings of the 17th Conference of the European Chapter of the Association for Computa- tional Linguistics, pages 3274–3287, 2023. 11
2023
-
[31]
QDyLoRA: Quantized dynamic low-rank adaptation for efficient large language model tuning
Hossein Rajabzadeh, Mojtaba Valipour, Tianshu Zhu, Marzieh S Tahaei, Hyock Ju Kwon, Ali Ghodsi, Boxing Chen, and Mehdi Rezagholizadeh. QDyLoRA: Quantized dynamic low-rank adaptation for efficient large language model tuning. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track, pages 712–718, 2024
2024
-
[32]
Adaptive mixtures of local experts.Neural computation, 3(1):79–87, 1991
Robert A Jacobs, Michael I Jordan, Steven J Nowlan, and Geoffrey E Hinton. Adaptive mixtures of local experts.Neural computation, 3(1):79–87, 1991
1991
-
[33]
Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer.arXiv preprint arXiv:1701.06538, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[34]
Sira: Sparse mixture of low rank adaptation
Yun Zhu, Nevan Wichers, Chu-Cheng Lin, Xinyi Wang, Tianlong Chen, Lei Shu, Han Lu, Canoee Liu, Liangchen Luo, Jindong Chen, et al. Sira: Sparse mixture of low rank adaptation. arXiv preprint arXiv:2311.09179, 2023
-
[35]
AdaMoLE: Adaptive mixture of LoRA experts.arXiv preprint arXiv:2405.00361, 2024
Zefang Liu and Jiahua Luo. AdaMoLE: Adaptive mixture of LoRA experts.arXiv preprint arXiv:2405.00361, 2024. URLhttps://arxiv.org/abs/2405.00361
-
[36]
Pushing mixture of experts to the limit: Extremely parameter efficient MoE for instruction tuning
Ted Zadouri, Ahmet Üstün, Arash Ahmadian, Beyza Ermis, Acyr Locatelli, and Sara Hooker. Pushing mixture of experts to the limit: Extremely parameter efficient MoE for instruction tuning. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[37]
Mixture of LoRA experts
Xun Wu, Shaohan Huang, and Furu Wei. Mixture of LoRA experts. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[38]
Mixlora: Enhancing large language models fine-tuning with lora based mixture of experts,
Dengchun Li, Yingzi Ma, Naizheng Wang, Zhengmao Ye, Zhiyuan Cheng, Yinghao Tang, Yan Zhang, Lei Duan, Jie Zuo, Cal Yang, et al. MixLoRA: Enhancing large language models fine-tuning with LoRA-based mixture of experts.arXiv preprint arXiv:2404.15159, 2024
-
[39]
LoRAMoE: Alleviating world knowledge forgetting in large language models via MoE-style plugin
Shihan Dou, Enyu Zhou, Yan Liu, Songyang Gao, Wei Shen, Limao Xiong, Yuhao Zhou, Xiao Wang, Zhiheng Xi, Xiaoran Fan, et al. LoRAMoE: Alleviating world knowledge forgetting in large language models via MoE-style plugin. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (V olume 1: Long Papers), pages 1932–1945, 2024
1932
-
[40]
Locating and editing factual associations in GPT
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in GPT. InAdvances in Neural Information Processing Systems, volume 35, 2022
2022
-
[41]
MedMCQA: A large- scale multi-subject multi-choice dataset for medical domain question answering
Ankit Pal, Logesh Kumar Umapathi, and Malaikannan Sankarasubbu. MedMCQA: A large- scale multi-subject multi-choice dataset for medical domain question answering. InProceedings of the Conference on Health, Inference, and Learning (CHIL), volume 174 ofProceedings of Machine Learning Research, pages 248–260. PMLR, 2022
2022
-
[42]
Synthetic-Text-To-SQL: A synthetic dataset for training language models to generate SQL queries from natural language prompts
Yev Meyer, Marjan Emadi, Dhruv Nathawani, Lipika Ramaswamy, Kendrick Boyd, Maarten Van Segbroeck, Matthew Grossman, Piotr Mlocek, and Drew Newberry. Synthetic-Text-To-SQL: A synthetic dataset for training language models to generate SQL queries from natural language prompts. https://huggingface.co/datasets/gretelai/synthetic_text_to_sql , April 2024
2024
-
[43]
The approximation of one matrix by another of lower rank
Carl Eckart and Gale Young. The approximation of one matrix by another of lower rank. Psychometrika, 1(3):211–218, 1936
1936
-
[44]
Symmetric gauge functions and unitarily invariant norms.The quarterly journal of mathematics, 11(1):50–59, 1960
Leon Mirsky. Symmetric gauge functions and unitarily invariant norms.The quarterly journal of mathematics, 11(1):50–59, 1960
1960
-
[45]
A rank stabilization scaling factor for fine-tuning with lora
Damjan Kalajdzievski. A rank stabilization scaling factor for fine-tuning with LoRA.arXiv preprint arXiv:2312.03732, 2023
-
[46]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980, 2014
work page internal anchor Pith review Pith/arXiv arXiv 2014
-
[47]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017. 12
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[48]
Aishwarya Kamath, Johan Ferret, Shreya Pathak, Nino Vieillard, Ramona Merhej, Sarah Perrin, Tatiana Matejovicova, Alexandre Ramé, Morgane Rivière, et al. Gemma 3 technical report. arXiv preprint arXiv:2503.19786, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[49]
An Yang, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chengyuan Li, Dayiheng Liu, Fei Huang, et al. Qwen2.5 technical report. https://arxiv.org/abs/2412 .15115, 2024. arXiv preprint arXiv:2412.15115. 13 A Experimental Details A.1 Derivation of the Expected Preconditioned Descent (EPD) Score The Expected Preconditioned Descent (EPD) score ...
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.