Recognition: 2 theorem links
· Lean TheoremNeurosymbolic Framework for Concept-Driven Logical Reasoning in Skeleton-Based Human Action Recognition
Pith reviewed 2026-05-11 02:37 UTC · model grok-4.3
The pith
Skeleton-based action recognition reframed as logical reasoning over motion concepts achieves competitive accuracy with explicit explanations.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
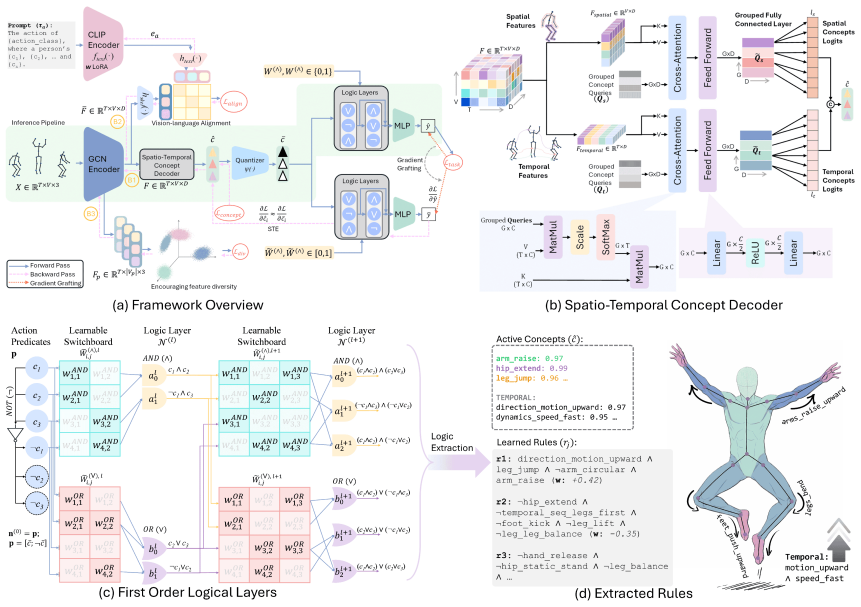
The framework reframes action recognition as first-order logical reasoning over motion primitives by grounding predicates in learnable spatial and temporal concepts extracted from skeleton data, composed through differentiable logic layers, and aligned with LLM-derived atomic motion descriptions to ensure semantic consistency, resulting in both high recognition rates and interpretable logical explanations.
What carries the argument
The spatio-temporal concept decoder that separates pose-centric and dynamics-centric abstractions and maps them to logic predicates, together with the differentiable first-order logic layers for rule composition.
If this is right
- The model learns human-readable logical rules that govern action semantics.
- Explicit interpretable explanations are provided for each recognition decision.
- Performance is competitive with black-box models on NTU RGB+D 60/120 and NW-UCLA datasets.
- Semantic structure is imposed on concepts through alignment with language descriptions of motion primitives.
Where Pith is reading between the lines
- This structure could enable manual inspection or editing of the learned rules to fix errors or add domain knowledge.
- Similar neurosymbolic grounding might apply to other perception tasks involving temporal sequences.
- The separation of pose and dynamics concepts could help in diagnosing which aspect of motion drives a particular classification.
Load-bearing premise
The descriptions of atomic motion primitives from large language models form a reliable shared conceptual space that can be accurately grounded in skeleton data by the concept decoder without misalignment.
What would settle it
Running the model on actions with well-known motion descriptions and checking if the generated logical rules align with those descriptions, or observing if performance drops sharply without the language alignment component.
Figures








read the original abstract
Skeleton-based human activity recognition has achieved strong empirical performance, yet most existing models remain black boxes and difficult to interpret. In this work, we introduce a neurosymbolic formulation of skeleton-based HAR that reframes action recognition as concept-driven first-order logical reasoning over motion primitives. Our framework bridges representation learning and symbolic inference by grounding first-order logic predicates in learnable spatial and temporal motion concepts. Specifically, we employ a standard spatio-temporal skeleton encoder to extract latent motion representations, which are then mapped to interpretable concept predicates via a spatio-temporal concept decoder that explicitly separates pose-centric and dynamics-centric abstractions. These concept predicates are composed through differentiable first-order logic layers, enabling the model to learn human-readable logical rules that govern action semantics. To impose semantic structure on the learned concepts, we align skeleton representations with LLM-derived descriptions of atomic motion primitives, establishing a shared conceptual space for perception and reasoning. Extensive experiments on NTU RGB+D 60/120 and NW-UCLA demonstrate that our approach achieves competitive recognition performance while providing explicit, interpretable explanations grounded in logical structure. Our results highlight neurosymbolic reasoning as an effective paradigm for interpretable spatio-temporal action understanding. Code: https://github.com/Mr-TalhaIlyas/REASON
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a neurosymbolic framework for skeleton-based human action recognition that reframes the task as concept-driven first-order logical reasoning over motion primitives. It uses a standard spatio-temporal skeleton encoder to extract latent representations, maps them via a spatio-temporal concept decoder that separates pose-centric and dynamics-centric predicates, composes the predicates in differentiable FOL layers to learn human-readable rules, and aligns the representations with LLM-derived descriptions of atomic motion primitives to impose semantic structure. Experiments on NTU RGB+D 60/120 and NW-UCLA are claimed to yield competitive recognition accuracy alongside explicit, interpretable explanations.
Significance. If the grounding and reasoning components hold, the work could advance interpretable action understanding by bridging neural representation learning with symbolic inference in a spatio-temporal setting. The explicit pose/dynamics separation and LLM-based alignment for shared conceptual space are distinctive elements, and the public code link supports reproducibility and verification of the differentiable logic implementation.
major comments (2)
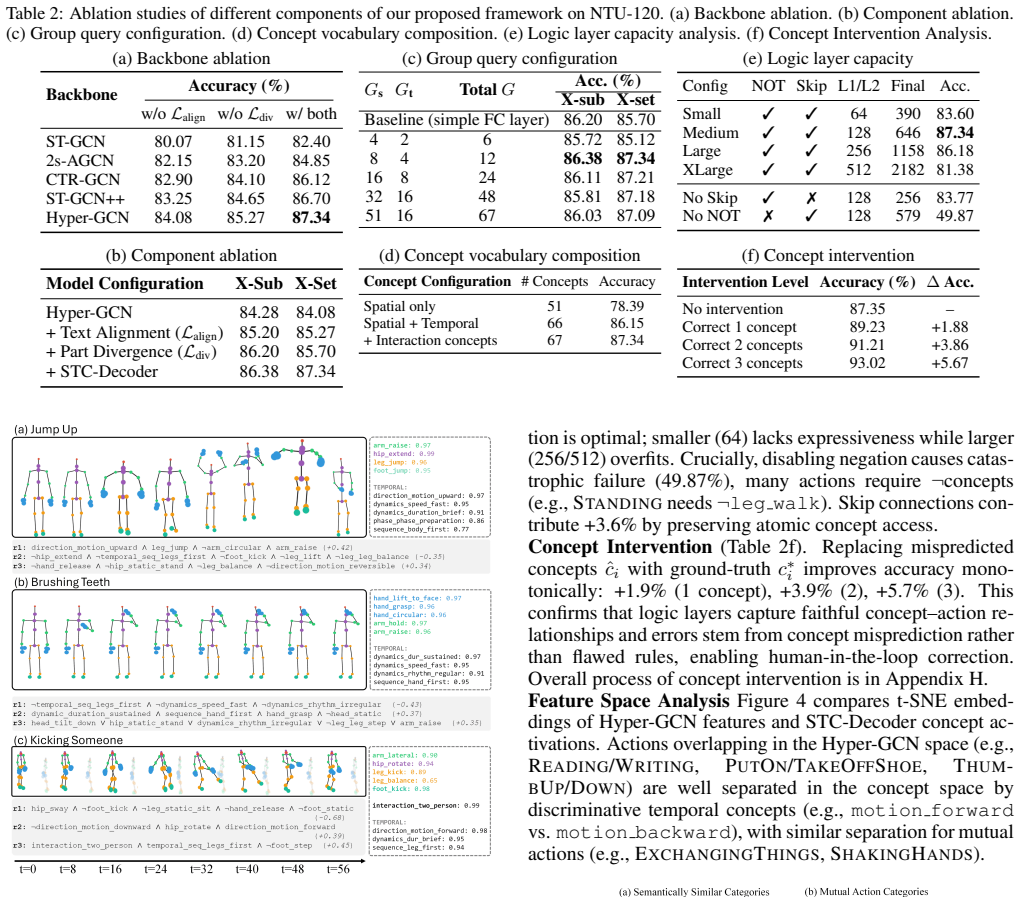
- [Abstract and Experiments] Abstract and Experiments section: The central claim of 'competitive recognition performance while providing explicit, interpretable explanations grounded in logical structure' lacks reported quantitative support in the form of accuracy tables, baseline comparisons, or ablations that isolate the LLM alignment step. Without these, it is impossible to assess whether the FOL rules contribute to performance or merely fit post-hoc to LLM descriptions, directly undermining the interpretability guarantee.
- [Method] Method section (concept decoder and alignment): The claim that LLM-derived atomic motion primitive descriptions form a reliable shared conceptual space with the learned predicates (the key axiom enabling semantic structure) is not supported by any validation metric such as concept-description similarity, rule fidelity checks, or an ablation removing the alignment. This is load-bearing for the neurosymbolic contribution, as misalignment would render the logical explanations spurious rather than grounded in skeleton data.
minor comments (2)
- Notation for the spatio-temporal concept predicates and the differentiable FOL operators could be made more explicit (e.g., defining the exact form of the pose and dynamics predicates) to improve clarity for readers unfamiliar with neurosymbolic setups.
- The paper should include a limitations paragraph discussing potential failure modes of the LLM alignment (e.g., hallucinated primitives or domain mismatch with skeleton data).
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies important gaps in empirical validation. We address each major comment below and will revise the manuscript to strengthen the support for our claims.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: The central claim of 'competitive recognition performance while providing explicit, interpretable explanations grounded in logical structure' lacks reported quantitative support in the form of accuracy tables, baseline comparisons, or ablations that isolate the LLM alignment step. Without these, it is impossible to assess whether the FOL rules contribute to performance or merely fit post-hoc to LLM descriptions, directly undermining the interpretability guarantee.
Authors: We appreciate the referee's point. The Experiments section (Section 4) reports accuracy tables on NTU RGB+D 60/120 and NW-UCLA with comparisons against multiple baselines, showing competitive performance. However, we acknowledge that ablations specifically isolating the LLM alignment step are absent. In the revised version, we will add these ablations (with/without alignment) along with quantitative metrics on rule quality to demonstrate that the FOL component contributes meaningfully rather than fitting post-hoc. revision: yes
-
Referee: [Method] Method section (concept decoder and alignment): The claim that LLM-derived atomic motion primitive descriptions form a reliable shared conceptual space with the learned predicates (the key axiom enabling semantic structure) is not supported by any validation metric such as concept-description similarity, rule fidelity checks, or an ablation removing the alignment. This is load-bearing for the neurosymbolic contribution, as misalignment would render the logical explanations spurious rather than grounded in skeleton data.
Authors: We agree this validation is essential. The alignment is currently enforced via a contrastive loss between skeleton-derived concept embeddings and LLM embeddings of motion primitives, but no explicit similarity scores, fidelity metrics, or removal ablations are reported. We will revise the Method and Experiments sections to include cosine similarity between aligned embeddings, rule fidelity checks against ground-truth action semantics, and an ablation removing the alignment loss to quantify its effect on both accuracy and explanation coherence. revision: yes
Circularity Check
No significant circularity detected in the derivation chain.
full rationale
The framework is built from a standard spatio-temporal skeleton encoder for latent representations, a decoder mapping to pose and dynamics predicates, differentiable FOL composition layers, and an alignment step with external LLM-derived motion primitive descriptions. No equations, self-citations, or steps in the provided abstract or description reduce by construction to fitted inputs renamed as predictions, self-definitional loops, or load-bearing self-citations. The alignment imposes semantic structure from an independent source rather than deriving it internally, and performance claims rest on experiments with external benchmarks (NTU RGB+D, NW-UCLA). The derivation chain remains self-contained without the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Differentiable first-order logic layers can learn human-readable rules that govern action semantics from data.
- ad hoc to paper LLM-derived descriptions of atomic motion primitives form a valid shared conceptual space with skeleton representations.
invented entities (1)
-
Spatio-temporal concept predicates
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/LogicAsFunctionalEquation.leanSatisfiesLawsOfLogic unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we employ a standard spatio-temporal skeleton encoder... mapped to interpretable concept predicates via a spatio-temporal concept decoder... composed through differentiable first-order logic layers
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
align skeleton representations with LLM-derived descriptions of atomic motion primitives
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Structure and Interpretation of Computer Programs
Harold Abelson and Gerald Jay Sussman and Julie Sussman. Structure and Interpretation of Computer Programs. 1985
work page 1985
-
[2]
Visual Information Extraction with Lixto
Robert Baumgartner and Georg Gottlob and Sergio Flesca. Visual Information Extraction with Lixto. Proceedings of the 27th International Conference on Very Large Databases. 2001
work page 2001
-
[3]
Ronald J. Brachman and James G. Schmolze. An overview of the KL-ONE knowledge representation system. Cognitive Science. 1985
work page 1985
-
[4]
Complexity results for nonmonotonic logics
Georg Gottlob. Complexity results for nonmonotonic logics. Journal of Logic and Computation. 1992
work page 1992
-
[5]
Hypertree Decompositions and Tractable Queries
Georg Gottlob and Nicola Leone and Francesco Scarcello. Hypertree Decompositions and Tractable Queries. Journal of Computer and System Sciences. 2002
work page 2002
- [6]
- [7]
-
[8]
On the compilability and expressive power of propositional planning formalisms
Bernhard Nebel. On the compilability and expressive power of propositional planning formalisms. Journal of Artificial Intelligence Research. 2000
work page 2000
- [9]
-
[10]
Neural Computing and Applications , volume=
Neuro-symbolic artificial intelligence: a survey , author=. Neural Computing and Applications , volume=. 2024 , publisher=
work page 2024
-
[11]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Channel-wise topology refinement graph convolution for skeleton-based action recognition , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[12]
Advances in Neural Information Processing Systems , volume=
Ptr: A benchmark for part-based conceptual, relational, and physical reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Revisiting skeleton-based action recognition , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[14]
IEEE transactions on pattern analysis and machine intelligence , volume=
Human action recognition from various data modalities: A review , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2022 , publisher=
work page 2022
-
[15]
Proceedings of the 30th ACM international conference on multimedia , pages=
Pyskl: Towards good practices for skeleton action recognition , author=. Proceedings of the 30th ACM international conference on multimedia , pages=
-
[16]
IEEE Transactions on Visualization and Computer Graphics , volume=
Skeleton-based human action recognition via large-kernel attention graph convolutional network , author=. IEEE Transactions on Visualization and Computer Graphics , volume=. 2023 , publisher=
work page 2023
-
[17]
Proceedings of the IEEE international conference on computer vision , pages=
P-cnn: Pose-based cnn features for action recognition , author=. Proceedings of the IEEE international conference on computer vision , pages=
-
[18]
Skelemotion: A new representation of skeleton joint sequences based on motion information for 3d action recognition , author=. 2019 16th IEEE international conference on advanced video and signal based surveillance (AVSS) , pages=. 2019 , organization=
work page 2019
-
[19]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
A new representation of skeleton sequences for 3d action recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[20]
arXiv preprint arXiv:1804.06055 , year=
Co-occurrence feature learning from skeleton data for action recognition and detection with hierarchical aggregation , author=. arXiv preprint arXiv:1804.06055 , year=
-
[21]
DeepActsNet: A deep ensemble framework combining features from face, hands, and body for action recognition , author=. Pattern Recognition , volume=. 2023 , publisher=
work page 2023
-
[22]
Proceedings of the 25th ACM international conference on Multimedia , pages=
3d cnns on distance matrices for human action recognition , author=. Proceedings of the 25th ACM international conference on Multimedia , pages=
-
[23]
arXiv preprint arXiv:1705.08106 , year=
Two-stream 3d convolutional neural network for skeleton-based action recognition , author=. arXiv preprint arXiv:1705.08106 , year=
-
[24]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Global context-aware attention lstm networks for 3d action recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[25]
European Conference on Computer Vision , pages=
Rnn fisher vectors for action recognition and image annotation , author=. European Conference on Computer Vision , pages=. 2016 , organization=
work page 2016
-
[26]
Proceedings of the AAAI conference on artificial intelligence , volume=
Spatial temporal graph convolutional networks for skeleton-based action recognition , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[27]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Disentangling and unifying graph convolutions for skeleton-based action recognition , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[28]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Actional-structural graph convolutional networks for skeleton-based action recognition , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[29]
Proceedings of the AAAI conference on artificial intelligence , volume=
Spatio-temporal graph routing for skeleton-based action recognition , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[30]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Two-stream adaptive graph convolutional networks for skeleton-based action recognition , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[31]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Hierarchically decomposed graph convolutional networks for skeleton-based action recognition , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[32]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Blockgcn: Redefine topology awareness for skeleton-based action recognition , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[33]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Infogcn: Representation learning for human skeleton-based action recognition , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[34]
Proceedings of the AAAI conference on artificial intelligence , volume=
Dynamic semantic-based spatial graph convolution network for skeleton-based human action recognition , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[35]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Towards automated and marker-less Parkinson disease assessment: predicting UPDRS scores using sit-stand videos , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[36]
International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=
Privacy-preserving early detection of epileptic seizures in videos , author=. International Conference on Medical Image Computing and Computer-Assisted Intervention , pages=. 2023 , organization=
work page 2023
-
[37]
Australasian Joint Conference on Artificial Intelligence , pages=
Privacy-Centric Seizure Detection Using Surface Normals, Pose and Segmentation Masks , author=. Australasian Joint Conference on Artificial Intelligence , pages=. 2025 , organization=
work page 2025
-
[38]
International Workshop on Applications of Medical AI , pages=
Privacy-Centric Seizure Diagnosis via Relation-Aware Fusion of Minimally-Invasive Modalities , author=. International Workshop on Applications of Medical AI , pages=. 2025 , organization=
work page 2025
-
[39]
arXiv preprint arXiv:2511.10091 , year=
SUGAR: Learning Skeleton Representation with Visual-Motion Knowledge for Action Recognition , author=. arXiv preprint arXiv:2511.10091 , year=
-
[40]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Generative action description prompts for skeleton-based action recognition , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[41]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Spatial-temporal concept based explanation of 3d convnets , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[42]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Understanding video transformers via universal concept discovery , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[43]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Neuro-symbolic evaluation of text-to-video models using formal verification , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[44]
Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition , pages=
Hierarchical neurosymbolic approach for comprehensive and explainable action quality assessment , author=. Proceedings of the IEEE/CVF Conference on computer vision and pattern recognition , pages=
-
[45]
Neuro-symbolic artificial intelligence: The state of the art , author=. 2022 , publisher=
work page 2022
-
[46]
Advances in neural information processing systems , volume=
Deepproblog: Neural probabilistic logic programming , author=. Advances in neural information processing systems , volume=
-
[47]
arXiv preprint arXiv:2505.05519 , year=
Real-time privacy preservation for robot visual perception , author=. arXiv preprint arXiv:2505.05519 , year=
-
[48]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Predicate invention for bilevel planning , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[49]
arXiv preprint arXiv:1705.08968 , year=
Logic tensor networks for semantic image interpretation , author=. arXiv preprint arXiv:1705.08968 , year=
-
[50]
International conference on machine learning , pages=
Concept bottleneck models , author=. International conference on machine learning , pages=. 2020 , organization=
work page 2020
-
[51]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Language in a bottle: Language model guided concept bottlenecks for interpretable image classification , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[52]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=. 2021 , organization=
work page 2021
-
[53]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
WISE: Weak-Supervision-Guided Step-by-Step Explanations for Multimodal LLMs in Image Classification , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[54]
arXiv preprint arXiv:2506.01334 , year=
Enhancing Interpretable Image Classification Through LLM Agents and Conditional Concept Bottleneck Models , author=. arXiv preprint arXiv:2506.01334 , year=
-
[55]
International Conference on Information Processing in Medical Imaging , pages=
Interpretable few-shot retinal disease diagnosis with concept-guided prompting of vision-language models , author=. International Conference on Information Processing in Medical Imaging , pages=. 2025 , organization=
work page 2025
-
[56]
International Conference on Machine Learning , pages=
Interpretable neural-symbolic concept reasoning , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[57]
arXiv preprint arXiv:2106.08641 , year=
Best of both worlds: local and global explanations with human-understandable concepts , author=. arXiv preprint arXiv:2106.08641 , year=
-
[58]
Logical approximation , author=. Soft Computing , volume=. 2002 , publisher=
work page 2002
-
[59]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
Learning interpretable rules for scalable data representation and classification , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2023 , publisher=
work page 2023
-
[60]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Ntu rgb+ d: A large scale dataset for 3d human activity analysis , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[61]
IEEE transactions on pattern analysis and machine intelligence , volume=
Ntu rgb+ d 120: A large-scale benchmark for 3d human activity understanding , author=. IEEE transactions on pattern analysis and machine intelligence , volume=. 2019 , publisher=
work page 2019
-
[62]
Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
Cross-view action modeling, learning and recognition , author=. Proceedings of the IEEE conference on computer vision and pattern recognition , pages=
-
[63]
2023 IEEE international conference on multimedia and expo workshops (ICMEW) , pages=
Skeletonmae: Spatial-temporal masked autoencoders for self-supervised skeleton action recognition , author=. 2023 IEEE international conference on multimedia and expo workshops (ICMEW) , pages=. 2023 , organization=
work page 2023
-
[64]
Proceedings of the IEEE/CVF international conference on computer vision , pages=
Motionbert: A unified perspective on learning human motion representations , author=. Proceedings of the IEEE/CVF international conference on computer vision , pages=
-
[65]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
Llms are good action recognizers , author=. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , pages=
-
[66]
Enhancing concept-based learning with logic , author=
-
[67]
LogicCBMs: Logic-Enhanced Concept-Based Learning, 2025
LogicCBMs: Logic-Enhanced Concept-Based Learning , author=. arXiv preprint arXiv:2512.07383 , year=
-
[68]
IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=
HAKE: A knowledge engine foundation for human activity understanding , author=. IEEE Transactions on Pattern Analysis and Machine Intelligence , volume=. 2022 , publisher=
work page 2022
-
[69]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[70]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Adaptive hyper-graph convolution network for skeleton-based human action recognition with virtual connections , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
- [71]
-
[72]
Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
Ml-decoder: Scalable and versatile classification head , author=. Proceedings of the IEEE/CVF winter conference on applications of computer vision , pages=
-
[73]
Promises and pitfalls of black-box concept learning models.arXiv preprint arXiv:2106.13314, 2021
Promises and pitfalls of black-box concept learning models , author=. arXiv preprint arXiv:2106.13314 , year=
-
[74]
Estimating or Propagating Gradients Through Stochastic Neurons for Conditional Computation
Estimating or propagating gradients through stochastic neurons for conditional computation , author=. arXiv preprint arXiv:1308.3432 , year=
work page internal anchor Pith review arXiv
-
[75]
European conference on computer vision , pages=
Decoupling gcn with dropgraph module for skeleton-based action recognition , author=. European conference on computer vision , pages=. 2020 , organization=
work page 2020
-
[76]
Multi-scale spatial temporal graph neural network for skeleton-based action recognition , author=. IEEE Access , volume=. 2021 , publisher=
work page 2021
-
[77]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Learning discriminative representations for skeleton based action recognition , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[78]
IEEE Transactions on Image Processing , volume=
Hypergraph neural network for skeleton-based action recognition , author=. IEEE Transactions on Image Processing , volume=. 2021 , publisher=
work page 2021
-
[79]
Proceedings of the 2022 international conference on multimedia retrieval , pages=
Selective hypergraph convolutional networks for skeleton-based action recognition , author=. Proceedings of the 2022 international conference on multimedia retrieval , pages=
work page 2022
-
[80]
2023 IEEE International Conference on Multimedia and Expo (ICME) , pages=
Dynamic spatial-temporal hypergraph convolutional network for skeleton-based action recognition , author=. 2023 IEEE International Conference on Multimedia and Expo (ICME) , pages=. 2023 , organization=
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.